LiME: Lightweight Mixture of Experts for Efficient Multimodal Multi-task Learning
Pith reviewed 2026-05-16 08:24 UTC · model grok-4.3
The pith
LiME achieves expert specialization by modulating a single shared PEFT module with lightweight expert vectors instead of replicating adapters per expert.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
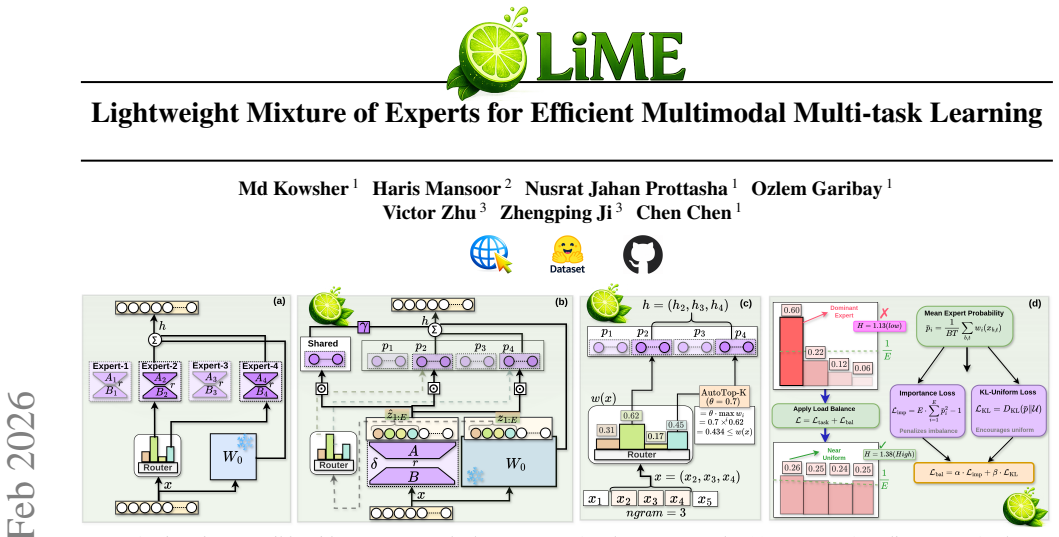
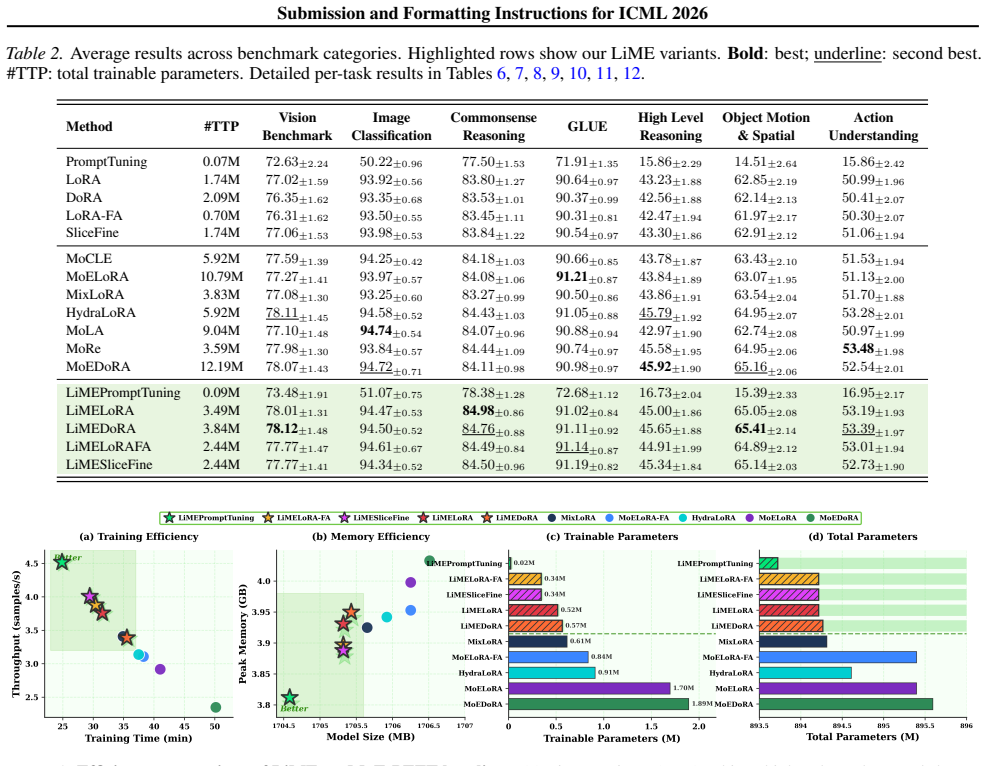
LiME achieves expert specialization in multimodal multi-task learning by using lightweight modulation of a single shared PEFT module via expert vectors rather than per-expert adapter replication. It employs zero-parameter routing that reuses existing frozen and adapted representations, together with n-gram windowed routing and adaptive Auto Top-K expert selection. The method proves that increasing the number of experts preserves more task-relevant information and that modulation approximates full expert-specific PEFT with bounded error. On the MMT-47 benchmark spanning text, image, and video tasks, LiME matches or exceeds MoE-PEFT baselines while requiring up to 4x fewer trainable parameters
What carries the argument
Lightweight modulation of a shared PEFT module by expert vectors, paired with zero-parameter routing derived from existing representations.
Load-bearing premise
Modulating the output of one shared PEFT module with small expert vectors approximates the effect of separate full PEFT modules per expert within a bounded error.
What would settle it
A task distribution or PEFT method where the accuracy gap between LiME and standard per-expert MoE-PEFT exceeds the claimed bound or produces large degradation would falsify the approximation.
Figures

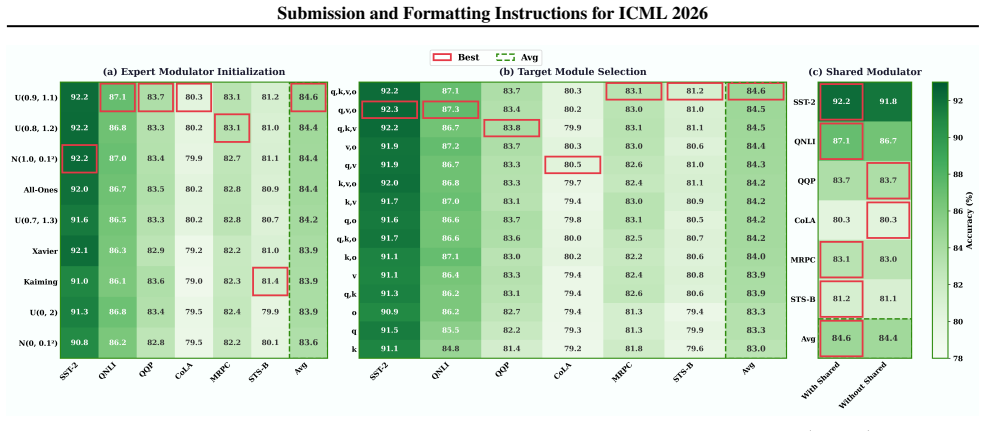
read the original abstract
