Recognition: no theorem link
MoDora: Tree-Based Semi-Structured Document Analysis System
Pith reviewed 2026-05-15 19:07 UTC · model grok-4.3
The pith
A tree structure turns fragmented OCR data into accurate answers for questions on semi-structured documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MoDora converts OCR-parsed fragments into layout-aware components via local-alignment aggregation and type-specific extraction for titles or non-text items. It organizes these components into the Component-Correlation Tree to capture hierarchical relations and layout distinctions through bottom-up cascade summarization. A question-type-aware retrieval step then applies grid partitioning for location queries and LLM-guided pruning for semantic ones, producing answers that respect both structure and content.
What carries the argument
The Component-Correlation Tree (CCTree), which arranges layout-aware components into a hierarchy and records their relations and layout distinctions via bottom-up cascade summarization.
If this is right
- Questions that require linking a paragraph on one page to table cells elsewhere become answerable because the tree preserves both location and semantic ties.
- Nested structures such as chapter titles containing sub-tables or sidebars remain distinguishable during retrieval.
- Layout-specific distinctions like main content versus side panels improve the precision of location-based retrieval steps.
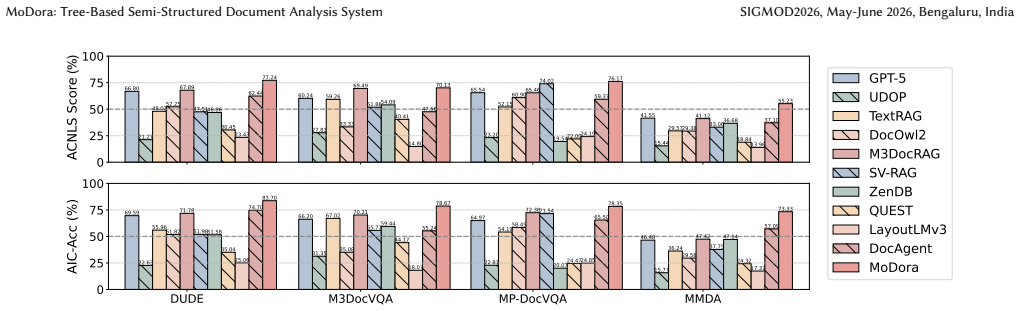
- End-to-end accuracy on natural-language question answering over semi-structured documents rises by 5.97 to 61.07 percent relative to existing baselines.
Where Pith is reading between the lines
- The same tree construction could support incremental updates when new pages are added to a live document collection.
- Scaling the cascade summarization to documents hundreds of pages long would test whether coherence is maintained at greater depth.
- Analogous tree organizations might improve LLM performance on other scattered structured sources such as web pages or code repositories.
Load-bearing premise
Local alignment can reassemble fragmented OCR pieces into components that keep their original semantic context and hierarchical links without major loss.
What would settle it
Run the system on a collection of documents whose OCR output is heavily fragmented and whose test questions require exact reconstruction of nested titles or cross-region table references; if accuracy falls to or below baseline levels, the central claim does not hold.
Figures









read the original abstract
Semi-structured documents integrate diverse interleaved data elements (e.g., tables, charts, hierarchical paragraphs) arranged in various and often irregular layouts. These documents are widely observed across domains and account for a large portion of real-world data. However, existing methods struggle to support natural language question answering over these documents due to three main technical challenges: (1) The elements extracted by techniques like OCR are often fragmented and stripped of their original semantic context, making them inadequate for analysis. (2) Existing approaches lack effective representations to capture hierarchical structures within documents (e.g., associating tables with nested chapter titles) and to preserve layout-specific distinctions (e.g., differentiating sidebars from main content). (3) Answering questions often requires retrieving and aligning relevant information scattered across multiple regions or pages, such as linking a descriptive paragraph to table cells located elsewhere in the document. To address these issues, we propose MoDora, an LLM-powered system for semi-structured document analysis. First, we adopt a local-alignment aggregation strategy to convert OCR-parsed elements into layout-aware components, and conduct type-specific information extraction for components with hierarchical titles or non-text elements. Second, we design the Component-Correlation Tree (CCTree) to hierarchically organize components, explicitly modeling inter-component relations and layout distinctions through a bottom-up cascade summarization process. Finally, we propose a question-type-aware retrieval strategy that supports (1) layout-based grid partitioning for location-based retrieval and (2) LLM-guided pruning for semantic-based retrieval. Experiments show MoDora outperforms baselines by 5.97%-61.07% in accuracy. The code is at https://github.com/weAIDB/MoDora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoDora, an LLM-powered system for natural language question answering over semi-structured documents. It addresses three challenges—fragmented OCR elements lacking semantic context, inadequate hierarchical and layout representations, and scattered multi-region information—via a local-alignment aggregation strategy to produce layout-aware components (with type-specific extraction), the Component-Correlation Tree (CCTree) for bottom-up hierarchical organization and relation modeling, and a question-type-aware retrieval method combining layout-based grid partitioning with LLM-guided semantic pruning. Experiments report accuracy gains of 5.97%–61.07% over baselines, with code released at https://github.com/weAIDB/MoDora.
