Recognition: no theorem link
Physically Guided Visual Mass Estimation from a Single RGB Image
Pith reviewed 2026-05-16 10:55 UTC · model grok-4.3
The pith
A single RGB image yields object mass by recovering depth-based volume and material semantics for density through fused latent factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
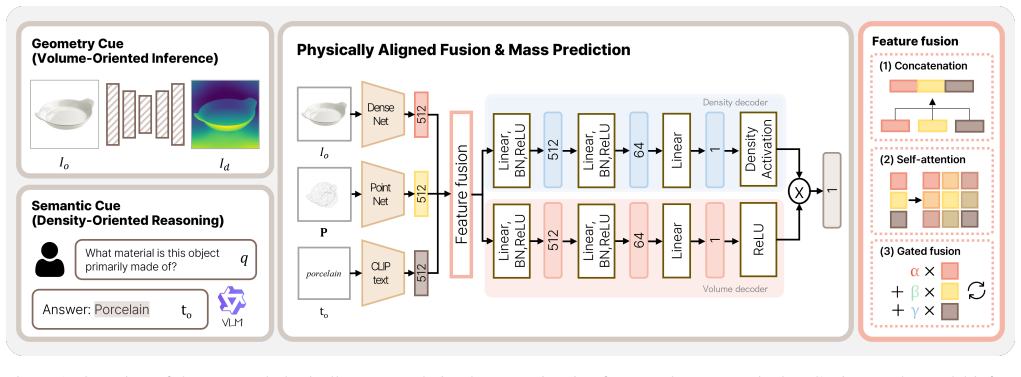
From a single RGB image, we recover object-centric three-dimensional geometry via monocular depth estimation to inform volume and extract coarse material semantics using a vision-language model to guide density-related reasoning. These geometry, semantic, and appearance representations are fused through an instance-adaptive gating mechanism, and two physically guided latent factors (volume- and density-related) are predicted through separate regression heads under mass-only supervision.
What carries the argument
The instance-adaptive gating mechanism that combines depth-derived geometry, vision-language material semantics, and appearance features to drive separate volume- and density-related regression heads.
If this is right
- Mass labels alone suffice to train separate volume and density predictors when guided by depth and semantic proxies.
- The fused representation constrains predictions to physically plausible mass values rather than arbitrary image correlations.
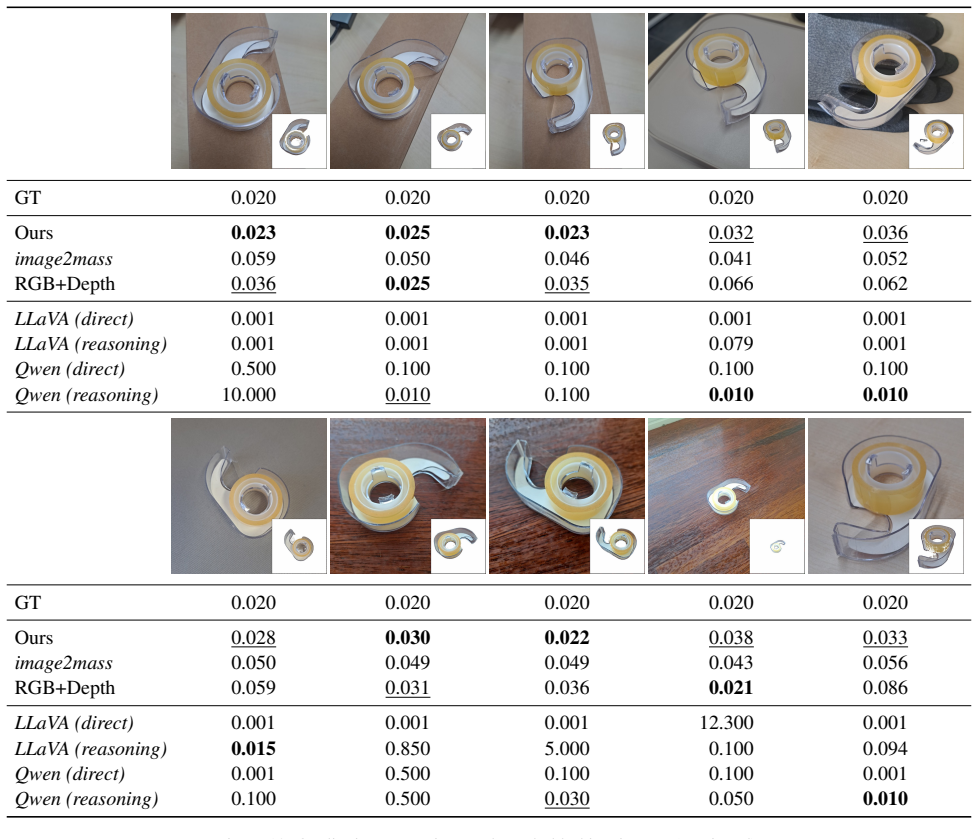
- Performance gains appear consistently on image2mass and ABO-500 relative to prior single-image methods.