MoE-PEFT methods combine Mixture of Experts with parameter-efficient fine-tuning for multi-task adaptation, but require separate adapters per expert causing trainable parameters to scale linearly with expert count and limiting applicability to adapter-based architectures. We propose LiME (Lightweight Mixture of Experts), which achieves expert specialization through lightweight modulation rather than adapter replication. Instead of separate adapters, LiME uses a single shared PEFT module and modulates its output with lightweight expert vectors, reducing expert parameters while generalizing to any PEFT method. Notably, LiME introduces zero-parameter routing by leveraging existing frozen and adapted representations eliminating learned router parameters typically required per layer. Theoretically, we prove that (i) more experts preserve more task-relevant information and (ii) modulation approximates full expert-specific PEFT with bounded error. LiME further incorporates n-gram windowed routing and adaptive expert selection (Auto Top-K) based on routing confidence. Experiments on MMT-47, a multimodal multi-task benchmark with 47 tasks spanning text, image, and video, demonstrate that LiME achieves competitive or superior performance while using up to 4x fewer trainable parameters and up to 29% faster training compared to corresponding MoE-PEFT baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LiME, a lightweight Mixture of Experts method for multimodal multi-task learning. It replaces per-expert PEFT adapters with a single shared PEFT module whose outputs are modulated by lightweight expert-specific vectors, introduces zero-parameter routing that reuses frozen and adapted representations, and adds n-gram windowed routing plus Auto Top-K expert selection. Theoretical results claim that increasing the number of experts preserves more task-relevant information and that the modulation step approximates full expert-specific PEFT with bounded error. On the new MMT-47 benchmark (47 tasks across text, image, and video), LiME is reported to match or exceed MoE-PEFT baselines while using up to 4× fewer trainable parameters and up to 29% faster training.
