Recognition: no theorem link
Adaptive Prompt Elicitation for Text-to-Image Generation
Pith reviewed 2026-05-16 07:26 UTC · model grok-4.3
The pith
Adaptive Prompt Elicitation improves text-to-image alignment by using visual queries to infer and refine user intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
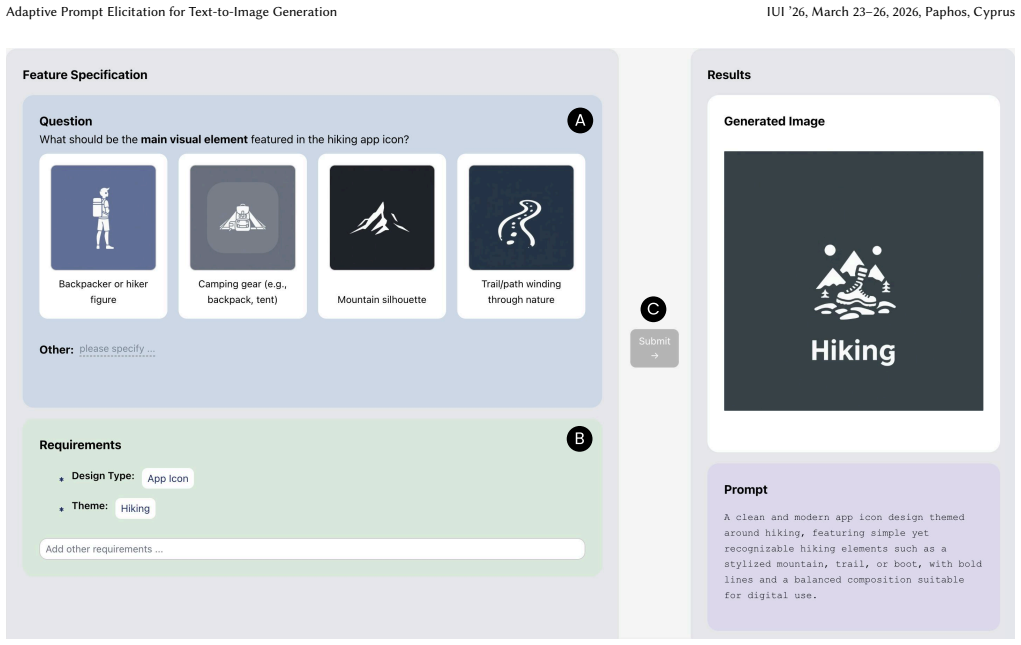
APE represents latent user intent as interpretable feature requirements using language model priors, adaptively generates visual queries under an information-theoretic framework to maximize information gain, and compiles the elicited requirements into effective prompts that produce stronger alignment with user intent than standard text-only interaction.
What carries the argument
The information-theoretic framework for interactive intent inference that selects visual queries to reduce uncertainty about user feature preferences.
If this is right
- APE produces stronger alignment with improved efficiency on IDEA-Bench and DesignBench.
- A 128-participant study on user-defined tasks reports 19.8 percent higher perceived alignment without added workload.
- Users refine prompts through visual queries rather than writing extensive text.
- The method supplies a principled complement to ordinary prompt-based interaction with text-to-image models.
Where Pith is reading between the lines
- The same elicitation loop could be tested on text-to-video or text-to-3D generators to check whether intent matching improves there too.
- Integrating the inferred features directly into image-editing controls might let users adjust outputs without returning to text.
- Lowering the writing barrier could widen access to generative tools for users who find prompt engineering difficult.
Load-bearing premise
Language model priors can turn vague user intent into reliable, interpretable feature lists and users will give accurate answers to the generated visual queries across varied tasks.
What would settle it
A side-by-side test in which participants give the same initial ambiguous prompt to both APE and a standard text-only system, then rate how well the resulting images match their stated goals; if APE shows no reliable improvement in match scores, the central claim fails.