- The decomposition into two latent factors makes the learned mapping more interpretable in physical terms.
Where Pith is reading between the lines
- The same depth-plus-semantics split could be tested on video sequences to track mass changes over time without new labels.
- Robotic systems that already run depth estimation might add this mass head to decide grasp forces before contact.
- If material semantics prove the weaker link, swapping in finer-grained material classifiers would be a direct next experiment.
- The approach suggests a template for estimating other hidden physical quantities such as friction or elasticity from single views.
Load-bearing premise
Monocular depth estimates and vision-language material semantics supply accurate enough proxies for true volume and density that mass-only training can recover the right factors.
What would settle it
Replace the monocular depth map with random noise or the vision-language material labels with unrelated categories and check whether mass accuracy falls below the level of ordinary image-only baselines on the same test images.
Figures









read the original abstract
Estimating object mass from visual input is challenging because mass depends jointly on geometric volume and material-dependent density, neither of which is directly observable from RGB appearance. Consequently, mass prediction from pixels is ill-posed and therefore benefits from physically meaningful representations to constrain the space of plausible solutions. We propose a physically structured framework for single-image mass estimation that addresses this ambiguity by aligning visual cues with the physical factors governing mass. From a single RGB image, we recover object-centric three-dimensional geometry via monocular depth estimation to inform volume and extract coarse material semantics using a vision-language model to guide density-related reasoning. These geometry, semantic, and appearance representations are fused through an instance-adaptive gating mechanism, and two physically guided latent factors (volume- and density-related) are predicted through separate regression heads under mass-only supervision. Experiments on image2mass and ABO-500 show that the proposed method consistently outperforms state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a physically structured framework for single-image mass estimation. From an RGB input it recovers object-centric 3D geometry via monocular depth estimation to inform volume, extracts coarse material semantics with a vision-language model to guide density reasoning, fuses geometry, semantic and appearance features through an instance-adaptive gating mechanism, and predicts two separate regression heads for volume- and density-related latent factors trained solely under mass supervision. Experiments on image2mass and ABO-500 are reported to show consistent outperformance over prior methods.
Significance. If the latent factors can be shown to meaningfully track volume and density rather than arbitrary decompositions that merely multiply to the observed mass, the work would supply a useful inductive bias for an ill-posed regression task and could improve generalization on unseen objects and materials. The explicit architectural separation and use of auxiliary pre-trained models constitute a concrete attempt to inject physical structure; however, the absence of direct validation for the claimed factorization limits the immediate impact.
major comments (2)
- [Section 3] Section 3 (method): the assertion that the two regression heads learn 'physically guided' volume- and density-related factors rests on mass-only supervision. No direct volume or density labels, no correlation analysis against 3D ground truth, and no ablation that removes the depth or VLM inputs while preserving mass accuracy are described; any decomposition whose product matches mass satisfies the loss, so the specialization claim is untested.
- [Section 4] Section 4 (experiments): the abstract states 'consistent outperformance' on image2mass and ABO-500 yet supplies no quantitative numbers, ablation tables, error distributions, or statistical significance tests. Without these data it is impossible to judge whether the reported gains are load-bearing or merely incremental.
minor comments (2)
- [Section 3.1] Notation for the instance-adaptive gating weights and the two latent factors should be introduced with explicit equations rather than descriptive prose only.
- [Section 3.2] The manuscript should clarify which pre-trained depth and VLM models are frozen versus fine-tuned and report their version numbers for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We address the concerns regarding the validation of the physically guided factors and the presentation of experimental results below.
read point-by-point responses
-
Referee: [Section 3] Section 3 (method): the assertion that the two regression heads learn 'physically guided' volume- and density-related factors rests on mass-only supervision. No direct volume or density labels, no correlation analysis against 3D ground truth, and no ablation that removes the depth or VLM inputs while preserving mass accuracy are described; any decomposition whose product matches mass satisfies the loss, so the specialization claim is untested.