Significance. If the bounded-error claim for shared-PEFT modulation holds with a tight, quantifiable bound across PEFT ranks and task distributions, the approach would meaningfully reduce the parameter scaling barrier in MoE-PEFT and generalize to arbitrary adapter families. The zero-parameter routing and the introduction of the MMT-47 benchmark are additional contributions that could influence efficient multi-task adaptation research.
major comments (2)
- [§3.2] §3.2 (Modulation Approximation Theorem): the central claim that modulating a shared PEFT module approximates full expert-specific adapters with bounded error is load-bearing for the 4× parameter reduction result, yet the paper provides neither the explicit dependence of the bound on PEFT rank, modality, or task distribution nor any numerical evaluation of the approximation error on MMT-47 tasks.
- [§4.2–4.3] §4.2–4.3 (Experimental Setup and Results): the reported gains (up to 4× fewer parameters, 29% faster training) rest on single-run point estimates without error bars, multiple random seeds, or statistical significance tests; this weakens the claim that LiME is competitive or superior across the 47 tasks.
minor comments (3)
- [Abstract] Abstract and §1: the phrase “theoretical proofs” appears without section or theorem numbers; add explicit cross-references to the statements in §3.
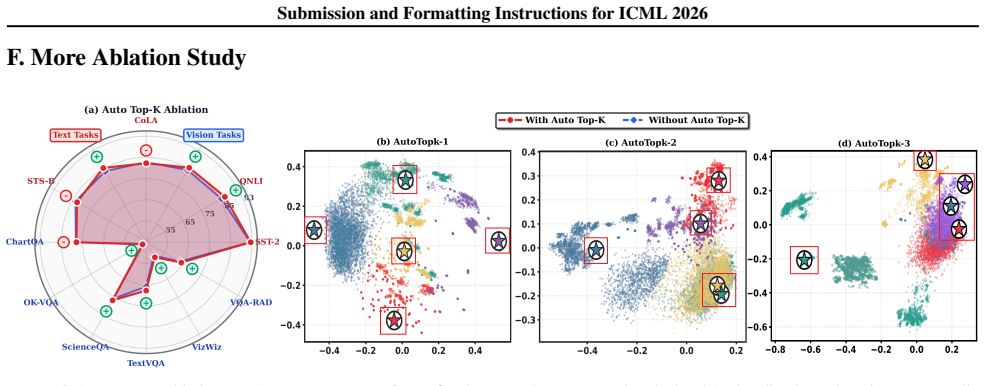
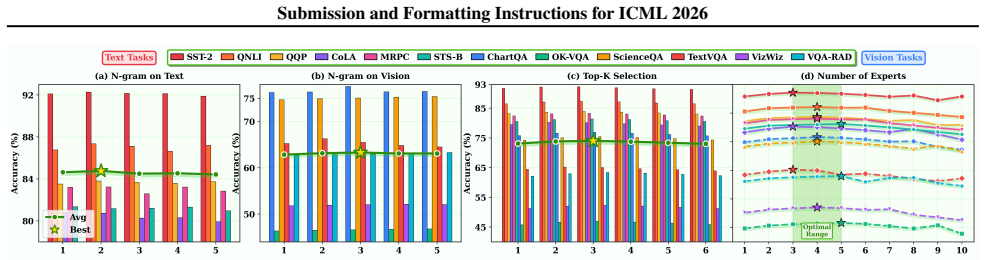
- [§2.3] §2.3 (Routing): the n-gram window size and Auto Top-K threshold are introduced without an equation or pseudocode showing how routing scores are computed from the frozen representations.
