Action Hallucination in Generative Vision-Language-Action Models
Pith reviewed 2026-05-16 07:27 UTC · model grok-4.3
The pith
Generative vision-language-action models produce action hallucinations from structural mismatches with physical robot constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hallucinations can arise from structural mismatches between feasible robot behavior and common model architectures. Focusing on latent-variable generative policies, the analysis studies three barriers—topological, precision, and horizon—and shows how they impose unavoidable tradeoffs, providing mechanistic explanations for reported empirical failures of generative robot policies.
What carries the argument
The three barriers (topological mismatches in action-space connectivity, precision limits on continuous actions, and horizon inconsistencies in long sequences) that arise in latent-variable generative policies and force tradeoffs between generalization and physical validity.
If this is right
- Action hallucinations extend beyond single steps to produce plan-level failures in robot policies.
- Many reported empirical failures of generative robot policies receive mechanistic explanations tied to the three barriers.
- Reliability can be improved through principled changes that address the barriers while preserving the models' generative and generalization capabilities.
Where Pith is reading between the lines
- Similar architectural mismatches may limit reliability in other generative models applied to physical or sequential domains beyond robotics.
- Hybrid approaches that combine generative components with explicit constraint enforcement could bypass the tradeoffs identified here.
- Empirical tests could isolate each barrier by constructing controlled environments that probe topology, precision, or horizon separately.
Load-bearing premise
That the topological, precision, and horizon barriers are the main structural causes of hallucinations and create unavoidable tradeoffs unless the generative latent-variable architecture itself is fundamentally altered.
What would settle it
A latent-variable generative VLA that achieves reliable physical action generation across varied robot tasks without any change to its core architecture or loss of expressive power would falsify the claim.
Figures

read the original abstract
Robot Foundation Models, such as VLAs, promise end-to-end generative robot policies with broad generalization. Yet it remains unclear whether they fundamentally resolve the core problem of action generation in embodied settings, or overcome the long-standing challenges of robotics. We address this question by analyzing action hallucinations that violate physical constraints and their extension to plan-level failures. Focusing on latent-variable generative policies, we show that hallucinations can arise from structural mismatches between feasible robot behavior and common model architectures. We study three such barriers -- topological, precision, and horizon -- and show how they impose unavoidable tradeoffs. Our analysis provides mechanistic explanations for reported empirical failures of generative robot policies and suggests principled directions for improving reliability and trustworthiness, without abandoning their expressive power.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes action hallucinations in generative vision-language-action (VLA) models, focusing on latent-variable generative policies. It identifies three structural barriers—topological, precision, and horizon—that arise from mismatches between feasible robot behavior and common model architectures, arguing that these impose unavoidable tradeoffs and provide mechanistic explanations for empirical failures in robot foundation models.
Significance. If the structural analysis holds, the work offers a principled framework for understanding why generative policies violate physical constraints, moving beyond empirical observations to identify root architectural causes. This could guide targeted improvements in VLA reliability without sacrificing expressivity, and it highlights the need for architectural variants that address these barriers.
major comments (2)
- [Sections on the three barriers] The central claim that the three barriers impose unavoidable tradeoffs within the latent-variable generative policy class lacks a formal reduction or proof showing that any model in this class must suffer at least one barrier. The argument relies on specific choices of latent dimensionality, sampling, and single-level generation (see the sections defining the topological, precision, and horizon barriers), which could potentially be relaxed by hierarchical latents or adaptive precision while remaining in the same family.
- [Abstract and analysis sections] The analysis asserts that hallucinations arise from structural mismatches but provides no quantitative bounds, derivations, or empirical tests to support the 'unavoidable' characterization or to measure the tradeoffs (e.g., no equations bounding the precision-horizon interaction or falsifiable predictions for specific VLA architectures).
minor comments (1)
- [Barrier definitions] Notation for the barriers could be clarified with explicit definitions or diagrams to distinguish them from general model capacity issues.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key opportunities to strengthen the formal grounding of our analysis. We have revised the manuscript to clarify the scope of our claims regarding the three barriers and to incorporate additional discussion on extensions such as hierarchical models.
read point-by-point responses
-
Referee: [Sections on the three barriers] The central claim that the three barriers impose unavoidable tradeoffs within the latent-variable generative policy class lacks a formal reduction or proof showing that any model in this class must suffer at least one barrier. The argument relies on specific choices of latent dimensionality, sampling, and single-level generation (see the sections defining the topological, precision, and horizon barriers), which could potentially be relaxed by hierarchical latents or adaptive precision while remaining in the same family.
