Learning to Configure Agentic AI Systems
Pith reviewed 2026-05-22 11:25 UTC · model grok-4.3
The pith
Dynamically learning per-query agent configurations improves LLM accuracy on reasoning and tool-use tasks over fixed templates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARC formulates agent configuration as a semi-Markov decision process where each possible combination of workflow, tools, token budget, and prompt serves as a temporally extended option, then trains a lightweight hierarchical policy to select the option best suited to the current query. Across reasoning, tool-use, and agentic benchmarks this learned selection raises average reasoning accuracy by 31.3 percent, tool-use accuracy by 13.95 percent, and doubles Pass^1 success on the tau-Bench Airline task from 9.0 percent to 18.0 percent relative to budget-matched tool-augmented baselines. The results establish that replacing one-size-fits-all designs with query-specific learned configurations is,
What carries the argument
ARC, the lightweight hierarchical policy that selects query-specific agent configurations treated as temporally extended options inside a semi-Markov decision process.
If this is right
- ARC raises average reasoning accuracy by 31.3 percent while staying within the same compute budget as the baselines.
- Tool-use accuracy increases by 13.95 percent through query-specific choice of workflows and tools.
- Pass^1 success on the tau-Bench Airline task doubles from 9.0 percent to 18.0 percent.
- Per-query adaptation replaces hand-tuned heuristics with a policy that matches configuration effort to query difficulty.
- The approach demonstrates that treating configurations as learnable options in an SMDP can outperform static agent designs.
Where Pith is reading between the lines
- If the discretization into options remains tractable, the same hierarchical selection idea could be applied to other combinatorial choices such as prompt ensembles or model routing.
- Deployed systems might automatically lower token budgets on easy queries and raise them only when needed, producing measurable savings at scale.
- A direct follow-up experiment would test whether a policy trained on one underlying language model transfers to a different model without retraining.
Load-bearing premise
The space of agent configurations can be discretized into a manageable collection of reusable options whose values can be learned by a hierarchical policy without prohibitive sample complexity or overfitting to the training queries.
What would settle it
Training ARC on one collection of queries and then evaluating it on a fresh collection drawn from a noticeably different distribution; if the accuracy and success-rate gains over fixed configurations largely disappear, the claim that the learned policy generalizes usefully would be falsified.
Figures





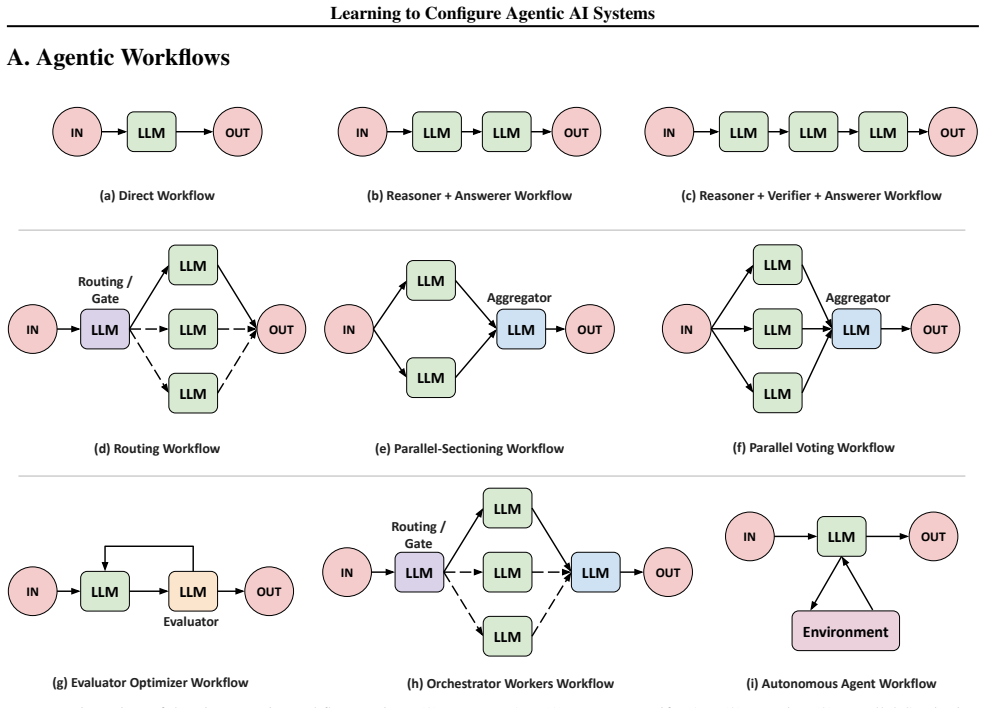






read the original abstract
Configuring LLM-based agent systems involves choosing workflows, tools, token budgets, and prompts from a large combinatorial design space, and is typically handled today by fixed templates or hand-tuned heuristics that apply the same configuration regardless of query difficulty, leading to brittle behavior and wasted compute. To address this, we formulate agent configuration as a semi-Markov decision process (SMDP) where each configuration acts as a temporally extended option that determines how an agent system processes a query, and introduce introduce ARC (Agentic Resource & Configuration learner), a lightweight hierarchical policy that dynamically selects query-specific agent configurations. Across reasoning, tool-use, and agentic benchmarks, ARC consistently improves over budget-matched tool-augmented LLMs, increasing average reasoning accuracy by 31.3%, tool-use accuracy by 13.95%, and doubling {\tau}-Bench (Airline) Pass^1 success from 9.0% to 18.0%. These