Recognition: unknown
Evidence of an Emergent "Self" in Continual Robot Learning
Pith reviewed 2026-05-15 00:29 UTC · model grok-4.3
The pith
Continual learning causes robots to develop a stable invariant subnetwork that functions as an emergent self.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
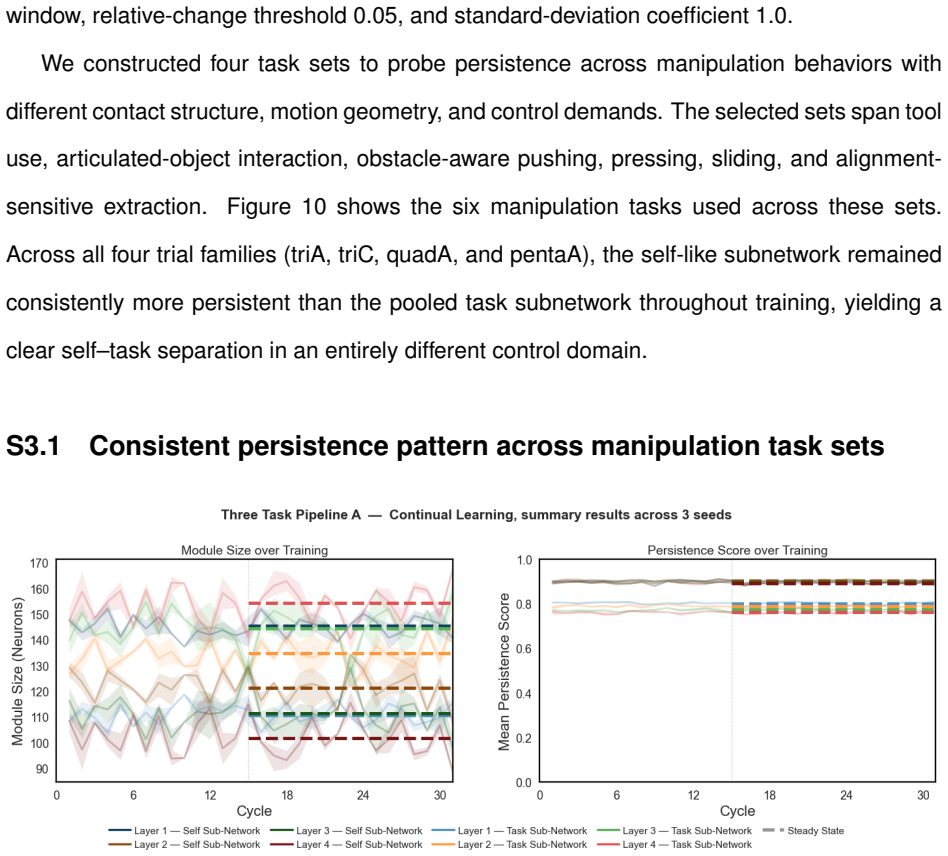
Robots subjected to continual learning under variable tasks develop an invariant subnetwork that remains significantly more stable than in robots learning a constant task, with statistical significance at p < 0.001. This subnetwork is functionally important because preserving it aids adaptation to new tasks while damaging it impairs performance. The authors interpret this invariant structure as evidence of an emergent self, defined as the portion of cognition that changes least compared to acquired skills.
What carries the argument
The invariant subnetwork, identified as the portion of the neural network with the least weight change during learning, proposed as the representation of the self.
If this is right
- Preserving the invariant subnetwork improves a robot's ability to adapt to new tasks.
- Damaging the invariant subnetwork reduces performance in continual learning scenarios.
- Continual learning environments produce more stable invariant subnetworks than static task environments.
- The stability difference is statistically significant with p less than 0.001.
Where Pith is reading between the lines
- This approach could be extended to non-robotic AI systems like language models to detect similar invariant structures.
- If the invariant subnetwork truly represents self, then systems without continual learning pressure might lack a developed self.
- Future experiments could test whether this subnetwork correlates with consistent behavior across different environments.
Load-bearing premise
That the most invariant portion of the network can be identified with the self.
What would settle it
If experiments show no significant difference in stability between continual and constant learning robots, or if damaging the identified subnetwork does not disproportionately impair adaptation compared to random damage.
