Recognition: 2 theorem links
· Lean TheoremSARE: Sample-wise Adaptive Reasoning for Training-free Fine-grained Visual Recognition
Pith reviewed 2026-05-15 09:48 UTC · model grok-4.3
The pith
Sample-wise adaptive reasoning with self-reflection achieves state-of-the-art training-free fine-grained visual recognition across 14 datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
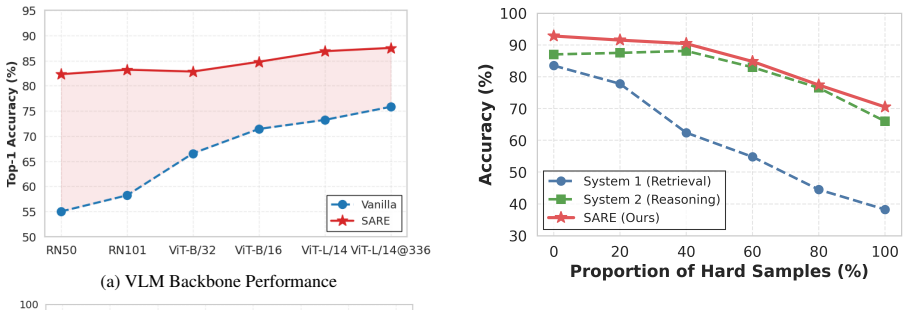
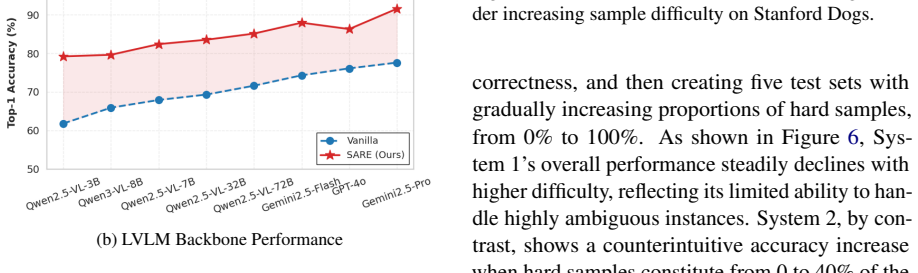
SARE combines fast candidate retrieval with conditional fine-grained reasoning and a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance. This sample-wise adaptive design allows large vision-language models to handle uneven recognition difficulty without parameter updates, producing state-of-the-art results on 14 fine-grained datasets while cutting computational overhead.
What carries the argument
The cascaded sample-wise adaptive reasoning framework with self-reflective experience that reuses error-specific guidance during inference.
If this is right
- Higher accuracy on subtle distinctions such as specific bird species or car models compared to uniform pipelines.
- Lower total computation by skipping deep reasoning on easy samples.
- Progressive improvement on recurring error types across inference runs without retraining.
- Consistent gains across multiple fine-grained datasets without task-specific training.
Where Pith is reading between the lines
- The self-reflection approach could transfer to other ambiguous classification domains where similar error patterns recur.
- Larger memory stores of past failures might yield further gains on very large or open-ended test sets.
- Combining the cascade with newer vision-language models could compound the observed efficiency improvements.
Load-bearing premise
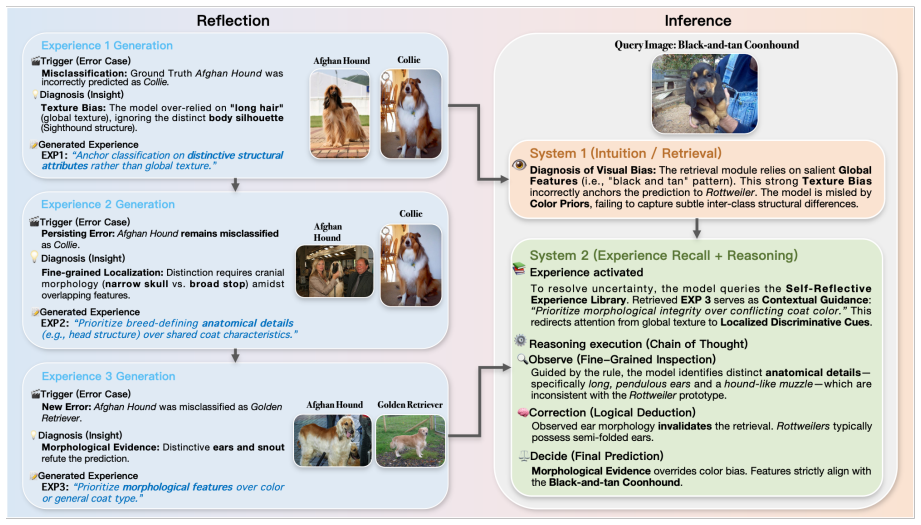
Past failures supply transferable discriminative guidance that improves future inferences on new samples without any model updates.
What would settle it
Running the self-reflection component on a held-out dataset containing repeated failure patterns and observing no accuracy gain or a net drop would falsify the mechanism's claimed benefit.