Figures













read the original abstract
Aligning text-to-image generation with user intent remains challenging, as users frequently provide ambiguous inputs and struggle with model idiosyncrasies. We propose Adaptive Prompt Elicitation (APE), a technique that adaptively poses visual queries to help users refine prompts without extensive writing. Our technical contribution is a formulation of interactive intent inference under an information-theoretic framework. APE represents latent user intent as interpretable feature requirements using language model priors, adaptively generates visual queries, and compiles elicited requirements into effective prompts. Evaluation on IDEA-Bench and DesignBench shows that APE achieves stronger alignment with improved efficiency. A user study with 128 participants on user-defined tasks demonstrates 19.8% higher perceived alignment without increased workload. Our work contributes a principled approach to prompting that offers an effective and efficient complement to the prevailing prompt-based interaction paradigm with text-to-image models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Prompt Elicitation (APE), a technique for text-to-image generation that uses an information-theoretic framework to adaptively generate visual queries. These queries elicit interpretable feature requirements from users based on language model priors, which are then compiled into refined prompts. The approach is evaluated on IDEA-Bench and DesignBench, where it reportedly achieves stronger alignment and improved efficiency compared to baselines. A user study with 128 participants on user-defined tasks shows 19.8% higher perceived alignment without increased workload.
Significance. If the empirical results hold under scrutiny, APE represents a meaningful contribution to HCI for generative AI by shifting from static prompt writing to an interactive, query-driven elicitation process grounded in information theory. This could reduce user effort in aligning outputs with intent, offering a scalable complement to existing T2I interfaces. The use of LM priors for feature interpretation and adaptive querying is a potentially generalizable idea that addresses a practical pain point in creative workflows.
major comments (3)
- [Abstract and §3] Abstract and §3 (formulation): The central information-theoretic framework for adaptive visual query generation is described at a high level but lacks the explicit objective function, entropy-based selection criterion, or pseudocode for how queries are chosen given current beliefs about user intent. This detail is load-bearing for claims of improved efficiency.
- [Evaluation sections] Evaluation sections: The abstract states that APE achieves 'stronger alignment with improved efficiency' on IDEA-Bench and DesignBench, yet provides no quantitative metrics (e.g., FID, CLIP score deltas), baseline definitions, or statistical significance tests. Without these, the support for the primary empirical claim cannot be verified.
- [User study section] User study section: The reported 19.8% higher perceived alignment with 128 participants is a key result, but the manuscript summary omits details on questionnaire design, workload measurement instrument (e.g., NASA-TLX), randomization procedure, or handling of multiple comparisons. These controls are necessary to substantiate the 'without increased workload' conclusion.
minor comments (2)
- [Abstract] Abstract: Consider specifying the exact alignment metrics and efficiency measures used in the benchmark evaluations to improve immediate readability.
- [Technical sections] Notation: Ensure consistent use of symbols for information gain and feature requirements across the technical sections to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. Where the comments identify opportunities for greater clarity or completeness, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (formulation): The central information-theoretic framework for adaptive visual query generation is described at a high level but lacks the explicit objective function, entropy-based selection criterion, or pseudocode for how queries are chosen given current beliefs about user intent. This detail is load-bearing for claims of improved efficiency.
Authors: We agree that the formulation benefits from explicit formalization. In the revised manuscript, we have expanded §3 to state the objective function (maximization of expected information gain, defined as mutual information between the query response and the posterior over latent intent features), the entropy-based selection criterion (selecting the visual query that minimizes expected posterior entropy), and pseudocode for the full adaptive loop: initialize uniform prior over features, iteratively select query, elicit binary response, update posterior via Bayes rule, and terminate when entropy falls below threshold. These additions directly substantiate the efficiency claims. revision: yes
-
Referee: [Evaluation sections] Evaluation sections: The abstract states that APE achieves 'stronger alignment with improved efficiency' on IDEA-Bench and DesignBench, yet provides no quantitative metrics (e.g., FID, CLIP score deltas), baseline definitions, or statistical significance tests. Without these, the support for the primary empirical claim cannot be verified.
