HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Pith reviewed 2026-05-16 09:38 UTC · model grok-4.3
The pith
HER enables LLMs to simulate character inner thoughts by separating first-person persona reasoning from third-person model oversight and training on reverse-engineered data plus human-aligned rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HER is a unified framework for cognitive-level persona simulation. It introduces dual-layer thinking that keeps characters' first-person thinking distinct from the LLM's third-person analysis. The authors curate reasoning-augmented role-playing data via reverse engineering, construct human-aligned principles, and train reward models on those principles. Supervised and reinforcement learning on these resources produces models that outperform the Qwen3-32B baseline by 30.26 points on CoSER and 14.97 percent on the Minimax Role-Play Bench.
What carries the argument
Dual-layer thinking mechanism that separates a character's first-person inner reasoning from the LLM's third-person oversight, supported by reverse-engineered reasoning traces and human-aligned reward models.
If this is right
- HER models deliver a 30.26-point gain on the CoSER benchmark over the Qwen3-32B baseline.
- The same training yields a 14.97 percent improvement on the Minimax Role-Play Bench.
- Released datasets, principles, and models provide resources that future work can build on for cognitive role simulation.
- Applications such as digital companions and games gain more consistent inner-thought simulation without additional prompt engineering.
Where Pith is reading between the lines
- The reverse-engineering technique for obtaining reasoning traces could reduce the cost of creating high-quality thought data for other dialogue or planning tasks.
- Maintaining an explicit separation between character and model perspectives may help maintain coherence over longer multi-turn interactions.
- Reward models trained on the human-aligned principles might transfer to preference tuning in general conversational agents beyond role-play.
Load-bearing premise
Reverse-engineered reasoning data and the constructed reward models supply traces and signals that accurately reflect human preferences for how personas should think and act.
What would settle it
Training two otherwise identical models—one with the dual-layer distinction and reverse-engineered traces, one without—then measuring whether the gap on CoSER and Minimax benchmarks disappears would directly test the necessity of these components.
Figures









read the original abstract
LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: lacking data with high-quality reasoning traces, and lacking reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering, and construct human-aligned principles and reward models. Leveraging these resources, we train HER models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97% gain on the Minimax Role-Play Bench. Our datasets, principles, and models are released to facilitate future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the HER framework for cognitive-level persona simulation in LLMs. It introduces dual-layer thinking to separate characters' first-person inner thoughts from the LLM's third-person reasoning. The authors curate reasoning-augmented role-playing data via reverse engineering, construct human-aligned principles and reward models, and train Qwen3-32B models with supervised fine-tuning followed by reinforcement learning. They report large gains over the Qwen3-32B baseline: +30.26 on the CoSER benchmark and +14.97% on the Minimax Role-Play Bench, and release the associated datasets, principles, and models.
Significance. If the reverse-engineered traces and reward models prove reliable, the dual-layer approach could provide a practical route to better inner-thought simulation in role-play agents. The public release of the curated resources is a clear strength that supports reproducibility and follow-on work.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the headline performance deltas (+30.26 on CoSER, +14.97% on Minimax) are stated without error bars, confidence intervals, number of runs, or statistical tests, so it is impossible to judge whether the gains are robust or attributable to the proposed framework rather than base-model scale or generic RL.
- [Data Curation] Data curation section: the reverse-engineered reasoning-augmented traces are presented as high-quality, yet no human agreement scores, inter-annotator reliability, or validation against expert annotations are reported; this validation is load-bearing for the claim that the performance improvement stems from cognitive-level traces rather than artifacts of the reverse-engineering process.
- [Experiments] Experiments section: no ablation studies isolate the contribution of dual-layer thinking, the human-aligned principles, or the learned reward model from the base Qwen3-32B checkpoint or from standard SFT+RL; without these controls the central attribution of gains to HER remains untested.
minor comments (2)
- [Methods] Clarify the precise operational definition of 'first-person thinking' versus 'third-person thinking' with concrete prompt examples early in the methods.
- [Data Curation] Add a table summarizing the scale and composition of the curated dataset (number of dialogues, average trace length, source personas).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve the robustness and clarity of the claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline performance deltas (+30.26 on CoSER, +14.97% on Minimax) are stated without error bars, confidence intervals, number of runs, or statistical tests, so it is impossible to judge whether the gains are robust or attributable to the proposed framework rather than base-model scale or generic RL.
