Recognition: no theorem link
Miner:Mining Intrinsic Mastery for Data-Efficient RL in Large Reasoning Models
Pith reviewed 2026-05-16 16:32 UTC · model grok-4.3
The pith
Policy uncertainty serves as a self-supervised reward to fix zero-advantage waste in critic-free RL for reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
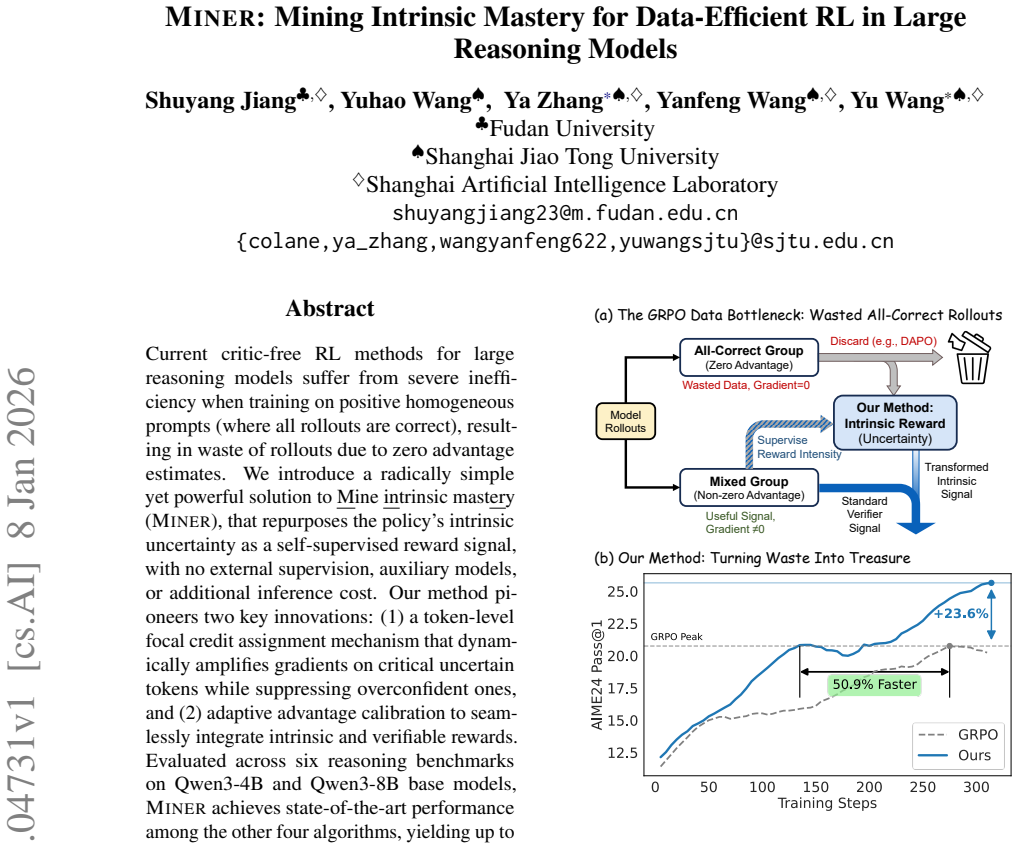
Miner repurposes the policy's intrinsic uncertainty as a self-supervised reward signal, with no external supervision, auxiliary models, or additional inference cost. It introduces token-level focal credit assignment that dynamically amplifies gradients on critical uncertain tokens while suppressing overconfident ones, together with adaptive advantage calibration to integrate intrinsic and verifiable rewards. Evaluated on Qwen3-4B and Qwen3-8B across six reasoning benchmarks, the approach yields up to 4.58 absolute gains in Pass@1 and 6.66 gains in Pass@K compared with GRPO, establishing that latent uncertainty exploitation is both necessary and sufficient for efficient and scalable RL of the
What carries the argument
Token-level focal credit assignment that amplifies gradients on uncertain tokens while suppressing overconfident ones, combined with adaptive advantage calibration to blend intrinsic uncertainty with verifiable rewards.
If this is right
- Rollout budgets on easy prompts are no longer wasted because uncertainty supplies non-zero advantage estimates.
- Training remains critic-free and incurs zero extra inference cost at every step.
- The same two innovations outperform other exploration-targeted methods on the reported benchmarks.
- The method scales from 4B to 8B base models without architectural changes.
- Performance gains appear consistently across six distinct reasoning benchmarks.