results demonstrate that learning per-query agent configurations is a powerful alternative to "one size fits all" designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates agent configuration as a semi-Markov decision process (SMDP) in which each choice of workflow, tools, token budget, and prompt is a temporally extended option, and introduces ARC, a lightweight hierarchical policy that learns to select query-specific configurations. It reports that ARC improves over budget-matched tool-augmented LLM baselines, raising average reasoning accuracy by 31.3 %, tool-use accuracy by 13.95 %, and doubling τ-Bench (Airline) Pass^1 success from 9.0 % to 18.0 %.
Significance. If the empirical gains are shown to arise from genuine per-query adaptation rather than selection of a strong fixed configuration, the work would demonstrate a practical alternative to static heuristics in combinatorial agent design spaces and could influence how resource allocation is handled in deployed LLM agents.
major comments (2)
- [Abstract] Abstract: the reported numeric improvements (31.3 % reasoning, 13.95 % tool-use, doubling Pass^1 from 9.0 % to 18.0 %) are presented without any description of the training procedure, the cardinality of the discretized option set, the number of training queries, the specific RL algorithm for the hierarchical policy, run-to-run variance, or statistical tests; these omissions prevent assessment of whether the gains reflect dynamic adaptation or a strong fixed configuration.
- [SMDP formulation and ARC] SMDP formulation and ARC description: the central claim rests on the assumption that the space of agent configurations can be discretized into a manageable set of options whose values are learnable by the hierarchical policy without prohibitive sample complexity or overfitting to the training query distribution; the manuscript provides no explicit size of the option set, number of training examples, or empirical checks for generalization versus overfitting.
minor comments (1)
- [Abstract] Abstract contains a duplicated word: 'introduce introduce ARC'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, agreeing that additional details on training and the option space are needed for clarity. Revisions will be made to incorporate these elements without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported numeric improvements (31.3 % reasoning, 13.95 % tool-use, doubling Pass^1 from 9.0 % to 18.0 %) are presented without any description of the training procedure, the cardinality of the discretized option set, the number of training queries, the specific RL algorithm for the hierarchical policy, run-to-run variance, or statistical tests; these omissions prevent assessment of whether the gains reflect dynamic adaptation or a strong fixed configuration.
Authors: We agree that the abstract lacks sufficient context on the experimental setup. In the revised manuscript we will expand the abstract with a concise description of the training procedure, the cardinality of the discretized option set, the number of training queries, the specific RL algorithm used for the hierarchical policy, run-to-run variance across seeds, and the statistical tests performed. Corresponding details will also be added to the main text and a new appendix to demonstrate that gains arise from per-query adaptation rather than a fixed configuration. revision: yes
-
Referee: [SMDP formulation and ARC] SMDP formulation and ARC description: the central claim rests on the assumption that the space of agent configurations can be discretized into a manageable set of options whose values are learnable by the hierarchical policy without prohibitive sample complexity or overfitting to the training query distribution; the manuscript provides no explicit size of the option set, number of training examples, or empirical checks for generalization versus overfitting.