- [Table 2] Table 2: column headers for parameter counts should explicitly distinguish frozen vs. trainable parameters to avoid ambiguity when comparing to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will make the indicated revisions to improve the clarity and robustness of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Modulation Approximation Theorem): the central claim that modulating a shared PEFT module approximates full expert-specific adapters with bounded error is load-bearing for the 4× parameter reduction result, yet the paper provides neither the explicit dependence of the bound on PEFT rank, modality, or task distribution nor any numerical evaluation of the approximation error on MMT-47 tasks.
Authors: The Modulation Approximation Theorem provides a general bound expressed in terms of the modulation vector norms and the operator norm of the shared PEFT module, which holds uniformly across modalities and task distributions. To make the dependence explicit, we will add a corollary in the revised §3.2 that isolates the scaling with PEFT rank r (error bounded by O(1/√r) under standard assumptions on the adapter weights). We will also add a new subsection in §4.3 with numerical approximation-error measurements (L2 output difference between modulated shared PEFT and per-expert PEFT) averaged over representative MMT-47 tasks for each modality and for ranks 8, 16, and 32. These additions will be included in the revision. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (Experimental Setup and Results): the reported gains (up to 4× fewer parameters, 29% faster training) rest on single-run point estimates without error bars, multiple random seeds, or statistical significance tests; this weakens the claim that LiME is competitive or superior across the 47 tasks.
Authors: We agree that single-run point estimates limit the strength of the empirical claims. In the revised manuscript we will rerun the primary MMT-47 experiments using at least three independent random seeds, report mean performance together with standard deviations, add error bars to all tables and figures, and include paired statistical significance tests (e.g., Wilcoxon signed-rank) against the strongest baselines. These changes will appear in the updated §4.2–4.3 and associated tables. revision: yes
Circularity Check
No significant circularity detected; claims rest on independent proof and experiments
full rationale
The paper asserts a new theoretical proof that modulation of a shared PEFT module approximates expert-specific adapters with bounded error and that more experts preserve more task information; these are presented as derived results rather than redefinitions of inputs. Zero-parameter routing is described as leveraging existing frozen representations without learned routers, and performance gains are tied to direct experiments on the MMT-47 benchmark rather than any fitted parameter renamed as a prediction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no equations reduce by construction to the claimed outputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Modulation of a shared PEFT output approximates expert-specific PEFT with bounded error
- domain assumption Existing frozen and adapted representations contain sufficient information for effective routing
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2: LiME Approximates Expert-Specific PEFT ... modulation approximates full expert-specific PEFT with bounded error
-
IndisputableMonolith/Foundation/ArithmeticFromLogicLogicNat_induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1: Adding Experts Is Information-Preserving ... I(Y;Z_n) ≥ I(Y;Z_{n-1})
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
, n}there existsR e ∈R d×d such that for allx∈Supp(X|I n =e), A(n−1) rn−1(x)x=R e A(n) e x
(Factorization-on-support) For eache∈ {1, . . . , n}there existsR e ∈R d×d such that for allx∈Supp(X|I n =e), A(n−1) rn−1(x)x=R e A(n) e x
-
[2]
at least half as good as the best
(Identifiability) There exists measurableˆe:R d → {1, . . . , n}such that In = ˆe(Zn)a.s. Then I(Y;Z n)≥I(Y;Z n−1). Proof.Defineh:R d →R d by h(z) :=R ˆe(z)z. Sinceˆeis measurable and eachz7→R ezis continuous,his measurable. Let N:={ω∈Ω :I n(ω)̸= ˆe(Zn(ω))}. By identifiability,P(N) = 0. For eache∈ {1, . . . , n}letS e :=Supp(X|I n =e). Then P(X∈S e |I n =...
work page 2026
-
[3]
As a result, each output dimension is influenced by many (often all) input dimensions
Any small slice of a transformer representation still carries global information.In transformers, each layer mixes information across dimensions through attention projections and feed-forward networks (Vaswani et al., 2017). As a result, each output dimension is influenced by many (often all) input dimensions. This means that even if we take only E dimens...