Where Pith is reading between the lines
- The same uncertainty signal could be applied in any sparse-reward RL setting where verifiable outcomes are infrequent.
- Combining focal credit assignment with other exploration bonuses might compound gains without new hyper-parameters.
- If uncertainty estimates become overconfident in later training stages, performance could plateau unless the calibration rule is updated.
- The approach opens a route to purely self-supervised RL loops that gradually reduce reliance on external verifiers.
Load-bearing premise
The policy's intrinsic uncertainty supplies a reliable and unbiased signal for credit assignment that mixes cleanly with verifiable rewards without introducing new biases or needing extra tuning.
What would settle it
Run the same training loop on a set of positive homogeneous prompts; if Miner produces no higher final Pass@1 or Pass@K than a plain GRPO baseline that receives zero advantage on every rollout, the central claim is false.
Figures












read the original abstract
Current critic-free RL methods for large reasoning models suffer from severe inefficiency when training on positive homogeneous prompts (where all rollouts are correct), resulting in waste of rollouts due to zero advantage estimates. We introduce a radically simple yet powerful solution to \uline{M}ine \uline{in}trinsic mast\uline{er}y (Miner), that repurposes the policy's intrinsic uncertainty as a self-supervised reward signal, with no external supervision, auxiliary models, or additional inference cost. Our method pioneers two key innovations: (1) a token-level focal credit assignment mechanism that dynamically amplifies gradients on critical uncertain tokens while suppressing overconfident ones, and (2) adaptive advantage calibration to seamlessly integrate intrinsic and verifiable rewards. Evaluated across six reasoning benchmarks on Qwen3-4B and Qwen3-8B base models, Miner achieves state-of-the-art performance among the other four algorithms, yielding up to \textbf{4.58} absolute gains in Pass@1 and \textbf{6.66} gains in Pass@K compared to GRPO. Comparison with other methods targeted at exploration enhancement further discloses the superiority of the two newly proposed innovations. This demonstrates that latent uncertainty exploitation is both necessary and sufficient for efficient and scalable RL training of reasoning models. Code is available at https://github.com/pixas/Miner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Miner, a critic-free RL method for large reasoning models that repurposes the policy's intrinsic uncertainty as a self-supervised reward signal to mitigate zero-advantage issues on positive homogeneous prompts. It introduces token-level focal credit assignment to dynamically amplify gradients on uncertain tokens and adaptive advantage calibration to integrate intrinsic and verifiable rewards. On Qwen3-4B and Qwen3-8B models across six reasoning benchmarks, Miner reports gains of up to 4.58 Pass@1 and 6.66 Pass@K over GRPO and three other exploration baselines, concluding that latent uncertainty exploitation is both necessary and sufficient for efficient and scalable RL training of reasoning models. Code is released.
Significance. If the empirical results hold under broader scrutiny, the approach could meaningfully advance data-efficient RL for reasoning models by avoiding auxiliary critics or extra inference. The open-sourced code is a clear strength for reproducibility. The sufficiency claim within the tested regime is plausible given the reported gains, but the necessity direction requires additional support beyond the four-algorithm comparison.
major comments (3)
- [Abstract] Abstract: The statement that the results 'demonstrate that latent uncertainty exploitation is both necessary and sufficient' is not supported by the evidence. The experiments compare Miner only to GRPO plus three exploration-targeted baselines; this can support sufficiency in the tested setting but does not establish necessity, as alternative credit-assignment schemes (entropy bonuses, prompt-level diversity, or learned critics) are not evaluated or ruled out.
- [Experiments] Experiments section: The absolute gains (4.58 Pass@1, 6.66 Pass@K) are reported without standard deviations, number of independent runs, or statistical significance tests. This weakens confidence in the superiority claims and the cross-benchmark conclusions.
- [Method] Method description: The focal amplification thresholds and adaptive calibration weights are free parameters. No sensitivity analysis or ablation isolating their contribution is provided, which undercuts the claim that the method is 'radically simple' with no extensive hyperparameter tuning.
minor comments (2)
- [Abstract] Abstract: The method-name description contains a visible LaTeX artifact (uline); this should be cleaned for the final version.
