When Iterative RAG Beats Ideal Evidence: A Diagnostic Study in Scientific Multi-hop Question Answering
Pith reviewed 2026-05-16 10:28 UTC · model grok-4.3
The pith
Iterative retrieval-reasoning loops outperform supplying all ideal evidence at once for multi-hop scientific questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
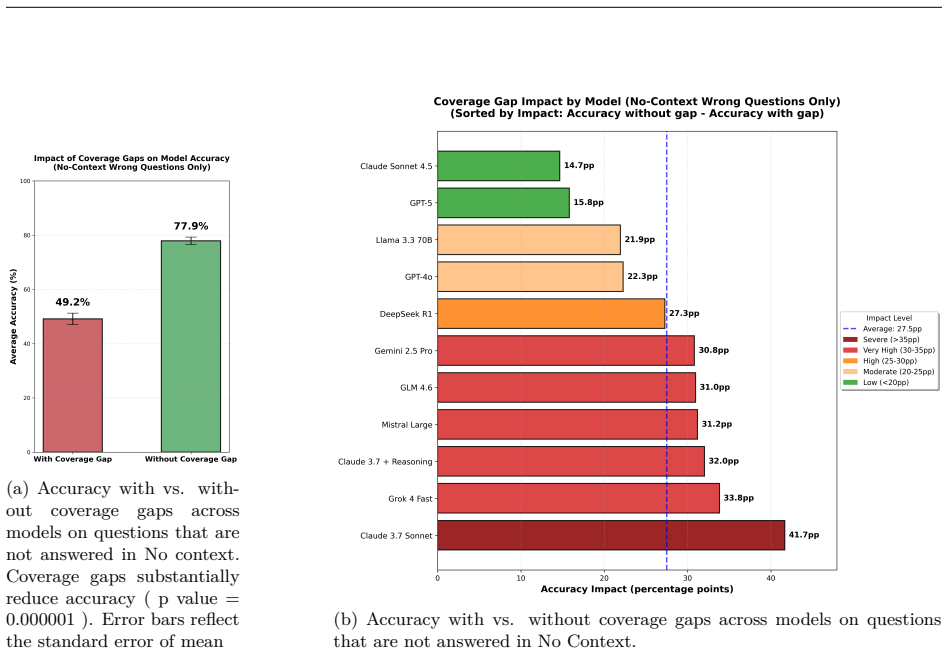
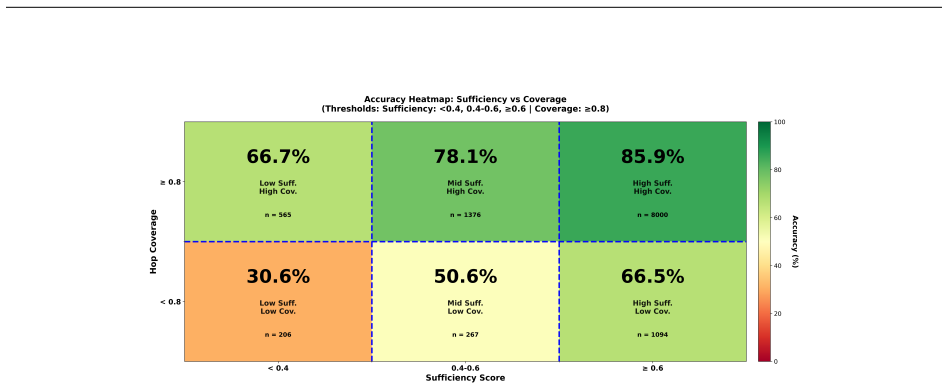
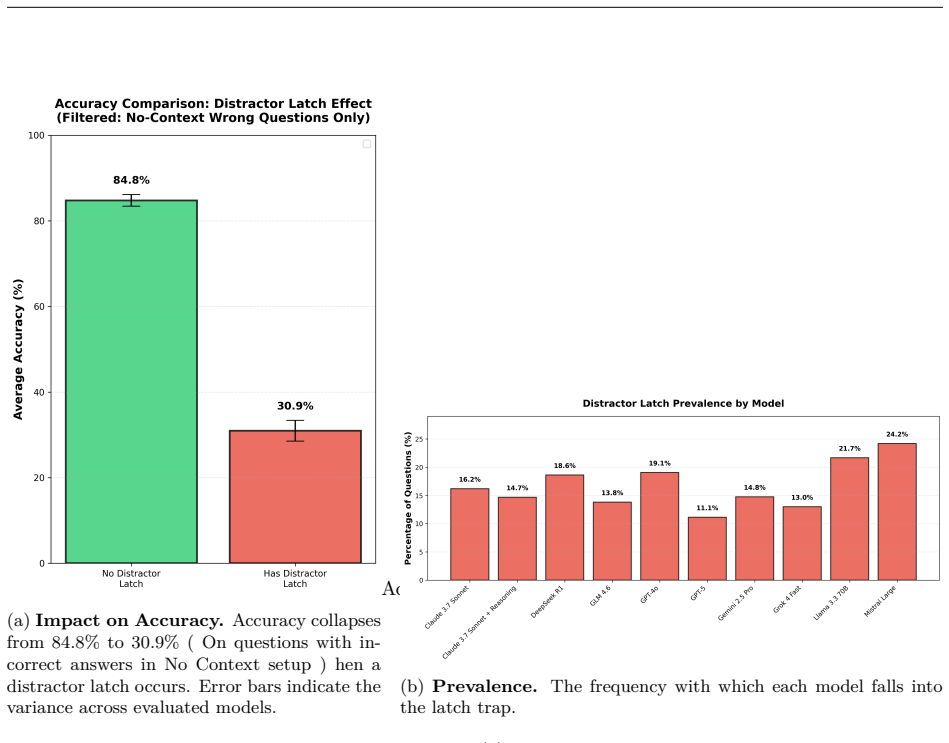
Using the ChemKGMultiHopQA dataset, the study finds that across eleven LLMs, the Iterative RAG regime, which alternates retrieval, hypothesis refinement, and evidence-aware stopping, consistently outperforms the Gold Context regime where all oracle evidence is provided at once, with improvements reaching 25.6 percentage points especially in non-reasoning fine-tuned models. This occurs because staged retrieval reduces late-hop failures, mitigates context overload, and allows dynamic correction of early hypothesis drift, even though remaining issues like incomplete coverage and distractor latching persist.
What carries the argument
The training-free Iterative RAG controller that alternates retrieval, hypothesis refinement, and evidence-aware stopping to synchronize retrieval and reasoning.
If this is right
- Staged retrieval reduces late-hop failures compared to static evidence provision.
- Mitigates context overload that can occur even with perfect evidence.
- Enables dynamic correction of early hypothesis drift during the process.
- Offers practical guidance for deploying and diagnosing RAG systems in specialized scientific settings.
Where Pith is reading between the lines
- This implies that for domain-specific multi-hop tasks, iterative strategies may be more effective than relying on static oracles even when perfect evidence is available.
- Similar patterns could be tested in other scientific domains like biology or physics to see if staged retrieval provides comparable advantages.
- Training methods could focus on improving stopping calibration and composition fidelity to further boost iterative RAG performance.
Load-bearing premise
That providing all oracle evidence at once truly represents an idealized upper bound without incurring hidden costs like context overload or distractor interference.
What would settle it
An experiment on the same ChemKGMultiHopQA dataset where Gold Context is adjusted to reduce overload, for instance by staging or shortening the evidence, and Iterative RAG no longer shows accuracy gains.
