Recognition: no theorem link
Do Machines Fail Like Humans? A Human-Centred Out-of-Distribution Spectrum for Mapping Error Alignment
Pith reviewed 2026-05-15 15:10 UTC · model grok-4.3
The pith
A spectrum of human perceptual difficulty shows vision-language models align with humans most consistently across out-of-distribution conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
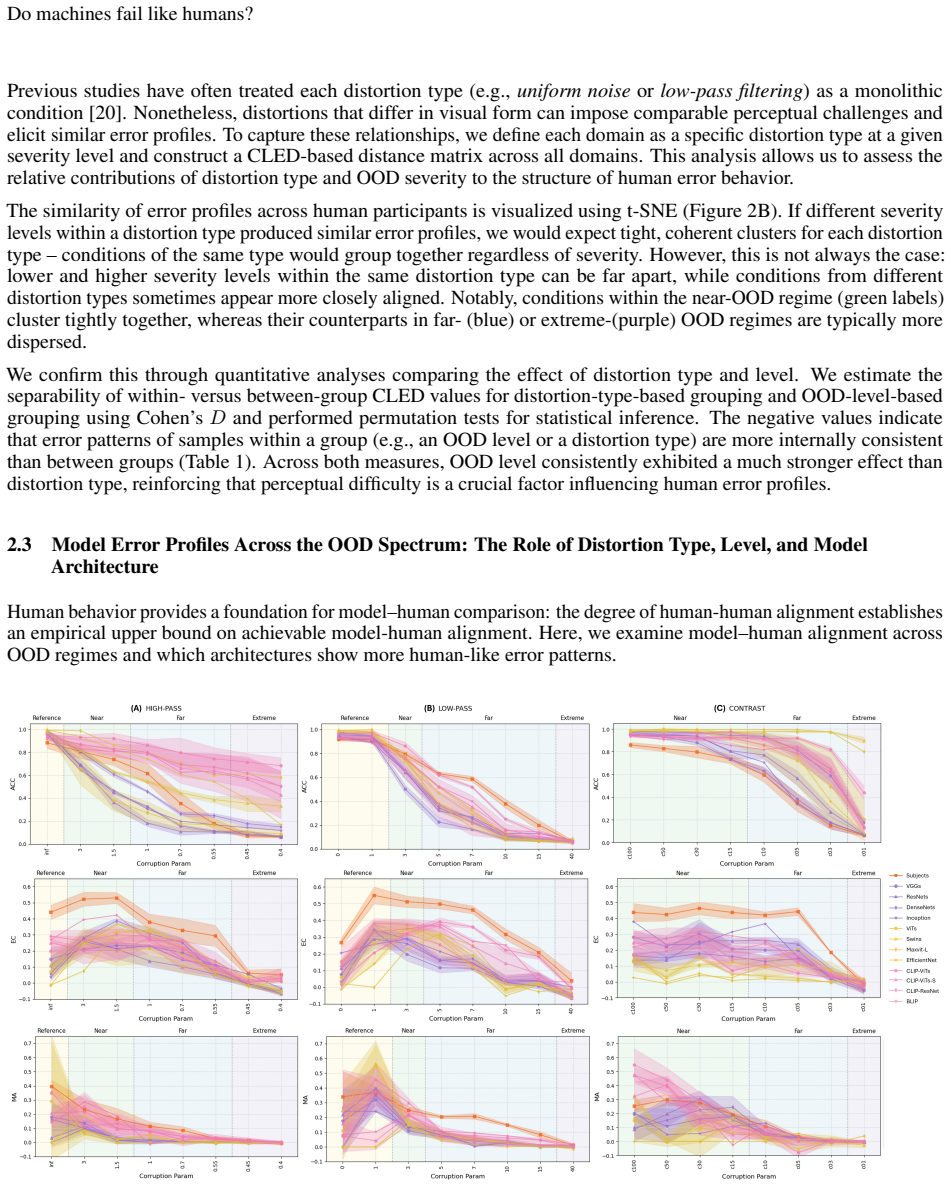
By quantifying how far a set of stimuli deviates from an undistorted reference according to human accuracy, the method defines an OOD spectrum and identifies four regimes of perceptual challenge; this enables direct model-human error alignment comparisons at matched difficulty levels, exposing architecture-specific patterns where vision-language models are most consistently aligned, CNNs outperform ViTs on near-OOD, and ViTs outperform CNNs on far-OOD.
What carries the argument
The human-centred OOD spectrum, constructed by measuring stimulus deviation from an undistorted reference set via drops in human recognition accuracy, which partitions stimuli into four calibrated regimes of perceptual difficulty.
If this is right
- Model-human comparisons become possible at explicitly matched difficulty levels instead of arbitrary OOD definitions.