Authors: We acknowledge that the evaluation presentation can be strengthened for verifiability. The revised manuscript now includes a dedicated results table with quantitative metrics (CLIP score and FID deltas relative to baselines), explicit definitions of all baselines (standard prompting, non-adaptive random querying, and fixed-template methods), and statistical significance tests (paired t-tests with reported p-values). Efficiency is quantified as mean number of queries to reach target alignment. These details were part of our analysis and are now foregrounded in the main text. revision: yes
-
Referee: [User study section] User study section: The reported 19.8% higher perceived alignment with 128 participants is a key result, but the manuscript summary omits details on questionnaire design, workload measurement instrument (e.g., NASA-TLX), randomization procedure, or handling of multiple comparisons. These controls are necessary to substantiate the 'without increased workload' conclusion.
Authors: We agree that methodological transparency is essential. The revised user study section now details the questionnaire (7-point Likert items for perceived alignment and intent match), workload assessment via the full NASA-TLX instrument, randomization of task order and condition assignment, and application of Bonferroni correction for multiple comparisons. These additions confirm that the reported alignment gain occurred without a significant workload increase. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces Adaptive Prompt Elicitation (APE) as a new formulation of interactive intent inference under an information-theoretic framework, where latent user intent is represented as interpretable feature requirements via language model priors, followed by adaptive visual query generation and prompt compilation. No equations, fitted parameters, or self-citations are present in the provided text that would reduce the claimed alignment gains or efficiency improvements to quantities defined by the inputs themselves. The central claims are supported by direct empirical evaluations on IDEA-Bench, DesignBench, and a 128-participant user study, which serve as independent external benchmarks rather than internal reductions. This makes the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language model priors can represent latent user intent as interpretable feature requirements
- domain assumption Adaptive visual queries selected by information-theoretic criteria will efficiently elicit requirements that improve prompt alignment
Reference graph
Works this paper leans on
-
[1]
Woźniak, Julia Dominiak, Andrzej Ro- manowski, Jakob Karolus, and Stanislav Frolov
Krzysztof Adamkiewicz, Paweł W. Woźniak, Julia Dominiak, Andrzej Ro- manowski, Jakob Karolus, and Stanislav Frolov. 2025. PromptMap: An Alternative Interaction Style for AI-Based Image Generation. InProceedings of the 30th Interna- tional Conference on Intelligent User Interfaces (IUI ’25). Association for Computing Machinery, New York, NY, USA, 1162–1176...
-
[2]
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. Easily Accessible Text-to-Image Generation Amplifies Demo- graphic Stereotypes at Large Scale. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’23)...
-
[3]
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. 2024. Training Diffusion Models with Reinforcement Learning. In The Twelfth Interna- tional Conference on Learning Representations
work page 2024
-
[4]
Stephen Brade, Bryan Wang, Mauricio Sousa, Sageev Oore, and Tovi Grossman
-
[5]
In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23)
Promptify: Text-to-Image Generation through Interactive Prompt Explo- ration with Large Language Models. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23) . Association for Computing Machinery, New York, NY, USA, 1–14. doi:10.1145/3586183.3606725
-
[6]
Eric Brochu, Tyson Brochu, and Nando de Freitas. 2010. A Bayesian interactive optimization approach to procedural animation design. In Proceedings of the 2010 ACM SIGGRAPH/Eurographics Symposium on Computer Animation . 103–112
work page 2010
-
[7]
Chengkun Cai, Haoliang Liu, Xu Zhao, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, John Lee, Jenq-Neng Hwang, and Lei Li. 2025. Bayesian Optimization for Controlled Image Editing via LLMs. In Findings of the Association for Computa- tional Linguistics: ACL 2025. Association for Computational Linguistics, Vienna, Austria, 10045–10056. doi:10.18653/v1/2025.fin...
-
[8]
Tingfeng Cao, Chengyu Wang, Bingyan Liu, Ziheng Wu, Jinhui Zhu, and Jun Huang. 2023. BeautifulPrompt: Towards Automatic Prompt Engineering for Text- to-Image Synthesis. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track . Association for Computational Linguistics, Singapore, 1–11. doi:10.18653/v1/2023...
