Path Dependence under Adaptive AI Delegation
Pith reviewed 2026-05-15 17:07 UTC · model grok-4.3
The pith
Adaptive delegation to AI produces path-dependent skill dynamics with two attracting equilibria separated by a separatrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
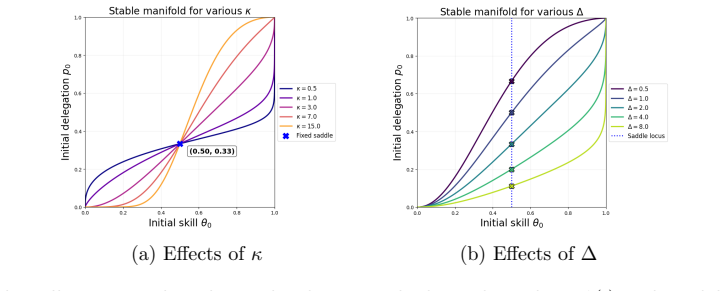
With adaptive delegation the coupled system possesses two attracting equilibria separated by the stable manifold of an interior saddle; the resulting path dependence means that performance-driven adjustments in reliance can trap the user in a low-skill steady state even when AI assistance improves immediate results relative to independent work.
What carries the argument
The two-dimensional dynamical system whose state variables are latent human skill (governing expected independent performance) and delegation level (the evolving tendency to rely on AI), with skill evolving by error-driven improvement under practice and decay under delegation, and delegation evolving by a performance-based rule that increases reliance when AI-assisted output exceeds independent output.
If this is right
- Small initial differences in skill or reliance can produce permanently different long-run skill levels.
- AI assistance can improve short-run performance while producing worse long-run performance than a no-AI baseline.
- Higher AI capability enlarges the basin of attraction of the low-skill equilibrium.
- The source of long-run risk is the coupling between performance-driven reliance and use-dependent skill change rather than AI assistance in isolation.
Where Pith is reading between the lines
- Deployment protocols could deliberately restrict early delegation to keep trajectories on the high-skill side of the separatrix.
- Empirical studies might measure the width of the separatrix by varying initial conditions in controlled repeated-task experiments.
- The same bistable structure may appear in other feedback systems where capability and usage co-evolve, such as tool-assisted learning or automated decision support.
Load-bearing premise
The specific functional forms chosen for error-driven skill improvement, skill decay under delegation, and the performance-comparison rule that updates delegation level are what produce the two-equilibrium structure and the separating manifold.
What would settle it
Longitudinal tracking of individual users performing repeated tasks under adaptive AI, recording both measured skill on independent trials and observed delegation rates, to test whether trajectories cluster into two distinct long-run attractors rather than converging to a single outcome regardless of small initial differences.
Figures





read the original abstract
Repeated AI assistance can improve immediate task performance while reducing the skill available for future independent work. We develop a mathematical framework for this long-run tradeoff. The model tracks two state variables: a latent human skill level governing expected independent performance, and a delegation level representing the learner's evolving tendency to rely on AI. Skill changes through error-driven learning under practice and decay under delegation; delegation responds to observed performance, increasing when AI-assisted work appears to outperform independent work. We analyze the resulting dynamics and contrast them with fixed delegation. With fixed delegation, skill follows a one-dimensional learning-decay process with a single stable equilibrium. With adaptive delegation, the coupled system has two attracting equilibria separated by the stable manifold of an interior saddle. The existence and geometry of this separatrix require a global phase-plane analysis of the coupled dynamics. The system is path-dependent: small differences in initial skill or reliance can lead to different long-run outcomes. We use this characterization to show that AI assistance can improve short-run performance while producing worse long-run performance than a no-AI baseline. Increasing AI capability can enlarge the basin of attraction of the low-skill equilibrium, making delegation appear beneficial for longer while increasing the risk of eventual skill loss. The qualitative picture is observed to persist across alternative specifications. Together, these results show that the risk is not AI assistance itself, but the coupling between performance-driven reliance and use-dependent skill change.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a two-dimensional dynamical system tracking latent human skill s and delegation level d. Skill evolves via error-driven improvement under independent practice and decay under delegation; delegation updates based on observed performance comparison between AI-assisted and independent work. With fixed delegation the system reduces to a one-dimensional process with a unique stable equilibrium. With adaptive delegation the coupled flow possesses two attracting equilibria separated by the stable manifold of an interior saddle, producing path dependence: trajectories starting near the separatrix converge to either a high-skill/low-delegation or low-skill/high-delegation attractor. The analysis shows that short-run performance gains from AI can place the system in the basin of the inferior long-run equilibrium, and that higher AI capability enlarges that basin. The qualitative structure is reported to survive changes in the functional forms of the update rules.
