Recognition: 2 theorem links
· Lean TheoremScaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning
Pith reviewed 2026-05-16 12:08 UTC · model grok-4.3
The pith
LLM agents iteratively evolve logic task families by authoring Generator-Validator pairs, producing training data with new rules that improves reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
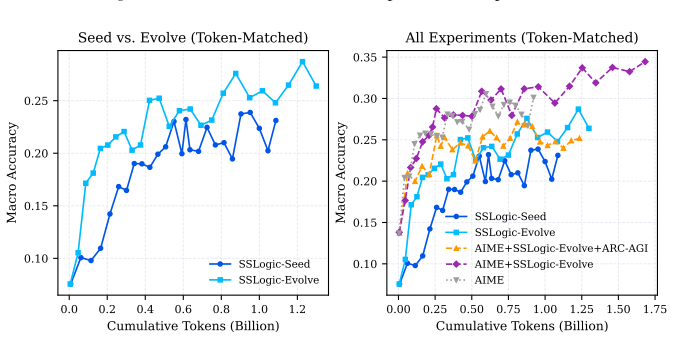
SSLogic is an agentic meta-synthesis framework in which LLM agents iteratively author and refine executable Generator-Validator pairs inside a closed Generate-Validate-Refine loop, producing families with new rules and difficulty gradients rather than parameter variations of old ones. A Multi-Gate Validation Protocol filters ill-posed tasks before they enter training. Starting from 400 seed families, two evolution rounds yield 953 families and 21,389 verifiable instances. Three converging comparisons consistently show higher training utility of the evolved data.
What carries the argument
The closed Generate-Validate-Refine loop in which agents author Generator-Validator pairs, together with the Multi-Gate Validation Protocol that combines multi-strategy consensus and Adversarial Blind Review.
Load-bearing premise
The Multi-Gate Validation Protocol reliably removes ill-posed tasks and the agent-authored pairs produce genuinely new rules and difficulty gradients rather than superficial variations of the seed families.
What would settle it
Retraining a model on the evolved dataset and finding no performance difference versus baseline synthesis on the same step-matched, token-matched, and size-controlled Enigmata evaluations would falsify the utility claim.
Figures





























read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) is bottlenecked by data: existing synthesis pipelines rely on expert-written code or fixed templates, confining growth to instance-level perturbations. We shift the evolvable unit from problem instances to task-family specifications. SSLogic is an agentic meta-synthesis framework in which LLM agents iteratively author and refine executable Generator-Validator pairs inside a closed Generate-Validate-Refine loop, producing families with new rules and difficulty gradients rather than parameter variations of old ones. A Multi-Gate Validation Protocol -- multi-strategy consensus plus Adversarial Blind Review, where independent agents solve each instance by writing and executing code -- filters ill-posed tasks before they enter training. Starting from 400 seed families, two evolution rounds yield 953 families and 21,389 verifiable instances. Three converging comparisons (step-matched, token-matched, and size-controlled on external Enigmata data) consistently show higher training utility of evolved data, with gains of SynLogic +5.2, AIME25 +3.0, and BBH +5.5 on Enigmata. Fine-grained KORBench evaluation reveals selective improvements in logic (+13.2%) and operation (+9.6%), linking structural evolution to downstream gains. Code: https://github.com/AdAstraAbyssoque/Scaling-the-Scaling-Logic
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SSLogic, an agentic meta-synthesis framework in which LLM agents iteratively author and refine executable Generator-Validator pairs in a closed Generate-Validate-Refine loop. Starting from 400 seed families, two evolution rounds produce 953 families and 21,389 verifiable instances. A Multi-Gate Validation Protocol (multi-strategy consensus plus adversarial blind review via code-writing agents) filters ill-posed tasks. Three matched comparisons (step-, token-, and size-controlled) on external Enigmata data report consistent gains from the evolved data: +5.2 on SynLogic, +3.0 on AIME25, and +5.5 on BBH, with selective KORBench improvements in logic (+13.2%) and operation (+9.6%) categories. Code is released at the provided GitHub link.
Significance. If the central claim holds, the work offers a concrete path to scale RLVR data beyond instance-level perturbations by evolving task-family specifications, which could improve training utility for reasoning models. The use of three converging matched controls and public code release are positive empirical strengths that facilitate verification.
major comments (3)
- [Abstract and Multi-Gate Validation Protocol description] The attribution of benchmark gains to 'new rules and difficulty gradients' (rather than superficial seed variations or formatting improvements) is load-bearing, yet the manuscript provides no quantitative diagnostics such as rule-novelty metrics, inter-family structural distances, or per-gate rejection fractions to confirm that the 953 families differ structurally from the 400 seeds.
