Recognition: 2 theorem links
· Lean TheoremConditional Compatibility Learning for Context-Dependent Anomaly Detection
Pith reviewed 2026-05-16 09:55 UTC · model grok-4.3
The pith
Global representations that mix subject and context are provably non-identifiable for context-dependent anomalies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Any detector reasoning from a global representation that conflates subject and context is provably non-identifiable: two different subject-context configurations can map to the same embedding while requiring opposite labels, and no such detector can be correct on both. This impossibility motivates conditional compatibility learning, in which the model determines whether subjects are compatible with their surrounding context. The framework is instantiated in CC-CLIP, a vision-language architecture that learns disentangled subject- and context-aware representations from a single image and fuses visual evidence through text-conditioned attention.
What carries the argument
Conditional compatibility learning, which asks whether a subject is compatible with its specific context rather than whether the observation deviates from global normality, realized through disentangled subject- and context-aware representations fused by text-conditioned attention in CC-CLIP.
If this is right
- CC-CLIP reaches state-of-the-art performance on real-world contextual anomaly detection benchmarks.
- A single-branch variant of CC-CLIP remains competitive on structural anomaly detection tasks.
- Anomaly labels that depend on subject-context relations become identifiable once representations are explicitly disentangled.
- Vision-language models can be adapted to perform compatibility checks without assuming abnormality is intrinsic to the observation.
Where Pith is reading between the lines
- The same disentanglement could be tested on relational tasks beyond anomaly detection, such as determining whether an object belongs in a given scene.
- If the single-image disentanglement holds, extending the approach to video sequences might allow context to be inferred across frames without additional labels.
- Datasets that explicitly annotate subject-context pairs would allow direct measurement of whether global embeddings actually collapse distinct configurations.
Load-bearing premise
The disentangled subject- and context-aware representations can be learned from single images without extra supervision or labels that would recreate the original identifiability problem.
What would settle it
A pair of images showing the same subject in two different contexts that produce identical global embeddings yet require opposite anomaly labels.
Figures












read the original abstract
Anomaly detection usually assumes that abnormality is an intrinsic property of an observation. A defect is a defect, and a rare object is rare, regardless of where it appears. Many real-world anomalies do not work this way. A runner on a track is normal, but the same runner on a highway is not. The subject is unchanged; only the context makes it anomalous. This setting, long recognized as contextual anomaly detection, remains largely underexplored in modern vision-language systems. The difficulty is not merely empirical; it is formal. When anomaly labels depend on the relation between a subject and its context, any detector reasoning from a global representation that conflates subject and context is provably non-identifiable: two different subject-context configurations can map to the same embedding while requiring opposite labels, and no such detector can be correct on both. This impossibility motivates a different formulation: instead of asking whether an observation deviates from a global notion of normality, the model should ask whether subjects are compatible with their surrounding context. We define this as conditional compatibility learning. We instantiate this framework in CC-CLIP, a vision-language architecture that learns disentangled subject- and context-aware representations from a single image and fuses visual evidence through text-conditioned attention. CC-CLIP achieves state-of-the-art results on real-world contextual anomaly detection, substantially outperforming all existing CLIP-based and context-reasoning baselines. A single-branch variant of CC-CLIP also achieves competitive performance on structural anomaly benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that global representations conflating subject and context are provably non-identifiable for context-dependent anomalies, as two configurations can share an embedding yet require opposite labels. It proposes conditional compatibility learning as an alternative formulation and instantiates it in CC-CLIP, a vision-language model that learns disentangled subject- and context-aware representations from single images via text-conditioned attention. The work reports state-of-the-art results on real-world contextual anomaly detection benchmarks and competitive performance on structural anomaly tasks with a single-branch variant.