work page 2017
-
[4]
Pretrained features are redundant, so reserving a small slice for routing is low-risk.Pretrained representations often contain substantial redundancy. For example, Luo et al. (2023) show that using only ∼1% of the most important feature dimensions can recover performance close to using the full representation. This supports our design in two ways. First, ...
work page 2023
-
[5]
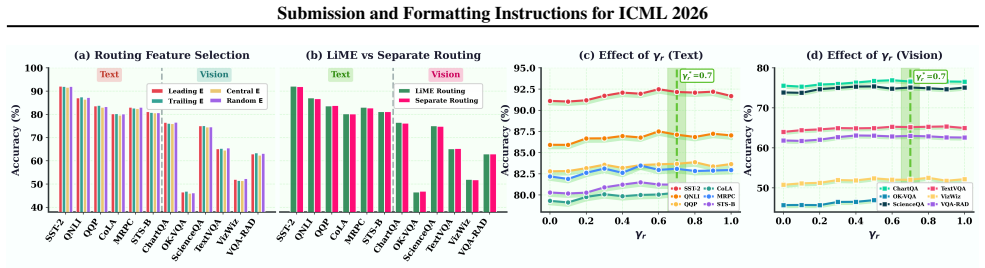
Sharing features for routing can encourage meaningful grouping.Using existing representations for routing can also act as a useful inductive bias. If routing depends on the same representations used for adaptation, the model is encouraged to organize its feature space so that inputs with similar semantics (and similar required adaptations) are routed to s...
work page 2026
-
[6]
MoELoRA degrades significantly.In contrast, MoELoRA (red) exhibits sharp degradation beyond E= 3 –4
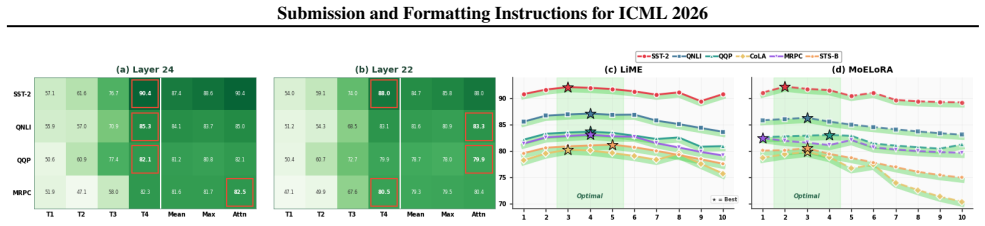
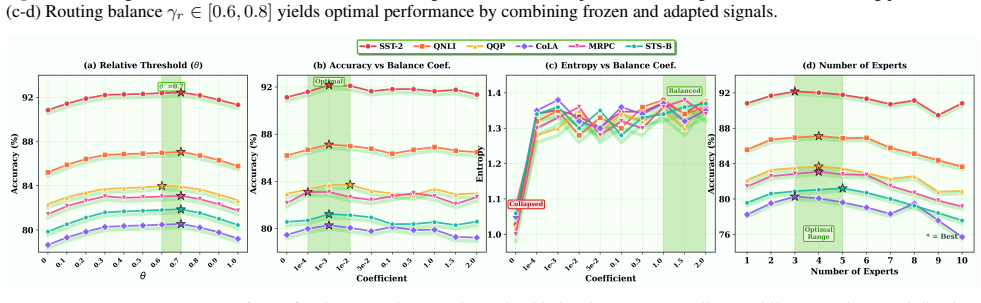
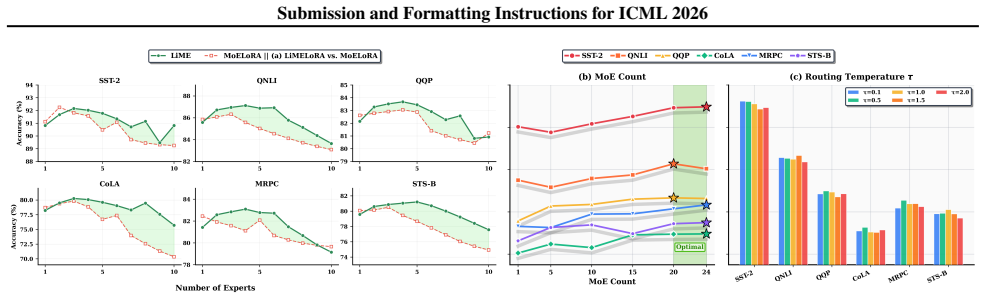
Performance typically peaks aroundE= 3–5and remains within a narrow range thereafter. MoELoRA degrades significantly.In contrast, MoELoRA (red) exhibits sharp degradation beyond E= 3 –4. The drops are particularly severe on CoLA (∼78% to ∼70%), STS-B (∼80% to ∼74%), and MRPC (∼83% to ∼73%)—losses of 8–10 percentage points. This divergence stems from overf...