- [Experiments and Results] Benchmark improvements are stated without error bars, statistical significance tests, or ablation results isolating the contribution of the Multi-Gate Protocol components versus simple data-volume increases, which weakens assessment of robustness under the step-, token-, and size-matched controls.
- [Methods (Multi-Gate Validation Protocol)] The Multi-Gate Validation Protocol is asserted to reliably remove ill-posed tasks via consensus and adversarial code-writing review, but no solve-rate statistics, inter-agent agreement scores, or exclusion criteria details are reported, leaving open whether residual gains could stem from reduced label noise rather than novel logic families.
minor comments (1)
- [Abstract] The abstract mentions 'fine-grained KORBench evaluation' but does not specify the exact subset or scoring protocol used for the +13.2% logic and +9.6% operation gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to strengthen the empirical support for our claims regarding the structural novelty of the evolved task families and the robustness of the reported gains.
read point-by-point responses
-
Referee: [Abstract and Multi-Gate Validation Protocol description] The attribution of benchmark gains to 'new rules and difficulty gradients' (rather than superficial seed variations or formatting improvements) is load-bearing, yet the manuscript provides no quantitative diagnostics such as rule-novelty metrics, inter-family structural distances, or per-gate rejection fractions to confirm that the 953 families differ structurally from the 400 seeds.
Authors: We agree that explicit quantitative diagnostics would better substantiate the claim that the 953 families introduce structurally new rules and difficulty gradients. In the revised manuscript we will add rule-novelty metrics computed via embedding cosine distances and normalized edit distances on the generator-validator code pairs, along with average inter-family structural distances and per-gate rejection fractions. These will be reported in a new subsection of the Methods and referenced in the Experiments section to directly address the distinction from seed variations. revision: yes
-
Referee: [Experiments and Results] Benchmark improvements are stated without error bars, statistical significance tests, or ablation results isolating the contribution of the Multi-Gate Protocol components versus simple data-volume increases, which weakens assessment of robustness under the step-, token-, and size-matched controls.
Authors: We acknowledge that the absence of error bars, significance testing, and targeted ablations limits the strength of the robustness claims. We will rerun all three matched comparisons (step-, token-, and size-controlled) across multiple random seeds to report standard deviations and conduct paired statistical tests (e.g., Wilcoxon signed-rank) for the reported gains. We will also add an ablation that compares the full evolved dataset against a volume-matched baseline using only seed families without the Generate-Validate-Refine loop. These results will be included in the revised Experiments section. revision: yes
-
Referee: [Methods (Multi-Gate Validation Protocol)] The Multi-Gate Validation Protocol is asserted to reliably remove ill-posed tasks via consensus and adversarial code-writing review, but no solve-rate statistics, inter-agent agreement scores, or exclusion criteria details are reported, leaving open whether residual gains could stem from reduced label noise rather than novel logic families.
Authors: We recognize that additional statistics on the validation protocol are needed to separate the effects of noise reduction from the introduction of novel families. In the revision we will report per-gate solve-rate statistics, inter-agent agreement scores (Cohen’s kappa on consensus decisions), and detailed exclusion criteria including the exact fraction of tasks rejected at each stage. These metrics will be presented in an expanded Multi-Gate Validation Protocol subsection of the Methods to allow readers to evaluate the protocol’s contribution. revision: yes
Circularity Check
No circularity: empirical gains derived from external benchmark comparisons, not self-referential fitting or definitions.
full rationale
The paper describes an agentic synthesis loop (Generate-Validate-Refine) that starts from 400 seed families and produces 953 evolved families, then reports performance deltas on held-out external benchmarks (Enigmata, SynLogic, AIME25, BBH) under step-, token-, and size-matched controls. No equations, fitted parameters, or uniqueness theorems are invoked that would make any reported gain equivalent to the input seeds by construction. The Multi-Gate Validation Protocol is presented as a procedural filter rather than a definitional step that presupposes the output distribution. All load-bearing claims rest on observable downstream accuracy improvements rather than on renaming, self-citation chains, or ansatz smuggling. This is a standard empirical pipeline whose central result is falsifiable against external test sets and therefore scores at the low end of the circularity range.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can iteratively author and refine executable Generator-Validator pairs that generate valid logic tasks with new rules.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SSLogic is an agentic meta-synthesis framework in which LLM agents iteratively author and refine executable Generator-Validator pairs inside a closed Generate-Validate-Refine loop
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Multi-Gate Validation Protocol—multi-strategy consensus plus Adversarial Blind Review
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[2]
URL https://aclanthology.org/2025. findings-acl.77/. He, F., Chen, Z., Liang, X., Ma, T., Qiu, Y ., Wu, S., and Yan, J. Protoreasoning: Prototypes as the foundation for generalizable reasoning in llms, 2025. URL https: //arxiv.org/abs/2506.15211. 10 Scaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning Helff, L., Omar, A., Friedrich, F., W ...
