Recognition: 2 theorem links
· Lean TheoremMachine learning for the early classification of broad-lined Ic supernovae
Pith reviewed 2026-05-16 20:39 UTC · model grok-4.3
The pith
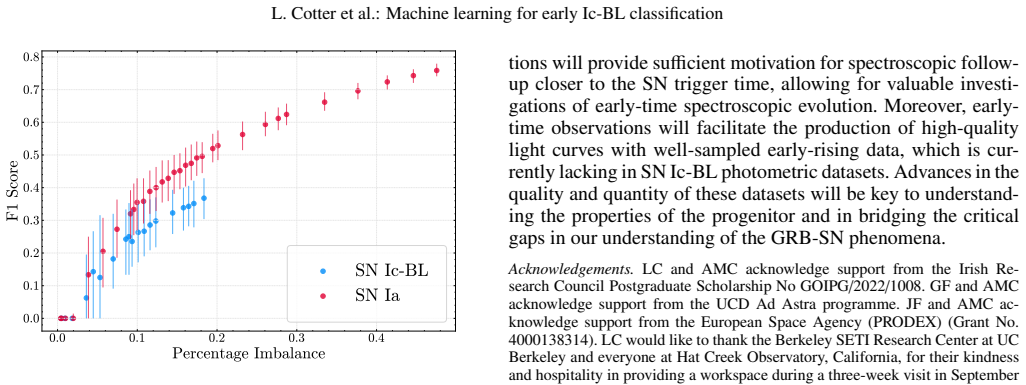
Machine learning with new magnitude rates from the first three photometric points can flag up to 13.6 percent of broad-lined Ic supernovae in unseen data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a random forest classifier trained solely on three magnitudes, three time differences, two newly defined magnitude rates, and the second derivative of those rates from the first three photometric points in one filter can identify upward of 13.6 percent of the total true SN Ic-BL population when applied to an unseen dataset, representing a significant improvement over existing classification techniques.
What carries the argument
Magnitude rates, defined from the change in brightness across the first three single-filter photometric points, which encode early light-curve evolution to separate Ic-BL events from other supernovae.
If this is right
- Dedicated campaigns can trigger rapid follow-up on flagged candidates and collect higher-quality early-time data each year.
- The number of classified Ic-BL supernovae available for studies of gamma-ray burst connections will increase.
- The same feature set and random forest approach reproduces useful results when applied to Type Ia supernovae, indicating broader applicability.
- Early single-filter classification reduces the fraction of events that remain untyped until after peak brightness.
Where Pith is reading between the lines
- Large surveys could incorporate these magnitude rates into real-time alert streams to prioritize spectroscopic resources.
- If the rates prove robust across instruments, they may help isolate physical differences in explosion mechanisms among core-collapse events.
- Adding multi-filter data or more points after the initial three could raise the recovered fraction further while keeping the early-time advantage.
- The method offers a practical way to increase the yield of rare transients without requiring new hardware.
Load-bearing premise
The first three photometric points in a single filter together with the derived magnitude rates contain enough information to generalize to the full Ic-BL population without large contamination from other supernova types.
What would settle it
Running the trained model on a large independent catalog of spectroscopically confirmed supernovae and finding that it recovers substantially fewer than 13.6 percent of known Ic-BL events or produces many false positives from Ia or Ib/c types would falsify the performance claim.
Figures




read the original abstract
Science is currently at an age where there is more data than we know how to deal with. Machine learning (ML) is an emerging tool that is useful for drawing valuable science out of incomprehensibly large datasets and identifying complex trends in data that may otherwise be overlooked. Moreover, ML can potentially enhance the quality and quantity of scientific data as they are collected. This paper explores how a new ML method can improve the rate of classification of rare broad-lined Ic (Ic-BL) supernovae (SNe). We introduce new parameters called magnitude rates to train ML models to identify SNe Ic-BL in large datasets and apply this same methodology to a population of SN Ia to test if our ML approach is reproducible. The information we required to train each ML model included three magnitudes, three time differences, two magnitude rates, and the second derivative of these rates using the first three available photometric data points in a single filter. Our initial investigations showed that the random forest algorithm provides a strong foundation for the early classifications SNe Ic-BL and SNe Ia. Testing this model again on an unseen dataset showed that the model can identify upward of 13.6\% of the total true SN Ic-BL population, significantly improving on current methods. By implementing a dedicated observation campaign using this model, the number of SN Ic-BL classified and the quality of early-time data collected each year will see considerable growth in the near future.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a random forest machine learning classifier for the early identification of broad-lined Type Ic supernovae (SN Ic-BL) using only the first three photometric points in a single filter. It introduces new engineered features termed 'magnitude rates' together with their second derivatives, in addition to the three magnitudes and three time differences. The central result is that the trained model recovers up to 13.6% of the true SN Ic-BL population when evaluated on an unseen dataset, which the authors state represents a significant improvement over existing classification methods; the same pipeline is applied to SN Ia as a reproducibility check.