Authors: We acknowledge that the manuscript presents a conceptual and mechanistic analysis rather than a complete formal proof of unavoidability across the entire class. The barriers are derived from the properties of standard single-level latent-variable policies with fixed-dimensional latents, as commonly implemented in current VLAs. In the revision, we have added a dedicated subsection examining hierarchical latent models and adaptive precision, showing that these variants typically shift rather than eliminate the core topological, precision, and horizon mismatches. We include a sketch of why a full reduction would require additional assumptions outside the standard generative policy family. revision: partial
-
Referee: [Abstract and analysis sections] The analysis asserts that hallucinations arise from structural mismatches but provides no quantitative bounds, derivations, or empirical tests to support the 'unavoidable' characterization or to measure the tradeoffs (e.g., no equations bounding the precision-horizon interaction or falsifiable predictions for specific VLA architectures).
Authors: We agree that quantitative support would strengthen the presentation. The revised manuscript now includes explicit derivations for the precision-horizon tradeoff (added to Section 3) and a new table in the discussion section listing falsifiable predictions for representative architectures such as RT-2 and OpenVLA. Full empirical validation of these predictions is noted as future work, as it lies outside the scope of the current theoretical analysis. revision: yes
Circularity Check
No significant circularity; analysis is self-contained structural reasoning
full rationale
The paper's core argument identifies topological, precision, and horizon barriers as sources of action hallucinations in latent-variable generative policies and claims they impose unavoidable tradeoffs. This rests on comparisons between feasible robot behavior and common model architectures rather than any equations, fitted parameters, or self-citations that reduce the conclusions to the inputs by construction. No load-bearing steps match the enumerated circularity patterns; the derivation does not rename known results, smuggle ansatzes via citation, or treat predictions as equivalent to fitted inputs. The analysis is therefore independent and self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent-variable generative policies are representative of current VLAs and exhibit the described structural mismatches with feasible robot behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
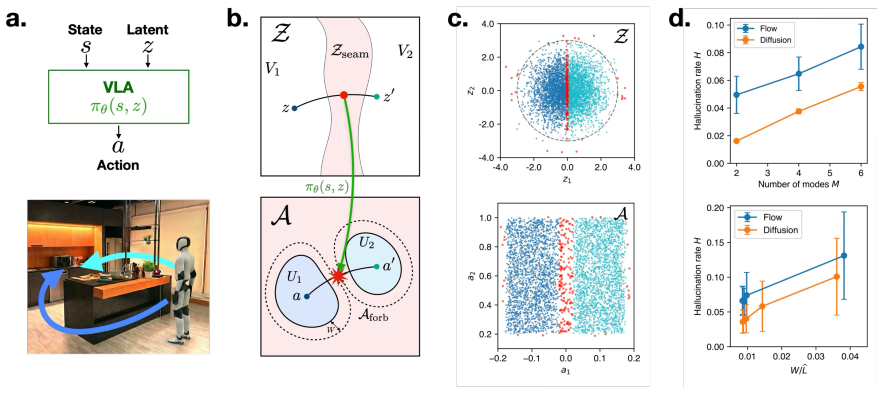
Lemma 10 (Topological Barrier): ... any continuous latent-to-action map that covers both safe modes can be hallucination-free at s.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
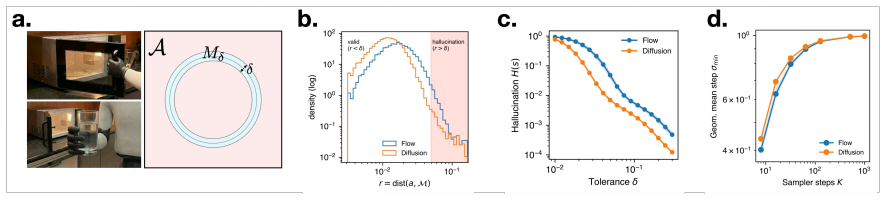
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kua...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Minkowski content for reachable sets.manuscripta mathematica, 131(3):507–530, 2010
Piermarco Cannarsa, Marc-Olivier Czarnecki, et al. Minkowski content for reachable sets.manuscripta mathematica, 131(3):507–530, 2010
work page 2010
-
[4]
John Canny.Complexity of Robot Motion Planning. PhD thesis, MIT, 1988
work page 1988
-
[5]
Dif- fusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[6]
Liu Dai, Haina Wang, Weikang Wan, and Hao Su. Mani- taskgen: A comprehensive task generator for benchmark- ing and improving vision-language agents on embodied decision-making. 2025
work page 2025
-
[7]
Safeflow: Safe robot motion planning with flow matching via control barrier functions, 2025
Xiaobing Dai, Zewen Yang, Dian Yu, Fangzhou Liu, Hamid Sadeghian, Sami Haddadin, and Sandra Hirche. Safeflow: Safe robot motion planning with flow matching via control barrier functions, 2025