-
[3]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
URL https://openreview.net/forum? id=7Bywt2mQsCe. Hu, J., Wu, X., Zhu, Z., Xianyu, Wang, W., Zhang, D., and Cao, Y . Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 2024. Hu, K., Cy, A., Qiu, L., Ding, X. D., Wang, R., Zhu, Y . E., Andreas, J., and He, K. Arc is a vision problem!, 2025. URLhttps://ar...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.1285 2024
-
[4]
URL https://openreview.net/forum? id=v8L0pN6EOi. Liu, B., Jin, C., Kim, S., Yuan, W., Zhao, W., Kulikov, I., Li, X., Sukhbaatar, S., Lanchantin, J., and Weston, J. Spice: Self-play in corpus environments improves reasoning, 2025a. URL https://arxiv.org/abs/ 2510.24684. Liu, H., Liu, J., Cui, L., Teng, Z., Duan, N., Zhou, M., and Zhang, Y . Logiqa 2.0—an i...
-
[5]
In: NeurIPS ML Safety Workshop (2022)
URL https://openreview.net/forum? id=uyTL5Bvosj. Featured Certification. Stojanovski, Z., Stanley, O., Sharratt, J., Jones, R., Ade- fioye, A., Kaddour, J., and Koepf, A. Reasoning gym: Reasoning environments for reinforcement learn- ing with verifiable rewards. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Ben...
-
[6]
URL https://aclanthology.org/2021. findings-acl.317/. Veeraboina, H. Aime problem set (1983– 2024). https://www.kaggle.com/ datasets/hemishveeraboina/ aime-problem-set-1983-2024 , 2024. Kaggle dataset. Xia, Z., Luo, K., Qian, H., and Liu, Z. Open data synthesis for deep research, 2025. URL https://arxiv.org/ abs/2509.00375. Xie, T., Gao, Z., Ren, Q., Luo,...
-
[7]
Seed-agnostic:The Enigmata seeds share no overlap with our original 400 Chinese seed families, demonstrating the pipeline generalizes beyond its original seed distribution
-
[8]
Zero human annotation:The entire pipeline—from seed ingestion through evolution to training—requires no human intervention beyond selecting the 30 eligible types
-
[9]
English-only:Unlike our main experiment where seeds are in Chinese, Enigmata is entirely English, confirming cross-language applicability. N. Token-Matched Analysis Step-matched comparisons may not fully control for compute, as Evolve tasks elicit progressively longer reasoning chains. This appendix provides a token-budget analysis using per-step training...
work page 2025
-
[10]
Ensure it is directly evaluable using the eval function
Code Generation: Create a Python dictionary representing the updated state. Ensure it is directly evaluable using the eval function. Check the Progress State section above for the required content and format for this dictionary. Keep every string value on a single line—do not embed raw newline characters inside string literals. 3.Conciseness: Summarize to...
-
[11]
Nevertheless, notice that you should NOT switch plans too frequently
Plan Adjustment: If previous attempts are unproductive, document insights in the experience field and consider a plan shift. Nevertheless, notice that you should NOT switch plans too frequently. 5.Utilize Resources: Effectively employ sub-agents and tools to address sub-tasks. Output Format CRITICAL: You MUST output EXACTLY ONE response with ONE Thought a...
-
[12]
Output Management: Use Python’s built-inprint function to display results. Printed outputs are used in subsequent steps, so keep them concise and focused on the most relevant information
-
[13]
Avoid interactive functions like input()to maintain automation and reproducibility
Self-Contained Code: Ensure your code is fully executable without requiring user input. Avoid interactive functions like input()to maintain automation and reproducibility
-
[14]
Utilizing Resources: Leverage the provided sub-agents and tools, which are essentially Python functions you can call within your code. Notice that these functions arealready defined and importedand you should NOT re-define or re-import them. 4.Task Completion: Use thestopfunction to return a well-formatted output when the task is completed
-
[15]
You do NOT have sudo privileges, so avoid any commands or operations requiring elevated permissions
Python Environment: Explicitly import any libraries you need, including standard ones such as os or sys, as nothing (except for the pre-defined sub-agents and tools) is imported by default. You do NOT have sudo privileges, so avoid any commands or operations requiring elevated permissions. 6.Working Directory: Use the current folder as your working direct...
