HydraCollab: Adaptive Collaborative-Perception for Distributed Autonomous Systems
Pith reviewed 2026-07-02 18:36 UTC · model grok-4.3
The pith
HydraCollab uses spatial confidence maps to select informative features and switch between intermediate and late fusion, cutting bandwidth to 26-41% of prior methods while slightly raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
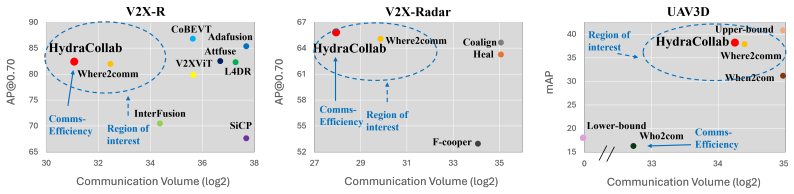
HydraCollab achieves the best overall trade-off between accuracy and communication cost among existing collaborative-perception methods. It does so by selectively transmitting the most informative sensor features and dynamically employing either intermediate or late collaboration based on spatial confidence maps, using only 41% of the bandwidth on V2X-R and 26% on V2X-Radar while improving performance by 0.78% and 0.75% respectively relative to the prior state-of-the-art Where2comm.
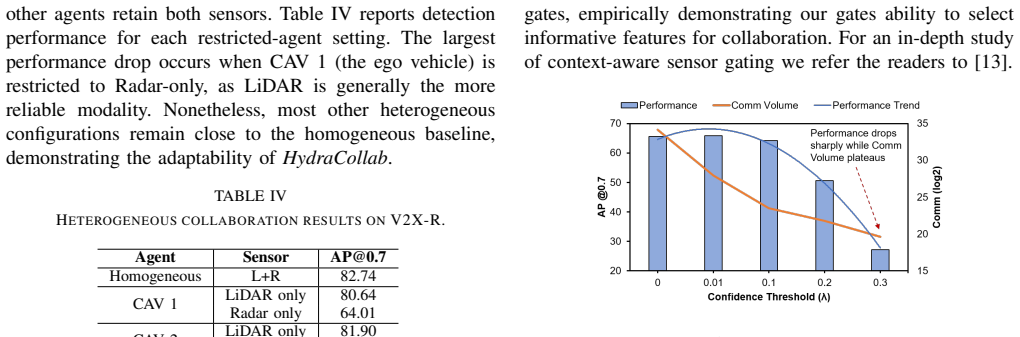
What carries the argument
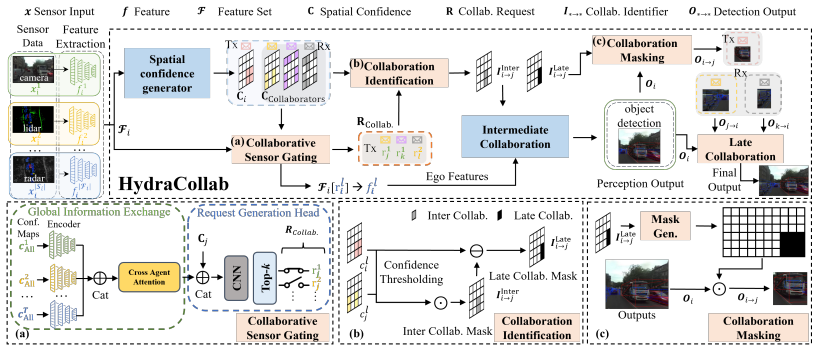
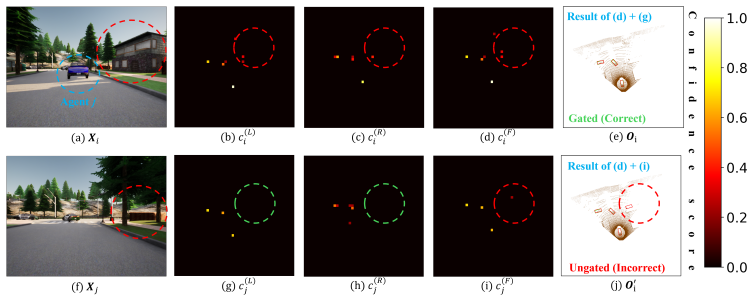
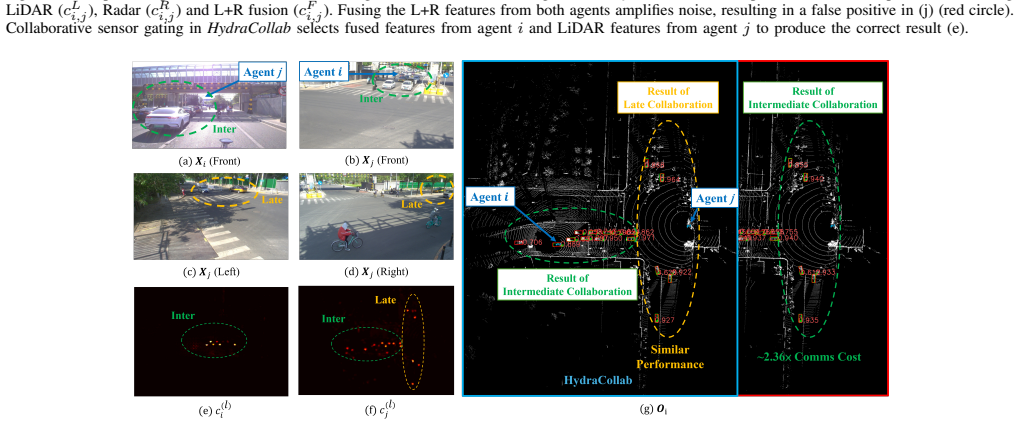
Spatial confidence maps derived from local features, which both identify the most informative data to transmit and select the collaboration strategy (intermediate versus late).
If this is right
- Multi-robot teams can sustain high situational awareness under tighter network constraints than previously feasible.
- Collaboration mode adapts automatically to local scene content rather than remaining fixed across all situations.
- The same mechanism produces measurable gains on both vehicle-to-everything and UAV perception benchmarks.
- Overall system scalability increases because communication volume no longer grows linearly with team size or sensor resolution.
Where Pith is reading between the lines
- The selective transmission pattern may extend to additional modalities such as lidar with only modest changes to the map-generation step.
- Lower data exchange could reduce end-to-end latency enough to support tighter closed-loop control in safety-critical tasks.
- In very large swarms the cumulative bandwidth savings could enable coordination scales that fixed high-bandwidth methods cannot reach.
Load-bearing premise