Authors: We acknowledge the referee's point that the specialization of the latent factors is not directly validated in the current manuscript. The design uses separate heads and fuses depth and VLM features to guide the decomposition, but to provide stronger evidence, we will include additional ablations that isolate the contribution of the depth and VLM modules to the final mass accuracy. We will also report correlations between the predicted volume-related factor and ground-truth volumes from the datasets where available. This will help confirm that the factors are not arbitrary. revision: yes
-
Referee: [Section 4] Section 4 (experiments): the abstract states 'consistent outperformance' on image2mass and ABO-500 yet supplies no quantitative numbers, ablation tables, error distributions, or statistical significance tests. Without these data it is impossible to judge whether the reported gains are load-bearing or merely incremental.
Authors: We agree that the abstract should provide concrete numbers to support the claim of outperformance. The experiments section contains the full tables and distributions; we will update the abstract to report key quantitative results (e.g., MAE and relative error on both benchmarks) and ensure all ablations and significance tests are clearly presented. revision: yes
Circularity Check
No significant circularity; method uses external pre-trained models and mass-only supervision without definitional reduction
full rationale
The described framework fuses outputs from independent pre-trained monocular depth and VLM models through an adaptive gate, then regresses two latent factors to mass labels. No equations, self-citations, or uniqueness claims are present that would make the volume/density factors equivalent to mass by construction. The physical guidance is an architectural and naming choice supported by external components, leaving the central claim independent of any fitted input redefined as prediction.
Axiom & Free-Parameter Ledger
free parameters (1)
- instance-adaptive gating weights
axioms (2)
- domain assumption Monocular depth estimation yields sufficiently accurate geometry to inform object volume
- domain assumption Vision-language model outputs provide reliable coarse material semantics for density reasoning
Reference graph
Works this paper leans on
-
[1]
Feel the force: Contact-driven learning from humans
[Adenijiet al., 2025 ] Ademi Adeniji, Zhuoran Chen, Vin- cent Liu, Venkatesh Pattabiraman, Raunaq Bhirangi, Siddhant Haldar, Pieter Abbeel, and Lerrel Pinto. Feel the force: Contact-driven learning from humans. arXiv:2506.01944,
-
[2]
Improving the estimation of object mass from images
[Andrade and Moreno, 2023] Jo˜ao Martinho Lopes Andrade and Plinio Moreno. Improving the estimation of object mass from images. InIEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC),
work page 2023
-
[3]
Estimating object physical properties from RGB- D vision and depth robot sensors using deep learning
[Cardoso and Moreno, 2025] Ricardo Cardoso and Plinio Moreno. Estimating object physical properties from RGB- D vision and depth robot sensors using deep learning. InIberian Conference on Pattern Recognition and Image Analysis,
work page 2025
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
[Changet al., 2015 ] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An information-rich 3D model repository.arXiv:1512.03012,
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
SpatialVLM: Endowing vision-language models with spatial reasoning capabili- ties
[Chenet al., 2024 ] Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: Endowing vision-language models with spatial reasoning capabili- ties. InCVPR,
work page 2024
-
[6]
Xception: Deep learning with depthwise separable convolutions
[Chollet, 2017] Franc ¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. InCVPR,
work page 2017
-
[7]
[Chuet al., 2025 ] Xiaomeng Chu, Jiajun Deng, Guoliang You, Wei Liu, Xingchen Li, Jianmin Ji, and Yanyong Zhang. GraspCoT: Integrating physical property reasoning for 6-DoF grasping under flexible language instructions. In ICCV,
work page 2025
-
[8]
Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik
[Collinset al., 2022 ] Jasmine Collins, Shubham Goel, Ke- nan Deng, Achleshwar Luthra, Leon Xu, Erhan Gun- dogdu, Xi Zhang, Tomas F. Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik. ABO: Dataset and benchmarks for real- world 3D object understanding. InCVPR,
work page 2022
-
[9]
Task-oriented robotic manipulation with vision language models