-
[9]
Jane Castleman and Aleksandra Korolova. 2025. Adultification Bias in LLMs and Text-to-Image Models. In Proceedings of the 2025 ACM Conference on Fair- ness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 2751–2767. doi:10.1145/3715275.3732178
-
[10]
Kathryn Chaloner and Isabella Verdinelli. 1995. Bayesian Experimental Design: A Review. Statist. Sci. 10, 3 (1995), 273–304
work page 1995
-
[11]
Zijie Chen, Lichao Zhang, Fangsheng Weng, Lili Pan, and Zhenzhong Lan. 2024. Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7727–7736
work page 2024
-
[12]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep Reinforcement Learning from Human Preferences. Advances in Neural Information Processing Systems 30 (2017)
work page 2017
-
[13]
Wei Chu and Zoubin Ghahramani. 2005. Preference Learning with Gaussian Processes. In Proceedings of the 22nd International Conference on Machine Learning - ICML ’05. ACM Press, Bonn, Germany, 137–144. doi:10.1145/1102351.1102369
-
[14]
John Joon Young Chung and Eytan Adar. 2023. PromptPaint: Steering Text- to-Image Generation Through Paint Medium-like Interactions. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23). Association for Computing Machinery, New York, NY, USA, 1–17. doi:10.1145/3586183.3606777
-
[15]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Defossez. 2023. Simple and Controllable Music Generation. Advances in Neural Information Processing Systems 36 (2023), 47704–47720
work page 2023
-
[16]
Siddhartha Datta, Alexander Ku, Deepak Ramachandran, and Peter Anderson
-
[17]
Prompt Expansion for Adaptive Text-to-Image Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 3449–3476. doi:10.18653/v1/2024.acl-long.189
-
[18]
Sebastian Deterding, Jonathan Hook, Rebecca Fiebrink, Marco Gillies, Jeremy Gow, Memo Akten, Gillian Smith, Antonios Liapis, and Kate Compton. 2017. Mixed-Initiative Creative Interfaces. In Proceedings of the 2017 CHI Confer- ence Extended Abstracts on Human Factors in Computing Systems (CHI EA ’17). Association for Computing Machinery, New York, NY, USA,...
-
[19]
Moreno D’Incà, Elia Peruzzo, Massimiliano Mancini, Dejia Xu, Vidit Goe, Xingqian Xu, Zhangyang Wang, Humphrey Shi, and Nicu Sebe. 2024. OpenBias: Open-Set Bias Detection in Text-to-Image Generative Models. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . 12225–12235. doi:10.1109/CVPR52733.2024.01162
- [20]
-
[21]
Xianzhe Fan, Qing Xiao, Xuhui Zhou, Jiaxin Pei, Maarten Sap, Zhicong Lu, and Hong Shen. 2025. User-Driven Value Alignment: Understanding Users’ Perceptions and Strategies for Addressing Biased and Discriminatory Statements in AI Companions. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing...
-
[22]
Franz Faul, Edgar Erdfelder, Axel Buchner, and Albert-Georg Lang. 2009. Sta- tistical power analyses using G* Power 3.1: Tests for correlation and regression analyses. Behavior research methods 41, 4 (2009), 1149–1160
work page 2009
-
[23]
Yingchaojie Feng, Xingbo Wang, Kam Kwai Wong, Sijia Wang, Yuhong Lu, Min- feng Zhu, Baicheng Wang, and Wei Chen. 2024. PromptMagician: Interactive Prompt Engineering for Text-to-Image Creation. IEEE Transactions on Visualiza- tion and Computer Graphics 30, 1 (Jan. 2024), 295–305. doi:10.1109/TVCG.2023. 3327168
-
[24]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. 2023. DreamSim: Learning New Dimensions of Human Visual Similarity Using Synthetic Data. Advances in Neural Information Processing Systems 36 (2023), 50742–50768
work page 2023
-
[25]
Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep Bayesian Active Learning with Image Data. In Proceedings of the 34th International Conference on Machine Learning. PMLR, 1183–1192
work page 2017
- [26]
-
[27]
Yuhan Guo, Hanning Shao, Can Liu, Kai Xu, and Xiaoru Yuan. 2025. PrompTHis: Visualizing the Process and Influence of Prompt Editing during Text-to-Image Creation. 31, 9 (2025), 4547–4559. doi:10.1109/TVCG.2024.3408255
-
[28]
Shashank Gupta, Vaishnavi Shrivastava, Ameet Deshpande, Ashwin Kalyan, Peter Clark, Ashish Sabharwal, and Tushar Khot. 2024. Bias Runs Deep: Im- plicit Reasoning Biases in Persona-Assigned LLMs. In The Twelfth International Conference on Learning Representations
work page 2024
-
[29]
