Recognition: 1 theorem link
· Lean TheoremAgentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
Pith reviewed 2026-05-16 11:17 UTC · model grok-4.3
The pith
Analysis of 14 million agentic search sessions shows 54% of new query terms come from prior evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
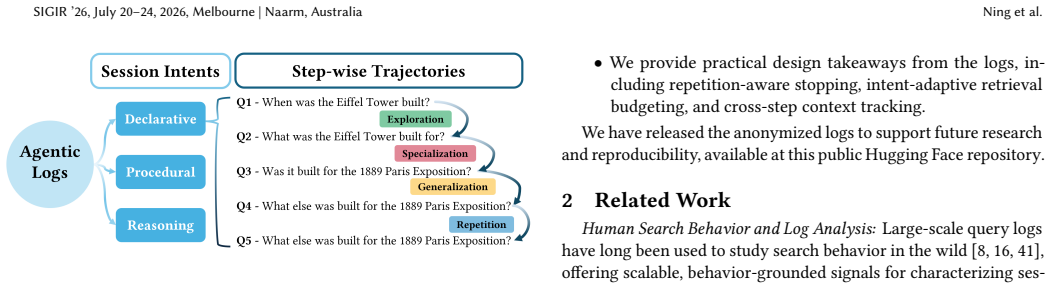
The paper establishes that query reformulations in agentic search are substantially driven by retrieved evidence, with 54% of newly introduced terms on average appearing in the accumulated context from previous steps. It further identifies that fact-seeking sessions show rising repetition over time while reasoning sessions sustain wider exploration, and that over 90% of sessions have at most ten steps with most intervals under one minute. These patterns are derived from sessionizing logs and applying annotations to quantify term adoption and intent variations.
What carries the argument
Context-driven Term Adoption Rate (CTAR), the metric used to determine the lexical traceability of new query terms back to the body of evidence gathered across retrieval steps.
If this is right
- Repetition patterns can serve as signals for developing stopping criteria tailored to different session intents.
- Retrieval strategies can be made adaptive by allocating resources according to whether a session is fact-seeking or requires reasoning.
- Maintaining and tracking evidence context across steps enables better support for query reformulation in agents.
- Insights from session dynamics support the creation of repetition-aware and intent-adaptive search mechanisms.
Where Pith is reading between the lines
- These findings imply that evaluation of search agents should incorporate metrics for context utilization and term traceability rather than relying solely on end-task success.
- Agent designs could benefit from mechanisms that explicitly surface or highlight evidence sources to improve reformulation quality.
- Extending the analysis to include the impact of different retrieval qualities on these patterns could reveal additional levers for optimization.
Load-bearing premise
The LLM-based annotation process for determining session intents and step-wise query reformulation labels accurately reflects the actual behaviors without substantial misclassification.
What would settle it
A controlled experiment where human annotators independently label a sample of sessions for intents and term origins, then compare agreement rates with the automated labels, would confirm or refute the reliability of the discovered patterns.
Figures





read the original abstract
LLM-powered search agents are increasingly being used for multi-step information seeking tasks, yet the IR community lacks empirical understanding of how agentic search sessions unfold and how retrieved evidence is reflected in later queries. This paper presents a large-scale log analysis of agentic search based on 14.44M search requests (3.97M sessions) collected from DeepResearchGym, i.e., an open-source search API accessed by external agentic clients. We sessionize the logs, assign session-level intents and step-wise query-reformulation labels using LLM-based annotation, and propose Context-driven Term Adoption Rate (CTAR) to quantify whether newly introduced query terms are lexically traceable to previously retrieved evidence. Our analyses reveal distinctive behavioral patterns. First, over 90\% of multi-turn sessions contain at most ten steps, and 89\% of inter-step intervals fall under one minute. Second, behavior varies by intent. Fact-seeking sessions exhibit high repetition that increases over time, while sessions requiring reasoning sustain broader exploration. Third, query reformulations are often traceable to retrieved evidence across steps. On average, 54\% of newly introduced query terms appear in the accumulated evidence context, with additional traceability to earlier steps beyond the most recent retrieval. These findings provide candidate signals for repetition-aware stopping, intent-adaptive retrieval budgeting, and explicit cross-step context tracking. We released the anonymized logs, making them available at a public HuggingFace~\chref{https://huggingface.co/datasets/cx-cmu/deepresearchgym-agentic-search-logs}{repository}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 14.44M search requests across 3.97M sessions from the DeepResearchGym open API logs. It applies LLM-based annotation to label session-level intents and step-wise query reformulations, introduces the Context-driven Term Adoption Rate (CTAR) metric to measure lexical traceability of new query terms to accumulated retrieved evidence, and reports empirical patterns including short session lengths (over 90% of multi-turn sessions have at most 10 steps), sub-minute inter-step intervals (89%), intent-dependent behaviors (high repetition in fact-seeking vs. broader exploration in reasoning sessions), and an average 54% traceability rate for newly introduced terms, with some traceability extending beyond the most recent retrieval. The anonymized logs are released publicly.