Significance. If the performance claims are substantiated with rigorous controls, MoDora could advance practical QA systems for real-world semi-structured documents (reports, forms, scientific papers) by explicitly handling layout distinctions and hierarchies that current OCR+LLM pipelines often lose. The open-source release is a clear strength for reproducibility.
major comments (2)
- [Abstract and §4 (System Overview / Local-Alignment Aggregation)] The headline accuracy improvements (5.97%–61.07%) are attributed to the full pipeline, yet the manuscript provides no ablation isolating the local-alignment aggregation step. Without a controlled comparison (raw OCR element lists vs. aggregated components before CCTree construction), it remains unclear whether this step preserves semantic context and hierarchical relations or merely adds overhead; the central claim that it successfully converts fragmented elements into layout-aware components therefore rests on an untested premise.
- [Experimental Evaluation] The experimental section lacks sufficient detail on baseline definitions, dataset statistics (size, domain, OCR quality), exact metrics, and error analysis. This prevents verification of whether reported gains derive from the CCTree cascade and retrieval heuristics or from differences in prompting volume, model choice, or post-hoc tuning.
minor comments (2)
- [Abstract] The accuracy range 5.97%–61.07% is stated without mapping specific values to particular baselines or datasets; a table or explicit per-baseline breakdown would improve clarity.
- [§3 (CCTree Construction)] Notation for component types and CCTree node attributes is introduced without a consolidated table; readers must infer definitions from scattered prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate additional experiments and details as outlined.
read point-by-point responses
-
Referee: [Abstract and §4 (System Overview / Local-Alignment Aggregation)] The headline accuracy improvements (5.97%–61.07%) are attributed to the full pipeline, yet the manuscript provides no ablation isolating the local-alignment aggregation step. Without a controlled comparison (raw OCR element lists vs. aggregated components before CCTree construction), it remains unclear whether this step preserves semantic context and hierarchical relations or merely adds overhead; the central claim that it successfully converts fragmented elements into layout-aware components therefore rests on an untested premise.
Authors: We agree that an isolated ablation of the local-alignment aggregation step would strengthen the claims. In the revised manuscript, we will add a controlled comparison between raw OCR element lists and the aggregated layout-aware components (prior to CCTree construction). This will report effects on component quality, downstream CCTree structure, and final QA accuracy, clarifying the contribution of this step beyond overhead. revision: yes
-
Referee: [Experimental Evaluation] The experimental section lacks sufficient detail on baseline definitions, dataset statistics (size, domain, OCR quality), exact metrics, and error analysis. This prevents verification of whether reported gains derive from the CCTree cascade and retrieval heuristics or from differences in prompting volume, model choice, or post-hoc tuning.
Authors: We acknowledge the need for greater experimental transparency. In the revision, we will expand §5 to include: precise definitions and prompting details for all baselines; full dataset statistics (document counts, domains, average OCR error rates where measurable); exact metric formulations; and a dedicated error analysis categorizing failure modes. These additions will allow readers to attribute gains more clearly to the proposed components. revision: yes
Circularity Check
No circularity: MoDora is an engineered pipeline with no self-referential derivations
full rationale
The paper presents MoDora as a descriptive system architecture consisting of local-alignment aggregation for OCR elements, CCTree construction via bottom-up cascade summarization, and question-type-aware retrieval with grid partitioning and LLM pruning. No equations, fitted parameters, or first-principles derivations appear in the provided text; performance claims rest on experimental comparisons rather than any quantity that reduces to its own inputs by construction. No self-citations are used to justify uniqueness or to smuggle ansatzes, and the central components are externally motivated engineering decisions rather than tautological redefinitions. The derivation chain is therefore a standard pipeline specification and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can perform effective type-specific information extraction and LLM-guided pruning on document components
invented entities (1)
-
Component-Correlation Tree (CCTree)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Semantic Data Processing with Holistic Data Understanding
HoldUp uses LLM-guided clustering to provide holistic dataset context for semantic operators, yielding up to 33% higher classification accuracy and 30% higher scoring accuracy than row-by-row LLM processing across 15 ...