Figures












read the original abstract
Retrieval-Augmented Generation (RAG) extends large language models (LLMs) beyond parametric knowledge, yet it is unclear when iterative retrieval-reasoning loops meaningfully outperform static RAG, particularly in scientific domains with multi-hop reasoning, sparse domain knowledge, and heterogeneous evidence. We provide the first controlled, mechanism-level diagnostic study of whether synchronized iterative retrieval and reasoning can surpass an idealized static upper bound (Gold Context) RAG. We benchmark eleven state-of-the-art LLMs under three regimes: (i) No Context, measuring reliance on parametric memory; (ii) Gold Context, where all oracle evidence is supplied at once; and (iii) Iterative RAG, a training-free controller that alternates retrieval, hypothesis refinement, and evidence-aware stopping. Using the chemistry-focused ChemKGMultiHopQA dataset, we isolate questions requiring genuine retrieval and analyze behavior with diagnostics spanning retrieval coverage gaps, anchor-carry drop, query quality, composition fidelity, and control calibration. Across models, Iterative RAG consistently outperforms Gold Context, with gains up to 25.6 percentage points, especially for non-reasoning fine-tuned models. Staged retrieval reduces late-hop failures, mitigates context overload, and enables dynamic correction of early hypothesis drift, but remaining failure modes include incomplete hop coverage, distractor latch trajectories, early stopping miscalibration, and high composition failure rates even with perfect retrieval. Overall, staged retrieval is often more influential than the mere presence of ideal evidence; we provide practical guidance for deploying and diagnosing RAG systems in specialized scientific settings and a foundation for more reliable, controllable iterative retrieval-reasoning frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a diagnostic study on scientific multi-hop question answering using the ChemKGMultiHopQA dataset. It compares three regimes—No Context, Gold Context (all oracle evidence provided at once), and Iterative RAG (a training-free iterative retrieval-reasoning controller)—across eleven LLMs. The key claim is that Iterative RAG consistently outperforms Gold Context, achieving gains of up to 25.6 percentage points, particularly for non-reasoning fine-tuned models, by reducing late-hop failures, mitigating context overload, and enabling dynamic correction of hypothesis drift. The study includes detailed failure diagnostics on retrieval coverage, anchor-carry drop, query quality, composition fidelity, and control calibration.
Significance. This work is significant for the field of retrieval-augmented generation in specialized domains. If the results hold, it demonstrates that the staging of retrieval and reasoning can be more influential than the mere availability of ideal evidence, challenging the assumption that static gold context is always optimal. The diagnostic approach provides a foundation for more reliable iterative RAG frameworks and practical guidance for scientific applications where knowledge is sparse and multi-hop reasoning is required. The consistent gains across models add to the robustness of the findings.
major comments (2)
- [Experimental Setup and Results] The central claim that Iterative RAG outperforms Gold Context (up to 25.6 pp) depends on Gold Context functioning as a true idealized upper bound. However, the manuscript does not report per-condition token lengths, hop-wise evidence sizes, or a controlled ablation equalizing total evidence while varying presentation order. This leaves open whether gains arise from avoiding attention dilution or overload in long concatenated passages rather than superior retrieval-reasoning (see abstract discussion of context overload mitigation).
- [Dataset and Methodology] Dataset construction details for isolating questions requiring genuine retrieval, exact stopping rules for the iterative controller, and statistical controls (e.g., significance testing or variance across the 11 models) are insufficiently specified. These are load-bearing for the cross-model consistency claim and reproducibility of the reported gains.
minor comments (2)
- [Figures] Figure captions and legends should more explicitly reference the specific diagnostic metrics (e.g., anchor-carry drop, composition fidelity) discussed in the text for improved clarity.