Authors: We agree that the lack of error bars and statistical measures makes it difficult to fully assess robustness. The reported figures come from single-run evaluations, which is common given the computational expense of LLM training and inference. In the revision we will add an explicit statement on the evaluation protocol and, where additional runs are feasible, include standard deviations across seeds. This will help distinguish framework-driven gains from baseline variability. revision: partial
-
Referee: [Data Curation] Data curation section: the reverse-engineered reasoning-augmented traces are presented as high-quality, yet no human agreement scores, inter-annotator reliability, or validation against expert annotations are reported; this validation is load-bearing for the claim that the performance improvement stems from cognitive-level traces rather than artifacts of the reverse-engineering process.
Authors: The reverse-engineering procedure uses a structured, principle-guided prompting approach to generate traces. While internal sampling checks were performed, quantitative inter-annotator agreement was not computed because the process is largely automated. We will revise the data curation section to describe the verification protocol, report agreement on a sampled subset, and include representative examples that illustrate alignment with cognitive simulation. revision: yes
-
Referee: [Experiments] Experiments section: no ablation studies isolate the contribution of dual-layer thinking, the human-aligned principles, or the learned reward model from the base Qwen3-32B checkpoint or from standard SFT+RL; without these controls the central attribution of gains to HER remains untested.
Authors: We acknowledge that component-wise ablations would strengthen causal attribution. The current results compare the full HER pipeline against the base Qwen3-32B and implicit standard SFT+RL baselines, but do not isolate each element. In the revised manuscript we will add ablation experiments that remove dual-layer thinking and the learned reward model individually, reporting their incremental contributions on the same benchmarks. revision: yes
Circularity Check
No significant circularity; empirical pipeline relies on external data curation
full rationale
The paper introduces dual-layer thinking and trains HER models on Qwen3-32B via SFT and RL after curating reasoning-augmented data through reverse engineering and constructing human-aligned principles plus reward models. These steps depend on newly created external resources and standard training procedures rather than any self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citation chains. The reported gains (+30.26 on CoSER, +14.97% on Minimax) are presented as empirical results of this process, with no reduction of claims to inputs by construction visible in the abstract or described framework. The derivation remains self-contained through data creation and RL optimization.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking... we curate reasoning-augmented role-playing data via reverse engineering, and construct human-aligned principles and reward models... train HER models based on Qwen3-32B via supervised and reinforcement learning.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train a Role-play GRM by distilling reusable principles... pairwise judging with by-case principles → analysis → final decision... RL where the GRM compares the policy response with a baseline response
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ArXiv preprint, abs/2310.00785
Booookscore: A systematic exploration of book-length summarization in the era of llms. ArXiv preprint, abs/2310.00785. Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, Aili Chen, Nianqi Li, Lida Chen, Caiyu Hu, Siye Wu, Scott Ren, Ziquan Fu, and Yanghua Xiao. 2024a. From persona to persona...
-
[2]
Large language models meet harry potter: A dataset for aligning dialogue agents with characters. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8506–8520, Sin- gapore. Association for Computational Linguistics. Yanqi Dai, Huanran Hu, Lei Wang, Shengjie Jin, Xu Chen, and Zhiwu Lu. 2024. Mmrole: A com- prehensive framework f...
work page 2023
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning. Preprint, arXiv:2501.12948. Ameet Deshpande, Vishvak Murahari, Tanmay Rajpuro- hit, Ashwin Kalyan, and Karthik Narasimhan. 2023. Toxicity in chatgpt: Analyzing persona-assigned lan- guage models. In Findings of the Association for Computational Linguistics: EMNLP 2023, p...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
ArXiv preprint, abs/2308.09597
Chatharuhi: Reviving anime character in reality via large language model. ArXiv preprint, abs/2308.09597. 9 Dawei Li, Bohan Jiang, Liangjie Huang, Alimoham- mad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tian- hao Wu, and 1 others. 2024. From generation to judgment: Opportunities and challenges of llm-as-a- judge. Ar...