- Different deep-learning architectures exhibit distinct alignment profiles that depend on the perceptual regime.
- Vision-language models maintain the steadiest error alignment from near-OOD through far-OOD conditions.
- Assessments of alignment must account for cross-condition differences in perceptual difficulty to be reliable.
Where Pith is reading between the lines
- The same spectrum could be applied to other sensory domains such as audio or text to test whether architecture-specific alignment patterns generalize.
- Training objectives that target alignment specifically within each regime might produce models that stay closer to human error patterns overall.
- Hybrid architectures that combine early-layer features from CNNs with later-layer features from ViTs could reduce the observed crossover in alignment.
- The framework supplies a concrete way to select test stimuli that probe alignment at the exact difficulty levels where current models diverge most from humans.
Load-bearing premise
Human accuracy on distorted stimuli supplies a valid, general, and model-independent yardstick for perceptual difficulty.
What would settle it
A replication in which the same images ordered by the human-accuracy spectrum produce different regime boundaries or reverse the reported CNN-ViT alignment crossover would falsify the central claim.
Figures










read the original abstract
Determining whether AI systems process information similarly to humans is central to cognitive science and trustworthy AI. While modern AI models can match human accuracy on standard tasks, such parity does not guarantee that their underlying decision-making strategies resemble those of humans. Assessing performance using error alignment metrics to compare how humans and models fail, and how this changes for distorted, or otherwise more challenging, stimuli, provides a viable pathway toward a finer characterization of model-human alignment. However, existing out-of-distribution (OOD) analyses for challenging stimuli are limited due to methodological choices: they define OOD shift relative to model training data or use arbitrary distortion-specific parameters with little correspondence to human perception, hindering principled comparisons. We propose a human-centred framework that redefines the degree of OOD as a spectrum of human perceptual difficulty. By quantifying how much a collection of stimuli deviates from an undistorted reference set based on human accuracy, we construct an OOD spectrum and identify four distinct regimes of perceptual challenge. This approach enables principled model-human comparisons at calibrated difficulty levels. We apply this framework to object recognition and reveal unique, regime-dependent model-human alignment rankings and profiles across deep learning architectures. Vision-language models are most consistently human aligned across near- and far-OOD conditions, but convolutional neural networks (CNNs) are more aligned than vision transformers (ViTs) for near-OOD and ViTs are more aligned than CNNs for far-OOD. Our work demonstrates the critical importance of accounting for cross-condition differences, such as perceptual difficulty, for a principled assessment of model-human alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a human-centred framework to define an out-of-distribution (OOD) spectrum based on human perceptual difficulty for assessing error alignment between humans and AI models in object recognition tasks. By using human accuracy on distorted stimuli to calibrate difficulty levels, it identifies four regimes and reports that vision-language models (VLMs) are most consistently aligned with humans across near- and far-OOD, with convolutional neural networks (CNNs) showing better alignment than vision transformers (ViTs) in near-OOD and the reverse in far-OOD.
Significance. This work has potential significance for cognitive science and trustworthy AI by providing a calibrated way to compare model and human error patterns at matched difficulty levels. If the spectrum construction is robust, it could highlight important architecture-specific differences in alignment that standard OOD analyses miss, encouraging more nuanced evaluations of AI systems.
major comments (2)
- [Abstract] The abstract reports regime-dependent rankings but provides insufficient detail on how the OOD spectrum is constructed, including the specific human accuracy thresholds for the four regimes, the size of the stimulus set, and any statistical tests used to validate the regimes.
- [Framework] The assumption that human accuracy defines a model-independent OOD spectrum (as per the framework description) is load-bearing for the central claim; without evidence that the perceptual difficulty ordering is consistent across CNNs, ViTs, and VLMs, the reported reversal in alignment rankings between near-OOD and far-OOD could be due to architecture-specific sensitivities to the distortions rather than true alignment differences.
minor comments (2)
- Add error bars and report dataset sizes in all figures and tables presenting alignment metrics to improve clarity and reproducibility.
- Clarify the exact definition of 'error alignment' metric used for comparisons.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] The abstract reports regime-dependent rankings but provides insufficient detail on how the OOD spectrum is constructed, including the specific human accuracy thresholds for the four regimes, the size of the stimulus set, and any statistical tests used to validate the regimes.
Authors: We agree that the abstract should provide more detail on the OOD spectrum construction. In the revised manuscript, we will expand the abstract to summarize the human accuracy thresholds defining the four regimes, the total size of the stimulus set used for calibration, and the statistical approaches (including any tests for regime separation) employed to validate the spectrum. These additions will be kept concise while directing readers to the methods section for full details. revision: yes
-
Referee: [Framework] The assumption that human accuracy defines a model-independent OOD spectrum (as per the framework description) is load-bearing for the central claim; without evidence that the perceptual difficulty ordering is consistent across CNNs, ViTs, and VLMs, the reported reversal in alignment rankings between near-OOD and far-OOD could be due to architecture-specific sensitivities to the distortions rather than true alignment differences.
