Benchmarking and Enhancing VLM for Compressed Image Understanding
Pith reviewed 2026-05-25 07:23 UTC · model grok-4.3
The pith
A single universal adaptor boosts VLM performance on compressed images by 10-30% across codecs and bitrates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLMs exhibit a generalization failure on compressed images that a single universal adaptor can mitigate, rather than being limited solely by irreversible information loss. The benchmark quantifies this gap across codecs and tasks, and the adaptor delivers consistent 10-30% gains on the compressed inputs without requiring codec-specific changes.
What carries the argument
The universal VLM adaptor, a single module that improves understanding of compressed inputs irrespective of codec or bitrate.
If this is right
- VLMs become usable on low-bitrate streams without retraining the entire model.
- Existing image codecs can be paired with VLMs more effectively through one shared adaptation step.
- Systematic evaluation of compression effects on multimodal tasks is now possible with the released benchmark.
- Generalization gaps for other degraded inputs may be addressable by similar lightweight modules.
Where Pith is reading between the lines
- The same adaptor principle could extend to other input degradations such as sensor noise or low resolution.
- Real-world applications with bandwidth limits become more practical once VLMs handle compressed data reliably.
- Testing whether comparable adaptors improve video or audio compression handling would be a direct next step.
Load-bearing premise
The performance gap on compressed images is caused by a generalization failure that one adaptor can correct, rather than by information loss that no model change can recover.
What would settle it
The adaptor produces no accuracy gain on a new codec outside the training set, or the gains vanish on tasks that require details known to be lost in compression.
Figures




















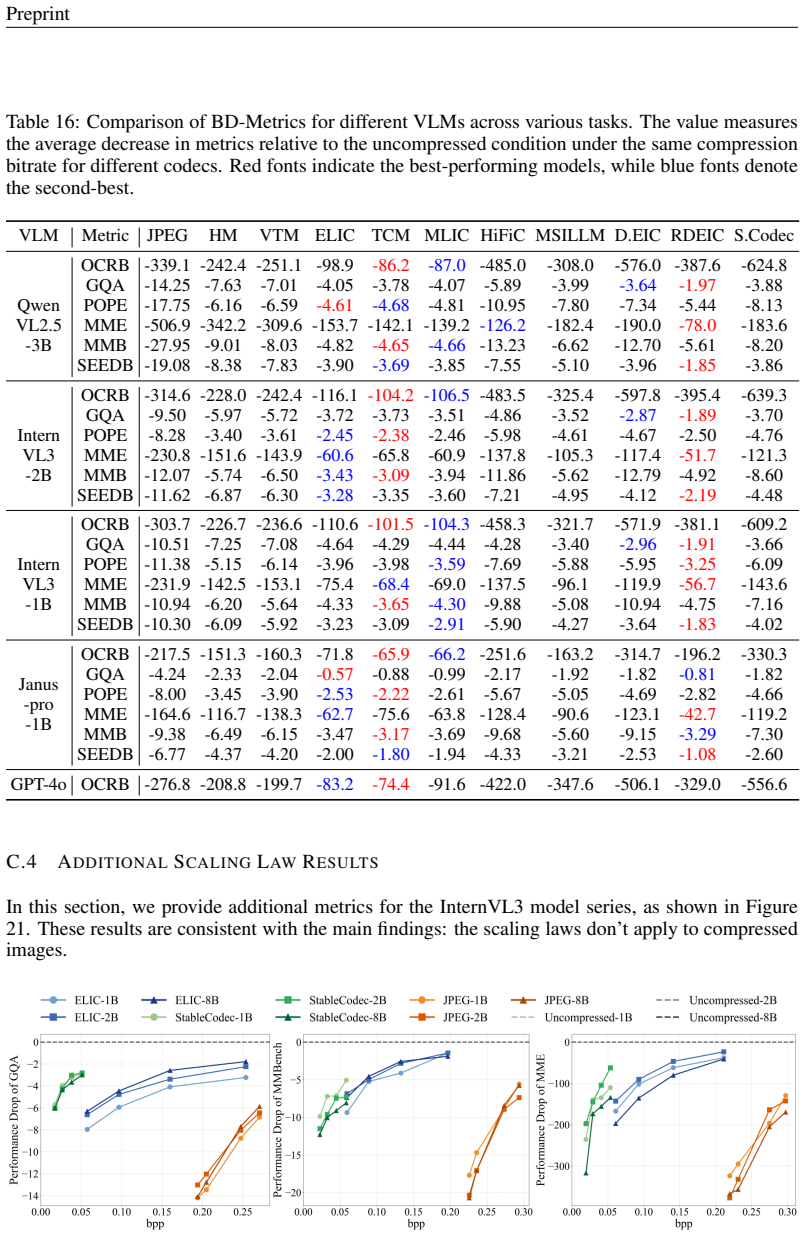


read the original abstract
With the rapid development of Vision-Language Models (VLMs) and the growing demand for their applications, efficient compression of the image inputs has become increasingly important. Existing VLMs predominantly digest and understand high-bitrate compressed images, while their ability to interpret low-bitrate compressed images has yet to be explored by far. In this paper, we introduce the first comprehensive benchmark to evaluate the ability of VLM against compressed images, varying existing widely used image codecs and diverse set of tasks, encompassing over one million compressed images in our benchmark. Next, we analyse the source of performance gap, by categorising the gap from a) the information loss during compression and b) generalisation failure of VLM. We visualize these gaps with concrete examples and identify that for compressed images, only the generalization gap can be mitigated. Finally, we propose a universal VLM adaptor to enhance model performance on images compressed by existing codecs. Consequently, we demonstrate that a single adaptor can improve VLM performance across images with varying codecs and bitrates by 10%-30%. We believe that our benchmark and enhancement method provide valuable insights and contribute toward bridging the gap between VLMs and compressed images. The source code is available at https://github.com/bblgbr/CompressVLMBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first large-scale benchmark (>1M compressed images) for VLMs across standard codecs, bitrates, and tasks. It partitions observed performance degradation into information loss versus generalization failure via qualitative visualizations, concludes that only the latter is mitigable, and presents a single universal adaptor that yields 10-30% gains on compressed inputs.
