Recognition: no theorem link
TERMINATOR: Learning Optimal Exit Points for Early Stopping in Chain-of-Thought Reasoning
Pith reviewed 2026-05-15 11:09 UTC · model grok-4.3
The pith
Terminator trains a predictor on the first position where a reasoning model outputs its final answer to stop chain-of-thought generation early.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Terminator is an early-exit strategy that treats the first arrival of the final answer token as a proxy for the optimal stopping point, builds a dataset of these positions from existing chain-of-thought traces, and trains a lightweight predictor to forecast the same positions on new inputs, thereby shortening reasoning sequences with virtually no accuracy drop on MATH-500, AIME 2025, HumanEval, and GPQA.
What carries the argument
A predictor trained on first-answer positions extracted from chain-of-thought traces to forecast optimal exit points at inference time.
If this is right
- CoT lengths drop 14-55 percent on average on MATH-500, AIME 2025, HumanEval, and GPQA while accuracy stays the same.
- Inference latency falls by more than a factor of two compared with standard full-generation runs.
- The approach outperforms prior state-of-the-art early-stopping baselines on the same four datasets.
- Optimal exit points can be learned in a task- and model-specific manner without hand-crafted heuristics.
Where Pith is reading between the lines
- The same first-answer labeling trick could be reused to create early-exit datasets for other autoregressive tasks such as code synthesis or multi-step planning.
- If the predictor transfers across model families, it would allow a single stopping model to accelerate many different reasoning systems.
- One could test whether the learned exit points correlate with human judgments of when a reasoning trace has become redundant.
Load-bearing premise
The first token position at which the model emits its final answer is a reliable proxy for the optimal stopping point and a predictor trained on these positions will generalize without harming accuracy on unseen problems or different models.
What would settle it
Running the trained predictor on a held-out test set and observing a statistically significant drop in final answer accuracy relative to full chain-of-thought generation would falsify the central claim.
Figures

















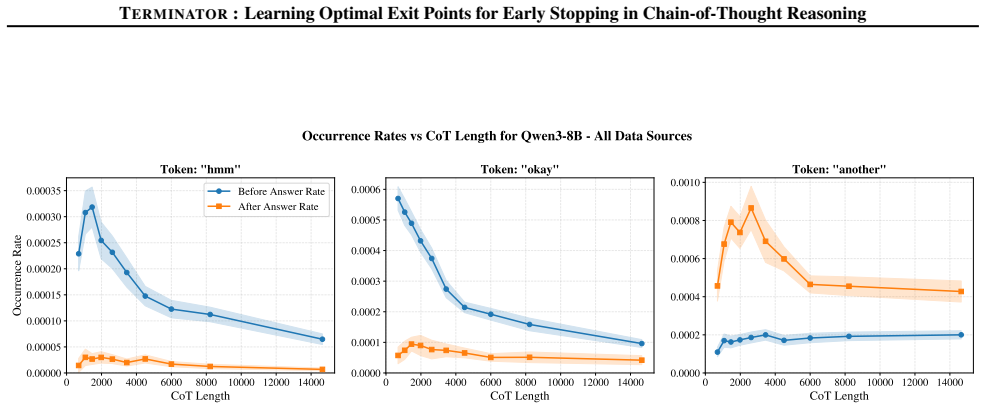












read the original abstract
Large Reasoning Models (LRMs) achieve impressive performance on complex reasoning tasks via Chain-of-Thought (CoT) reasoning, which enables them to generate intermediate thinking tokens before arriving at the final answer. However, LRMs often suffer from significant overthinking, spending excessive compute time even after the answer is generated early on. Prior work has identified the existence of an optimal reasoning length such that truncating reasoning at this point significantly shortens CoT outputs with virtually no change in performance. However, determining optimal CoT lengths for practical datasets is highly non-trivial as they are fully task and model-dependent. In this paper, we precisely address this and design Terminator, an early-exit strategy for LRMs at inference to mitigate overthinking. The central idea underpinning Terminator is that the first arrival of an LRM's final answer is often predictable, and we leverage these first answer positions to create a novel dataset of optimal reasoning lengths to train Terminator. Powered by this approach, Terminator achieves significant reductions in CoT lengths of 14%-55% on average across four challenging practical datasets: MATH-500, AIME 2025, HumanEval, and GPQA, while outperforming current state-of-the-art methods and reducing inference latency by more than 2x compared to the original LRM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Terminator, an early-exit strategy for Large Reasoning Models performing Chain-of-Thought reasoning. It constructs training labels from the first token position at which the model emits a final answer (e.g., in boxed format), trains a separate predictor on these positions as proxies for optimal stopping points, and reports 14-55% average CoT length reductions on MATH-500, AIME 2025, HumanEval, and GPQA while outperforming prior methods and cutting latency by more than 2x with virtually no accuracy change.