Spatial confidence maps derived from local features can reliably identify both the most informative data to transmit and the appropriate collaboration strategy without introducing systematic errors that degrade perception in unseen environments.
What would settle it
A controlled experiment on a new dataset with different sensor placements or environmental conditions in which HydraCollab either loses its bandwidth advantage or falls below the accuracy of a non-adaptive baseline.
Figures

read the original abstract
Collaborative-perception enables multi-robot systems to enhance situational awareness by sharing perceptual information. Existing collaborative-perception systems face an inherent trade-off between communication bandwidth requirements and perception accuracy, where methods that exchange more information achieve better perception results at the cost of increased communication overhead. However, real-world communication networks impose bandwidth constraints that require minimizing communication overhead without sacrificing perception performance. To address this challenge, we propose HydraCollab, an adaptive collaborative-perception framework that (i) selectively transmits the most informative sensor features and (ii) dynamically employs collaboration strategies (intermediate or late) based on spatial confidence maps. Extensive evaluations on the V2X-R, V2X-Radar and UAV3D-mini datasets demonstrate that HydraCollab achieves the best overall trade-off between accuracy and communication cost among existing collaborative-perception methods. Relative to SOTA Where2comm, HydraCollab uses only 41% of the bandwidth on V2X-R and 26% on V2X-Radar while improving performance by 0.78% and 0.75% respectively. Our code and models are available at https://github.com/AICPS/HydraCollab.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HydraCollab, an adaptive collaborative-perception framework for distributed autonomous systems. It derives spatial confidence maps from local sensor features to (i) selectively transmit only the most informative features and (ii) dynamically switch between intermediate and late fusion strategies. On the V2X-R, V2X-Radar and UAV3D-mini datasets the method is reported to achieve the best accuracy–communication trade-off, using 41 % and 26 % of the bandwidth of Where2comm while improving detection performance by 0.78 % and 0.75 % respectively.