Significance. If the LLM annotations prove reliable, the work delivers a valuable large-scale observational characterization of real-world agentic search trajectories that is rare in the IR literature. The public dataset release and concrete signals for repetition-aware stopping and intent-adaptive retrieval budgeting constitute concrete contributions that can directly inform agent design and evaluation.
major comments (2)
- [§3 (Annotation and Labeling Pipeline)] §3 (Annotation and Labeling Pipeline): The central 54% CTAR figure is computed from LLM-assigned reformulation labels that identify 'new' terms and define the evidence context, yet the manuscript reports no inter-annotator agreement, human validation subset, or sensitivity analysis on these labels. Any systematic bias in the LLM annotator directly affects both numerator and denominator of CTAR, rendering the quantitative claim unverifiable from the provided text.
- [§4.3 (CTAR Definition and Computation)] §4.3 (CTAR Definition and Computation): The precise operational definition of 'accumulated evidence context' (whether it includes only retrieved passages, prior queries, or both) and the exact procedure for determining term novelty across steps are not fully specified. Without this, it is impossible to reproduce or assess the reported 54% average and the claim of traceability to earlier steps.
minor comments (1)
- [Abstract] The abstract states that logs are released at a Hugging Face repository but does not include the exact dataset identifier or citation format, which would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and commit to revisions that improve the clarity and verifiability of the work without altering its core claims.
read point-by-point responses
-
Referee: §3 (Annotation and Labeling Pipeline): The central 54% CTAR figure is computed from LLM-assigned reformulation labels that identify 'new' terms and define the evidence context, yet the manuscript reports no inter-annotator agreement, human validation subset, or sensitivity analysis on these labels. Any systematic bias in the LLM annotator directly affects both numerator and denominator of CTAR, rendering the quantitative claim unverifiable from the provided text.
Authors: We agree that the absence of reported validation metrics for the LLM annotations is a limitation that affects confidence in the CTAR results. In the revised version we will add a human validation study on a stratified random sample of 1,000 sessions (balanced across intents), with two independent human annotators. We will report Cohen's kappa for inter-annotator agreement between humans and between humans and the LLM, plus a sensitivity analysis that varies the LLM prompt template and model temperature. These additions will directly support the reliability of the 54% figure. revision: yes
-
Referee: §4.3 (CTAR Definition and Computation): The precise operational definition of 'accumulated evidence context' (whether it includes only retrieved passages, prior queries, or both) and the exact procedure for determining term novelty across steps are not fully specified. Without this, it is impossible to reproduce or assess the reported 54% average and the claim of traceability to earlier steps.
Authors: We acknowledge that the current description in §4.3 leaves room for ambiguity. The accumulated evidence context is strictly the concatenation of all retrieved passages (not prior queries) up to and including the current step; term novelty is operationalized by tokenizing queries with the same tokenizer used for passage indexing and checking whether a token appears in the current query but not in any prior query. Traceability is measured by exact lexical match (case-insensitive) within the evidence context. In the revision we will insert explicit pseudocode, a formal definition of the context window, and an example walkthrough of a three-step session to make the 54% computation fully reproducible. revision: yes
Circularity Check
No circularity: purely observational log analysis with defined metric
full rationale
The paper conducts empirical analysis on 14.44M search requests by sessionizing logs, applying LLM annotation for intents and reformulation labels, defining the CTAR metric as the proportion of new query terms traceable to accumulated evidence, and reporting observed statistics (e.g., 54% average). No derivations, equations, fitted parameters presented as predictions, or self-citation chains reduce any reported result to the inputs by construction. The 54% figure is a direct computation on the annotated data using the explicitly defined metric, not a tautology or forced outcome. This is a standard empirical study with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based annotation reliably identifies session-level intents and step-wise query-reformulation labels
invented entities (1)
-