Significance. If the adaptor results are reproducible with proper controls, the benchmark and method would offer a practical contribution to deploying VLMs under bandwidth constraints. The scale of the benchmark and public code release are positive features. The work remains primarily empirical and does not supply parameter-free derivations or formal bounds.
major comments (2)
- [Gap analysis] Gap analysis section: the claim that only generalization failure (not information loss) is mitigable rests on qualitative examples and visualizations alone. No quantitative separation—such as task-specific mutual-information bounds, oracle comparisons against lossless reconstructions, or ablations isolating recoverable versus lost content—is provided, leaving the load-bearing distinction between the two gap types unverified.
- [Experiments / Results] Experimental evaluation: the reported 10-30% gains are presented without details on adaptor training procedure, exact baseline models and hyperparameters, statistical significance testing, train/test splits, or error analysis. These omissions prevent verification of the central claim that one adaptor generalizes across codecs and bitrates.
minor comments (1)
- Figure captions for the gap visualizations should explicitly state the codec, bitrate, and task for each example to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below and commit to revisions that strengthen reproducibility and analysis without overstating the current manuscript's contributions.
read point-by-point responses
-
Referee: [Gap analysis] Gap analysis section: the claim that only generalization failure (not information loss) is mitigable rests on qualitative examples and visualizations alone. No quantitative separation—such as task-specific mutual-information bounds, oracle comparisons against lossless reconstructions, or ablations isolating recoverable versus lost content—is provided, leaving the load-bearing distinction between the two gap types unverified.
Authors: We agree that the distinction relies on qualitative visualizations of concrete examples (e.g., cases of irreversible detail loss versus patterns the VLM can adapt to). These examples support our conclusion that only the generalization gap is mitigable, as evidenced by the adaptor's consistent gains. We acknowledge the absence of quantitative separation such as mutual-information bounds or oracle lossless comparisons. In revision we will add oracle comparisons against lossless reconstructions and targeted ablations to isolate recoverable content; however, formal task-specific mutual-information bounds for VLMs lie outside the empirical scope of this work. revision: partial
-
Referee: [Experiments / Results] Experimental evaluation: the reported 10-30% gains are presented without details on adaptor training procedure, exact baseline models and hyperparameters, statistical significance testing, train/test splits, or error analysis. These omissions prevent verification of the central claim that one adaptor generalizes across codecs and bitrates.