Significance. If the phase-plane results hold, the paper supplies a clean, falsifiable mechanism for the long-run skill-atrophy risk of performance-driven AI delegation. The global analysis, explicit contrast with fixed delegation, and robustness statements across functional forms constitute a genuine contribution to the formal modeling of human-AI interaction. The framework is simple enough to be extended empirically yet rich enough to generate testable predictions about basin boundaries and the effect of AI capability.
major comments (2)
- [§3.2] §3.2, Eq. (11)–(12): the claim that the interior equilibrium is a saddle whose stable manifold forms the separatrix is supported only by a qualitative sign argument on the Jacobian; an explicit computation of the eigenvalues (or at least their signs) at the equilibrium point would make the saddle classification and the geometry of the basins rigorous rather than heuristic.
- [§4.3] §4.3: the statement that the two-equilibrium structure 'persists across alternative specifications' is illustrated with only two variants of the skill-update rule; because the existence of the interior saddle and the separatrix are sensitive to the relative curvatures of the learning and decay functions, the robustness section should either enumerate the precise class of functions for which the result holds or provide a general proof that does not rely on the specific forms chosen in the main text.
minor comments (3)
- [§2.1] §2.1: the performance function P(s,d) used to drive the delegation update is described verbally but never written explicitly; inserting the functional form immediately after its introduction would remove ambiguity about how the comparison between assisted and unassisted performance is operationalized.
- [Figure 2] Figure 2: the phase portrait would be clearer if the stable manifold of the saddle were drawn as a distinct curve (rather than inferred from the flow arrows) and if the no-AI baseline trajectory were overlaid for direct visual comparison.
- [§5] §5: the discussion of policy implications is brief; a short paragraph indicating how the separatrix location could be estimated from observable data (initial skill and delegation levels) would strengthen the bridge to empirical work.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful review and the recommendation for minor revision. The comments help strengthen the rigor of our analysis, and we address them point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (11)–(12): the claim that the interior equilibrium is a saddle whose stable manifold forms the separatrix is supported only by a qualitative sign argument on the Jacobian; an explicit computation of the eigenvalues (or at least their signs) at the equilibrium point would make the saddle classification and the geometry of the basins rigorous rather than heuristic.
Authors: We concur that the qualitative sign argument on the Jacobian can be made more rigorous with explicit eigenvalue computation. We will add this calculation in the revised manuscript, explicitly solving for the eigenvalues at the interior equilibrium point given by Eqs. (11)–(12) and verifying that they are real and of opposite signs, thereby confirming the saddle nature and the role of its stable manifold as the separatrix. revision: yes
-
Referee: [§4.3] §4.3: the statement that the two-equilibrium structure 'persists across alternative specifications' is illustrated with only two variants of the skill-update rule; because the existence of the interior saddle and the separatrix are sensitive to the relative curvatures of the learning and decay functions, the robustness section should either enumerate the precise class of functions for which the result holds or provide a general proof that does not rely on the specific forms chosen in the main text.