work page 2025
-
[8]
Diffusion meets options: Hierarchical generative skill composition for temporally-extended tasks
Zeyu Feng, Hao Luan, Kevin Yuchen Ma, and Harold Soh. Diffusion meets options: Hierarchical generative skill composition for temporally-extended tasks. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10854–10860, 2025
work page 2025
-
[9]
Scaling up and distilling down: Language-guided robot skill acquisition
Huy Ha, Pete Florence, and Shuran Song. Scaling up and distilling down: Language-guided robot skill acquisition. InConference on Robot Learning, pages 3766–3777. PMLR, 2023
work page 2023
-
[10]
Abstracting robot manipulation skills via mixture-of- experts diffusion policies
Ce Hao, Xuanran Zhai, Yaohua Liu, and Harold Soh. Abstracting robot manipulation skills via mixture-of- experts diffusion policies. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[11]
Kris Hauser and Jean-Claude Latombe. Multi-modal mo- tion planning in non-expansive spaces.The International Journal of Robotics Research, 29(7):897–915, 2010
work page 2010
- [12]
-
[13]
David Hsu, Jean-Claude Latombe, and Hanna Kurniawati. On the probabilistic foundations of probabilistic roadmap planning.The International Journal of Robotics Research, 25(7):627–643, 2006
work page 2006
-
[14]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Trans. Inf. Syst., 43(2), January 2025. ISSN 1046-8188
work page 2025
-
[15]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas God- den, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter...
work page 2025
-
[16]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Unveiling the latent space geometry of push-forward generative models
Thibaut Issenhuth, Ugo Tanielian, Jeremie Mary, and David Picard. Unveiling the latent space geometry of push-forward generative models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learn- ing, volume 202 ofProceedings of Machi...
work page 2023
-
[18]
Path planning under kinematic constraints by rapidly exploring manifolds
L´eonard Jaillet and Josep M Porta. Path planning under kinematic constraints by rapidly exploring manifolds. IEEE Transactions on Robotics, 29(1):105–117, 2012
work page 2012
-
[19]
Survey of hallucination in natural language generation.ACM Comput
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12), March 2023. ISSN 0360-0300
work page 2023
-
[20]
Towards diverse behaviors: A benchmark for imitation learning with human demonstrations
Xiaogang Jia, Denis Blessing, Xinkai Jiang, Moritz Reuss, Atalay Donat, Rudolf Lioutikov, and Gerhard Neumann. Towards diverse behaviors: A benchmark for imitation learning with human demonstrations. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[21]
Herman Kahn and Theodore E Harris. Estimation of particle transmission by random sampling.National Bureau of Standards applied mathematics series, 12:27– 30, 1951
work page 1951
-
[22]
Adam Tauman Kalai and Santosh S. Vempala. Calibrated language models must hallucinate. InProceedings of the 56th Annual ACM Symposium on Theory of Computing (STOC), 2024
work page 2024
-
[23]
Mahyar Khayatkhoei, Maneesh K. Singh, and Ahmed Elgammal. Disconnected manifold learning for generative adversarial networks. In Samy Bengio, Hanna Wallach, Hugo Larochelle, Kristen Grauman, Nicol `o Cesa-Bianchi, and Roman Garnett, editors,Advances in Neural Infor- mation Processing Systems 31, pages 7354–7364. Curran Associates, Inc., 2018
work page 2018
-
[24]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024
work page 2024
-
[25]
Robomonkey: Scaling test-time sampling and verification for vision-language-action models
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Foutter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models. In Second Workshop on Out-of-Distribution Generalization in Robotics at RSS 2025, 2025
