Recognition: 2 theorem links
· Lean TheoremDialectLLM: A Dialect-Aware Dialog[ue] Generation Framework Beyond Standard American English
Pith reviewed 2026-05-16 09:50 UTC · model grok-4.3
The pith
A framework generates authentic multi-dialect conversational data for nine English variants by applying linguist-validated rules to Standard American English dialogs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
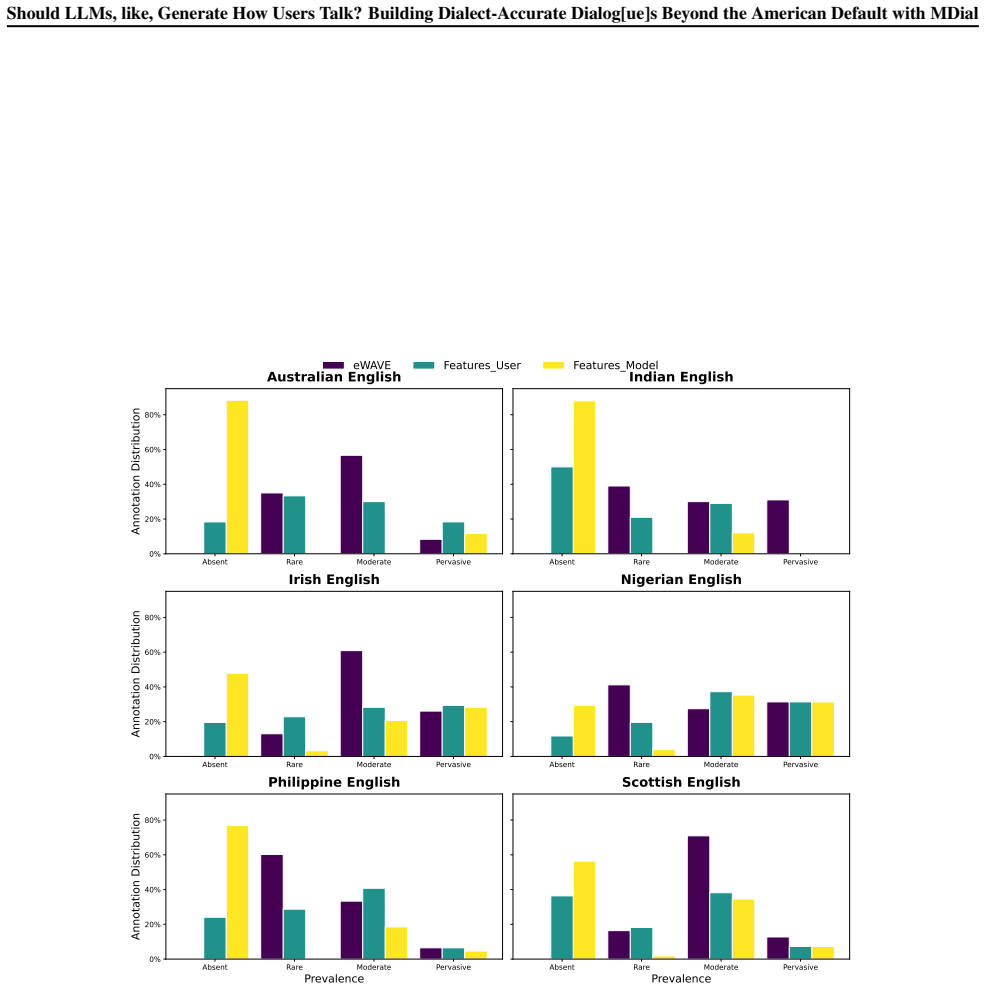
DialectLLM is the first large-scale framework that produces a dialect-parallel dialog dataset spanning nine English dialects through SAE-to-dialect transformation rules designed and validated with native linguists to cover lexical, orthographic, and morphosyntactic features, while demonstrating that models should avoid reproducing up to 90 percent of a dialect's grammatical features in their responses.
What carries the argument
SAE-to-dialect transformation rules that handle lexical, orthographic, and morphosyntactic features separately for user utterances versus model responses and are validated by native linguists for authenticity.