Figures





















read the original abstract
A key challenge to understanding self-awareness has been a principled way of quantifying whether an intelligent system has a concept of a "self", and if so how to differentiate the "self" from other cognitive structures. We propose that the "self" can be isolated by seeking the invariant portion of cognitive process that changes relatively little compared to more rapidly acquired cognitive knowledge and skills, because our self is the most persistent aspect of our experiences. We used this principle to analyze the cognitive structure of robots under two conditions: One robot learns a constant task, while a second robot is subjected to continual learning under variable tasks. We find that robots subjected to continual learning develop an invariant subnetwork that is significantly more stable (p < 0.001) compared to the control, and that this subnetwork is also functionally important: preserving it aids adaptation while damaging it impairs performance. We suggest that this principle can offer a window into exploring selfhood in other cognitive AI systems
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes isolating the 'self' in intelligent systems as the most invariant portion of cognitive processes, which changes little relative to acquired skills. It compares a robot learning a constant task against one under continual learning with variable tasks, reporting that the continual-learning robot develops a significantly more stable invariant subnetwork (p < 0.001). This subnetwork is functionally relevant: preserving it supports adaptation while ablating it impairs performance. The authors argue the approach provides a window into selfhood in other AI systems.
Significance. If the empirical results hold after fuller documentation, the work supplies a concrete, measurable criterion for detecting emergent invariant structures in continual-learning agents and demonstrates their functional role via preservation/ablation tests. The statistical threshold and performance impact are positive features. The interpretive step equating invariance with selfhood, however, remains an open claim that would benefit from external validation.
major comments (2)
- Abstract: the reported statistical result (p < 0.001) and functional test are presented without any description of network architecture, task definitions, the precise procedure used to extract the invariant subnetwork, or controls for total training time and network size. These omissions prevent evaluation of whether the stability difference is attributable to the continual-learning condition rather than confounding variables.
- Methods (assumed section describing subnetwork isolation): the invariant subnetwork is isolated by the same invariance criterion that is then used to label it the 'self'. No independent behavioral, representational, or self-other distinction test is supplied to decouple the measurement from the interpretation, leaving the central claim vulnerable to circularity.
minor comments (1)
- Provide the exact stability metric, threshold for invariance, and any statistical test details (e.g., sample size, correction for multiple comparisons) used to obtain p < 0.001.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and robustness of our manuscript. We address each major comment below and have made corresponding revisions.
read point-by-point responses
-
Referee: [—] Abstract: the reported statistical result (p < 0.001) and functional test are presented without any description of network architecture, task definitions, the precise procedure used to extract the invariant subnetwork, or controls for total training time and network size. These omissions prevent evaluation of whether the stability difference is attributable to the continual-learning condition rather than confounding variables.
Authors: We agree that the abstract should have included summaries of these key elements to facilitate immediate evaluation. Although the full details are provided in the Methods section, we have revised the abstract to briefly describe the network architecture, task definitions, the procedure used to extract the invariant subnetwork, and the controls for total training time and network size. This revision ensures that readers can assess whether the stability difference is due to the continual-learning condition. revision: yes
-
Referee: [—] Methods (assumed section describing subnetwork isolation): the invariant subnetwork is isolated by the same invariance criterion that is then used to label it the 'self'. No independent behavioral, representational, or self-other distinction test is supplied to decouple the measurement from the interpretation, leaving the central claim vulnerable to circularity.
Authors: We acknowledge the potential for circularity in the interpretation. The subnetwork is identified via the invariance criterion, and we interpret it as the 'self' based on the persistence principle outlined in the introduction. However, the functional relevance is demonstrated through independent preservation and ablation experiments, which show performance impacts without relying on the 'self' label. We have added a dedicated subsection in the Discussion to explicitly address this concern, including suggestions for future independent tests such as representational analyses and behavioral self-distinction tasks. This provides a stronger separation between measurement and interpretation while preserving the core contribution. revision: partial
Circularity Check
Definition of 'self' as the invariant subnetwork renders the identification tautological
specific steps
-
self definitional
[Abstract]
"We propose that the 'self' can be isolated by seeking the invariant portion of cognitive process that changes relatively little compared to more rapidly acquired cognitive knowledge and skills, because our self is the most persistent aspect of our experiences. We used this principle to analyze the cognitive structure of robots under two conditions... We find that robots subjected to continual learning develop an invariant subnetwork that is significantly more stable (p < 0.001) compared to the control, and that this subnetwork is also functionally important"
The paper first defines 'self' as the invariant portion, then applies the invariance criterion to extract a subnetwork and declares it the emergent 'self'. The identification is therefore true by the definitional premise rather than by any separate validation that the subnetwork implements self-concept or self-other distinction.