[Guranet al., 2024 ] Nurhan Bulus Guran, Hanchi Ren, Jingjing Deng, and Xianghua Xie. Task-oriented robotic manipulation with vision language models. arXiv:2410.15863,
-
[10]
[Hanet al., 2020 ] Yuanfeng Han, Ruixin Li, and Gregory S. Chirikjian. Can I lift it? Humanoid robot reasoning about the feasibility of lifting a heavy box with unknown physi- cal properties. InIROS,
work page 2020
-
[11]
[Huanget al., 2017 ] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely con- nected convolutional networks. InCVPR,
work page 2017
-
[12]
Repurposing diffusion-based image generators for monocular depth estimation
[Keet al., 2024 ] Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InCVPR,
work page 2024
-
[13]
Global-local path networks for monocular depth estima- tion with vertical cutdepth.arXiv:2201.07436,
[Kimet al., 2022 ] Doyeon Kim, Woonghyun Ka, Pyung- whan Ahn, Donggyu Joo, Sehwan Chun, and Junmo Kim. Global-local path networks for monocular depth estima- tion with vertical cutdepth.arXiv:2201.07436,
-
[14]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
[Kirillovet al., 2023 ] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InCVPR,
work page 2023
-
[15]
[Liet al., 2025 ] Wenqiao Li, Yao Gu, Xintao Chen, Xiaohao Xu, Ming Hu, Xiaonan Huang, and Yingna Wu. Towards visual discrimination and reasoning of real-world physi- cal dynamics: Physics-grounded anomaly detection. In CVPR,
work page 2025
-
[16]
[Liaoet al., 2024 ] Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, and David Acuna. Reasoning paths with reference objects elicit quantitative spatial reasoning in large vision- language models. InEMNLP,
work page 2024
-
[17]
Visual instruction tuning.NeurIPS,
[Liuet al., 2023 ] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS,
work page 2023
-
[18]
Ground- ing DINO: Marrying DINO with grounded pre-training for open-set object detection
[Liuet al., 2025 ] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Ground- ing DINO: Marrying DINO with grounded pre-training for open-set object detection. InECCV,
work page 2025
-
[19]
Qi, Hao Su, Kaichun Mo, and Leonidas J
[Qiet al., 2017 ] Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InCVPR,
work page 2017
-
[20]
Learning transferable visual models from natural language supervi- sion
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervi- sion. InICML,
work page 2021
-
[21]
Benford’s curse: Tracing digit bias to numerical hallucina- tion in LLMs.NeurIPS,
[Shaoet al., 2025 ] Jiandong Shao, Yao Lu, and Jianfei Yang. Benford’s curse: Tracing digit bias to numerical hallucina- tion in LLMs.NeurIPS,
work page 2025
-
[22]
PUGS: Zero-shot physical understanding with Gaussian splatting.arXiv:2502.12231,
[Shuaiet al., 2025 ] Yinghao Shuai, Ran Yu, Yuantao Chen, Zijian Jiang, Xiaowei Song, Nan Wang, Jv Zheng, Jianzhu Ma, Meng Yang, Zhicheng Wang, Wenbo Ding, and Hao Zhao. PUGS: Zero-shot physical understanding with Gaussian splatting.arXiv:2502.12231,
-
[23]
image2mass: Estimating the mass of an object from its image
[Standleyet al., 2017 ] Trevor Standley, Ozan Sener, Dawn Chen, and Silvio Savarese. image2mass: Estimating the mass of an object from its image. InCoRL,
work page 2017
- [24]
-
[25]
ULIP-2: Towards scalable multimodal pre-training for 3D understanding
[Xueet al., 2024 ] Le Xue, Ning Yu, Shu Zhang, Artemis Panagopoulou, Junnan Li, Roberto Mart ´ın-Mart´ın, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. ULIP-2: Towards scalable multimodal pre-training for 3D understanding. InCVPR,
work page 2024
-
[26]
[Yanget al., 2024a ] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Ji- axi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Li...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
[Zhaiet al., 2024 ] Albert J. Zhai, Yuan Shen, Emily Y . Chen, Gloria X. Wang, Xinlei Wang, Sheng Wang, Kaiyu Guan, and Shenlong Wang. Physical property understanding from language-embedded feature fields. InCVPR,
work page 2024
-
[28]
Long-CLIP: Un- locking the long-text capability of CLIP
[Zhanget al., 2024 ] Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-CLIP: Un- locking the long-text capability of CLIP. InECCV,
work page 2024
-
[29]
PhysVLM: Enabling visual language mod- els to understand robotic physical reachability
[Zhouet al., 2025 ] Weijie Zhou, Manli Tao, Chaoyang Zhao, Haiyun Guo, Honghui Dong, Ming Tang, and Jin- qiao Wang. PhysVLM: Enabling visual language mod- els to understand robotic physical reachability. InCVPR, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.