If this is right
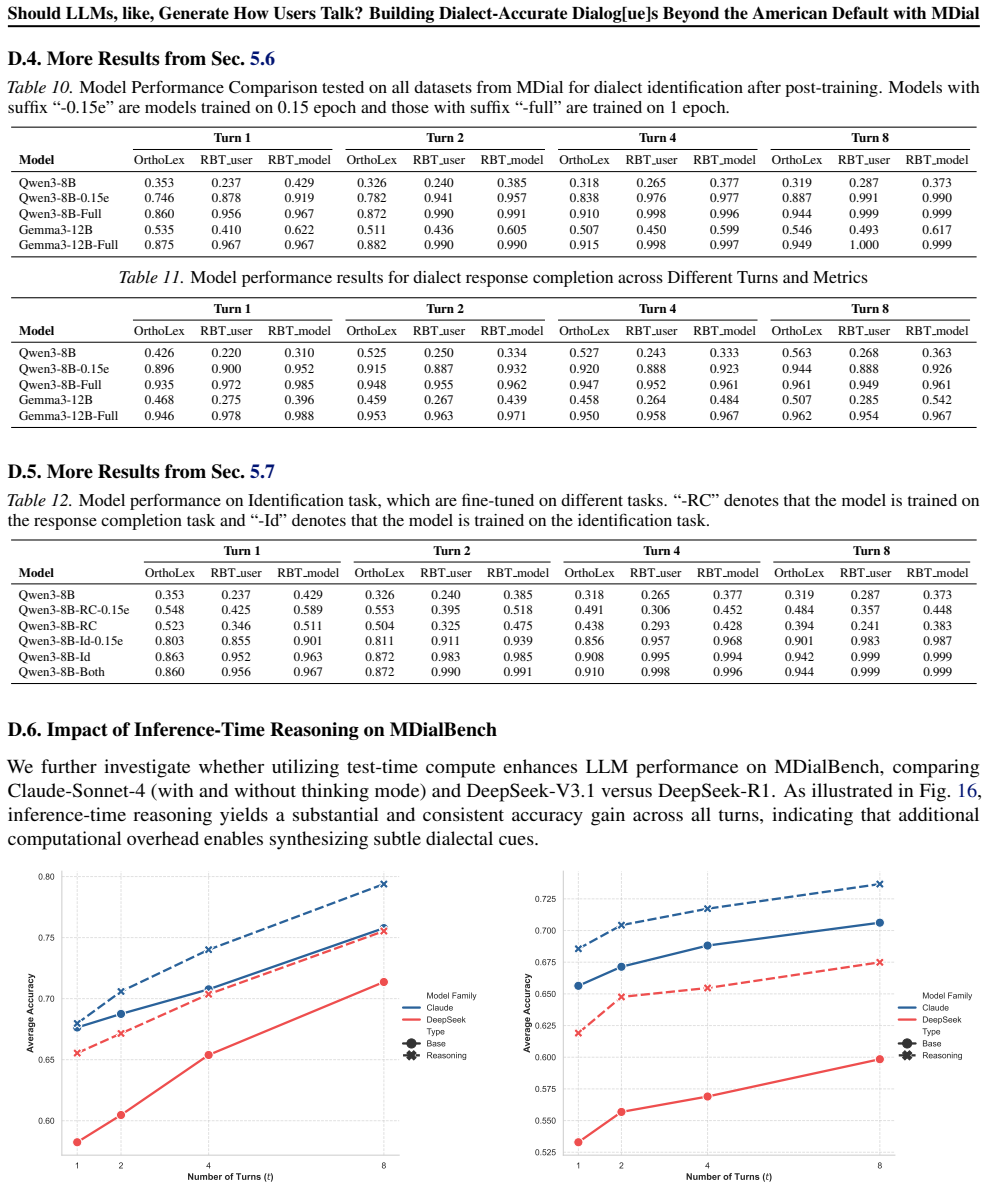
- Frontier models achieve under 70 percent accuracy on dialect identification and under 50 percent for dialects such as Canadian English.