- [Abstract] The abstract could briefly note the number of questions or hops in ChemKGMultiHopQA to provide immediate scale for the results.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our diagnostic study of iterative RAG versus Gold Context in scientific multi-hop QA. We address each major comment point by point below, with planned revisions to improve clarity and reproducibility while preserving the core findings.
read point-by-point responses
-
Referee: [Experimental Setup and Results] The central claim that Iterative RAG outperforms Gold Context (up to 25.6 pp) depends on Gold Context functioning as a true idealized upper bound. However, the manuscript does not report per-condition token lengths, hop-wise evidence sizes, or a controlled ablation equalizing total evidence while varying presentation order. This leaves open whether gains arise from avoiding attention dilution or overload in long concatenated passages rather than superior retrieval-reasoning (see abstract discussion of context overload mitigation).
Authors: We agree that explicit reporting of token lengths would help disambiguate length-based effects from the benefits of staged retrieval. In the revision we will add a table reporting average input token counts for No Context, Gold Context, and Iterative RAG conditions, plus hop-wise evidence sizes. Our existing diagnostics already show Iterative RAG reducing late-hop failures and correcting hypothesis drift even when retrieval coverage is high; these mechanisms are not reducible to length alone. A full ablation that equalizes total evidence while randomizing order is not present in the current experiments and would require new runs, so we will note this as a limitation and future direction rather than claim the current results fully isolate it. Revision made: partial. revision: partial
-
Referee: [Dataset and Methodology] Dataset construction details for isolating questions requiring genuine retrieval, exact stopping rules for the iterative controller, and statistical controls (e.g., significance testing or variance across the 11 models) are insufficiently specified. These are load-bearing for the cross-model consistency claim and reproducibility of the reported gains.
Authors: We acknowledge these specification gaps limit reproducibility. The revised manuscript will expand the dataset section to describe the exact filtering criteria used to retain only questions where No-Context performance indicates genuine retrieval need (i.e., parametric failure). We will also state the precise stopping rules (confidence threshold of 0.8 or maximum 5 iterations, whichever first) and add per-model standard deviations plus paired statistical tests (Wilcoxon signed-rank) across the 11 LLMs to quantify consistency of the gains. These additions directly support the cross-model claims without altering the experimental design. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with no derivations or fitted predictions
full rationale
The paper is a controlled empirical study comparing three RAG regimes (No Context, Gold Context, Iterative RAG) on the ChemKGMultiHopQA dataset across eleven LLMs. It reports performance metrics, diagnostics for retrieval coverage, hypothesis drift, and failure modes without any equations, parameter fitting, predictions derived from inputs, or load-bearing self-citations. The central claim (Iterative RAG outperforming Gold Context) rests on direct experimental measurements rather than any reduction to prior quantities by construction. No self-definitional loops, ansatz smuggling, or renaming of known results occur. The study is self-contained against external benchmarks and does not invoke uniqueness theorems or author-prior results as justification for its methodology.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Hypergraph Enterprise Agentic Reasoner over Heterogeneous Business Systems
HEAR uses a stratified hypergraph ontology to orchestrate evidence-driven multi-hop reasoning over heterogeneous business systems, reaching 94.7% accuracy on supply-chain root-cause tasks with open-weight models.
Reference graph
Works this paper leans on
-
[1]
Cognitive load limits in large language models: Benchmarking multi-hop reasoning
Sai Teja Reddy Adapala. Cognitive load limits in large language models: Benchmarking multi-hop reasoning. arXiv preprint arXiv:2509.19517,
-
[2]
Llama-3.3-70b-instruct, Dec 2024a
Meta AI. Llama-3.3-70b-instruct, Dec 2024a. URLhttps://huggingface.co/meta-llama/Llama-3. 3-70B-Instruct. Model card; Accessed 2025-10-21. Mistral AI. Mistral large: Open-weight dense transformer.https://mistral.ai/news/mistral-large, 2024b. Released December 2024, Accessed: 2025-10-03. Mistral AI. Au large: Announcing mistral large (2402).https://mistral...