Authors: We acknowledge that the current robustness checks are limited to two variants. To address the concern about sensitivity to curvatures, we will revise §4.3 to provide a general argument under the assumption that the skill update functions satisfy certain monotonicity and concavity conditions (specifically, positive but decreasing marginal learning and non-increasing marginal decay). This will delineate the precise class of functions for which the two-attractor structure holds, without relying on the specific forms in the main text. We will also include an additional functional form in the illustrations. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines a two-dimensional dynamical system from explicit first-principles functional forms for error-driven skill improvement, skill decay under delegation, and performance-based delegation adjustment. The two attracting equilibria, interior saddle, and separating stable manifold are derived via global phase-plane analysis of the resulting ODEs; they are not presupposed, fitted to data, or imported via self-citation. The path-dependence and short-run vs. long-run tradeoff statements follow directly from the geometry of the vector field and are shown to be robust under alternative specifications of the update rules. No load-bearing step reduces to a definition, a fitted parameter renamed as prediction, or an unverified self-citation chain. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Skill changes through error-driven learning under practice and decay under delegation
- domain assumption Delegation level increases when AI-assisted performance appears to outperform independent performance
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
˙θ=θ(1−θ)((1−p)(1−θ)−Δpθ), ˙p=κp(1−p)((1−θ)²−(1−θa)²) with equilibria at (1,0), (0,1), interior saddle (θa,1−θa/(1−(1−Δ)θa))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stable manifold ψ(θ) partitions basins; short-run gain, long-run loss via negative feedback
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Building pro-worker artificial intelligence
Daron Acemoglu, David Autor, and Simon Johnson. Building pro-worker artificial intelligence. Working Paper 34854, National Bureau of Economic Research, February 2026
work page 2026
-
[2]
ChatGPT: The cognitive effects on learning and memory
Long Bai, Xiangfei Liu, and Jiacan Su. ChatGPT: The cognitive effects on learning and memory. Brain-X, 2023
work page 2023
-
[3]
Generative AI without guardrails can harm learning: Evidence from high school mathematics
Hamsa Bastani, Osbert Bastani, Alp Sungu, Haosen Ge, ¨Ozge Kabakcı, and Rei Mariman. Generative AI without guardrails can harm learning: Evidence from high school mathematics. Proceedings of the National Academy of Sciences of the United States of America, 122, 2025
work page 2025
-
[4]
Dynamics of stochastic approximation algorithms
Michel Bena¨ ım. Dynamics of stochastic approximation algorithms. In Jacques Az´ ema, Michel ´Emery, Michel Ledoux, and Marc Yor, editors,S´ eminaire de Probabilit´ es XXXIII, pages 1–68, Berlin, Heidelberg, 1999. Springer Berlin Heidelberg
work page 1999
-
[5]
Elisa Celis, Amit Kumar, Anay Mehrotra, and Nisheeth K
L. Elisa Celis, Amit Kumar, Anay Mehrotra, and Nisheeth K. Vishnoi. Bias in evaluation processes: An optimization-based model. InNeurIPS, 2023
work page 2023
-
[6]
Mollick, Hila Lifshitz-Assaf, Katherine C
Fabrizio Dell’Acqua, Edward McFowland, Ethan R. Mollick, Hila Lifshitz-Assaf, Katherine C. Kellogg, Saran Rajendran, Lisa Krayer, Fran¸ cois Candelon, and Karim R. Lakhani. Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality.SSRN Electronic Journal, 2023
work page 2023
-
[7]
Teachers College, Columbia University, 1913
Hermann Ebbinghaus.Memory: A Contribution to Experimental Psychology. Teachers College, Columbia University, 1913. Transl. of 1885 German edition
work page 1913
-
[8]
Asma Ejaz, Muhammad Farhan, Francesco Ernesto, and Alessi Longa. AI and cognitive load: How reliance on AI tools (Chatgpt, etc.) affects critical thinking.Research Journal of Psychology, 2025
work page 2025
-
[9]
Ido Erev and Alvin E. Roth. Predicting how people play games: Reinforcement learning in experimental games with unique, mixed strategy equilibria.The American Economic Review, 88(4):848–881, 1998
work page 1998
-
[10]
K. Anders Ericsson, Ralf Thomas Krampe, Clemens Tesch-Romer, Catherine Ashworth, Gregory Carey, Robert J. Crutcher, Janet Grassia, Reid Hastie, Stefanie Heizmann, Charles Judd, Ronald Kellogg, Robert Levin, Clayton H. Lewis, William Oliver, Peter G. Poison, Robert Rehder, Kurt Schlesinger, Vivian I. Schneider, and James Wilson. The role of deliberate prac...