- Non-SAE dialects are systematically misclassified as American or British English by current models.
- The generated data serves as a scalable post-training resource to improve dialect-aware conversational performance.
- Models should not reproduce up to 90 percent of the grammatical features when generating responses in a given dialect.
Where Pith is reading between the lines
- Wider adoption of separate feature rules for responses could reduce stereotypical outputs in global English conversations.
- The parallel dataset structure may support targeted fine-tuning experiments to close specific dialect gaps.
- Similar rule-based transformation approaches could be tested on spoken rather than written dialect data.
- Benchmark results suggest value in expanding evaluation to real-time multi-turn interactions with dialect speakers.
Load-bearing premise
The SAE-to-dialect transformation rules designed and validated with native linguists accurately capture authentic dialect features without introducing new stereotypes or artifacts that human raters would miss.
What would settle it
Native speakers rating DialectLLM-generated dialogs as less natural than real dialect speech or than outputs from earlier methods, or models fine-tuned on the data showing no measurable gains on dialect identification or generation tasks.
Figures
























read the original abstract
More than 80% of the 1.6B English speakers do not use Standard American English (SAE), yet LLMs often fail to correctly identify non-SAE dialects and generate stereotyped responses for their speakers. We introduce DialectLLM, the first large-scale framework for generating high-quality multi-dialectal conversational data encompassing the three pillars of written dialect -- lexical (vocabulary), orthographic (spelling), and morphosyntactic (grammar) features. DialectLLM produces a dialect-parallel dialog dataset spanning nine English dialects. Partnering with native linguists, we design and validate SAE-to-dialect transformation rules, ensuring authenticity. Our approach challenges the prevailing practice of applying a single morphosyntactic feature set to both user utterances and model responses, showing that models should not reproduce up to 90% of the grammatical features of a dialect. Human evaluation confirms data quality, with annotators preferring DialectLLM over prior methods in 98.8% of pairwise comparisons for dialect naturalness. We then construct DialectLLM-Bench, a dialect-parallel benchmark with 50k+ dialogs, resulting in 97k+ QA pairs, and evaluate 17 LLMs on dialect identification and response generation tasks. Even frontier models achieve under 70% accuracy, fail to reach 50% for prominent dialects like Canadian English, and systematically misclassify non-SAE dialects as American or British. Beyond benchmarking, we show that DialectLLM data also serve as a scalable LLM post-training resource, suggesting a practical path toward dialect-aware conversational AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DialectLLM, a framework for generating high-quality multi-dialectal dialog data across nine English dialects using SAE-to-dialect transformation rules designed and validated with native linguists. It reports a human evaluation with 98.8% annotator preference for naturalness over prior methods, constructs the DialectLLM-Bench benchmark containing over 50k dialogs and 97k QA pairs, evaluates 17 LLMs showing poor performance on dialect identification and generation (under 70% accuracy, below 50% for some dialects), and demonstrates the data's value as a post-training resource.
Significance. If the results hold, the work is significant for advancing dialect-aware AI, given that over 80% of English speakers use non-SAE dialects. The linguist-validated rules, extensive human preference study, and new benchmark provide concrete resources and evidence of current LLM limitations. The approach of separating user and response grammar features is a useful insight. The availability of the dataset for post-training is a practical contribution.
major comments (2)
- [Human Evaluation] Human Evaluation section: The reported 98.8% preference rate in pairwise comparisons for dialect naturalness lacks error bars, inter-annotator agreement statistics, details on the number of annotators, or their selection criteria, which are necessary to assess the reliability of the human evaluation results supporting data quality.
- [Abstract] Abstract: The statement that models should not reproduce up to 90% of the grammatical features of a dialect lacks a clear derivation or empirical basis for the specific 90% threshold; this appears central to the framework's design but requires more justification to support the challenge to prevailing practices.
minor comments (2)
- [Title] Title: The title includes 'Dialog[ue]', which appears to be a formatting artifact and should be corrected to 'Dialogue' for consistency.