Context-driven Term Adoption Rate (CTAR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce CTAR, a metric for quantifying evidence-conditioned query evolution... CTAR(·)_k = |NewTerms(q_{k+1}, q_k) ∩ C(·)_k| / |NewTerms(q_{k+1}, q_k)|
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Eugene Agichtein, Eric Brill, and Susan Dumais. 2006. Improving web search ranking by incorporating user behavior information. InInternational Conference on Research and Development in Information Retrieval (SIGIR)
work page 2006
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[3]
InInternational Conference on Learning Representations (ICLR)
Self-RAG: Learning to Retrieve, Generate, and Critique through Self- Reflection. InInternational Conference on Learning Representations (ICLR)
-
[4]
Paolo Boldi, Francesco Bonchi, Carlos Castillo, and Sebastiano Vigna. 2011. Query reformulation mining: models, patterns, and applications.Information Retrieval
work page 2011
-
[5]
Andrei Broder. 2002. A taxonomy of web search.SIGIR Forum
work page 2002
-
[6]
Aaron Brown and Matt Saner. 2025. The Agentic AI Security Scoping Matrix: A framework for securing autonomous AI systems. AWS Security Blog. Published: 21 Nov 2025. Accessed: 29 Dec 2025. (2025). https://aws.amazon.com/cn/blogs /security/the-agentic-ai-security-scoping-matrix-a-framework-for-securin g-autonomous-ai-systems/
work page 2025
-
[7]
Wei-Lin Chiang et al. 2024. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. (2024). arXiv: 2403.04132
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
-
[9]
Russell, Diane Tang, and Jaime Teevan
Susan Dumais, Robin Jeffries, Daniel M. Russell, Diane Tang, and Jaime Teevan
-
[10]
Understanding User Behavior Through Log Data and Analysis.Ways of Knowing in HCI
-
[11]
Carsten Eickhoff, Sebastian Dungs, and Vu Tran. 2015. An Eye-Tracking Study of Query Reformulation. InConference on Research and Development in Infor- mation Retrieval (SIGIR)
work page 2015
-
[12]
Carsten Eickhoff, Jaime Teevan, Ryen White, and Susan Dumais. 2014. Lessons from the Journey: A Query Log Analysis of Within-session Learning. InInter- national Conference on Web Search and Data Mining (WSDM)
work page 2014
-
[13]
Feild, James Allan, and Rosie Jones
Henry A. Feild, James Allan, and Rosie Jones. 2010. Predicting Searcher Frus- tration. InInternational Conference on Research and Development in Information Retrieval (SIGIR)
work page 2010
-
[14]
Steve Fox, Kuldeep Karnawat, Mark Mydland, Susan Dumais, and Thomas White. 2005. Evaluating implicit measures to improve web search.ACM Trans- actions on Information Systems
work page 2005
-
[15]
Google. 2025. Gemini 3 Developer Guide (model id: gemini-3-flash-preview). Google AI for Developers Documentation. Gemini 3 models in preview; model IDs listed in documentation. (2025). Retrieved Jan. 18, 2026 from https://ai.goo gle.dev/gemini-api/docs/gemini-3
work page 2025
- [16]
-
[17]
Jeff Huang and Efthimis N. Efthimiadis. 2009. Analyzing and evaluating query reformulation strategies in web search logs. InConference on Information and Knowledge Management (CIKM)
work page 2009
-
[18]
Jansen, Amanda Spink, Judy Bateman, and Tefko Saracevic
Bernard J. Jansen, Amanda Spink, Judy Bateman, and Tefko Saracevic. 1998. Real life information retrieval: a study of user queries on the web.SIGIR Forum
work page 1998
-
[19]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravis- hankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Processing Systems
work page 2019
-
[20]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[21]
InConference of the North American Chapter of the Association for Computational Linguistics (NAACL)
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InConference of the North American Chapter of the Association for Computational Linguistics (NAACL)
- [22]
-
[23]
Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke, and Geri Gay. 2005. Accurately interpreting clickthrough data as implicit feedback. In International Conference on Research and Development in Information Retrieval (SIGIR)
work page 2005
-
[24]
Rosie Jones and Kristina Lisa Klinkner. 2008. Beyond the session timeout: au- tomatic hierarchical segmentation of search topics in query logs. InConference on Information and Knowledge Management (CIKM)
work page 2008
-
[25]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. (2020). arXiv: 2004.04906
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. 2025. Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generatio. InConference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL)
work page 2025
-
[27]
Ido Levy, Ben wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov
-
[28]
InWorkshop on Computer Use Agents (ICML)
ST-WebAgentBench: A Benchmark for Evaluating Safety and Trustwor- thiness in Web Agents. InWorkshop on Computer Use Agents (ICML)
-
[29]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. (2024). arXiv: 2412.05579