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
https://github.com/lisun-ai/DocAgent
2025.DocAgent. https://github.com/lisun-ai/DocAgent
work page 2025
-
[4]
https://github.com/bloomberg/m3docrag
2025.m3docrag. https://github.com/bloomberg/m3docrag
work page 2025
-
[5]
https://pypi.org/project/PyMuPDF/
2025.PyMuPDF 1.26.7. https://pypi.org/project/PyMuPDF/
work page 2025
-
[6]
https://github.com/Ruiying-Ma/SHTRAG
2025.SHTRAG. https://github.com/Ruiying-Ma/SHTRAG
work page 2025
-
[7]
https://pypi.org/project/pdfplumber/
2026.pdfplumber 0.11.9. https://pypi.org/project/pdfplumber/
work page 2026
-
[8]
Srikar Appalaraju, Bhavan Jasani, Bhargava Urala Kota, Yusheng Xie, and R Manmatha. 2021. Docformer: End-to-end transformer for document understand- ing. InProceedings of the IEEE/CVF international conference on computer vision. 993–1003
work page 2021
-
[9]
Simran Arora, Brandon Yang, Sabri Eyuboglu, Avanika Narayan, Andrew Ho- jel, Immanuel Trummer, and Christopher Ré. 2023. Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. Proceedings of the VLDB Endowment17, 2 (2023), 92–105
work page 2023
-
[10]
Yushi Bai, Shangqing Tu, Jiajie Zhang, and et alsdf. 2025. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. In ACL (1). Association for Computational Linguistics, 3639–3664
work page 2025
-
[11]
Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas. 2019. Scene text visual question answering. InProceedings of the IEEE/CVF international conference on computer vision. 4291–4301
work page 2019
- [12]
- [13]
-
[14]
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. PaddleOCR 3.0 Technical Report. arXiv:2507.05595 [cs.CV] https://arxiv.org/abs/2507.05595
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2025. ColPali: Efficient Document Retrieval with Vision Language Models. arXiv:2407.01449 [cs.IR] https://arxiv.org/abs/2407. 01449
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [16]
- [17]
-
[18]
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. 2022. Layoutlmv3: Pre-training for document ai with unified text and image masking. InProceedings of the 30th ACM international conference on multimedia. 4083–4091
work page 2022
-
[19]
Yiming Lin, Mawil Hasan, Rohan Kosalge, Alvin Cheung, and Aditya G. Parameswaran. 2025. TWIX: Automatically Reconstructing Structured Data from Templatized Documents.CoRRabs/2501.06659 (2025)
- [20]
-
[21]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
work page 2025
-
[22]
OpenAI. 2025.Introducing GPT-5. Technical Report. https://openai.com/index/ introducing-gpt-5/
work page 2025
-
[23]
Panupong Pasupat and Percy Liang. 2015. Compositional Semantic Parsing on Semi-Structured Tables. InACL (1). The Association for Computer Linguistics, 1470–1480
work page 2015
-
[24]
Jon Saad-Falcon, Joe Barrow, Alexa Siu, Ani Nenkova, Seunghyun Yoon, Ryan A Rossi, and Franck Dernoncourt. 2024. Pdftriage: Question answering over long, structured documents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 153–169
work page 2024
-
[25]
Li Sun, Liu He, Shuyue Jia, Yangfan He, and Chenyu You. 2025. Docagent: An agentic framework for multi-modal long-context document understanding. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 17712–17727
work page 2025
-
[26]
Zhaoze Sun, Chengliang Chai, Qiyan Deng, Kaisen Jin, Xinyu Guo, Han Han, Ye Yuan, Guoren Wang, and Lei Cao. 2025. QUEST: Query Optimization in Unstructured Document Analysis.Proceedings of the VLDB Endowment18, 11 (2025), 4560–4573
work page 2025
-
[27]
Zirui Tang, Boyu Niu, Xuanhe Zhou, Boxiu Li, Wei Zhou, Jiannan Wang, Guoliang Li, Xinyi Zhang, and Fan Wu. 2026. ST-Raptor: LLM-Powered Semi-Structured Table Question Answering.Proc. ACM Manag. Data(2026)
work page 2026
-
[28]
Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, and Mohit Bansal. 2023. Unifying vision, text, and lay- out for universal document processing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19254–19264
work page 2023
-
[29]
Qwen Team. 2025. Qwen2.5-VL. https://qwenlm.github.io/blog/qwen2.5-vl/
work page 2025
-
[30]
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. 2023. Hierarchical multi- modal transformers for multipage docvqa.Pattern Recognition144 (2023), 109834
work page 2023
-
[31]
Jordy Van Landeghem, Rubèn Tito, Łukasz Borchmann, Michał Pietruszka, Pawel Joziak, Rafal Powalski, Dawid Jurkiewicz, Mickaël Coustaty, Bertrand Anckaert, Ernest Valveny, et al. 2023. Document understanding dataset and evaluation (dude). InProceedings of the IEEE/CVF International Conference on Computer Vision. 19528–19540
work page 2023
- [32]
-
[33]
Chening Yang, Duy-Khanh Vu, Minh-Tien Nguyen, Xuan-Quang Nguyen, Linh Nguyen, and Hung Le. 2025. Superrag: Beyond rag with layout-aware graph mod- eling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track). 544–557
work page 2025
-
[34]
Haopeng Zhang, Philip S Yu, and Jiawei Zhang. 2025. A systematic survey of text summarization: From statistical methods to large language models.Comput. Surveys57, 11 (2025), 1–41
work page 2025
-
[35]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[36]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025). 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.