work page 2026
-
[7]
Base Forward z←W 0x//z∈R B×T×d o, frozen computation
-
[8]
PEFT Adaptation ˆz←ˆz(x)//ˆz∈R B×T×d o, any PEFT method
-
[9]
Zero-Param Routing // no learned router! ˜z1:E ←z [:,:,1:E] /∥z [:,:,1:E]∥∞ // normalize firstEdims ˜ˆz1:E ←ˆz[:,:,1:E] /∥ˆz[:,:,1:E]∥∞ w←softmax (1−γr)·˜z1:E+γr·˜ˆz1:E τ // routing weights
-
[10]
Auto Top-K Selection Sθ ← {i:w i ≥θ·max j wj}// adaptive selection ˜wi ←w i /P j∈Sθ wj // renormalize
-
[11]
Expert Modulation P ← P i∈Sθ ˜wi ·p i // weighted expert combination
-
[12]
Output h←z+ ˆz⊙ P+γ·(ˆz⊙p s)// base + routed + shared
-
[13]
Load Balance // training only ¯pi ← 1 BT P b,twi(xb,t)// mean routing prob per expert Limp ←E· PE i=1¯p2 i −1// importance loss LKL ←PE i=1¯pi log(E·¯pi)// KL-uniform loss L ← L task +α· L imp +β· L KL // total loss Return:h,L(loss only during training) LiME forward pass and training.Colors indicate: frozen , trainable , routing (0 params) , training only...
-
[14]
41 Submission and Formatting Instructions for ICML 2026 I
prevents expert collapse. 41 Submission and Formatting Instructions for ICML 2026 I. Extended Related Work Parameter-Efficient Fine-Tuning.PEFT methods adapt large pre-trained models by updating only a small subset of parameters. LoRA (Hu et al., 2022) introduces low-rank decomposition for weight updates, while adapters insert lightweight modules between ...
work page 2026
-
[15]
PESC (Wu et al., 2024a) enables sparse model transitions in instruction tuning
decouples training for continual learning. PESC (Wu et al., 2024a) enables sparse model transitions in instruction tuning. Limitations of Existing MoE-PEFT.Existing methods share three limitations: (i)parameter explosion, with expert parameters scaling linearly with expert count (E× |ϕ| ); (ii)router overheadfrom learned routers adding parameters and auxi...
work page 2026
-
[16]
Multimodal Generalization: By training on text, video, and image data jointly, we test whether experts specialize by modality without explicit supervision
-
[17]
Multi-task Transfer: Within each modality, we include diverse tasks (e.g., sentiment vs. inference for text, VQA vs. classification for images) to test task-level routing
-
[18]
The model must learn to route based on input characteristics alone
No Task Identifiers: Unlike prior multi-task learning setups, we do not provide explicit task or modality labels during training or inference. The model must learn to route based on input characteristics alone
-
[19]
All datasets are formatted as text generation tasks with consistent prompt templates
Scale and Diversity: With 47 test sets across 5 categories, MMT-47 ensures comprehensive evaluation that goes beyond single-domain benchmarks. All datasets are formatted as text generation tasks with consistent prompt templates. For classification tasks, we format the output as the class label in text form. For regression tasks (STS-B), we discretize scor...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.