- [Method] Method: Explicit equations or pseudocode for the token-level focal credit assignment and adaptive advantage calibration would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and have prepared revisions to the manuscript where the feedback identifies areas for improvement.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that the results 'demonstrate that latent uncertainty exploitation is both necessary and sufficient' is not supported by the evidence. The experiments compare Miner only to GRPO plus three exploration-targeted baselines; this can support sufficiency in the tested setting but does not establish necessity, as alternative credit-assignment schemes (entropy bonuses, prompt-level diversity, or learned critics) are not evaluated or ruled out.
Authors: We agree that the current experiments establish sufficiency relative to the four compared methods but do not rule out all alternative credit-assignment approaches, so the necessity claim is not fully supported. We will revise the abstract to state that the results demonstrate sufficiency for efficient and scalable RL training within the evaluated regime, while noting that broader comparisons would be required to strengthen any necessity argument. revision: yes
-
Referee: [Experiments] Experiments section: The absolute gains (4.58 Pass@1, 6.66 Pass@K) are reported without standard deviations, number of independent runs, or statistical significance tests. This weakens confidence in the superiority claims and the cross-benchmark conclusions.
Authors: This is a valid observation. The current manuscript reports point estimates only. In the revised version we will report standard deviations across multiple independent runs (at least three random seeds per setting), specify the number of runs, and include statistical significance tests (e.g., paired t-tests) for the key comparisons to increase confidence in the reported gains. revision: yes
-
Referee: [Method] Method description: The focal amplification thresholds and adaptive calibration weights are free parameters. No sensitivity analysis or ablation isolating their contribution is provided, which undercuts the claim that the method is 'radically simple' with no extensive hyperparameter tuning.
Authors: The thresholds and weights are set once via a simple quantile-based heuristic on a small validation subset and then held fixed across all six benchmarks and both model sizes, which is consistent with limited tuning. Nevertheless, we accept that an explicit sensitivity study and ablation isolating each component would strengthen the simplicity claim. We will add both a sensitivity table and component-wise ablations to the revised manuscript. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines Miner by repurposing the policy's intrinsic uncertainty as a self-supervised reward signal and introduces two explicit mechanisms (token-level focal credit assignment and adaptive advantage calibration) that are combined with verifiable external rewards. These steps are presented as algorithmic innovations without any equation or derivation reducing the final advantage estimate to a fitted parameter or input by construction. The necessity-and-sufficiency claim rests on empirical benchmark comparisons rather than a mathematical chain that loops back to the method's own definitions. No self-citation load-bearing step, uniqueness theorem, or ansatz smuggling appears in the derivation; the approach remains self-contained against external benchmarks and falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
free parameters (2)
- focal amplification thresholds
- adaptive calibration weights
axioms (1)
- standard math Policy gradient updates remain valid when rewards are augmented by internal uncertainty estimates
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Towards medical complex reasoning with LLMs through medical verifiable problems. InFind- ings of the Association for Computational Linguistics: ACL 2025, pages 14552–14573, Vienna, Austria. As- sociation for Computational Linguistics. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burd...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Reasoning with exploration: An entropy per- spective.arXiv preprint arXiv:2506.14758. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The Entropy Mechanism of Rein- forcement Learning for Reasoni...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Fei, W., Kong, H., Liang, S., Lin, Y ., Yang, Y ., Tang, J., Chen, L., and Hua, X
Self-guided process reward optimization with masked step advantage for process reinforcement learning.arXiv preprint arXiv:2507.01551. Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. 2025. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307....
-
[4]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models.arXiv preprint arXiv:2501.03262. Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. 2025. Vcrl: Variance-based curriculum rein- forcement learning for large language models.arXiv preprint arXiv:2509.19803. Di Jin, Eileen P...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Understanding R1-Zero-Like Training: A Critical Perspective
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. 2017. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision (ICCV). Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Cha...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
InThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems
Improving data efficiency for LLM reinforce- ment fine-tuning through difficulty-targeted online data selection and rollout replay. InThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems. Leitian Tao, Ilia Kulikov, Swarnadeep Saha, Tianlu Wang, Jing Xu, Sharon Li, Jason E Weston, and Ping Yu. 2025. Hybrid reinforcement: When re- w...