work page 2025
-
[3]
Mohammad Aghajani Asl, Majid Asgari-Bidhendi, and Behrooz Minaei-Bidgoli. Fair-rag: Faithful adaptive iterative refinement for retrieval-augmented generation.arXiv preprint arXiv:2510.22344,
-
[4]
Probing-rag: Self-probing to guide language models in selective document retrieval
Ingeol Baek, Hwan Chang, Byeongjeong Kim, Jimin Lee, and Hwanhee Lee. Probing-rag: Self-probing to guide language models in selective document retrieval. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 3287–3304,
work page 2025
-
[5]
Finqa: A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 3697–3711. Association for Computation...
work page 2021
-
[6]
URLhttps:// aclanthology.org/2021.emnlp-main.300/. Qinyuan Cheng, Xiaonan Li, Shimin Li, Qin Zhu, Zhangyue Yin, Yunfan Shao, Linyang Li, Tianxiang Sun, Hang Yan, and Xipeng Qiu. Unified active retrieval for retrieval augmented generation.arXiv preprint arXiv:2406.12534,
-
[7]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A
URLhttps://aclanthology.org/2025.findings-acl.123/. Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Tech...
work page 2025
-
[8]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert
URL https://aclanthology.org/2021.naacl-main.365/. Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. RAGAs: Automated evaluation of retrieval augmented generation. In Nikolaos Aletras and Orphee De Clercq (eds.),Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrati...
work page 2021
-
[9]
Association for Computational Linguistics. doi: 10.18653/v1/2024.eacl-demo.16. URLhttps://aclanthology.org/2024.eacl-demo.16/. Meta AI et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.eacl-demo.16 2024
-
[10]
URLhttps://arxiv. org/abs/2407.21783. Jinyuan Fang, Zaiqiao Meng, and Craig Macdonald. Kirag: Knowledge-driven iterative retriever for enhanc- ing retrieval-augmented generation.arXiv preprint arXiv:2502.18397,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Smartrag: Jointly learn rag-related tasks from the environment feedback
Jingsheng Gao, Linxu Li, Weiyuan Li, Yuzhuo Fu, and Bin Dai. Smartrag: Jointly learn rag-related tasks from the environment feedback.arXiv preprint arXiv:2410.18141,
-
[12]
Synergizing rag and reasoning: A systematic review
Yunfan Gao, Yun Xiong, Yijie Zhong, Yuxi Bi, Ming Xue, and Haofen Wang. Synergizing rag and reasoning: A systematic review.arXiv preprint arXiv:2504.15909,
- [13]
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://ai.google.dev/gemini-api/docs/changelog. Accessed 2025-10-21. Daya Guo et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. 2025a. URLhttps://arxiv.org/abs/2501.12948. Daya Guo et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645 (8081):633–638, 2025b. doi: 10.1038/s4...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[15]
URLhttps://aclanthology.org/2020.coling-main.580/. Zhen Huang, Zengzhi Wang, Shijie Xia, Xuefeng Li, Haoyang Zou, Ruijie Xu, Run-Ze Fan, Lyumanshan Ye, Ethan Chern, Yixin Ye, et al. Olympicarena: Benchmarking multi-discipline cognitive reasoning for superintelligent ai.Advances in Neural Information Processing Systems, 37:19209–19253,
work page 2020
-
[16]
Retrieve, summarize, plan: Advancing multi- hop question answering with an iterative approach
Zhouyu Jiang, Mengshu Sun, Lei Liang, and Zhiqiang Zhang. Retrieve, summarize, plan: Advancing multi- hop question answering with an iterative approach. InCompanion Proceedings of the ACM on Web Conference 2025, pp. 1677–1686,
work page 2025
-
[17]
Ali Shiraee Kasmaee, Mohammad Khodadad, Mehdi Astaraki, Mohammad Arshi Saloot, Nicholas Sherck, Hamidreza Mahyar, and Soheila Samiee. Chembed: Enhancing chemical literature search through domain- specific text embeddings.arXiv preprint arXiv:2508.01643,
-
[18]
Evaluating multi-hop reasoning in large language models: A chemistry-centric case study
Mohammad Khodadad, Ali Shiraee Kasmaee, Mahdi Astaraki, Nicholas Sherck, Hamidreza Mahyar, and Soheila Samiee. Evaluating multi-hop reasoning in large language models: A chemistry-centric case study. arXiv preprint arXiv:2504.16414, 2025a. Mohammad Khodadad, Ali Shiraee Kasmaee, Mahdi Astaraki, Nicholas Sherck, Hamidreza Mahyar, and Soheila Samiee. Evalua...