full rationale
The paper's central interpretive step defines the 'self' explicitly as the most invariant portion of the cognitive process and then isolates the most stable subnetwork under continual learning to label it the emergent 'self'. This matches the self-definitional pattern: the label follows directly from the isolation criterion rather than from independent evidence of selfhood (e.g., self-other distinction or behavioral tests). The empirical measurements of stability (p<0.001) and functional ablation effects are direct and non-circular, but the load-bearing claim that this subnetwork constitutes a 'self' reduces to the premise used to select it. No mathematical derivation or fitted parameter is involved, keeping the overall circularity moderate.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The self is the most persistent aspect of experiences and can therefore be isolated as the invariant portion of cognitive processes
invented entities (1)
-
invariant subnetwork
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Locke,An Essay Concerning Human Understanding(Clarendon Press, Oxford) (1975)
J. Locke,An Essay Concerning Human Understanding(Clarendon Press, Oxford) (1975). 17
work page 1975
-
[2]
Ricoeur,Oneself as Another(University of Chicago Press, Chicago) (1992)
P . Ricoeur,Oneself as Another(University of Chicago Press, Chicago) (1992)
work page 1992
-
[3]
Parfit,Reasons and Persons(Oxford University Press, Oxford) (1984)
D. Parfit,Reasons and Persons(Oxford University Press, Oxford) (1984)
work page 1984
-
[4]
Merleau-Ponty,Phenomenology of Perception(Routledge, London) (2012)
M. Merleau-Ponty,Phenomenology of Perception(Routledge, London) (2012)
work page 2012
-
[5]
J. Bongard, V. Zykov, H. Lipson, Resilient machines through continuous self-modeling. Science314(5802), 1118–1121 (2006), doi:10.1126/science.1133687
-
[6]
B. Chen, R. Kwiatkowski, C. Vondrick, H. Lipson, Full-body visual self-modeling of robot morphologies.Science Robotics7(66), eabn8010 (2022), doi:10.1126/scirobotics. abn8010
-
[7]
F . Díaz Ledezma, S. Haddadin, Machine learning–driven self-discovery of the robot body morphology.Science Robotics8(74), eade2241 (2023), doi:10.1126/scirobotics.ade2241
- [8]
-
[9]
G. Pugach, A. Pitti, O. Tolochko, P . Gaussier, Brain-inspired coding of robot body schema through visuo-motor integration of touched events.Frontiers in Neurorobotics13, 37 (2019), doi:10.3389/fnbot.2019.00037
-
[10]
H. Lipson, J. B. Pollack, N. P . Suh, On the origin of modular variation.Evolution56(8), 1549–1556 (2002), doi:10.1111/j.0014-3820.2002.tb01466.x
-
[11]
J. Clune, J.-B. Mouret, H. Lipson, The evolutionary origins of modularity.Proceedings of the Royal Society B: Biological Sciences280(1755), 20122863 (2013), doi:10.1098/rspb. 2012.2863
-
[12]
R. Caruana, Multitask Learning.Machine Learning28, 41–75 (1997), doi:10.1023/A: 1007379606734. 18
work page doi:10.1023/a: 1997
-
[13]
Learning Shared Representations in Multi-task Reinforcement Learning
D. Borsa, T. Graepel, J. Shawe-Taylor, Learning Shared Representations in Multi-task Reinforcement Learning, arXiv (2016), doi:10.48550/arXiv.1603.02041,https://arxiv. org/abs/1603.02041
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1603.02041 2016
-
[14]
C. D’Eramo, D. Tateo, A. Bonarini, M. Restelli, J. Peters, Sharing Knowledge in Multi-Task Deep Reinforcement Learning, inInternational Conference on Learning Representations (ICLR)(2020),https://openreview.net/forum?id=rkgpv2VFvr
work page 2020
-
[15]
K. Khetarpal, M. Riemer, I. Rish, D. Precup, Towards Continual Reinforcement Learning: A Review and Perspectives.Journal of Artificial Intelligence Research75, 1401–1476 (2022), doi:10.1613/JAIR.1.13673
-
[16]