-
[16]
latest research paper on large language models
Complexity Control: Keep your code straightforward and avoid unnecessary complexity, especially when calling tools or sub-agents. Write code that is easy to follow and less prone to errors or exceptions. Output Format CRITICAL: You MUST output EXACTLY ONE response with ONE Thought and ONE Code block. DO NOT output multiple Thought-Code pairs. DO NOT conti...
-
[17]
It should include two fields: output and log
Code: Generate a Python dictionary representing the final output. It should include two fields: output and log. The output field should contain the well-formatted final output result, while the log field should summarize the navigation trajectory. 30 Scaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning
-
[18]
Final Result: Carefully examine the outputs from the previous steps as well as the alternative result (if existing) to decide the final output
-
[19]
Output Rules: Your final output should be a number OR as few words as possible OR a comma separated list of numbers and/or strings. Do NOT include any unnecessary information in the output. Output Format CRITICAL: You MUST output EXACTLY ONE response with ONE Thought and ONE Code block. DO NOT output multiple Thought-Code pairs. DO NOT continue thinking a...
-
[20]
Contextual Review: Carefully review the Progress State and Current Step to understand the context and require- ments for this selection
-
[21]
If multiple results are similar, prefer the one that aligns with the consensus
Majority Voting: By default, select the result that is most consistent with the majority of other results. If multiple results are similar, prefer the one that aligns with the consensus
-
[22]
Error Exclusion: Exclude any results that are clearly unreasonable, such as those containing errors, irrelevant information, or signs of failed execution
-
[23]
Tie-Breaking: If there is a tie among reasonable results, select the one that is best formatted and provides the most detailed and complete answer. 5.Fallback: If none of the results are clearly correct, select the one that appears most reasonable given the context
-
[24]
Given [Input Slot 1] and [Input Slot 2], find
Output Format: Output the index of the selected result using the print function. For example, to select the result at index 2, output in your code section:print(2). Figure 16.The system prompt used for result aggregation in the Cognitive Kernel Pro framework. O.2. Scale Scaling Logic (SSL) Pipeline Prompts The SSL pipeline for data generation consists of ...
work page 2000
-
[25]
Call seed save code() after defining generator/template/validator, then manually run input() and solution() in Python to check typical samples
-
[26]
Run seed generate sample() at least once and manually inspect the statement and validator votes to ensure answers are non-degenerate and validators agree
-
[27]
Call seed check question quality() and obtain action: "proceed" ; if revise, adjust per feedback and pass again
-
[28]
Trigger seed submit blind review() and record matching details for a passing attempt; if it fails, fix your code and retry
-
[29]
Before stop, re-check statement wording, difficulty labels, answer format, and validator outputs. Ensuresample summary 33 Scaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning and blind review summary in final JSON are truthful and reproducible.Important: the output parameter to stop must be a valid JSON string (usejson.dumps()) containing ...
-
[30]
Deconstruct the original problem → map its reasoning chain → design a new reasoning path/constraints → implement three components
-
[31]
Repeated verification: run generator and validator repeatedly in Python, print intermediate variables, and confirm correctness; if needed, sample across difficulties to check solvable/unsolvable ratios
-
[32]
Save code: define variables (e.g.,generator code = ’’’...’’’ ) and call seed save code(generator code, question template, validator code); then run seed generate sample() to inspect statements and an- swers
-
[33]
Callseed check question quality()to confirm readability/novelty/difficulty; iterate if needed
-
[34]
Useseed generate sample()to inspectvalidator votes; if inconsistent, fix the main validator and retry
-
[35]
Trigger blind review (auto-completes validator pool); if it fails, use failed samples detail to locate and fix issues before retrying
-
[36]
Recordgeneralizableproblem-design experience (not task-specific details)→organize deliverables→callstop. Seed Summary(mutation hintis for inspiration only; design a stronger reasoning goal) •question templatespreview: (runtime injected templates preview) • Reference sample question (original seed example, for understanding only; you may completely change ...