-
[19]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Rui Li, Quanyu Dai, Zeyu Zhang, Xu Chen, Zhenhua Dong, and Ji-Rong Wen. Knowtrace: Bootstrapping iterative retrieval-augmented generation with structured knowledge tracing. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pp. 1470–1480, 2025a. Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.1142. URLhttps://aclanthology.org/2025.acl-long.1142/. Jinchang Luo, Mingquan Cheng, Fan Wan, Ni Li, Xiaoling Xia, Shuangshuang Tian, Tingcheng Bian, Haiwei Wang, Haohuan Fu, and Yan Tao. Globalrag: Enhancing global reasoning in multi-hop question answering v...
-
[21]
Md Mahadi Hasan Nahid and Davood Rafiei
URLhttps://arxiv.org/abs/2510.20548. Md Mahadi Hasan Nahid and Davood Rafiei. Prism: Agentic retrieval with llms for multi-hop question answering.arXiv preprint arXiv:2510.14278,
-
[22]
Gpt-4o: Openai’somnimodalmodel.https://openai.com/index/hello-gpt-4o, 2024a
OpenAI. Gpt-4o: Openai’somnimodalmodel.https://openai.com/index/hello-gpt-4o, 2024a. Released May 2024, Accessed: 2025-10-03. OpenAI. Gpt-4o system card.https://openai.com/index/gpt-4o-system-card/, 2024b. Accessed 2025- 10-20. OpenAI. Gpt-5: Advancing multimodal and long-context reasoning.https://openai.com/research,
work page 2024
-
[23]
Jaewan Park, Solbee Cho, and Jay-Yoon Lee
Released mid-2025, Accessed: 2025-10-03. Jaewan Park, Solbee Cho, and Jay-Yoon Lee. Stop-rag: Value-based retrieval control for iterative rag, 2025a. URLhttps://arxiv.org/abs/2510.14337. Sangwoo Park, Jinheon Baek, Soyeong Jeong, and Sung Ju Hwang. Chain of retrieval: Multi-aspect iterative search expansion and post-order search aggregation for full paper...
-
[24]
Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy,
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy.arXiv preprint arXiv:2305.15294,
-
[25]
URLhttps: //arxiv.org/abs/2508.03644. Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025a. Maojia Song, Renhang Liu, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou...
-
[26]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Han- naneh Hajishirzi. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7534–7550. Association for Computa- tional Linguistics,
work page 2020
-
[27]
Jinyu Wang, Jingjing Fu, Rui Wang, Lei Song, and Jiang Bian
URLhttps://aclanthology.org/2020.emnlp-main.609/. Jinyu Wang, Jingjing Fu, Rui Wang, Lei Song, and Jiang Bian. Pike-rag: specialized knowledge and rationale augmented generation.arXiv preprint arXiv:2501.11551,
-
[28]
URL https://arxiv.org/abs/2504.14858. Geemi P Wellawatte, Huixuan Guo, Magdalena Lederbauer, Anna Borisova, Matthew Hart, Marta Brucka, andPhilippeSchwaller. Chemlit-qa: ahumanevaluateddatasetforchemistryragtasks.Machine Learning: Science and Technology, 6(2):020601, 2025a. Geemi P Wellawatte, Huixuan Guo, Magdalena Lederbauer, Anna Borisova, Matthew Hart...