Meera Hahn, Wenjun Zeng, Nithish Kannen, Rich Galt, Kartikeya Badola, Been Kim, and Zi Wang. 2025. Proactive Agents for Multi-Turn Text-to-Image Gen- eration Under Uncertainty. In Forty-Second International Conference on Machine Learning
work page 2025
-
[30]
Shu-Jung Han and Susan R. Fussell. 2025. Understanding User Perceptions and the Role of AI Image Generators in Image Creation Workflows. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2025-04-25) (CHI ’25). Association for Computing Machinery, 1–17. doi:10.1145/3706598.3713227
-
[31]
Yaru Hao, Zewen Chi, Li Dong, and Furu Wei. 2023. Optimizing Prompts for Text-to-Image Generation. Advances in Neural Information Processing Systems 36 (2023), 66923–66939
work page 2023
-
[32]
Sandra G Hart and Lowell E Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in psy- chology. Vol. 52. Elsevier, 139–183
work page 1988
-
[33]
Pappas, Hamed Hassani, Yuki Mitsufuji, Ruslan Salakhut- dinov, and J Zico Kolter
Yutong He, Alexander Robey, Naoki Murata, Yiding Jiang, Joshua Nathaniel Williams, George J. Pappas, Hamed Hassani, Yuki Mitsufuji, Ruslan Salakhut- dinov, and J Zico Kolter. 2025. Automated Black-box Prompt Engineering for Personalized Text-to-Image Generation. Transactions on Machine Learning Re- search (2025)
work page 2025
-
[34]
Nailei Hei, Qianyu Guo, Zihao Wang, Yan Wang, Haofen Wang, and Wenqiang Zhang. 2024. A User-Friendly Framework for Generating Model-Preferred Prompts in Text-to-Image Synthesis. Proceedings of the AAAI Conference on Artificial Intelligence 38, 3 (March 2024), 2139–2147. doi:10.1609/aaai.v38i3.27986
-
[35]
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel
-
[36]
Bayesian Active Learning for Classification and Preference Learning
Bayesian Active Learning for Classification and Preference Learning. arXiv:1112.5745 [stat.ML] https://arxiv.org/abs/1112.5745
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Hsiu-Fang Hsieh and Sarah E Shannon. 2005. Three approaches to qualitative content analysis. Qualitative health research 15, 9 (2005), 1277–1288. Adaptive Prompt Elicitation for Text-to-Image Generation IUI ’26, March 23–26, 2026, Paphos, Cyprus
work page 2005
-
[38]
Daolang Huang, Yujia Guo, Luigi Acerbi, and Samuel Kaski. 2024. Amortized Bayesian Experimental Design for Decision-Making. Advances in Neural Infor- mation Processing Systems 37 (2024), 109460–109486
work page 2024
-
[39]
Rahul Jain, Amit Goel, Koichiro Niinuma, and Aakar Gupta. 2025. AdaptiveSliders: User-aligned Semantic Slider-based Editing of Text-to-Image Model Output. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–27. doi:10.1145/3706598.3714292
-
[40]
Kaixuan Ji, Jiafan He, and Quanquan Gu. 2025. Reinforcement Learning from Human Feedback with Active Queries.Transactions on Machine Learning Research (2025)
work page 2025
-
[41]
Ironies of Generative AI: Understanding and mitigating productivity loss in human-AI interactions,
Soomin Kim, Jinsu Eun, Changhoon Oh, and Joonhwan Lee. 2025. “Journey of Finding the Best Query”: Understanding the User Experience of AI Image Generation System. International Journal of Human–Computer Interaction 41, 2 (2025), 951–969. doi:10.1080/10447318.2024.2307670
-
[42]
Andreas Kirsch, Joost van Amersfoort, and Yarin Gal. 2019. BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning. Advances in Neural Information Processing Systems 32 (2019)
work page 2019
-
[43]
Kasia Kobalczyk, Nicolás Astorga, Tennison Liu, and Mihaela van der Schaar
-
[44]
In The Thirteenth International Conference on Learning Representations
Active Task Disambiguation with LLMs. In The Thirteenth International Conference on Learning Representations
-
[45]
Yuki Koyama and Masataka Goto. 2022. BO as Assistant: Using Bayesian Op- timization for Asynchronously Generating Design Suggestions. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology (UIST ’22). Association for Computing Machinery, New York, NY, USA, 1–14. doi:10.1145/3526113.3545664
-
[46]
Yuki Koyama, Issei Sato, and Masataka Goto. 2020. Sequential Gallery for In- teractive Visual Design Optimization. ACM Trans. Graph. 39, 4 (Aug. 2020), 88:88:1–88:88:12. doi:10.1145/3386569.3392444
-
[47]