- [Abstract] Abstract: The abstract mentions 'three pillars of written dialect' but could briefly list the nine dialects covered to provide immediate context.
Simulated Author's Rebuttal
We appreciate the referee's positive recommendation for minor revision and constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Human Evaluation] Human Evaluation section: The reported 98.8% preference rate in pairwise comparisons for dialect naturalness lacks error bars, inter-annotator agreement statistics, details on the number of annotators, or their selection criteria, which are necessary to assess the reliability of the human evaluation results supporting data quality.
Authors: We agree that these details are important for assessing reliability. The original manuscript reported the aggregate preference rate but did not include the supporting statistics. We have revised the Human Evaluation section to add the number of annotators, their selection criteria, inter-annotator agreement statistics, and error bars on the reported preference rate. revision: yes
-
Referee: [Abstract] Abstract: The statement that models should not reproduce up to 90% of the grammatical features of a dialect lacks a clear derivation or empirical basis for the specific 90% threshold; this appears central to the framework's design but requires more justification to support the challenge to prevailing practices.
Authors: The 90% threshold is derived from the linguist-validated experiments described in Section 3, where applying 90% or more of the morphosyntactic features to model responses was rated as less natural. To address the comment, we have revised the abstract to briefly note this empirical basis and expanded the justification in the main text with reference to the specific validation results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core contributions rest on externally validated SAE-to-dialect transformation rules developed with native linguists, large-scale human preference evaluations (98.8% win rate), and construction of a new falsifiable benchmark (DialectLLM-Bench). No equations, fitted parameters presented as predictions, or self-citation chains reduce any claim to its own inputs by construction. The argument structure relies on independent empirical evidence rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can reliably distinguish authentic dialect naturalness from generated text.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Partnering with native linguists, we design and validate SAE-to-dialect transformation rules... up to 90% of the grammatical features of a dialect should not be reproduced by models.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct MDialBench... evaluate 17 LLMs on dialect identification and response generation tasks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
URL https://aclanthology.org/2023. emnlp-main.421/. Deas, N., Vente, B., Ananthram, A., Grieser, J. A., Patton, D. U., Kleiner, S., Iii, J. R. S., and McKeown, K. Data caricatures: On the representation of African American language in pretraining corpora. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proceed- ings of the 63rd Annual Mee...
-
[4]
Is llm-as- a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment
URL https://aclanthology.org/2025. acl-long.1252/. Fleisig, E., Smith, G., Bossi, M., Rustagi, I., Yin, X., and Klein, D. Linguistic bias in ChatGPT: Language models reinforce dialect discrimination. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Nat- ural Language Processing, pp. 13541–1...
-
[5]
Francesco D’Angelo, Maksym Andriushchenko, Aditya Vardhan Varre, and Nicolas Flammarion
URL https://aclanthology.org/2024. emnlp-main.750/. Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y ., Ma, S., Liu, H., et al. A survey on llm-as-a- judge.The Innovation, 2024. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek-r1 incentivizes reasoning in llms through reinf...
-
[6]
URL https://aclanthology.org/2025. findings-emnlp.913/. Held, W., Ziems, C., and Yang, D. TADA : Task agnostic dialect adapters for English. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.),Findings of the Association for Computational Linguistics: ACL 2023, pp. 813–824, Toronto, Canada, July 2023. Association for Computa- tional Linguistics. doi: 1...
-
[7]
doi: 10.18653/v1/2024.findings-acl
URL https://aclanthology.org/2023. findings-acl.51/. Hofmann, V ., Kalluri, P. R., Jurafsky, D., and King, S. Ai generates covertly racist decisions about people based on their dialect.Nature, 633(8028):147–154, 2024. Holt, F., Held, W., and Yang, D. Perceptions of lan- guage technology failures from South Asian English speakers. In Ku, L.-W., Martins, A....