Significance. If the adaptive policy generalizes, the framework could reduce communication overhead in bandwidth-constrained multi-robot deployments without sacrificing perception accuracy. The empirical comparisons on three public datasets and the public release of code are positive for reproducibility, but the absence of error bars, ablations, and out-of-distribution tests limits the strength of the central claim.
major comments (3)
- [Abstract] Abstract: the headline performance deltas (0.78 % / 0.75 %) and bandwidth reductions (41 % / 26 %) are presented without error bars, statistical significance tests, or any description of how post-hoc dataset splits or thresholds were chosen; this directly undermines the claim that HydraCollab achieves a reliably superior trade-off.
- [Method] Method (spatial confidence map construction): the central adaptive mechanism rests on the assumption that local-feature-derived confidence maps correctly identify both which features to transmit and whether to use intermediate vs. late collaboration; no cross-domain, occlusion, or distribution-shift experiments are reported to test this assumption, leaving open the possibility that the reported gains are dataset-specific.
- [Experiments] Experiments: the manuscript provides no ablation isolating the contribution of the dynamic collaboration-strategy selector versus the feature-selection component alone, making it impossible to determine which element drives the claimed bandwidth savings.
minor comments (2)
- [Abstract] The GitHub link for code and models is provided, which supports reproducibility.
- [Method] Notation for the spatial confidence map and the intermediate/late decision rule should be introduced with explicit equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance deltas (0.78 % / 0.75 %) and bandwidth reductions (41 % / 26 %) are presented without error bars, statistical significance tests, or any description of how post-hoc dataset splits or thresholds were chosen; this directly undermines the claim that HydraCollab achieves a reliably superior trade-off.
Authors: We agree that the abstract would be strengthened by statistical context. In the revision we will report standard deviations over multiple runs for the key metrics and add a concise reference to the evaluation protocol. Full statistical tests and split details will be expanded in the Experiments section. revision: yes
-
Referee: [Method] Method (spatial confidence map construction): the central adaptive mechanism rests on the assumption that local-feature-derived confidence maps correctly identify both which features to transmit and whether to use intermediate vs. late collaboration; no cross-domain, occlusion, or distribution-shift experiments are reported to test this assumption, leaving open the possibility that the reported gains are dataset-specific.
Authors: The three evaluated datasets already span distinct sensor modalities and environments. We will add an explicit limitations paragraph acknowledging the lack of dedicated distribution-shift or occlusion tests and listing this as future work. New experiments cannot be completed within the revision window. revision: partial
-
Referee: [Experiments] Experiments: the manuscript provides no ablation isolating the contribution of the dynamic collaboration-strategy selector versus the feature-selection component alone, making it impossible to determine which element drives the claimed bandwidth savings.
Authors: We will add the requested ablation study comparing the full model against ablated versions that disable either the dynamic selector or the feature-selection module, thereby quantifying each component's contribution to bandwidth reduction. revision: yes
- Explicit cross-domain, occlusion, and distribution-shift experiments to further validate the confidence-map assumption.