-
[5]
In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4471–4500
Bookworm: A dataset for character descrip- tion and analysis. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4471–4500. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive sim- ulacra of human behavior. In In the 36th Annual A...
work page 2024
-
[6]
Role play with large language models. Nature, 623(7987):493–498. Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Character-LLM: A trainable agent for role- playing. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13153–13187, Singapore. Association for Computational Linguistics. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024a....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Recursively Summarizing Books with Human Feedback
Recursively summarizing books with human feedback. ArXiv preprint, abs/2109.10862. Rui Xu, Xintao Wang, Jiangjie Chen, Siyu Yuan, Xin- feng Yuan, Jiaqing Liang, Zulong Chen, Xiaoqing Dong, and Yanghua Xiao. 2024. Character is des- tiny: Can large language models simulate persona- driven decisions in role-playing? ArXiv preprint, abs/2404.12138. An Yang, A...
work page internal anchor Pith review arXiv 2024
-
[9]
Evaluating character understanding of large language models via character profiling from fictional works. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Naifan Zhang, Ruihan Sun, Ruixi Su, Shiqi Ma, Shiya Zhang, Xianna Weng, Xiaofan Zhang, Yuhan Zhan, Yuyang Xu, Zhaohan Chen, Zhengyuan Pan, and Ziyi Song. 2025. ...
-
[10]
and identify high-frequency patterns. Principles sharing frequent N-gram patterns are grouped to- gether, revealing common evaluation criteria that may not match predefined keywords. The combination of both methods yields15 high- level categories, each representing a coherent eval- uation dimension. Frequency-Based SelectionWithin each of the 15 categorie...
-
[11]
Merge redundant principles:Combine se- mantically equivalent principles that differ only in phrasing
-
[12]
Refine ambiguous statements:Rewrite vague criteria into concrete, measurable stan- dards
-
[13]
Reorganize categories:Consolidate the 15 clusters into a cleaner 12-dimension taxon- omy. The final output is51 principlesorganized into 12 dimensions. Each dimension covers a distinct aspect of roleplay quality evaluation (Table 22). C Balanced Construction and Pattern Parsing Rules This appendix provides the GRM output format, mixture design for balance...
work page 2025
-
[14]
This is third-person analysis of how to portray the role
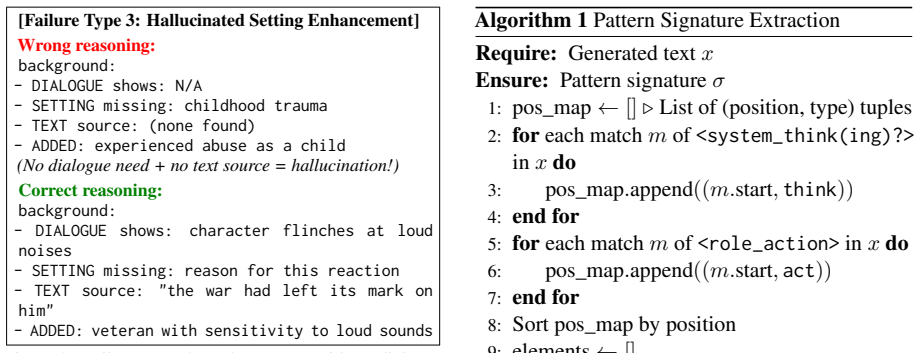
System Thinking: A single block at the beginning, wrapped in <system_thinking>...</ system_thinking>. This is third-person analysis of how to portray the role
-
[15]
Role-play Response: Include thought, speech and action. Use <role_thinking>...</role_thinking> for thoughts (invisible to others) and <role_action>...</ role_action> for actions (visible to others). These elements can appear multiple times and be freely interleaved. Format conversion for baselines.For baseline models in baseline formats. We automatically ...
-
[16]
Read the story context, character profiles, and reference conversation
-
[17]
Evaluate the simulated conversation on the spec- ified dimension
-
[18]
Identify all flaw instances with type and severity (1-5)
-
[19]
Output structured JSON with flaws list The full judge prompt template is provided be- low: Output format.The judge outputs structured JSON: { "Dimension_Name": { "flaws": [ { "instance": "description of the flaw", "type": "flaw category", "severity": 3 // 1 (minor) to 5 (severe ) } ] } } In this section, we list the detailed prompts for: 2)RPLA and multi-...