Authors: We agree these details are necessary for verification. The revised manuscript will expand the experimental section with the full adaptor training procedure, exact baseline models and hyperparameters, train/test splits, statistical significance testing (including p-values), and error analysis. These additions will directly support the claim of cross-codec/bitrate generalization. revision: yes
Circularity Check
No circularity: empirical benchmark and measured adaptor gains
full rationale
The paper introduces a benchmark of over one million compressed images, categorizes performance gaps qualitatively via examples, and reports measured improvements (10%-30%) from a proposed universal adaptor. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The gains are presented as experimental outcomes on the benchmark rather than derivations that reduce to the benchmark construction or prior self-citations by definition. The work is self-contained as an empirical study with no load-bearing steps that collapse to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The performance gap between high-bitrate and low-bitrate compressed images contains a mitigable generalization component separate from irreversible information loss.
invented entities (1)
-
universal VLM adaptor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Variational image compression with a scale hyperprior
J. Ball´e, D. Minnen, S. Singh, S. Hwang, and N. Johnston. Variational image compression with a scale hyperprior.arXiv preprint arXiv:1802.01436,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu Chaoyou, Chen Peixian, Shen Yunhang, Qin Yulei, Zhang Mengdan, Lin Xu, Yang Jinrui, Zheng Xiawu, Li Ke, Sun Xing, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 3,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chaoran Chen, Mai Xu, Shengxi Li, Tie Liu, Minglang Qiao, and Zhuoyi Lv. Residual based hierar- chical feature compression for multi-task machine vision. In2023 IEEE International Conference on Multimedia and Expo (ICME), pp. 1463–1468. IEEE, 2023a. Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Yongchao Feng, Yajie Liu, Shuai Yang, Wenrui Cai, Jinqing Zhang, Qiqi Zhan, Ziyue Huang, Hongxi Yan, Qiao Wan, Chenguang Liu, et al. Vision-language model for object detection and segmentation: A review and evaluation.arXiv preprint arXiv:2504.09480,
-
[8]
Wei Jiang, Jiayu Yang, Yongqi Zhai, Feng Gao, and Ronggang Wang. Mlic++: Linear com- plexity multi-reference entropy modeling for learned image compression.arXiv preprint arXiv:2307.15421,
-
[9]
Chia-Hao Kao, Cheng Chien, Yu-Jen Tseng, Yi-Hsin Chen, Alessandro Gnutti, Shao-Yuan Lo, Wen- Hsiao Peng, and Riccardo Leonardi. Bridging compressed image latents and multimodal large language models.arXiv preprint arXiv:2407.19651,
-
[10]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Binzhe Li, Shurun Wang, Shiqi Wang, and Yan Ye. High efficiency image compression for large visual-language models.IEEE Transactions on Circuits and Systems for Video Technology, 2024a. Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Bench- marking multimodal llms with generative comprehension.arXiv preprint arXiv:2307....
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Learned image compression with mixed transformer- cnn architectures
Jinming Liu, Heming Sun, and Jiro Katto. Learned image compression with mixed transformer- cnn architectures. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14388–14397, 2023a. Tie Liu, Mai Xu, Shengxi Li, Chaoran Chen, Li Yang, and Zhuoyi Lv. Learnt mutual feature compression for machine vision. InIEEE ICASSP 202...
work page 2023
-
[12]
Fabian Mentzer, George D Toderici, Michael Tschannen, and Eirikur Agustsson
doi: 10.1109/DCC52660.2022.00080. Fabian Mentzer, George D Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity gen- erative image compression.Advances in neural information processing systems, 33:11913–11924,
-
[13]
13 Preprint Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Zhendong Wang, Hao Liu, Bin Lin, Hao Li, Xue Xu, et al. Can understanding and generation truly benefit together–or just coexist? arXiv preprint arXiv:2509.09666,
-
[16]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Anygpt: Unified multimodal llm with discrete sequence modeling.arXiv preprint arXiv:2402.12226,
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al. Anygpt: Unified multimodal llm with discrete sequence modeling.arXiv preprint arXiv:2402.12226,
-
[18]
Tianyu Zhang, Xin Luo, Li Li, and Dong Liu. Stablecodec: Taming one-step diffusion for extreme image compression.arXiv preprint arXiv:2506.21977, 2025a. Yuan Zhang, Hanming Wang, Yunlong Li, and Lu Yu. Afc: Asymmetrical feature coding for multi- task machine intelligence. In2024 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), pp. 1...
-
[19]
provides a standardized dataset and evaluation protocol for im- age caption generation using 5000 MS COCO testing images with 40 reference sentences per im- age. Captions output by different approaches are evaluated by automatic metrics including CIDEr, ROUGEL and Bleu. 16 Preprint • CIDEr aggregates Term Frequency Inverse Document Frequency (TF–IDF) weig...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.