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilac- qua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilac- qua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics
work page 2024
-
[31]
Xiao Liu et al. 2023. AgentBench: Evaluating LLMs as Agents. (2023). arXiv: 2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Gary Marchionini. 2006. Exploratory search: from finding to understanding. Communications of the ACM
work page 2006
-
[33]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA: a benchmark for General AI Assistants. (2023). arXiv: 2311.12983
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Reiichiro Nakano et al. 2022. WebGPT: Browser-assisted question-answering with human feedback. (2022). arXiv: 2112.09332
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Lunyiu Nie, Nedim Lipka, Ryan A. Rossi, and Swarat Chaudhuri. 2025. FlashRe- search: Real-time Agent Orchestration for Efficient Deep Research. (2025). arXiv: 2510.05145
-
[36]
OpenAI. 2025. GPT-5 nano Model. OpenAI API Documentation. Accessed: 2025-12-29. (2025). https://platform.openai.com/docs/models/gpt-5-nano
work page 2025
-
[37]
OpenAI. 2025. How People Use ChatGPT. Tech. rep. OpenAI
work page 2025
- [38]
-
[39]
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Mar- garet Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. (2024). arXiv: 2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Long Phan, Alice Gatti, Ziwen Han, et al. 2025. Humanity’s Last Exam. (2025). https://arxiv.org/abs/2501.14249 arXiv: 2501.14249
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Yujia Qin et al. 2023. ToolLLM: facilitating large language models to master 16,000+ real-world APIs. (2023). arXiv: 2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Soo Young Rieh, Kevyn Collins-Thompson, Preben Hansen, and Hye-Jung Lee
-
[43]
Towards searching as a learning process: a review of current perspectives and future directions.Journal of Information Science
-
[44]
Daniel E. Rose and Danny Levinson. 2004. Understanding user goals in web search. InInternational Conference on World Wide Web (WWW)
work page 2004
-
[45]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. (2023). arXiv: 2302.047 61
work page 2023
-
[46]
Craig Silverstein, Hannes Marais, Monika Henzinger, and Michael Moricz. 1999. Analysis of a very large web search engine query log.SIGIR Forum
work page 1999
-
[47]
Jaime Teevan, Eytan Adar, Rosie Jones, and Michael A. S. Potts. 2007. Informa- tion re-retrieval: repeat queries in yahoo’s logs. InConference on Research and Development in Information Retrieval (SIGIR)
work page 2007
-
[48]
Jaime Teevan, Christine Alvarado, Mark S. Ackerman, and David R. Karger
-
[49]
InConference on Human Factors in Computing Systems (CHI)
The perfect search engine is not enough: a study of orienteering behavior in directed search. InConference on Human Factors in Computing Systems (CHI)
-
[50]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[51]
InAnnual Meeting of the Association for Com- putational Linguistics (ACL)
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InAnnual Meeting of the Association for Com- putational Linguistics (ACL)
-
[52]
Kelsey Urgo and Jaime Arguello. 2022. Learning assessments in search-as- learning: a survey of prior work and opportunities for future research.Infor- mation Processing and Management
work page 2022
- [53]
- [54]
-
[55]
Ryen W. White and Steven M. Drucker. 2007. Investigating behavioral variabil- ity in web search. InInternational Conference on World Wide Web (WWW)
work page 2007
-
[56]
Jialong Wu et al. 2025. WebWalker: Benchmarking LLMs in Web Traversa. In Annual Meeting of the Association for Computational Linguistics
work page 2025
-
[57]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. Web- Shop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. InInternational Conference on Neural Information Processing Systems (NeurIPS)
work page 2022
-
[58]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. (2023). arXiv: 2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Yanzhao Zhang et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. (2025). arXiv: 2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [60]
-
[61]
Lianmin Zheng et al. 2023. Judging LLM-as-a-judge with MT-bench and Chatbot Arena. InInternational Conference on Neural Information Processing Systems (NeurIPS)
work page 2023
-
[62]
Lianmin Zheng et al. 2024. LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset. InInternational Conference on Learning Representations (ICLR)
work page 2024
-
[63]
Jianan Zhou, Fleur Corbett, Joori Byun, Talya Porat, and Nejra van Zalk. 2025. Psychological and behavioural responses in human-agent vs. human-human interactions: a systematic review and meta-analysis. (2025). arXiv: 2509.21542
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Shuyan Zhou et al. 2023. Webarena: a realistic web environment for building autonomous agents. (2023). arXiv: 2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.