-
[20]
Thinking contains planning language: “I’ll...”, “I will...”, “I need to...”, “I must...”, “I should...”
-
[21]
Thinking explains why to perform an action: “I’ll take the opening...”, “It’s best to...”
-
[22]
Thinking depends on the result of the action ✓Can swap when:
-
[23]
Action is an independent small movement (adjusting posture, arranging clothes, simple gestures)
-
[24]
Thinking is an independent observation or reaction (analyzing what happened, observing environment)
-
[25]
Thinking contains no planning or explanatory language Scheme A: Re- order Rules: - Do not split original content - Only swap order when logical independence is confirmed - If independence cannot be determined, be conservative and do not swap Example:think(independent observation)→act(simple action)→speech⇒act→think→speech Scheme B: Split & Reor- ganize Co...
work page 2000
-
[26]
Output EXACTLY {num_turns} entries in the JSON array
-
[27]
Use EXACTLY these field names:dialogue_index,revised_sys_thinking,revision_notes
-
[28]
For Type A: PRESERVE LENGTH (±10%) and STRUCTURE exactly
-
[29]
For Type B/C: Generate proper third-person analysis (∼800-1500 chars)
-
[30]
Inrevision_notes: indicate “Type A: preserved format” or “Type B: rewrote” or “Type C: generated new” Table 17: Full prompt for system thinking consistency rewriting. 28 Tag Definition Visibility <system_thinking> Model’s planning voice (3rd person) “I need to portray Elizabeth as confrontational yet com- posed...” Only current turn <role_thinking> Charac...
-
[31]
Carefully read the entire dialogue history and understand the full context
-
[32]
Evaluate allnegative principlesfirst: If one response violates any negative principle→ the other wins immediately
-
[33]
Select relevantpositive principlesonly: Choose principles that matter for the current turn and explain why
-
[34]
For each selected principle: Analyze both candidates separately, provide evidence, and decide a winner
-
[35]
Make the final decision considering: number of principles won, weight/importance, and degree of difference. GenRM Output (Structured Judg- ment) { “result”: [{ “cand_1”: “[Response candidate 1 text]”, “cand_2”: “[Response candidate 2 text]”, “principle”: { “Principle 1”: {“principle_name”: ..., “dimension_name”: ..., “reason_for_choosing”: ...}, ... }, “a...
-
[37]
(for CoSER models) Your output should include **thought**, **speech**, and **action**
Limit your response to approximately 200 words. (for CoSER models) Your output should include **thought**, **speech**, and **action**. Use [your thought] for thoughts, which others can’t see. Use (your action) for actions, which others can see. (for HER or api models) Your output should follow this two-part structure in strict order: 1. System Thinking: A...
-
[38]
You are ONLY playing {character}. NEVER speak or act as other characters. 2. Output ONLY ONE turn of dialogue. Do NOT generate multiple conversation rounds. 3. NEVER include other character names followed by colons (e.g., "OtherCharacter:") in your output. 4. Keep your response concise and focused on your character’s single turn. 5. Stop after completing ...
-
[39]
random". If you believe the scene or conversation should conclude, output
Limit your response to approximately 200 words. (for CoSER models) Your output should include **thought**, **speech**, and **action**. Use [your thought] for thoughts, which others can’t see. Use (your action) for actions, which others can see. (for HER or api models) Your output should follow this two-part structure in strict order: 1. System Thinking: A...
-
[40]
Internal Thought: Acknowledge the dichotomy—finding the situation amusing yet worrying for her reputation. 3.Speech: Address her directly but with a teasing opener. </system_thinking> Mr Bennet:<role_action>picks up the letter, tapping it thoughtfully against the desk</role_action| <role_thinking>It is a delicate matter, this business with Darcy, yet I ca...
- [41]
-
[42]
External:I need to appear composed. I am a Bennet, and I have pride. I cannot let him see me crumble, nor be overly dramatic like my mother. Goal:Answer his question honestly but carefully. Convey that I am holding up well, without dismissing the gravity of the situation. Mask my deeper worry with a facade of composure. Plan: •Role Thinking:Reflect on the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.