J. Kirkpatrick,et al., Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences114(13), 3521–3526 (2017), doi:10.1073/pnas. 1611835114,https://www.pnas.org/doi/10.1073/pnas.1611835114
-
[17]
A. A. Rusu,et al., Progressive Neural Networks, arXiv (2016), doi:10.48550/arXiv.1606. 04671,https://arxiv.org/abs/1606.04671
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606 2016
-
[18]
M. Wołczyk, M. Zaj ˛ ac, R. Pascanu, Ł. Kuci´nski, P . Miło´s, Continual World: A Robotic Benchmark For Continual Reinforcement Learning.arXiv preprint arXiv:2105.10919 (2021), doi:10.48550/arXiv.2105.10919
-
[19]
T. Yu,et al., Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforce- ment Learning, inProceedings of the 4th Conference on Robot Learning (CoRL)(2020)
work page 2020
-
[20]
V. A. C. Horta, I. Tiddi, S. Little, A. Mileo, Extracting knowledge from deep neural networks through graph analysis.Future Generation Computer Systems120, 109–118 (2021), doi:10.1016/j.future.2021.02.009,https://www.sciencedirect.com/science/ article/pii/S0167739X21000613. 19
-
[21]
A. M. Weil, V. A. C. Horta, H. Qadeer, A. Mileo, Adapting Graph-Based Analysis for Knowledge Extraction from Transformer Models, inProceedings of The 19th International Conference on Neurosymbolic Learning and Reasoning, vol. 284 ofProceedings of Ma- chine Learning Research(2025), pp. 1–14,https://proceedings.mlr.press/v284/ weil25a.html
work page 2025
-
[22]
E. Cuthill, J. McKee, Reducing the Bandwidth of Sparse Symmetric Matrices, inProceed- ings of the 1969 24th National Conference, ACM ’69 (Association for Computing Machin- ery, New Y ork, NY , USA) (1969), pp. 157–172, doi:10.1145/800195.805928
- [23]
-
[24]
E. Puiutta, E. M. S. P . Veith, Explainable Reinforcement Learning: A Survey, arXiv (2020), doi:10.48550/arXiv.2005.06247,https://arxiv.org/abs/2005.06247
-
[25]
S. Milani, N. Topin, M. Veloso, F . Fang, A Survey of Explainable Reinforcement Learning, arXiv (2022), doi:10.48550/arXiv.2202.08434,https://arxiv.org/abs/2202.08434
-
[26]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
F . Acero, Z. Li, Distilling Reinforcement Learning Policies for Interpretable Robot Locomo- tion: Gradient Boosting Machines and Symbolic Regression (2024), doi:10.48550/arXiv. 2403.14328,https://arxiv.org/abs/2403.14328
work page internal anchor Pith review doi:10.48550/arxiv 2024
- [27]
-
[28]
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
C. Fernando,et al., PathNet: Evolution Channels Gradient Descent in Super Neural Net- works, arXiv (2017), doi:10.48550/arXiv.1701.08734,https://arxiv.org/abs/1701. 08734. 20
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1701.08734 2017
-
[29]
H. Lipson, Principles of modularity, regularity, and hierarchy for scalable systems.Journal of Biological Physics and Chemistry7(4), 125–128 (2007), doi:10.4024/40701.jbpc.07.04
-
[30]
J. Y osinski, J. Clune, Y . Bengio, H. Lipson, How transferable are features in deep neu- ral networks?, inAdvances in Neural Information Processing Systems, vol. 27 (2014), pp. 3320–3328,https://proceedings.neurips.cc/paper_files/paper/2014/file/ 532a2f85b6977104bc93f8580abbb330-Paper.pdf
work page 2014
-
[31]
R. S. Sutton, D. Precup, S. Singh, Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence112(1–2), 181– 211 (1999), doi:10.1016/S0004-3702(99)00052-1,https://www.sciencedirect.com/ science/article/pii/S0004370299000521
-
[32]
P . M. Wyder,et al., Robot metabolism: Toward machines that can grow by consum- ing other machines.Science Advances11(29), eadu6897 (2025), doi:10.1126/sciadv. adu6897
-
[33]
Farama Foundation, Ant, Gymnasium Documentation (MuJoCo Environments) (2026), https://gymnasium.farama.org/environments/mujoco/ant/, accessed: 2026-02- 18
work page 2026
-