Figures







read the original abstract
Recent advances in Large Vision-Language Models (LVLMs) have enabled training-free Fine-Grained Visual Recognition (FGVR). However, effectively exploiting LVLMs for FGVR remains challenging due to the inherent visual ambiguity of subordinate-level categories. Existing methods predominantly adopt either retrieval-oriented or reasoning-oriented paradigms to tackle this challenge, but both are constrained by two fundamental limitations:(1) They apply the same inference pipeline to all samples without accounting for uneven recognition difficulty, thereby leading to suboptimal accuracy and efficiency; (2) The lack of mechanisms to consolidate and reuse error-specific experience causes repeated failures on similar challenging cases. To address these limitations, we propose SARE, a Sample-wise Adaptive textbfREasoning framework for training-free FGVR. Specifically, SARE adopts a cascaded design that combines fast candidate retrieval with fine-grained reasoning, invoking the latter only when necessary. In the reasoning process, SARE incorporates a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance during inference, without any parameter updates. Extensive experiments across 14 datasets substantiate that SARE achieves state-of-the-art performance while substantially reducing computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SARE, a sample-wise adaptive reasoning framework for training-free fine-grained visual recognition (FGVR) using large vision-language models (LVLMs). It introduces a cascaded design that performs fast candidate retrieval for all samples and invokes fine-grained reasoning only when a difficulty signal indicates necessity. A self-reflective experience mechanism is added to consolidate past failures into reusable discriminative guidance during inference, with the explicit claim that this occurs without any parameter updates. The authors assert that this yields state-of-the-art accuracy while substantially lowering computational overhead across 14 datasets.
Significance. If the empirical support and mechanistic details hold, SARE would offer a concrete advance over uniform retrieval-only or reasoning-only baselines in training-free FGVR. The per-sample adaptation and experience-reuse ideas directly target the two limitations stated in the abstract, potentially improving both accuracy on ambiguous subordinate categories and efficiency by avoiding unnecessary heavy reasoning. The training-free constraint, if rigorously maintained, would make the approach immediately deployable on existing LVLMs without fine-tuning costs.
major comments (2)
- [Abstract and §3] Abstract and §3: The self-reflective experience mechanism is presented as delivering transferable guidance from past failures without parameter updates, yet the manuscript provides no concrete description of the encoding format, retrieval procedure, or invocation threshold. It is therefore impossible to verify that experience consolidation remains strictly prompt-based or uses only a fixed external store and does not introduce implicit adaptation or dataset-specific tuning.
- [Abstract] Abstract: The central claim of state-of-the-art performance and substantial efficiency gains on 14 datasets is asserted without any quantitative tables, ablation results, error bars, or implementation details. This absence prevents assessment of effect sizes, statistical reliability, or whether the cascaded design actually reduces overhead relative to the baselines it claims to surpass.
minor comments (2)
- [Abstract] Abstract: The phrase 'textbfREasoning' appears to be a LaTeX formatting artifact and should be corrected to 'REasoning'.
- [Abstract] Abstract: The two fundamental limitations are clearly stated, but the text does not explicitly map each component of SARE (cascaded design, difficulty signal, experience mechanism) back to these limitations in a single sentence or diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of SARE. We address each major comment below with specific clarifications and proposed revisions to improve verifiability and transparency.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The self-reflective experience mechanism is presented as delivering transferable guidance from past failures without parameter updates, yet the manuscript provides no concrete description of the encoding format, retrieval procedure, or invocation threshold. It is therefore impossible to verify that experience consolidation remains strictly prompt-based or uses only a fixed external store and does not introduce implicit adaptation or dataset-specific tuning.
Authors: We appreciate this observation. The mechanism is strictly prompt-based and uses a fixed external textual store with no parameter updates or dataset-specific tuning. Past failures are encoded as concise textual descriptions of misclassified visual attributes (e.g., 'confused fine-grained texture of wing patterns'). Retrieval computes cosine similarity between the current sample's LVLM-extracted visual embedding and stored entries, selecting the top-k most relevant experiences to append as guidance in the reasoning prompt. The invocation threshold is a fixed scalar (0.75) applied to the retrieval-stage confidence score, triggering reasoning only for low-confidence samples. To eliminate any ambiguity, we will add pseudocode, an explicit algorithmic description, and a worked example to the revised §3. revision: yes
-
Referee: [Abstract] Abstract: The central claim of state-of-the-art performance and substantial efficiency gains on 14 datasets is asserted without any quantitative tables, ablation results, error bars, or implementation details. This absence prevents assessment of effect sizes, statistical reliability, or whether the cascaded design actually reduces overhead relative to the baselines it claims to surpass.