Authors: We acknowledge that the manuscript would benefit from more explicit statements on these points. The revised version will state the size of the option set, the number of training examples, and include empirical checks such as performance on held-out queries to show generalization and address potential overfitting. These additions will strengthen the justification for the SMDP formulation and the learnability of the hierarchical policy. revision: yes
Circularity Check
No circularity: empirical gains measured on held-out benchmarks against external baselines
full rationale
The paper formulates agent configuration as an SMDP and introduces the ARC hierarchical policy as a method to select query-specific configurations. Reported improvements (31.3% reasoning accuracy, 13.95% tool-use accuracy, doubling of τ-Bench success) are obtained by direct comparison to budget-matched tool-augmented LLMs on standard benchmarks. No equations, fitted parameters, or self-citations are shown that reduce these gains to quantities defined or optimized inside the same experiment; the evaluation uses held-out test distributions and external baselines, keeping the derivation chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Policy hyperparameters and option discretization granularity
axioms (1)
- domain assumption Agent configuration choices can be represented as temporally extended options in a semi-Markov decision process.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate agent configuration as a semi-Markov decision process (SMDP) where each configuration acts as a temporally extended option... ARC (Agentic Resource & Configuration learner), a lightweight hierarchical policy that dynamically selects query-specific agent configurations.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Reward R = α·I[correct] − βs·nsteps − βt·ntokens/Tmax + η·Rtool
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
URL https:// github.com/langchain-ai/langchain. Ac- cessed: 2025-01-12. Chen, L., Zaharia, M., and Zou, J. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Dua, D., Wang, Y ., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. Drop: A reading comprehension bench- mark requiring discrete reasoning over paragraphs.arXiv preprint arXiv:1903.00161,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[7]
Token-budget-aware llm reasoning
Han, T., Wang, Z., Fang, C., Zhao, S., Ma, S., and Chen, Z. Token-budget-aware llm reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 24842–24855,
work page 2025
-
[8]
Llmlingua: Compressing prompts for accelerated inference of large language models
URL https: //research.trychroma.com/context-rot. Jiang, H., Wu, Q., Lin, C.-Y ., Yang, Y ., and Qiu, L. Llmlin- gua: Compressing prompts for accelerated inference of large language models.arXiv preprint arXiv:2310.05736,
-
[9]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., San- thanam, K., Vardhamanan, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., et al. Dspy: Compiling declarative language model calls into self-improving pipelines.arXiv preprint arXiv:2310.03714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
AgentBench: Evaluating LLMs as Agents
Liu, X., Yu, H., Zhang, H., Xu, Y ., Lei, X., Lai, H., Gu, Y ., Ding, H., Men, K., Yang, K., et al. Agentbench: Evalu- ating llms as agents.arXiv preprint arXiv:2308.03688,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
H., Constant, N., Ma, J., Hall, K., Cer, D., and Yang, Y
Ni, J., Abrego, G. H., Constant, N., Ma, J., Hall, K., Cer, D., and Yang, Y . Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. InFindings of the association for computational linguistics: ACL 2022, pp. 1864–1874,
work page 2022
-
[12]
Y ., Yuan, W., Cho, K., He, H., Sukhbaatar, S., and Weston, J
Pang, R. Y ., Yuan, W., Cho, K., He, H., Sukhbaatar, S., and Weston, J. Iterative reasoning preference optimization. In arXiv preprint arXiv:2404.19733,
-
[13]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
9 Learning to Configure Agentic AI Systems Qin, Y ., Liang, S., Ye, Y ., Zhu, K., Yan, L., Lu, Y ., Lin, Y ., Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. In arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., and Wei, F. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y ., Wan, Y ., Liu, Y ....
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., and Press, O
Yang, J., Jimenez, C. E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., and Press, O. Swe-agent: Agent- computer interfaces enable automated software engineer- ing.Advances in Neural Information Processing Systems, 37:50528–50652, 2024b. Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for...
work page 2018
-
[18]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y ., Fried, D., et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
(21) =τ.(22) 13 Learning to Configure Agentic AI Systems C.3.1. DISCUSSION: WHYTHESEGUARANTEESMATTER Support Restrictionensures that the refined policy only proposes configurations that were successful during training. This prevents the policy from “inventing” novel, untested configurations at deployment time, which could lead to unpredictable behavior. R...
work page 2022
-
[20]
Embedder Mode ARI Cls. Acc Complexity Decision Overall Time (s) sentence-t5-base (768D) native 0.5603± 0.1019 0.8733± 0.0048 0.9261± 0.0099 0.7221± 0.0070 0.7704± 0.0305 38.39± 1.24 sentence-t5-base (768D) projected 0.4867± 0.1017 0.8635± 0.0084 0.9189± 0.0109 0.7138± 0.0018 0.7457± 0.0229 37.56± 0.89 MetaCLIP-H14 (1024D) native 0.4074± 0.0525 0.8514± 0.0...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.