Significance. If the non-identifiability argument holds and the CC-CLIP architecture demonstrably resolves the identifiability issue through its disentanglement mechanism, the contribution would be significant: it supplies a formal motivation for moving beyond global embeddings in contextual anomaly detection and offers a concrete VLM-based implementation that could influence downstream work on context-aware vision-language systems.
major comments (3)
- [Introduction / non-identifiability claim] The non-identifiability argument is presented as a general proof in the abstract and introduction, but the manuscript does not reduce it to an explicit pair of subject-context configurations (e.g., runner-on-track vs. runner-on-highway) that map to identical embeddings while demanding opposite anomaly labels; without this concrete counterexample, it is difficult to verify that the impossibility result applies to standard CLIP-style global pooling.
- [CC-CLIP architecture description] CC-CLIP is described as learning disentangled subject- and context-aware representations through text-conditioned attention, yet no auxiliary loss, orthogonality constraint, or explicit separation objective is specified to guarantee independence of the two streams; absent such a mechanism, the fused output could remain partially entangled and inherit the same non-identifiability counterexamples.
- [Experiments] The claim of state-of-the-art results on real-world contextual anomaly detection lacks any reference to the specific datasets, evaluation metrics, or baseline implementations used; without these details or ablations isolating the contribution of the disentangled representations, the empirical superiority cannot be assessed.
minor comments (1)
- [Abstract] The abstract mentions a 'single-branch variant' achieving competitive results on structural anomaly benchmarks but does not clarify how this variant differs architecturally from the main two-branch CC-CLIP model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Introduction / non-identifiability claim] The non-identifiability argument is presented as a general proof in the abstract and introduction, but the manuscript does not reduce it to an explicit pair of subject-context configurations (e.g., runner-on-track vs. runner-on-highway) that map to identical embeddings while demanding opposite anomaly labels; without this concrete counterexample, it is difficult to verify that the impossibility result applies to standard CLIP-style global pooling.
Authors: We agree that an explicit counterexample would make the non-identifiability claim easier to verify. The abstract already uses the runner-on-track (normal) versus runner-on-highway (anomalous) scenario to motivate the issue. In the revised manuscript we will add a short formal subsection that constructs these two configurations, shows they collide under global CLIP-style pooling, and derives the opposite required labels, thereby confirming the impossibility result for standard global embeddings. revision: yes
-
Referee: [CC-CLIP architecture description] CC-CLIP is described as learning disentangled subject- and context-aware representations through text-conditioned attention, yet no auxiliary loss, orthogonality constraint, or explicit separation objective is specified to guarantee independence of the two streams; absent such a mechanism, the fused output could remain partially entangled and inherit the same non-identifiability counterexamples.
Authors: The text-conditioned attention mechanism produces separate subject and context streams by conditioning on distinct prompts. We acknowledge that an explicit independence guarantee is currently missing. In the revision we will introduce an orthogonality loss between the subject and context feature vectors and report ablations quantifying its effect on disentanglement and downstream performance. revision: yes
-
Referee: [Experiments] The claim of state-of-the-art results on real-world contextual anomaly detection lacks any reference to the specific datasets, evaluation metrics, or baseline implementations used; without these details or ablations isolating the contribution of the disentangled representations, the empirical superiority cannot be assessed.
Authors: The full manuscript already specifies the real-world contextual benchmarks, AUROC/AUPRC metrics, and the full set of CLIP-based and context-reasoning baselines. To improve accessibility we will add explicit citations to these elements in the abstract and introduction, and include a new ablation table that isolates the contribution of the disentangled representations. revision: partial
Circularity Check
No circularity: non-identifiability claim and CC-CLIP instantiation remain independent
full rationale
The paper states a general non-identifiability result for any global embedding that conflates subject and context, then defines conditional compatibility learning as an alternative formulation and instantiates it in CC-CLIP via text-conditioned attention for disentangled representations. No equation or definition reduces the non-identifiability proof to the CC-CLIP parameters, no fitted input is relabeled as prediction, and no self-citation chain is invoked to justify the core impossibility result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Global representations that conflate subject and context are provably non-identifiable for context-dependent anomaly labels
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 4.1 (Non-identifiability under intrinsic representation collisions)... ϕ(g(a,c))=ϕ(g(a,c′)) but h(a,c)≠h(a,c′)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Context-Selective Residuals (CSR)... Compatibility Reasoning Module (CRM) fuses... text-conditioned attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://cdn.openai.com/papers/ gpt-4.pdf. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pp. 8748–8763. PmLR, 2021. Roth, K., Pemula, L., Zepeda, J., Sch ...