Authors: We thank the referee for raising this foundational concern. The OOD spectrum is defined solely from human accuracy on the stimuli, making the difficulty ordering and regime boundaries model-independent by construction; all models are evaluated against the same human-calibrated difficulty levels. The reversal in alignment rankings is therefore measured under this fixed human reference. To address potential concerns about architecture-specific sensitivities, we will add a supplementary analysis in the revision showing that accuracy for CNNs, ViTs, and VLMs decreases with increasing human-defined difficulty, supporting that the regimes reflect progressive challenge across architectures. This clarification and addition will strengthen the framework's justification without altering the core results. revision: partial
Circularity Check
No circularity in human-centred OOD definition
full rationale
The paper defines its OOD spectrum directly from measured human accuracy drops on a fixed collection of distorted stimuli relative to an undistorted reference, producing four perceptual-difficulty regimes as an external empirical input. Model error patterns are then compared to human error patterns at these fixed levels via separate alignment metrics. No step fits a parameter to model outputs and relabels it a prediction, invokes a self-citation as the sole justification for a uniqueness claim, or reduces the reported architecture rankings to a definitional identity. The derivation therefore remains self-contained against external human data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human accuracy on distorted images is a valid proxy for perceptual difficulty independent of any particular model
Reference graph
Works this paper leans on
-
[1]
Nikolaus Kriegeskorte. Deep neural networks: a new framework for modeling biological vision and brain information processing.Annual review of vision science, 1(1):417–446, 2015
work page 2015
-
[2]
Deep neural networks as scientific models.Trends in cognitive sciences, 23(4):305–317, 2019
Radoslaw M Cichy and Daniel Kaiser. Deep neural networks as scientific models.Trends in cognitive sciences, 23(4):305–317, 2019
work page 2019
-
[3]
Friedemann Pulvermüller, Rosario Tomasello, Malte R Henningsen-Schomers, and Thomas Wennekers. Biological constraints on neural network models of cognitive function.Nature Reviews Neuroscience, 22(8):488–502, 2021
work page 2021
-
[4]
Rishi Rajalingham, Elias B Issa, Pouya Bashivan, Kohitij Kar, Kailyn Schmidt, and James J DiCarlo. Large-scale, high-resolution comparison of the core visual object recognition behavior of humans, monkeys, and state-of-the-art deep artificial neural networks.Journal of Neuroscience, 38(33):7255–7269, 2018
work page 2018
-
[5]
Getting aligned on representational alignment.arXiv preprint arXiv:2310.13018, 2023
Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C Love, Erin Grant, Iris Groen, Jascha Achterberg, et al. Getting aligned on representational alignment.arXiv preprint arXiv:2310.13018, 2023
-
[6]
Human uncertainty makes classification more robust
Joshua C Peterson, Ruairidh M Battleday, Thomas L Griffiths, and Olga Russakovsky. Human uncertainty makes classification more robust. InProceedings of the IEEE/CVF international conference on computer vision, pages 9617–9626, 2019
work page 2019
-
[7]
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C Mozer, Klaus-Robert Müller, Thomas Unterthiner, and Andrew K Lampinen. Aligning machine and human visual representations across abstraction levels.Nature, 647(8089):349–355, 2025. *https://docs.google.com/spreadsheets/d/1ldqG8LlQd_tDh9f3xdZQRA3v2UffUIhaLds2wTrhoLU/e...