Significance. If the central claims hold after verification, the work would offer a practical, model-agnostic way to reduce overthinking and inference cost in LRMs on hard reasoning tasks, with clear deployment value for latency-sensitive applications.
major comments (2)
- [Abstract] Abstract: the headline guarantee of 'virtually no change in performance' is load-bearing for the contribution, yet the manuscript provides no information on how accuracy equivalence was measured across datasets, whether error bars or statistical tests were used, or how the training set was constructed to avoid leakage from the same LRM whose outputs supply the labels.
- [Method] Central method (first-answer-position labeling): treating the first emission of a final answer as the optimal exit label requires explicit empirical verification on held-out prompts that tokens generated after this point never improve correctness; absent such a check, any systematic mismatch between the proxy and true optimality directly undermines the no-accuracy-loss claim.
Simulated Author's Rebuttal
We appreciate the referee's detailed and constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline guarantee of 'virtually no change in performance' is load-bearing for the contribution, yet the manuscript provides no information on how accuracy equivalence was measured across datasets, whether error bars or statistical tests were used, or how the training set was constructed to avoid leakage from the same LRM whose outputs supply the labels.
Authors: We thank the referee for this observation. Accuracy equivalence was evaluated via exact-match on the final answer (e.g., boxed content) between full CoT and early-exit outputs on identical test prompts. In the revised manuscript we will expand the abstract and add an explicit evaluation subsection that reports the precise metric, includes error bars computed over 3 independent runs with different random seeds, and describes the training-set construction: labels were generated on a disjoint collection of prompts (distinct from all evaluation sets) to prevent leakage from the same LRM. revision: yes
-
Referee: [Method] Central method (first-answer-position labeling): treating the first emission of a final answer as the optimal exit label requires explicit empirical verification on held-out prompts that tokens generated after this point never improve correctness; absent such a check, any systematic mismatch between the proxy and true optimality directly undermines the no-accuracy-loss claim.
Authors: We agree that a direct empirical check would strengthen the optimality assumption. While our reported results already demonstrate that early exits at the predicted positions preserve accuracy, the manuscript does not contain an explicit ablation confirming that post-first-answer tokens never alter correctness on held-out prompts. We will add this verification in the revised version by continuing generation after the first-answer position on a held-out subset and measuring any change in final-answer correctness; the results and any necessary discussion of the proxy's limitations will be included. revision: yes
Circularity Check
No significant circularity: labels are observable first-answer positions; performance claims rest on empirical evaluation
full rationale
The paper constructs a dataset of reasoning lengths directly from the observable first token positions at which the LRM emits a final answer during full generation. Terminator is trained as a standard supervised predictor on these labels. The headline performance claims (length reduction with virtually no accuracy change) are supported by direct empirical measurements on held-out examples from MATH-500, AIME 2025, HumanEval, and GPQA rather than by any definitional equivalence or self-referential reduction. No equation or step equates the learned exit prediction to its own training labels by construction, and no load-bearing self-citation or imported uniqueness theorem is invoked. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=MSbU3L7V00. Cheng, J. and Durme, B. V . Compressed chain of thought: Efficient reasoning through dense representations, 2024. URLhttps://arxiv.org/abs/2412.13171. Chevalier, A., Wettig, A., Ajith, A., and Chen, D. Adapting language models to compress contexts. In Bouamor, H., Pino, J., and Bali, K. (eds.),Proceed- ings...