Significance. If the reported recovery rate is shown to be robust, the work could increase the annual yield of early-classified SN Ic-BL events and thereby improve the quality and quantity of follow-up data for these rare transients. The introduction of magnitude rates offers a lightweight way to encode early light-curve slope information that may be useful for other time-domain classification tasks. The approach directly addresses the data-volume challenge in modern transient surveys.
major comments (3)
- [Abstract] Abstract: the claim that the model 'can identify upward of 13.6% of the total true SN Ic-BL population' on an unseen dataset is presented without any description of the test-set construction, class balance, achieved precision or specificity, error bars, or measured contamination from other supernova types. These quantities are required to determine whether the result constitutes a genuine population-level improvement.
- [Abstract] Abstract: the feature vector is defined as 'three magnitudes, three time differences, two magnitude rates, and the second derivative of these rates', yet no explicit formula or algorithmic definition is supplied for the magnitude rates or their derivatives. Without this information the features cannot be reproduced or checked for redundancy with the raw magnitudes.
- [Results] Results: no baseline classifiers, ablation experiments on feature importance, or quantitative comparison against existing photometric SN classification pipelines are reported. Consequently it is impossible to attribute the stated improvement to the newly introduced magnitude rates rather than to the random-forest algorithm or to dataset-specific biases.
minor comments (1)
- [Abstract] Abstract: the phrase 'early classifications SNe Ic-BL' is grammatically incomplete and should read 'early classification of SNe Ic-BL'.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address each of the major comments below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the model 'can identify upward of 13.6% of the total true SN Ic-BL population' on an unseen dataset is presented without any description of the test-set construction, class balance, achieved precision or specificity, error bars, or measured contamination from other supernova types. These quantities are required to determine whether the result constitutes a genuine population-level improvement.
Authors: We agree that the abstract lacks sufficient supporting details for the 13.6% claim. In the revised manuscript, we will expand the abstract to briefly describe the test-set construction, class balance, precision, specificity, error bars on the recovery rate, and measured contamination from other types. This will allow readers to better evaluate whether the result represents a genuine improvement. revision: yes
-
Referee: [Abstract] Abstract: the feature vector is defined as 'three magnitudes, three time differences, two magnitude rates, and the second derivative of these rates', yet no explicit formula or algorithmic definition is supplied for the magnitude rates or their derivatives. Without this information the features cannot be reproduced or checked for redundancy with the raw magnitudes.
Authors: We acknowledge that explicit definitions are necessary for reproducibility. We will add a dedicated subsection in the Methods section providing the mathematical definitions: the magnitude rate between points i and i+1 is (m_{i+1} - m_i)/(t_{i+1} - t_i), and the second derivative is the difference of consecutive rates divided by the time interval. This will allow readers to verify the features and assess any redundancy with the raw magnitudes. revision: yes
-
Referee: [Results] Results: no baseline classifiers, ablation experiments on feature importance, or quantitative comparison against existing photometric SN classification pipelines are reported. Consequently it is impossible to attribute the stated improvement to the newly introduced magnitude rates rather than to the random-forest algorithm or to dataset-specific biases.
Authors: We recognize the value of baseline comparisons and ablation studies for attributing the performance gains. In the revised manuscript, we will include ablation experiments demonstrating the importance of the magnitude rate features by comparing model performance with and without them. We will also add a baseline classifier (such as a decision tree or logistic regression using only the raw magnitudes and times) for direct comparison. Regarding existing pipelines, we will discuss the challenges in direct quantitative comparison, as most prior methods require full light-curve coverage rather than the first three points, but we will reference relevant works and note how our early-time focus differs. The reproducibility check on SN Ia provides supporting evidence for the method's robustness. revision: yes
Circularity Check
No circularity in ML training and unseen-test evaluation pipeline
full rationale
The paper trains a random forest model on engineered features (three magnitudes, time differences, magnitude rates and second derivatives) extracted from the first three single-filter photometric points, then evaluates recovery on a separate unseen dataset to claim 13.6% population identification. This is a standard supervised-learning workflow with no self-definitional reduction, no fitted parameter renamed as a prediction, and no load-bearing self-citation chain. The reported performance is measured on held-out data and does not collapse to the training inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training data is representative of the full population of SNe Ic-BL and Ia.