work page 2025
-
[26]
Molmoact: Action reasoning models that can reason in space, 2025
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. Molmoact: Action reasoning models that can reason in space, 2025
work page 2025
-
[27]
Reducing hallucinations in large vision-language models via latent space steering
Sheng Liu, Haotian Ye, and James Zou. Reducing hallucinations in large vision-language models via latent space steering. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[28]
RDT-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1b: a diffusion foundation model for bimanual manipulation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[29]
Tomas Lozano-Perez, Matthew T Mason, and Russell H Taylor. Automatic synthesis of fine-motion strategies for robots.The International Journal of Robotics Research, 3(1):3–24, 1984
work page 1984
-
[30]
Tomas Lozano-P´erez. Spatial planning: A configuration space approach.IEEE Transactions on Computers, C-32 (2):108–120, 1979
work page 1979
-
[31]
Matthew Mason. The mechanics of manipulation. In Proceedings. 1985 IEEE International Conference on Robotics and Automation, volume 2, pages 544–548. IEEE, 1985
work page 1985
-
[32]
Matthew T Mason. Compliance and force control for computer controlled manipulators.IEEE Transactions on Systems, Man, and Cybernetics, 11(6):418–432, 1981
work page 1981
-
[33]
Rectifiability; a survey.arXiv preprint arXiv:2112.00540, 2021
Pertti Mattila. Rectifiability; a survey.arXiv preprint arXiv:2112.00540, 2021
-
[34]
Gr00t n1: An open foundation model for generalist humanoid robots, 2025
NVIDIA, :, Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed,...
work page 2025
-
[35]
NVIDIA, :, Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, Liang Feng, Greg Heinrich, Jack Huang, Peter Karkus, Boyi Li, Pinyi Li, Tsung-Yi Lin, Dongran Liu, Ming-Yu Liu, Langechuan Liu, Zhijian Liu, Jason Lu, Yunxiang Mao, Pavlo Molchanov, Lindsey Pavao, Zhenghao Peng, Mike Ranzinger, ...
work page 2026
-
[36]
Much ado about noising: Dispelling the myths of generative robotic control, 2025
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, and Max Simchowitz. Much ado about noising: Dispelling the myths of generative robotic control, 2025
work page 2025
-
[37]
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and infer- ence.Journal of Machine Learning Research, 22(57): 1–64, 2021
work page 2021
-
[38]
Complexity of the mover’s problem and generalizations
John H Reif. Complexity of the mover’s problem and generalizations. In20th Annual Symposium on Foundations of Computer Science (sfcs 1979), pages 421–
work page 1979
-
[39]
IEEE Computer Society, 1979
work page 1979
-
[40]
Efficient reductions for imitation learning
St´ephane Ross and Drew Bagnell. Efficient reductions for imitation learning. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 661–668. JMLR Workshop and Confer- ence Proceedings, 2010
work page 2010
-
[41]
Springer Science & Business Media, 2004
Reuven Y Rubinstein and Dirk P Kroese.The cross- entropy method: a unified approach to combinatorial op- timization, Monte-Carlo simulation and machine learning. Springer Science & Business Media, 2004
work page 2004
-
[42]
Antoine Salmona, Valentin De Bortoli, Julie Delon, and Agnes Desolneux. Can push-forward generative models fit multimodal distributions?Advances in Neural Information Processing Systems, 35:10766–10779, 2022
work page 2022
-
[43]
Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
work page 2024
-
[44]
Resampling base distributions of normalizing flows
Vincent Stimper, Bernhard Sch ¨olkopf, and Jose Miguel Hernandez-Lobato. Resampling base distributions of normalizing flows. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors,Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 ofProceedings of Machine Learning Research, pages 4915–49...