-
[7]
We use 4xA100 GPUs to train the OctoThinker-8B- Hybrid-Base for 7 days
Computational Cards:We use 4xA100 GPUs to train the Qwen3-4B-Base and Llama3.1-8B-Instruct for 4 days. We use 4xA100 GPUs to train the OctoThinker-8B- Hybrid-Base for 7 days. We use 8xA100 GPUs to train the Qwen3-8B-Base for 3 days
-
[8]
Code:We attach the implementation code in the supplementary materials
-
[9]
Data:All the dataset is officially available through their released links. B Related Work This appendix complements the preliminary discus- sion in §2 by positioning our study in the broader landscape of (i) data-efficient policy optimization under sparse/binary outcome rewards, (ii) prior at- tempts to resolve the diminishing-advantage phe- nomenon induc...
work page 1992
-
[10]
stabilizes updates via clipped importance ratios and KL regularization (Kullback and Leibler, 1951). GRPO (Shao et al., 2024) adapts PPO-style updates to a group sampling scheme by estimating advantages from the relative reward statistics within a set of rollouts generated from the same prompt. This design eliminates a learned value critic and is thus mem...
work page 1951
-
[11]
augment correctness with proper scoring- rule–based rewards so the model learns to output calibrated confidence alongside answers. However, the first two paradigms overlook the advantage shaping of PH trajectories and fail to utilize them, while calibrated methods destroy the objective of the maximization of correctness, and achieve bad performance compar...
-
[12]
Each dataset contains 30 challenging problems covering Algebra/Ge- ometry/Number theory
AIME2024, AIME2025(Mathematical Associ- ation of America, 2025a,b): These two datasets contain High school Olympiad-level assessment from American Invitational Mathematics Exam- ination in 2024 and 2025. Each dataset contains 30 challenging problems covering Algebra/Ge- ometry/Number theory
work page 2024
-
[13]
AMC23(AI-MO, 2024): This dataset is sourced from American Mathematics Competitions sys- tem in 2023, which contains 40 problems with hybrid question types
work page 2024
-
[14]
OlympiadBench(He et al., 2024): This dataset contains comprehensive math Olympiad prob- lems from various nations. We only select the English version related to Math and keep the problems that require an answer with a number, leaving 581 problems for evaluation in total
work page 2024
-
[15]
MATH500(Lightman et al., 2023): This dataset is an advanced mathematics evaluation set cu- rated by OpenAI containing 500 problems with formal mathematical notations
work page 2023
-
[16]
30 questions were extracted, converted to LaTeX and verified
HMMT25(Balunovi ´c et al., 2025): The orig- inal questions were sourced from the HMMT February 2025 competition. 30 questions were extracted, converted to LaTeX and verified. C.2 Descriptions of Medical Testbeds We present the detailed description of the medical evaluation datasets as follows: 13 Model AIME2024 AIME2025 AMC23 HMMT25 MATH OlympiadB. Avg. P...
-
[17]
We adopt its 5-options English version, taking the 1,273 test problems as the evaluation benchmark
MedQA(Jin et al., 2021) is a widely used bench- mark for evaluating AI systems in medical ques- tion answering, featuring multiple-choice ques- tions from professional medical licensing exams such as the USMLE and exams from China and Taiwan. We adopt its 5-options English version, taking the 1,273 test problems as the evaluation benchmark
work page 2021
-
[18]
It focuses on yes/no/- maybe questions that require reasoning over biomedical literature
PubmedQA(Jin et al., 2019) is a specialized benchmark for biomedical question answer- ing, consisting of question-answer pairs derived from PubMed abstracts. It focuses on yes/no/- maybe questions that require reasoning over biomedical literature. We use the human-labeled question test set, with 500 problems for evalu- ation. Note that we include relevant...
work page 2019
-
[19]
MedMCQA(Pal et al., 2022) is a large-scale benchmark for medical question answering, fea- turing over 194,000 multiple-choice questions sourced from Indian medical entrance exams and other educational resources. It spans a wide range of medical topics, including anatomy, pharmacology, and pathology, and is designed to evaluate the reasoning and knowledge ...
work page 2022
-
[20]
MMLU-Pro(Wang et al., 2024) is a chal- lenging multi-task benchmark containing over 12,000 multiple-choice questions across 14 di- verse domains, including subjects in STEM (e.g., math, physics, chemistry), social sciences, law, and humanities. We only maintain health and biology subsets for testing medical reason- ing abilities, which includes 1535 problems
work page 2024
-
[21]
Please reason step by step and output the final answer as ‘The answer is’
MedXpertQA(Zuo et al., 2025) is an expert- level medical benchmark comprising 4,460 questions spanning 17 medical specialties and 11 body systems. It includes two subsets: a text-only version for evaluating textual medi- cal reasoning and a multimodal version (MM) with images, aimed at assessing advanced clini- cal knowledge comparable to medical licensin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.