-
[29]
Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools,
URLhttps://en.wikipedia. org/wiki/Grok_(large_language_model). Junde Wu, Jiayuan Zhu, Yuyuan Liu, Min Xu, and Yueming Jin. Agentic reasoning: A streamlined frame- work for enhancing llm reasoning with agentic tools.arXiv preprint arXiv:2502.04644,
-
[30]
Grok 4 model card.https://data.x.ai/2025-08-20-grok-4-model-card.pdf, Aug
xAI. Grok 4 model card.https://data.x.ai/2025-08-20-grok-4-model-card.pdf, Aug
work page 2025
-
[31]
Kaige Xie, Philippe Laban, Prafulla Kumar Choubey, Caiming Xiong, and Chien-Sheng Wu
Accessed 2025-10-21. Kaige Xie, Philippe Laban, Prafulla Kumar Choubey, Caiming Xiong, and Chien-Sheng Wu. Do RAG systems cover what matters? evaluating and optimizing responses with sub-question coverage. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.),Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Comp...
work page 2025
-
[32]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long.301. URL https://aclanthology.org/2025.naacl-long.301/. Guangzhi Xiong, Qiao Jin, Xiao Wang, Minjia Zhang, Zhiyong Lu, and Aidong Zhang. Improving retrieval- augmented generation in medicine with iterative follow-up questions. InBiocomputing 2025: Proceedin...
-
[33]
Zhipeng Xu, Zhenghao Liu, Yukun Yan, Shuo Wang, Shi Yu, Zheni Zeng, Chaojun Xiao, Zhiyuan Liu, Ge Yu, and Chenyan Xiong. Activerag: Autonomously knowledge assimilation and accommodation through retrieval-augmented agents.arXiv preprint arXiv:2402.13547,
-
[34]
O1 embedder: Let retrievers think before action.arXiv preprint arXiv:2502.07555,
Ruiran Yan, Zheng Liu, and Defu Lian. O1 embedder: Let retrievers think before action.arXiv preprint arXiv:2502.07555,
-
[35]
URLhttp://dx.doi.org/10.1145/3726302.3730018
doi: 10.1145/3726302.3730018. URLhttp://dx.doi.org/10.1145/3726302.3730018. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
-
[36]
URLhttps: //aclanthology.org/2021.acl-long.254/. Yilun Zhang. Cognitive load-aware inference: A neuro-symbolic framework for optimizing the token economy of large language models.arXiv preprint arXiv:2507.00653,
-
[37]
URLhttps://z.ai/ blog/glm-4.6. Accessed 2025-10-21. S1 Appendix S1.1 Extended Literature Review The 2024–2025 period brought a steady run of dense-transformer LLMs, with some Mixture-of-Experts (MoE) experiments. In February 2024, Mistral releasedMistral Large, a conventional dense transformer tuned with instruction Supervised Fine-tuning (SFT) for predic...
work page 2025
-
[38]
Anthropic’sClaude 4.5 Sonnet(Sept
stays dense and SFT+preference tuned; the goal is smoother, less jumpy gains when users add exemplars, reasoning tokens, or clean retrieval OpenAI (2025). Anthropic’sClaude 4.5 Sonnet(Sept
work page 2025
-
[39]
continues the dense line with stronger longer-horizon control; its SFT variants try to ensure that spending more tokens yields helpful intermediate structure rather than drift Anthropic (2025b). xAI’sGrokevolved from an MoE phase (e.g., the 314B Grok-1) toward later, reasoning-oriented post-training on streamlined backbones; instruction SFT and preference...
work page 2025
-
[40]
extends a pragmatic dense family for enterprise cod- ing/reasoning; instruction SFT supports the usual test-time levers (few-shot conditioning, short intermediate reasoning, and measured benefits from tidy retrieval). Overall, three overlapping currents are relevant to this work: (i)Alignment-first dense transformers(e.g., Mistral Large 2402; Llama 3.3 70...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.