[34]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal,et al., Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning (2025), doi:10.48550/arXiv.2511.04831,https://arxiv.org/abs/2511. 04831
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.04831 2025
-
[35]
T. Haarnoja, A. Zhou, P . Abbeel, S. Levine, Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, inInternational Conference on Ma- chine Learning (ICML)(2018),https://proceedings.mlr.press/v80/haarnoja18b. html
work page 2018
-
[36]
Haarnoja,et al., Soft Actor-Critic Algorithms and Applications, arXiv (2018)
T. Haarnoja,et al., Soft Actor-Critic Algorithms and Applications, arXiv (2018). 21
work page 2018
-
[37]
M. Raghu, J. Gilmer, J. Y osinski, J. Sohl-Dickstein, SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability, inAdvances in Neu- ral Information Processing Systems (NeurIPS)(2017),https://proceedings.neurips. cc/paper/2017/hash/dc6a7e655d7e5840e66733e9ee67cc69-Abstract.html
work page 2017
-
[38]
S. Kornblith, M. Norouzi, H. Lee, G. Hinton, Similarity of Neural Network Representa- tions Revisited, inInternational Conference on Machine Learning (ICML)(2019),https: //proceedings.mlr.press/v97/kornblith19a.html
work page 2019
-
[39]
M. B. Eisen, P . T. Spellman, P . O. Brown, D. Botstein, Cluster analysis and display of genome-wide expression patterns.Proceedings of the National Academy of Sciences 95(25), 14863–14868 (1998), doi:10.1073/pnas.95.25.14863
-
[40]
R. Entezari, H. Sedghi, O. Saukh, B. Neyshabur, The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks, inInternational Conference on Learning Representations (ICLR)(2022),https://openreview.net/forum?id=dNigytemkL
work page 2022
-
[41]
S. K. Ainsworth, J. Hayase, S. Srinivasa, Git Re-Basin: Merging Models modulo Permuta- tion Symmetries, inInternational Conference on Learning Representations (ICLR)(2023), doi:10.48550/arXiv.2209.04836,https://openreview.net/forum?id=CQsmMYmlP5T
-
[42]
B. Simsek,et al., Geometry of the Loss Landscape in Overparameterized Neural Net- works: Symmetries and Invariances, inInternational Conference on Learning Represen- tations (ICML), vol. 139 ofProceedings of Machine Learning Research(2021), pp. 9722– 9732,https://proceedings.mlr.press/v139/simsek21a.html
work page 2021
-
[43]
H. W. Kuhn, The Hungarian Method for the Assignment Problem.Naval Research Logis- tics Quarterly2, 83–97 (1955), doi:10.1002/nav.3800020109
-
[44]
J. Munkres, Algorithms for the Assignment and Transportation Problems.Journal of the Society for Industrial and Applied Mathematics5(1), 32–38 (1957), doi:10.1137/0105003. 22
-
[45]
S. Kim, S. Lee, Continual Learning with Neuron Activation Importance, inImage Analysis and Processing – ICIAP 2022, S. Sclaroff, C. Distante, M. Leo, G. M. Farinella, F . Tombari, Eds. (Springer, Cham), vol. 13231 ofLecture Notes in Computer Science(2022), doi: 10.1007/978-3-031-06427-2_26
-
[46]
D. Bau,et al., Understanding the role of individual units in a deep neural network.Pro- ceedings of the National Academy of Sciences(2020), doi:10.1073/pnas.1907375117, https://www.pnas.org/doi/10.1073/pnas.1907375117
-
[47]
A. S. Morcos, D. G. T. Barrett, N. C. Rabinowitz, M. Botvinick, On the Importance of Single Directions for Generalization, inInternational Conference on Learning Representations (ICLR)(2018),https://openreview.net/forum?id=r1iuQjxCZ
work page 2018
-
[48]
Biometrics Bulletin , author =
F . Wilcoxon, Individual Comparisons by Ranking Methods.Biometrics Bulletin1(6), 80–83 (1945), doi:10.2307/3001968. 23 Code Availability All code is available athttps://github.com/adidevj7/EmergentRobotSelf. The repository includes the Isaac-based training pipeline, the full analysis toolkit used in this study, experi- ment configuration files, and valida...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.