Black Forest Labs. 2025. FLUX.1 - a Black-Forest-Labs Collection. https:// huggingface.co/collections/black-forest-labs/flux1 Accessed: 2025-10-10
work page 2025
-
[48]
Daniel Lee, Nikhil Sharma, Donghoon Shin, DaEun Choi, Harsh Sharma, Jeongh- wan Kim, and Heng Ji. 2025. ThematicPlane: Bridging Tacit User Intent and Latent Spaces for Image Generation. In Adjunct Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST Adjunct ’25) . Association for Computing Machinery, New York, NY, U...
-
[49]
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. 2023. Aligning Text-to-Image Models using Human Feedback. arXiv:2302.12192 [cs.LG] https: //arxiv.org/abs/2302.12192
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Li, Alex Tamkin, Noah Goodman, and Jacob Andreas
Belinda Z. Li, Alex Tamkin, Noah Goodman, and Jacob Andreas. 2025. Elicit- ing Human Preferences with Language Models. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[51]
Chen Liang, Lianghua Huang, Jingwu Fang, Huanzhang Dou, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Junge Zhang, Xin Zhao, and Yu Liu. 2025. IDEA-Bench: How Far Are Generative Models from Professional Designing?. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 18541–18551
work page 2025
-
[52]
Haichuan Lin, Yilin Ye, Jiazhi Xia, and Wei Zeng. 2025. SketchFlex: Facilitating Spatial-Semantic Coherence in Text-to-Image Generation with Region-Based Sketches. In Proceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–19. doi:10.1145/3706598.3713801
-
[53]
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. 2024. Evaluating Text-to-Visual Genera- tion with Image-to-Text Generation. In European Conference on Computer Vision . Springer, 366–384
work page 2024
-
[54]
Shihong Liu, Samuel Yu, Zhiqiu Lin, Deepak Pathak, and Deva Ramanan. 2024. Language Models as Black-Box Optimizers for Vision-Language Models. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 12687–12697
work page 2024
-
[55]
Vivian Liu and Lydia B Chilton. 2022. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2022-04-29) (CHI ’22). Association for Computing Machinery, 1–23. doi:10.1145/3491102.3501825
-
[56]
Ryan Louie, Andy Coenen, Cheng Zhi Huang, Michael Terry, and Carrie J. Cai
-
[57]
Novice-AI Music Co-Creation via AI-Steering Tools for Deep Generative Models. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/3313831.3376739
-
[58]
Shuai Ma, Zijun Wei, Feng Tian, Xiangmin Fan, Jianming Zhang, Xiaohui Shen, Zhe Lin, Jin Huang, Radomír Měch, Dimitris Samaras, et al . 2019. SmartEye: assisting instant photo taking via integrating user preference with deep view proposal network. In Proceedings of the 2019 CHI conference on human factors in computing systems. 1–12
work page 2019
-
[59]
Atefeh Mahdavi Goloujeh, Anne Sullivan, and Brian Magerko. 2024. Is It AI or Is It Me? Understanding Users’ Prompt Journey with Text-to-Image Generative AI Tools. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2024-05-11) (CHI ’24). Association for Computing Machinery, 1–13. doi:10.1145/3613904.3642861
-
[60]
Saaduddin Mahmud, Mason Nakamura, and Shlomo Zilberstein. 2025. MAPLE: A Framework for Active Preference Learning Guided by Large Language Models. Proceedings of the AAAI Conference on Artificial Intelligence 39, 26 (April 2025), 27518–27528. doi:10.1609/aaai.v39i26.34964
-
[61]
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal
-
[62]
Transactions on Machine Learning Research (2024)
Improving Text-to-Image Consistency via Automatic Prompt Optimization. Transactions on Machine Learning Research (2024)
work page 2024
-
[63]
Henry B Mann and Donald R Whitney. 1947. On a Test of Whether One of Two Random Variables Is Stochastically Larger than the Other. The Annals of Mathematical Statistics 18, 1 (1947), 50–60. jstor:2236101
work page 1947
-
[64]
OpenAI. 2025. Vector embeddings. https://platform.openai.com/docs/guides/ embeddings Accessed: 2025-10-10
work page 2025
-
[65]
Jonas Oppenlaender. 2024. A Taxonomy of Prompt Modifiers for Text-to-Image Generation. Behaviour & Information Technology 43, 15 (Nov. 2024), 3763–3776. doi:10.1080/0144929X.2023.2286532
-
[66]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po- Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick La...