-
[2]
URL https://aclanthology.org/2023. emnlp-main.232/. Ding, B., Chen, Y ., Wang, F., Ming, L., and Lin, T. Do thinking tokens help or trap? towards more efficient large reasoning model, 2025. URL https://arxiv.org/ abs/2506.23840. Fu, Y ., Chen, J., Zhu, S., Fu, Z., Dai, Z., Zhuang, Y ., Ma, Y ., Qiao, A., Rosing, T., Stoica, I., and Zhang, H. Ef- ficiently...
-
[3]
Training Large Language Models to Reason in a Continuous Latent Space
URL https://openreview.net/forum? id=uREj4ZuGJE. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Lu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[4]
URL https://openreview.net/forum? id=9YvfRrpmyw. Jung, H. and Kim, K.-J. Discrete prompt compression with reinforcement learning.IEEE Access, 12:72578–72587,
-
[5]
ISSN 2169-3536. doi: 10.1109/access.2024. 3403426. URL http://dx.doi.org/10.1109/ ACCESS.2024.3403426. Kang, Y ., Sun, X., Chen, L., and Zou, W. C3ot: Generating shorter chain-of-thought without compromising effective- ness.Proceedings of the AAAI Conference on Artificial Intelligence, 39(23):24312–24320, Apr. 2025a. doi: 10. 1609/aaai.v39i23.34608. URL h...
-
[6]
URL https://openreview.net/forum? id=v8L0pN6EOi. Liu, A. H., Khandelwal, K., Subramanian, S., Jouault, V ., Rastogi, A., Sadé, A., Jeffares, A., Jiang, A., Cahill, A., Gavaudan, A., Sablayrolles, A., Héliou, A., You, A., Ehrenberg, A., Lo, A., Eliseev, A., Calvi, A., Soori- yarachchi, A., Bout, B., Rozière, B., Monicault, B. D., Lanfranchi, C., Barreau, C...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
URL https: //aclanthology.org/2025.acl-long.300/
doi: 10.18653/v1/2025.acl-long.300. URL https: //aclanthology.org/2025.acl-long.300/. Mao, M., Yin, B., Zhu, Y ., and Fang, X. Early stopping chain-of-thoughts in large language models, 2025. URL https://arxiv.org/abs/2509.14004. Mu, J., Li, X. L., and Goodman, N. Learning to com- press prompts with gist tokens. InThirty-seventh Conference on Neural Infor...
-
[8]
URL https://openreview.net/forum? id=2DtxPCL3T5. Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., and Hashimoto, T. s1: Simple test-time scaling, 2025. URL https://arxiv.org/abs/2501.19393. Nagle, A., Girish, A., Bondaschi, M., Gastpar, M., Makkuva, A. V ., and Kim, H. Fundamental limits o...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-3009 2025
-
[9]
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 13 TERMINATOR: Learning Optimal Exit Points for Early Stopping in Chain-of-Thought Reasoning 6fac9e316a4ae75ea244ddcef1982c71-Paper-Conference. pdf. Shrivastava, V ., Awadallah, A., Balachandran, V ., Garg, S., Behl, H., and Papailiopoulos, D. Sample more to think less: Group filtered policy...
-
[13]
URL https://aclanthology.org/2025. emnlp-main.184/. Zhang, J., Zhu, Y ., Sun, M., Luo, Y ., Qiao, S., Du, L., Zheng, D., Chen, H., and Zhang, N. LightThinker: Thinking step-by-step compression. In Christodoulopou- los, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processi...
-
[14]
Extract the final answer from:
URL https://aclanthology.org/2025. emnlp-main.673/. Zhang, Z., He, X., Yan, W., Shen, A., Zhao, C., Wang, S., Shen, Y ., and Wang, X. E. Soft thinking: Un- locking the reasoning potential of llms in continuous 14 TERMINATOR: Learning Optimal Exit Points for Early Stopping in Chain-of-Thought Reasoning concept space, 2025d. URL https://arxiv.org/ abs/2505....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.