invented entities (1)
-
magnitude rates
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three magnitudes, three time differences, two magnitude rates, and the second derivative of these rates using the first three available photometric data points in a single filter
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
random forest algorithm provides a strong foundation for the early classifications
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Arnett, W. D. 1982, ApJ, 253, 785
work page 1982
-
[2]
Barnes, J., Duffell, P. C., Liu, Y ., et al. 2018, The Astrophysical Journal, 860, 38
work page 2018
-
[3]
Baum, E. B. 1988, Journal of Complexity, 4, 193–215
work page 1988
-
[4]
Bianco, F. B., Ivezi´c, Ž., Jones, R. L., et al. 2022, ApJS, 258, 1
work page 2022
- [5]
-
[6]
2017, Advances in Astronomy, 2017, 8929054
Cano, Z., Wang, S.-Q., Dai, Z.-G., & Wu, X.-F. 2017, Advances in Astronomy, 2017, 8929054
work page 2017
-
[7]
Carrasco-Davis, R., Reyes, E., Valenzuela, C., et al. 2021, AJ, 162, 231
work page 2021
-
[8]
Corsi, A., Ho, A. Y . Q., Cenko, S. B., et al. 2023, ApJ, 953, 179
work page 2023
- [9]
-
[10]
Filippenko, A. V . 1997, ARA&A, 35, 309
work page 1997
-
[11]
Finneran, G., Cotter, L., & Martin-Carrillo, A. 2025, A&A, 700, A200
work page 2025
- [12]
-
[13]
Freund, Y . & Schapire, R. E. 1997, Journal of Computer and System Sciences, 55, 119–139 Förster, F., Cabrera-Vives, G., Castillo-Navarrete, E., et al. 2021, ApJ, 161, 242
work page 1997
-
[14]
Galama, T. J., Vreeswijk, P. M., van Paradijs, J., et al. 1998, Nature, 395, 670
work page 1998
-
[15]
Granot, J., Panaitescu, A., Kumar, P., & Woosley, S. E. 2002, ApJ, 570, L61
work page 2002
-
[16]
Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357
work page 2020
-
[17]
Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90
work page 2007
- [18]
-
[19]
Izzo, L., de Ugarte Postigo, A., Maeda, K., et al. 2019, Nature, 565, 324
work page 2019
-
[20]
Kessler, R., Bassett, B., Belov, P., et al. 2010, PASP, 122, 1415
work page 2010
-
[21]
Khakpash, S., Bianco, F. B., Modjaz, M., et al. 2024, ApJ, 275, 37
work page 2024
- [22]
-
[23]
Lochner, M., McEwen, J. D., Peiris, H. V ., Lahav, O., & Winter, M. K. 2016, ApJS, 225, 31
work page 2016
-
[24]
Markel, J. & Bayless, A. J. 2020, Using Random Forest Machine Learning Al- gorithms in Binary Supernovae Classification
work page 2020
- [25]
-
[26]
Modjaz, M., Liu, Y . Q., Bianco, F. B., & Graur, O. 2016, ApJ, 832, 108 Möller, A., Ruhlmann-Kleider, V ., Leloup, C., et al. 2016, J. Cosmology As- tropart. Phys., 2016, 008
work page 2016
-
[27]
2011, Journal of Machine Learning Research, 12, 2825
Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825
work page 2011
-
[28]
Pessi, T., Desai, D. D., Prieto, J. L., et al. 2025, arXiv e-prints, arXiv:2508.10985
-
[29]
2004, Reviews of Modern Physics, 76, 1143
Piran, T. 2004, Reviews of Modern Physics, 76, 1143
work page 2004
-
[30]
Quinlan, J. R. 1986, Machine Learning, 1, 81–106
work page 1986
-
[31]
Rish, I. 2001, IJCAI 2001 Workshop on Empirical Methods in Artifical Intelli- gence, 3, 41 Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141
work page 2001
-
[32]
Schroeder, G., Ho, A. Y . Q., Dastidar, R. G., et al. 2025, ApJ, 995, 61
work page 2025
-
[33]
Taddia, F., Stritzinger, M. D., Bersten, M., et al. 2018, A&A, 609, A136
work page 2018
- [34]
-
[35]
2016, International Journal of Applied Pattern Recognition, 3, 145
Tharwat, A. 2016, International Journal of Applied Pattern Recognition, 3, 145
work page 2016
-
[36]
2003, in Supernovae and Gamma-Ray Bursters, ed
Turatto, M. 2003, in Supernovae and Gamma-Ray Bursters, ed. K. Weiler, V ol. 598, 21–36
work page 2003
- [37]
- [38]
-
[39]
Woosley, S. E. & Bloom, J. S. 2006, ARA&A, 44, 507
work page 2006
-
[40]
Woosley, S. E., Eastman, R. G., & Schmidt, B. P. 1999, ApJ, 516, 788 Article number, page 7 of 10 A&A proofs:manuscript no. aanda Appendix A: Tables Tables showing the different metrics measured in each of the training and testing datasets for each SN case and for each of the ML algorithms models considered. Table A.1: esults of the validation done from a...
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.