-
[37]
generator(生成器):Python函数input(difficulty),生成题目的输入数据和槽位文本 •返回格式:(inputs, slot texts) •inputs:传递给validator的输入数据 •slot texts:用于填充题面模板的文本列表
-
[38]
question template(题面模板):包含[输入槽位1]、[输入槽位2]等占位符的题目描述文本 •示例:"给定[输入槽位1]和[输入槽位2],求..." •槽位会被generator的slot texts依次填充
-
[39]
validator(验证器):Python函数solution(inputs),根据输入计算正确答案 •接收generator产生的inputs •返回题目的标准答案,需保持纯函数、无副作用,便于系统基于题面规范自动生成多个独立验证器进行一致性 检验 交付格式 •使用stop输出JSON: task id、generator code、question template、validator code、evolution strategy、 sample summary、blind review summary、experience updates、notes。 •重要:stop工具的参数必须是有效的 JSON 字符串,包含上述所有字段。系统会在最后一步( end 阶段)解析这 个JSON, 如果输出为No...
-
[40]
Function signature must bedef solution(inputs):
-
[41]
Solve using only data ininputs; do not call the generator, random functions, or I/O
- [42]
-
[43]
You may return a number, string, tuple, or dict, but it must match the statement
Output must be the unique standard answer. You may return a number, string, tuple, or dict, but it must match the statement
-
[44]
Helper functions are allowed, but must ultimately returnsolution(inputs)
-
[45]
Avoid side effects; keep pure functions so the system can generate multiple validators for voting
-
[46]
If it disagrees with the main validator, the system will expose validator votesfor comparison
Your implementation must be independently derived. If it disagrees with the main validator, the system will expose validator votesfor comparison
-
[47]
Avoid high resource usage (excessive computation or infinite loops). Ensure reasonable runtime. Generator (for input structure) ‘‘‘python ... ‘‘‘ Question Template (slots will be filled) (runtime injected template text) Current Main Validator (for IO contract only; do not copy line-by-line) ‘‘‘python ... ‘‘‘ 36 Scaling the Scaling Logic: Agentic Meta-Synt...
-
[48]
38 Scaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning
Understand the problem and perform clear reasoning. 38 Scaling the Scaling Logic: Agentic Meta-Synthesis of Logic Reasoning
-
[49]
3.The final answer must be strictly enclosed in\boxed{final answer}
You may call thepythontool to write and run code to assist reasoning; print intermediate results when needed. 3.The final answer must be strictly enclosed in\boxed{final answer}
-
[50]
If unsolvable or information is insufficient, use\boxed{N/A}. 5.Important: After finishing reasoning and giving the answer, you must call thestoptool to end the task
-
[51]
Avoid high resource usage (excessive computation or infinite loops); ensure reasonable runtime. Output Example Reasoning: ... therefore ... Final Answer:\boxed{42} Then callstopto finish. Figure 23.The prompt template used for blind review solution generation, where models solve problems independently without access to validators. Blind Review Prompt (Chi...
-
[52]
Align with Task Goals: Remove items that encourage simplifying problems, lowering difficulty, weakening constraints, or prioritizing easy solvability. Retain or rewrite items that strengthen multi-stage reasoning, complex constraint combinations, or counterintuitive setups
-
[53]
Quality Filtering: Deduplicate and merge semantic overlaps; rewrite overly specific items to make them transferable and focused on increasing reasoning difficulty
-
[54]
Coverage: Prioritize experience involving generator/validator co-verification, improving blind-review pass rates (while keeping high difficulty), and preventing shortcut solutions. 4.Quantity Control: Limit output to the specified maximum; each item must be one concise, actionable sentence. 5.Output Format: Return a strict JSON array of strings only, for ...
-
[55]
In thegenerator, explicitly construct test cases that are “almost valid” (satisfying n−1 constraints) to test the strictness of the validator
-
[56]
In thevalidator, implement a dual-check mechanism: one forward pass to construct the solution and one backward pass to verify the solution against all constraints
-
[57]
Distance constraints take precedence over color constraints
Ifblind reviewfails frequently on specific constraints, refine thequestion templateto explicitly state the priority of conflicting rules (e.g., “Distance constraints take precedence over color constraints”). Figure 30.Experience Entry (English) Experience Entry (Chinese) 策略:针对复杂约束强制实施多验证器一致性 描述:在设计具有复杂组合约束(例如带有附加路径权重限制的图着色)的问题时,主验证器往往难以覆盖所有边 缘情况。 可执行建议: 1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.