Circularity Check
No circularity: empirical comparisons on public datasets
full rationale
The manuscript describes an adaptive framework evaluated through direct empirical comparisons against prior methods (e.g., Where2comm) on the V2X-R, V2X-Radar, and UAV3D-mini datasets. No derivation chain, equations, or fitted parameters are shown that reduce to inputs by construction. Claims rest on measured accuracy-bandwidth trade-offs rather than self-referential definitions or load-bearing self-citations. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Collaborative perception in autonomous driving: Methods, datasets, and challenges,
Y . Han, H. Zhang, H. Li, Y . Jin, C. Lang, and Y . Li, “Collaborative perception in autonomous driving: Methods, datasets, and challenges,” IEEE Intelligent Transportation Systems Magazine, vol. 15, no. 6, pp. 131–151, 2023
2023
-
[2]
V2x-r: Cooperative lidar-4d radar fusion with denoising diffusion for 3d object detection,
X. Huanget al., “V2x-r: Cooperative lidar-4d radar fusion with denoising diffusion for 3d object detection,” inProceedings of the computer vision and pattern recognition conference, 2025, pp. 27 390– 27 400
2025
-
[3]
V2x-radar: A multi-modal dataset with 4d radar for cooperative perception,
L. Yanget al., “V2x-radar: A multi-modal dataset with 4d radar for cooperative perception,”Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[4]
Uav3d: A large-scale 3d perception benchmark for unmanned aerial vehicles,
H. Ye, R. Sunderraman, and S. Ji, “Uav3d: A large-scale 3d perception benchmark for unmanned aerial vehicles,” inThe 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[5]
Car2x- based perception in a high-level fusion architecture for cooperative perception systems,
A. Rauch, F. Klanner, R. Rasshofer, and K. Dietmayer, “Car2x- based perception in a high-level fusion architecture for cooperative perception systems,” in2012 IEEE Intelligent Vehicles Symposium. IEEE, 2012, pp. 270–275
2012
-
[6]
Collaborative automated driving: A machine learning-based method to enhance the accuracy of shared information,
Z. Y . Rawashdeh and Z. Wang, “Collaborative automated driving: A machine learning-based method to enhance the accuracy of shared information,” in2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 3961–3966
2018
-
[7]
Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,
Q. Chen, S. Tang, Q. Yang, and S. Fu, “Cooper: Cooperative percep- tion for connected autonomous vehicles based on 3d point clouds,” in 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2019, pp. 514–524
2019
-
[8]
Collaboration helps camera overtake lidar in 3d detection,
Y . Hu, Y . Lu, R. Xu, W. Xie, S. Chen, and Y . Wang, “Collaboration helps camera overtake lidar in 3d detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9243–9252
2023
-
[9]
Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,”Advances in Neural Information Processing Systems, vol. 35, pp. 4874–4886, 2022
2022
-
[10]
Who2com: Collaborative perception via learnable handshake com- munication,
Y .-C. Liu, J. Tian, C.-Y . Ma, N. Glaser, C.-W. Kuo, and Z. Kira, “Who2com: Collaborative perception via learnable handshake com- munication,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 6876–6883
2020
-
[11]
When2com: Multi-agent perception via communication graph grouping,
Y .-C. Liu, J. Tian, N. Glaser, and Z. Kira, “When2com: Multi-agent perception via communication graph grouping,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4106–4115
2020
-
[12]
An ex- tensible framework for open heterogeneous collaborative perception,
Y . Lu, Y . Hu, Y . Zhong, D. Wang, S. Chen, and Y . Wang, “An ex- tensible framework for open heterogeneous collaborative perception,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[13]
Hydrafusion: Context-aware selective sensor fusion for robust and efficient au- tonomous vehicle perception,
A. V . Malawade, T. Mortlock, and M. A. Al Faruque, “Hydrafusion: Context-aware selective sensor fusion for robust and efficient au- tonomous vehicle perception,” in2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS). IEEE, 2022, pp. 68–79
2022
-
[14]
Cobevt: Cooperative bird’s eye view semantic segmentation with sparse trans- formers,
R. Xu, Z. Tu, H. Xiang, W. Shao, B. Zhou, and J. Ma, “Cobevt: Cooperative bird’s eye view semantic segmentation with sparse trans- formers,” inConference on Robot Learning (CoRL), 2022
2022
-
[15]
Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2583–2589