work page 2024
-
[67]
Christiano, Jan Leike, and Ryan Lowe
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training Language Models to Follow Instructions with Huma...
work page 2022
-
[68]
Srishti Palani and Gonzalo Ramos. 2024. Evolving Roles and Workflows of Creative Practitioners in the Age of Generative AI. In Proceedings of the 16th Conference on Creativity & Cognition (C&C ’24) . Association for Computing Machinery, New York, NY, USA, 170–184. doi:10.1145/3635636.3656190
-
[69]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model. In Advances in Neural Information Processing Systems, Vol. 36. 53728–53741
work page 2023
-
[70]
Tom Rainforth, Adam Foster, Desi R Ivanova, and Freddie Bickford Smith. 2024. Modern Bayesian Experimental Design. Statist. Sci. 39, 1 (2024), 100–114
work page 2024
-
[71]
Philip Resnik. 2025. Large Language Models Are Biased Because They Are Large Language Models. Computational Linguistics 51, 3 (Sept. 2025), 885–906. doi:10.1162/coli_a_00558
-
[72]
Jeba Rezwana and Mary Lou Maher. 2023. Designing Creative AI Partners with COFI: A Framework for Modeling Interaction in Human-AI Co-Creative Systems. ACM Trans. Comput.-Hum. Interact.30, 5, Article 67 (Sept. 2023), 28 pages. doi:10.1145/3519026
-
[73]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
work page 2022
-
[74]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2022. Photo- realistic Text-to-Image Diffusion Models with Deep Language Understanding. Advances in Neural Information Processing Systems 35 (2022)...
work page 2022
-
[75]
Téo Sanchez. 2023. Examining the Text-to-Image Community of Practice: Why and How Do People Prompt Generative AIs?. In Proceedings of the 15th Confer- ence on Creativity and Cognition (New York, NY, USA, 2023-06-19) (C&C ’23). Association for Computing Machinery, 43–61. doi:10.1145/3591196.3593051
-
[76]
Jonathan W Schooler and Tonya Y Engstler-Schooler. 1990. Verbal overshadowing of visual memories: Some things are better left unsaid. Cognitive Psychology 22, 1 (1990), 36–71. doi:10.1016/0010-0285(90)90003-M
-
[77]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[78]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG] https: //arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Savvas Petridis, Yi-Hao Peng, Li Qiwei, Chenglei Si, Yutong Xie, Jeffrey P. Bigham, Frank Bentley, Joyce Chai, Zachary Chase Lipton, Qiaozhu Mei, Michael Terry, Diyi Yang, Meredith Ringel Morris, Paul Resnick, and David Jurgens. 2025. Position: Towards Bidirectional Human-...
work page 2025
-
[80]
Xinyu Shi, Yinghou Wang, Ryan Rossi, and Jian Zhao. 2025. Brickify: Enabling Expressive Design Intent Specification through Direct Manipulation on Design Tokens. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, IUI ’26, March 23–26, 2026, Paphos, Cyprus Wen e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.