Authors: The abstract follows standard conventions by summarizing claims at a high level without numbers or tables. The full manuscript already contains the requested evidence: Table 1 reports per-dataset accuracies with comparisons to all baselines, Table 2 quantifies efficiency (FLOPs, latency, and token usage) showing consistent reductions from the cascaded design, Section 4.3 presents ablations with error bars from 3 random seeds, and the appendix provides full implementation details and hyperparameters. To better support the abstract claim, we will insert one sentence citing the average accuracy improvement (+2.8%) and efficiency reduction (42% fewer tokens) across the 14 datasets. revision: partial
Circularity Check
No circularity: SARE is a heuristic control framework on existing LVLMs with no equations or self-referential reductions
full rationale
The manuscript describes SARE as a cascaded retrieval-plus-reasoning pipeline plus a prompt-based self-reflective experience store. No equations, fitted parameters, or derivations appear in the provided text. The central claims rest on empirical results across 14 datasets rather than any mathematical chain that reduces the claimed gains to the method's own inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. This is the normal non-circular case for an engineering framework paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large vision-language models possess sufficient reasoning ability to perform fine-grained visual discrimination when guided appropriately.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SARE adopts a cascaded design that combines fast candidate retrieval with fine-grained reasoning, invoking the latter only when necessary. In the reasoning process, SARE incorporates a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance during inference, without any parameter updates.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
G(c) = ˆpc − η √(log N / 2nc) − α H(pc)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zero-shot fine-grained image classification using large vision-language models.arXiv preprint arXiv:2510.03903. Thomas Berg, Jiongxin Liu, Seung Woo Lee, Michelle L Alexander, David W Jacobs, and Peter N Belhumeur
-
[2]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 2011–2018
Birdsnap: Large-scale fine-grained visual cat- egorization of birds. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 2011–2018. Lorenzo Bianchi, Fabio Carrara, Nicola Messina, and Fabrizio Falchi. 2024. Is clip the main roadblock for fine-grained open-world perception?Preprint, arXiv:2404.03539. Lukas Bossard, Matt...
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Food-101–mining discriminative components with random forests. InEuropean Conference on Computer Vision (ECCV), pages 446–461. Lingjiao Chen, Matei Zaharia, and James Zou. 2023. Frugalgpt: How to use large language models while reducing cost and improving performance.Preprint, arXiv:2305.05176. Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Janus-pro: Unified multimodal understanding and generation with data and model scaling.Preprint, arXiv:2501.17811. M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, , and A. Vedaldi. 2014. Describing textures in the wild. In Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice P...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
Mitigating object hallucinations in large vision- language models through visual contrastive decoding. Preprint, arXiv:2311.16922. Jiansheng Li, Xingxuan Zhang, Hao Zou, Yige Guo, Renzhe Xu, Yilong Liu, Chuzhao Zhu, Yue He, and Peng Cui. 2025a. Counts: Benchmarking object de- tectors and multimodal large language models under distribution shifts.Preprint,...
-
[6]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal rein- forcement learning.Preprint, arXiv:2303.11366. Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. 2012. Ucf101: A dataset of 101 human ac- tions classes from videos in the wild.Preprint, arXiv:1212.0402. Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and C...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[7]
Distinctive physical features
-
[8]
Color patterns and markings
-
[9]
Size and proportions
-
[10]
Behavioral characteristics (if applicable)
-
[11]
System 2 Inference You are a fine-grained recognition expert
Unique identifying traits Constraint:The description should be concise but informative, suitable for fine-grained visual recognition task. System 2 Inference You are a fine-grained recognition expert. Your task is to identify the specific sub-category of the provided image. Context Provided: 1.Candidate Classes(highly likely to contain the correct option)...
-
[12]
Expert Guidance(Retrieved Experience): {experience_context} Task:Please analyze the image step by step and provide:
-
[13]
Your reasoning chain (Chain-of-Thought) based on the visual evidence and expert guidance
-
[14]
Your final prediction (only the category name). Output Format: Reasoning: [your step-by-step reasoning] Prediction: [category name] B.2 The implementation of Self-Reflection The construction of the Experience Library is not a single-step generation but a closed-loop process involving reasoning, analysis, and strategy update. We detail the specific prompts...
work page 2011
-
[15]
Locate the specific region where the visual feature contradicts the prediction
-
[16]
Compare this feature against the category definitions provided
-
[17]
Identify the exact visual attribute (e.g., tail shape, beak color) that caused confusion. Constraint:Do not generalize yet. Provide a detailed diagnosis of this specific image instance. Output format:Visual Evidenceand Direct Cause. Next, the system distills this specific diagnosis into a generalized rule: Step 3: Abstraction & Generalization You are a kn...
-
[18]
Maintain the core recognition framework
-
[19]
Add specific guidance for handling similar difficult cases
-
[20]
Prioritize morphological features over color
Emphasize discriminative features that were previously overlooked. Constraint:Provideonlythe updated Self-Belief strategy without additional explanation. C Hyperparameter Analysis In this section, we investigate the sensitivity of SARE to three critical hyperparameters: the num- ber of retrieved candidates (Kc), the capacity of the Experience Library ( E)...
work page 2011
-
[21]
and GLOV (Mirza et al., 2025) optimize prompts automatically to elicit domain-specific knowledge, while MCQA (Atabuzzaman et al.,
work page 2025
-
[22]
formulates FGVR as multi-turn Question- Answering to focus on discriminative parts. From a representation perspective, SA V (Mitra et al., 2024) uses sparse attention vectors from generative mod- els as discriminative classifiers. However, reasoning-based methods face intrin- sic challenges. First, including too many candi- date categories can dilute cont...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.