-
[8]
URL https://aclanthology.org/2024. findings-acl.241/. Joshi, A., Dabre, R., Kanojia, D., Li, Z., Zhan, H., Haffari, G., and Dippold, D. Natural language processing for di- alects of a language: A survey.ACM Comput. Surv., 57(6), February 2025. ISSN 0360-0300. doi: 10.1145/3712060. URLhttps://doi.org/10.1145/3712060. Kortmann, B., Lunkenheimer, K., and Ehr...
-
[9]
Lin, F., Mao, S., La Malfa, E., Hofmann, V ., de Wynter, A., Wang, X., Chen, S.-Q., Wooldridge, M
URL https://openreview.net/forum? id=YIpvHrQAks. Lin, F., Mao, S., La Malfa, E., Hofmann, V ., de Wynter, A., Wang, X., Chen, S.-Q., Wooldridge, M. J., Pierre- humbert, J. B., and Wei, F. Assessing dialect fairness and robustness of large language models in reasoning tasks. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proceedings of th...
-
[10]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[11]
URL https://aclanthology.org/2025. acl-long.317/. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024. Liu, Y ., Held, W., and Yang, D. DADA: Dialect adap- tation via dynamic aggregation of linguistic rules. In Bouamor, H., Pino, J., and Ba...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.emnlp-main 2025
-
[12]
B leu: a Method for Automatic Evaluation of Machine Translation
URL https://aclanthology.org/2023. emnlp-main.850/. Mihalcea, R., Ignat, O., Bai, L., Borah, A., Chiruzzo, L., Jin, Z., Kwizera, C., Nwatu, J., Poria, S., and Solorio, T. Why ai is weird and shouldn’t be this way: To- wards ai for everyone, with everyone, by everyone.Pro- ceedings of the AAAI Conference on Artificial Intelli- gence, 39(27):28657–28670, Ap...
-
[13]
URL https://aclanthology.org/2023. emnlp-main.487/. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. Yong, Z.-X., Zhang, R., Forde, J. Z., Wang, S., Subramo- nian, A., Lovenia, H., Cahyawijaya, S., Winata, G. I., Sutawika, L., Cruz, J. C. B.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2022 2023
-
[14]
Feature is required in this locale.It would sound unnatural if the speaker used the original sentence instead of the transformed sentence. US example: Possessive: The transformed sentence uses to “my object” when the original sentence uses “me object” [Tips for Model Mirror? Column] For each feature listed, please evaluate LLM/voice agent’s capabilities i...
-
[15]
An LLM/voice agent should understand this term but not generate it
Feature exists but is rare.The word/spelling might be understood but is outdated, region-specific, or influenced by other dialects. An LLM/voice agent should understand this term but not generate it. 3.Feature exists and is commonly used in colloquial speech.The word/spelling is widespread in informal Irish English but may coexist with other variants. Bot...
-
[16]
Feature is required in this locale.Using the US variant would sound unnatural or incorrect. The Irish variant is the standard and expected form. Examples: US IE note Rating Explanation (Optional) Excellent, Great Savage lexical Fruitcake Barmbrack lexical -or (e.g., color, favor) -our (e.g., colour, favour) orthographic Figure 6.Guidelines provided to Iri...
work page 2023
-
[17]
V1 isgreatly preferredover V2
-
[18]
V1 issomewhat preferredover V2
-
[19]
No clear preference between V1 and V2
-
[20]
V2 issomewhat preferredover V1
-
[21]
V2 isgreatly preferredover V1 Order was randomly shuffled to ensure no annotation bias. We provide the following additional annotation instructions: For the USER annotations:Which version is more representative of how users from your country speak in day-to-day conversation? We are trying to capture colloquial expressions (e.g., “y’all” instead of “you al...
work page 2024
-
[22]
The Conversation History (Conversation history of previous turns)
-
[23]
The Current User Turn (The message the Assistant must reply to)
-
[24]
A list of Candidate Options for the Assistant’s response. Instructions: • Analyze the {sentence} of the ’Conversation History’ and ’Current User Turn’ to identify the specific English dialect being used. •Evaluate the ’Candidate Options’ and select the one that is linguistically consistent with the identified dialect from the conversation history and curr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.