2022
-
[16]
Comamba: Real-time cooperative perception unlocked with state-space models,
J. Liet al., “Comamba: Real-time cooperative perception unlocked with state-space models,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 16 993– 17 000
2025
-
[17]
Cocmt: Communication-efficient cross-modal transformer for collaborative perception,
R. Wang, X. Gao, H. Xiang, R. Xu, and Z. Tu, “Cocmt: Communication-efficient cross-modal transformer for collaborative perception,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2471–2478
2025
-
[18]
Coopre: Cooperative pretraining for v2x cooperative perception,
S. Z. Zhao, H. Xiang, C. Xu, X. Xia, B. Zhou, and J. Ma, “Coopre: Cooperative pretraining for v2x cooperative perception,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 11 765–11 772
2025
-
[19]
Learning distilled collaboration graph for multi-agent perception,
Y . Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang, “Learning distilled collaboration graph for multi-agent perception,” inThirty- fifth Conference on Neural Information Processing Systems (NeurIPS 2021), 2021
2021
-
[20]
Adaptive feature fusion for cooperative perception using lidar point clouds,
D. Qiao and F. Zulkernine, “Adaptive feature fusion for cooperative perception using lidar point clouds,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 1186–1195
2023
-
[21]
Sicp: Simultaneous individual and cooperative percep- tion for 3d object detection in connected and automated vehicles,
D. Quet al., “Sicp: Simultaneous individual and cooperative percep- tion for 3d object detection in connected and automated vehicles,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 8905–8912
2024
-
[22]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,” inEuropean conference on computer vision. Springer, 2022, pp. 107– 124
2022
-
[23]
Region-based hybrid collaborative perception for connected autonomous vehicles,
P. Liu, Z. Wang, G. Yu, B. Zhou, and P. Chen, “Region-based hybrid collaborative perception for connected autonomous vehicles,”IEEE Transactions on Vehicular Technology, vol. 73, no. 3, pp. 3119–3128, 2023
2023
-
[24]
L4dr: Lidar-4dradar fusion for weather-robust 3d object detection,
X. Huanget al., “L4dr: Lidar-4dradar fusion for weather-robust 3d object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3806–3814
2025
-
[25]
Hyperdimensional uncertainty quantification for multimodal uncer- tainty fusion in autonomous vehicles perception,
L. Chen, J. Wang, T. Mortlock, P. Khargonekar, and M. A. Al Faruque, “Hyperdimensional uncertainty quantification for multimodal uncer- tainty fusion in autonomous vehicles perception,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 306–22 316
2025
-
[26]
Vikienet: Towards efficient 3d object detection with virtual key instance enhanced network,
Z. Yu, B. Qiu, and A. W. Khong, “Vikienet: Towards efficient 3d object detection with virtual key instance enhanced network,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 844–11 853
2025
-
[27]
Interfusion: Interaction-based 4d radar and lidar fusion for 3d object detection,
L. Wanget al., “Interfusion: Interaction-based 4d radar and lidar fusion for 3d object detection,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 12 247– 12 253
2022
-
[28]
Opencda: an open cooperative driving automation framework integrated with co-simulation,
R. Xu, Y . Guo, X. Han, X. Xia, H. Xiang, and J. Ma, “Opencda: an open cooperative driving automation framework integrated with co-simulation,” in2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021, pp. 1155–1162
2021
-
[29]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inProceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16
2017
-
[30]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles,
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” inField and service robotics: Results of the 11th international conference. Springer, 2017, pp. 621–635
2017
-
[31]
F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds,
Q. Chen, X. Ma, S. Tang, J. Guo, Q. Yang, and S. Fu, “F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d point clouds,” inProceedings of the 4th ACM/IEEE Symposium on Edge Computing, 2019, pp. 88–100
2019
-
[32]
Robust collaborative 3d object detection in presence of pose errors,
Y . Luet al., “Robust collaborative 3d object detection in presence of pose errors,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 4812–4818
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.