-
[2]
Section A presents additional model details
-
[3]
Section B describes implementation and training de- tails
-
[4]
Section C reports extended ablation studies and addi- tional quantitative results
-
[5]
Section D details the construction, annotation protocol, and evaluation splits of the CAAD-3K dataset
-
[6]
Section E provides full quantitative results across all benchmarks
-
[7]
Section F discusses limitations and directions for future work
-
[8]
Section G presents additional qualitative results. A. Additional Model Details This appendix provides full specifications of the model com- ponents summarized in Section 5, including (i) Context- Selective Residuals (CSR), (ii) text refinement and losses, (iii) the Compatibility Reasoning Module (CRM), and (iv) inference for image- and pixel-level scoring...
work page 2021
-
[9]
a photo of cls in a normal place
with (β1, β2) = (0.5,0.999) . Table 7 summarizes the default hyperparameters used for CAAD-3K, which were kept fixed across all experiments unless otherwise noted. Table 7.Core hyperparameters used in training (default configura- tion for CAAD-3K). Component Setting Text learning rate2×10 −5 Image learning rate3×10 −4 Text refinement depthL= 3layers Image...
work page 2019
-
[10]
and GroundingDINO (Liu et al., 2024). YOLOv8 (Jocher et al., 2023) provides reliable bounding boxes for common object categories, but cannot handle fine-grained action prompts (e.g., “person running”) or uncommon gen- erated categories (e.g., “fire”) absent from its label space. GroundingDINO (Liu et al., 2024), in contrast, performs open-vocabulary groun...
work page 2024
-
[11]
produces diverse paraphrases describing object ap- pearance, actions, and camera viewpoints. This prevents linguistic overfitting and yields a broad range of visual in- stantiations rather than template-like repetitions. Reviewer Assurance:Together, this strategy guarantees that contextual abnormality emerges from semantic rela- tional mismatch, not from ...
-
[12]
rich and balanced class-level semantics,
-
[13]
broad intra-class scene diversity, and
-
[14]
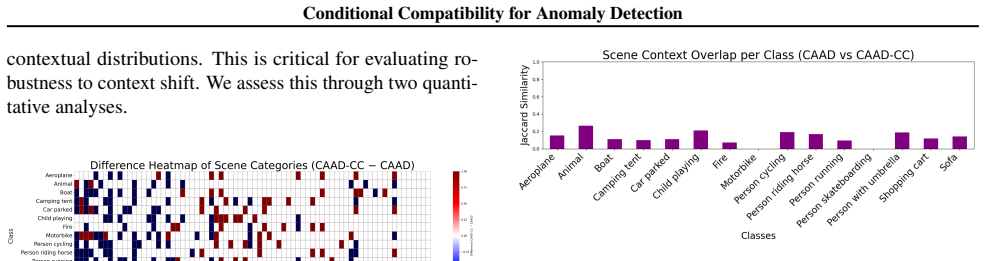
Figure 11.Per-class Jaccard similarity between the sets of scene categories in CAAD-SS and CAAD-CC
controlled inter-split contextual complementarity. Figure 11.Per-class Jaccard similarity between the sets of scene categories in CAAD-SS and CAAD-CC. Similarity scores remain consistently low (0.07–0.27), indicating minimal overlap in con- texts while preserving the semantic identity of each class. This low contextual redundancy is desirable for reliably...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.