work page 2022
-
[45]
Learning disconnected manifolds: a no GAN’s land
Ugo Tanielian, Thibaut Issenhuth, Elvis Dohmatob, and Jeremie Mary. Learning disconnected manifolds: a no GAN’s land. In Hal Daum ´e III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9418–9427. PMLR, 13–18 Jul 2020
work page 2020
-
[46]
Halluci- nation is inevitable: An innate limitation of large language models, 2025
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Halluci- nation is inevitable: An innate limitation of large language models, 2025
work page 2025
-
[47]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. Embodiedbench: Com- prehensive benchmarking multi-modal large language models for vision-driven embodied agents. InForty- second International Conference on Machine Learning, 2025
work page 2025
-
[48]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large language models. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[49]
Monte carlo tree diffusion for system 2 planning
Jaesik Yoon, Hyeonseo Cho, Doojin Baek, Yoshua Bengio, and Sungjin Ahn. Monte carlo tree diffusion for system 2 planning. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[50]
Robotic control via embodied chain-of-thought reasoning
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[51]
Vfp: Variational flow-matching policy for multi-modal robot manipulation, 2025
Xuanran Zhai, Qianyou Zhao, Qiaojun Yu, and Ce Hao. Vfp: Variational flow-matching policy for multi-modal robot manipulation, 2025
work page 2025
-
[52]
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation. 2024
work page 2024
-
[53]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11142–11152, Oct...
work page 2025
-
[54]
Large language models as commonsense knowledge for large-scale task planning
Zirui Zhao, Wee Sun Lee, and David Hsu. Large language models as commonsense knowledge for large-scale task planning. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[55]
Language agent tree search unifies reasoning acting and planning in language models, 2023
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models, 2023
work page 2023
-
[56]
ACTIONHALLUCINATION INGENERATIVE VISUAL-LANGUAGE-ACTIONMODELS
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michalewski...
work page 2023
-
[57]
Density:ρ Z(z)≤ρ max Z
-
[58]
Jacobian: forz∈Z δ,|detJ F (z)| ≥(σ min(JF (z)))d ≥σ ∗(δ)d. Substituting these bounds into the sum gives, for a.e.a∈ M δ, p(a|s)≤ X z∈F −1(a)∩U ρmax Z σ∗(δ)d = #{z∈Z δ :F(z) =a} ·ρ max Z ·σ ∗(δ)−d. Taking the essential supremum overa∈ M δ yields ess sup a∈Mδ p(a|s)≤N δρmax Z σ∗(δ)−d. Applying Lemma 14, Hθ(s;δ)≥1−C M δd−k ·ess sup a∈Mδ p(a|s), and substitu...
-
[59]
Topology reappears at the progress/chunk level.Even if Asafe(s) is connected for small one-step controls, theprogressset Aprog(s, t) can be disconnected at reachability bottlenecks. Two small safe actions can lead into different time-bounded reachable basins Σt−1, while “in-between” actions can be safe butnon-progress(leading to dead ends or timeouts). Ch...
-
[60]
Precision compounds within a chunk.In contact-rich tasks (Section IV-B), progress may require staying in a thin tube (or near a manifold) over multiple successive steps. Requiring consecutive steps in the chunk to remain in such a tube makes the feasible region effectively thinner, decreasing the per-sample mass of Aprog(s, t) (often sharply) as the chunk...
-
[61]
Horizon compounding improves in count, worsens in mass.If the policy outputs chunks of length ℓ and commits to executing them, then Lemma 17 applies with aneffectivehorizon of roughly ⌈T /ℓ⌉. Increasing ℓ reduces the number of factors in this product (helping the horizon barrier) but typically decreases each factor γt (harder chunk feasibility due to topo...
-
[62]
Sampling is deterministic Euler (or Heun) integration fromt= 1tot= 0starting at Gaussian noise. • Diffusion.We train a v-pred diffusion model with cosine schedule (default T= 200 ) and exponential moving average (EMA) of parameters. Training uses MSE on the v-prediction target. Sampling is deterministic DDIM (i.e. η= 0 ) with a user-specified number of sa...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.