work page 2025
-
[8]
Thomas Fel, Ivan F Rodriguez Rodriguez, Drew Linsley, and Thomas Serre. Harmonizing the object recognition strategies of deep neural networks with humans.Advances in neural information processing systems, 35:9432– 9446, 2022
work page 2022
-
[9]
Aidan Boyd, Mohamed Trabelsi, Huseyin Uzunalioglu, and Dan Kushnir. Increasing interpretability of neural networks by approximating human visual saliency.arXiv preprint arXiv:2410.16115, 2024
-
[10]
Drew Linsley, Pinyuan Feng, Thibaut Boissin, Alekh Karkada Ashok, Thomas Fel, Stephanie Olaiya, and Thomas Serre. Adversarial alignment: Breaking the trade-off between the strength of an attack and its relevance to human perception.arXiv preprint arXiv:2306.03229, 2023
-
[11]
Blaine Hoak, Kunyang Li, and Patrick McDaniel. Alignment and adversarial robustness: Are more human-like models more secure?arXiv preprint arXiv:2502.12377, 2025
- [12]
-
[13]
Robert Geirhos, Kristof Meding, and Felix A. Wichmann. Beyond accuracy: quantifying trial-by-trial behaviour of cnns and humans by measuring error consistency. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
work page 2020
-
[14]
Measuring error alignment for decision-making systems
Binxia Xu, Antonis Bikakis, Daniel FO Onah, Andreas Vlachidis, and Luke Dickens. Measuring error alignment for decision-making systems. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27731–27739, 2025
work page 2025
-
[15]
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. In International conference on learning representations, 2018
work page 2018
-
[16]
Nicholas Baker, Hongjing Lu, Gennady Erlikhman, and Philip J Kellman. Deep convolutional networks do not classify based on global object shape.PLoS computational biology, 14(12):e1006613, 2018
work page 2018
-
[17]
Colin Conwell, Jacob S Prince, Kendrick N Kay, George A Alvarez, and Talia Konkle. A large-scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature communications, 15(1):9383, 2024
work page 2024
-
[18]
Saeed R Kheradpisheh, Masoud Ghodrati, Mohammad Ganjtabesh, and Timothée Masquelier. Humans and deep networks largely agree on which kinds of variation make object recognition harder.Frontiers in computational neuroscience, 10:92, 2016
work page 2016
-
[19]
A study and comparison of human and deep learning recognition performance under visual distortions
Samuel Dodge and Lina Karam. A study and comparison of human and deep learning recognition performance under visual distortions. In2017 26th international conference on computer communication and networks (ICCCN), pages 1–7. IEEE, 2017
work page 2017
-
[20]
Robert Geirhos, Carlos RM Temme, Jonas Rauber, Heiko H Schütt, Matthias Bethge, and Felix A Wichmann. Generalisation in humans and deep neural networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[21]
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.Proceedings of the International Conference on Learning Representations, 2019
work page 2019
-
[22]
What’out-of-distribution’is and is not
Sebastian Farquhar and Yarin Gal. What’out-of-distribution’is and is not. InNeurips ml safety workshop, 2022
work page 2022
-
[23]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distribution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583–18599, 2020
work page 2020
-
[25]
Partial success in closing the gap between human and machine vision
Robert Geirhos, Kantharaju Narayanappa, Benjamin Mitzkus, Tizian Thieringer, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Partial success in closing the gap between human and machine vision. In Advances in Neural Information Processing Systems 34, 2021
work page 2021
-
[26]
Understanding how image quality affects deep neural networks
Samuel Dodge and Lina Karam. Understanding how image quality affects deep neural networks. In2016 eighth international conference on quality of multimedia experience (QoMEX), pages 1–6. IEEE, 2016
work page 2016
-
[27]
Methods and measurements to compare men against machines.Electronic Imaging, 29:36–45, 2017
Felix A Wichmann, David HJ Janssen, Robert Geirhos, Guillermo Aguilar, Heiko H Schütt, Marianne Maertens, and Matthias Bethge. Methods and measurements to compare men against machines.Electronic Imaging, 29:36–45, 2017
work page 2017
-
[28]
Girik Malik, Dakarai Crowder, and Ennio Mingolla. Extreme image transformations affect humans and machines differently.Biological Cybernetics, 117(4):331–343, 2023. 14 Do machines fail like humans?
work page 2023
-
[29]
Larry V Hedges. Distribution theory for glass’s estimator of effect size and related estimators.journal of Educational Statistics, 6(2):107–128, 1981
work page 1981
-
[30]
Vishwakumara Kayargadde and Jean-Bernard Martens. Perceptual characterization of images degraded by blur and noise: model.Journal of the Optical Society of America A, 13(6):1178–1188, 1996
work page 1996
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[32]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[33]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[35]
Shikhar Tuli, Ishita Dasgupta, Erin Grant, and Thomas L Griffiths. Are convolutional neural networks or transformers more like human vision?arXiv preprint arXiv:2105.07197, 2021
-
[36]
Gary Lupyan and Emily J Ward. Language can boost otherwise unseen objects into visual awareness.Proceedings of the National Academy of Sciences, 110(35):14196–14201, 2013
work page 2013
-
[37]
Peter D Weller, Milena Rabovsky, and Rasha Abdel Rahman. Semantic knowledge enhances conscious awareness of visual objects.Journal of Cognitive Neuroscience, 31(8):1216–1226, 2019
work page 2019
-
[38]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[39]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017
work page 2017
-
[40]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
work page 2016
-
[41]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[42]
Maxvit: Multi-axis vision transformer
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxvit: Multi-axis vision transformer. InEuropean conference on computer vision, pages 459–479. Springer, 2022
work page 2022
-
[43]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019
work page 2019
-
[44]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022. 15 Do machines fail like humans? Appendix Code is available athttps://github.com/xubinxia/ood-spectrum. A. Statistical ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.