work page 1993
-
[11]
Griffiths, Charles Kemp, and Joshua B
Thomas L. Griffiths, Charles Kemp, and Joshua B. Tenenbaum. Bayesian models of cognition, 2008. 38
work page 2008
-
[12]
Andrew Heathcote, Scott Brown, and D. J. K. Mewhort. The power law repealed: The case for an exponential law of practice.Psychonomic Bulletin & Review, 7(2):185–207, Jun 2000
work page 2000
-
[13]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vi- vian Beresnitzky, Iris Braunstein, and Pattie Maes. Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task. 2025
work page 2025
-
[14]
Semi-supervised learning with gans: Manifold invariance with improved inference
Abhishek Kumar, Prasanna Sattigeri, and Tom Fletcher. Semi-supervised learning with gans: Manifold invariance with improved inference. InNeural Information Processing Systems, 2017
work page 2017
-
[15]
Hao-Ping (Hank) Lee, Advait Sarkar, Lev Tankelevitch, Ian Drosos, Sean Rintel, Richard Banks, and Nicholas Wilson. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In CHI 2025, April 2025
work page 2025
-
[16]
Matthias Lehmann, Philipp B. Cornelius, and Fabian J. Sting. AI meets the classroom: When do large language models harm learning?, 2024
work page 2024
-
[17]
Smitha Milli, John Miller, Anca D. Dragan, and Moritz Hardt. The social cost of strategic classification. InProceedings of the Conference on Fairness, Accountability, and Transparency, FAT* ’19, page 230–239, New York, NY, USA, 2019. Association for Computing Machinery
work page 2019
-
[18]
Dylan R. Nelson and Joey Cheung. Non-linear dynamics and chaos. 2007
work page 2007
-
[19]
Allen Newell and Paul S. Rosenbloom. Mechanisms of skill acquisition and the law of practice. In John R. Anderson, editor,Cognitive Skills and Their Acquisition, pages 1–55. Lawrence Erlbaum, Hillsdale, NJ, 1981
work page 1981
-
[20]
Norman.Things That Make Us Smart: Defending Human Attributes in the Age of the Machine
Donald A. Norman.Things That Make Us Smart: Defending Human Attributes in the Age of the Machine. Addison-Wesley, 1994
work page 1994
-
[21]
R. Parasuraman, T.B. Sheridan, and C.D. Wickens. A model for types and levels of human interaction with automation.IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, 30(3):286–297, 2000
work page 2000
-
[22]
A survey of random processes with reinforcement.Probability Surveys [electronic only], 4:1–79, 2007
Robin Pemantle. A survey of random processes with reinforcement.Probability Surveys [electronic only], 4:1–79, 2007
work page 2007
-
[23]
Juan Perdomo, Tijana Zrnic, Celestine Mendler-D¨ unner, and Moritz Hardt. Performative prediction. In Hal Daum´ e III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 7599–7609. PMLR, 13–18 Jul 2020
work page 2020
-
[24]
Lawrence Perko.Differential equations and dynamical systems. New York: Springer, 2001
work page 2001
-
[25]
R. A. Rescorla and A. R. Wagner. A theory of pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In A. H. Black and W. F. Prokasy, editors, Classical Conditioning II: Current Research and Theory, pages 64–99. Appleton-Century-Crofts, New York, 1972. 39
work page 1972
-
[26]
The manifold tangent classifier
Salah Rifai, Yann Dauphin, Pascal Vincent, Yoshua Bengio, and Xavier Muller. The manifold tangent classifier. InNeural Information Processing Systems, 2011
work page 2011
-
[27]
Evan F. Risko and Sam J. Gilbert. Cognitive offloading.Trends in Cognitive Sciences, 20(9):676–688, 2016
work page 2016
-
[28]
Hang Shao, Abhishek Kumar, and P. Thomas Fletcher. The riemannian geometry of deep generative models.2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 428–4288, 2018
work page 2018
-
[29]
No evidence for LLMs being useful in problem reframing
Joongi Shin, Anna Polyanskaya, Andr´ es Lucero, and Antti Oulasvirta. No evidence for LLMs being useful in problem reframing. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, page 1–25. ACM, April 2025
work page 2025
-
[30]
Stack Overflow developer survey 2025
Stack Overflow. Stack Overflow developer survey 2025. Online report, 2025
work page 2025
-
[31]
arXiv preprint arXiv:2306.07899 , year=
Veniamin Veselovsky, Manoel Horta Ribeiro, and Robert West. Artificial artificial artificial intelligence: Crowd workers widely use large language models for text production tasks.ArXiv, abs/2306.07899, 2023
-
[32]
Chunpeng Zhai, Santoso Wibowo, and Lily D. Li. The effects of over-reliance on AI dialogue systems on students’ cognitive abilities: a systematic review.Smart Learning Environments, 11, 2024
work page 2024
-
[33]
Ruixun Zhang, Thomas J Brennan, and Andrew W Lo. The origin of risk aversion.Proceedings of the National Academy of Sciences, 111(50):17777–17782, 2014. 40
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.