Recognition: 2 theorem links
· Lean TheoremImproving MPI Error Detection and Repair with Large Language Models and Bug References
Pith reviewed 2026-05-13 21:28 UTC · model grok-4.3
The pith
Integrating bug references into large language models raises MPI error detection accuracy from 44% to 77%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
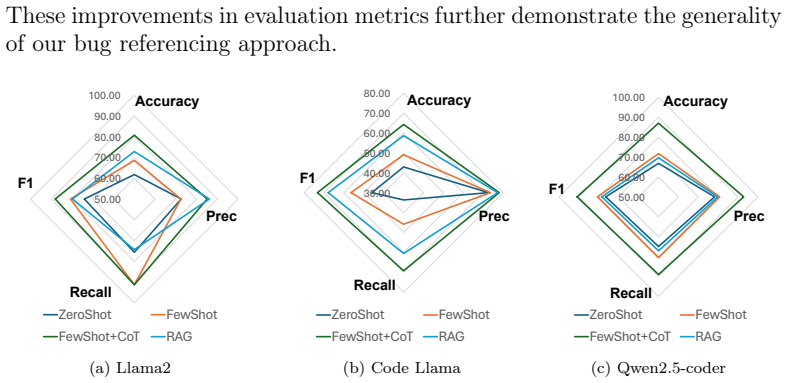
The central claim is that a bug detection and repair technique using few-shot learning, chain-of-thought reasoning, and retrieval augmented generation with bug references significantly improves large language models' performance on MPI errors, achieving 77% accuracy compared to 44% for direct use, and generalizes to other models.
What carries the argument
The bug referencing technique that supplies the model with examples of correct and incorrect MPI usage to guide detection and repair.
If this is right
- Error detection in MPI programs becomes substantially more accurate with these enhancements.
- The method can be applied to repair errors as well as detect them.
- It generalizes to other large language models beyond the primary one tested.
- Automated tools for maintaining high-performance computing code improve markedly.
Where Pith is reading between the lines
- Developers of distributed systems could adopt similar reference techniques for other communication libraries.
- This points to the value of curated bug databases for domain-specific LLM applications.
- Future work might test the approach on real-world MPI codebases from scientific simulations.
Load-bearing premise
The chosen MPI bug examples and test cases represent the full range of real-world errors that occur in practice.
What would settle it
A follow-up test on an independent collection of MPI programs showing error detection accuracy remaining near 44 percent would falsify the claimed improvement.
Figures







read the original abstract
Message Passing Interface (MPI) is a foundational technology in high-performance computing (HPC), widely used for large-scale simulations and distributed training (e.g., in machine learning frameworks such as PyTorch and TensorFlow). However, maintaining MPI programs remains challenging due to their complex interplay among processes and the intricacies of message passing and synchronization. With the advancement of large language models like ChatGPT, it is tempting to adopt such technology for automated error detection and repair. Yet, our studies reveal that directly applying large language models (LLMs) yields suboptimal results, largely because these models lack essential knowledge about correct and incorrect usage, particularly the bugs found in MPI programs. In this paper, we design a bug detection and repair technique alongside Few-Shot Learning (FSL), Chain-of-Thought (CoT) reasoning, and Retrieval Augmented Generation (RAG) techniques in LLMs to enhance the large language model's ability to detect and repair errors. Surprisingly, such enhancements lead to a significant improvement, from 44% to 77%, in error detection accuracy compared to baseline methods that use ChatGPT directly. Additionally, our experiments demonstrate our bug referencing technique generalizes well to other large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that directly applying LLMs like ChatGPT to MPI error detection and repair yields suboptimal results due to insufficient domain knowledge of correct/incorrect MPI usage. It proposes combining Few-Shot Learning (FSL), Chain-of-Thought (CoT) reasoning, and Retrieval Augmented Generation (RAG) with bug references to address this, reporting an accuracy increase from 44% to 77% over the direct ChatGPT baseline, with the approach generalizing to other LLMs.
Significance. If the empirical gains hold under rigorous controls, the work would be significant for HPC software reliability, as MPI programs underpin large-scale simulations and distributed ML training. The bug-referencing RAG technique offers a practical way to inject domain-specific knowledge into LLMs without retraining, potentially reducing the maintenance burden for complex message-passing code.
major comments (2)
- [Evaluation] Evaluation section: The headline result (44% to 77% detection accuracy) is presented without any information on dataset size, sourcing of the MPI bug examples (e.g., real GitHub issues vs. synthetic), diversity of error types (deadlock, race condition, type mismatch, etc.), baseline implementation details, or statistical tests/cross-validation. This information is load-bearing for attributing the gain to FSL+CoT+RAG rather than selection effects.
- [Experiments] Generalization experiments: The claim that the bug-referencing technique generalizes well to other LLMs lacks concrete details on which models were tested, the exact accuracy numbers obtained, or the evaluation protocol used to measure generalization. Without these, the broader applicability assertion cannot be assessed.
minor comments (1)
- [Abstract] Abstract: The abstract would be strengthened by briefly stating dataset size and error-type coverage to allow readers to gauge the scope of the 44%–77% claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and valuable feedback on our manuscript. We agree that additional details on the evaluation dataset and generalization experiments are necessary to strengthen the paper. We have revised the manuscript to address both major comments, as detailed in the point-by-point responses below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline result (44% to 77% detection accuracy) is presented without any information on dataset size, sourcing of the MPI bug examples (e.g., real GitHub issues vs. synthetic), diversity of error types (deadlock, race condition, type mismatch, etc.), baseline implementation details, or statistical tests/cross-validation. This information is load-bearing for attributing the gain to FSL+CoT+RAG rather than selection effects.
Authors: We agree that these details are essential for reproducibility and to substantiate the claims. The original manuscript omitted some of this information for brevity. In the revised version, we have expanded Section 4 to specify: the dataset contains 200 MPI error examples (120 drawn from real GitHub issues and 80 synthetic cases constructed from MPI standard documentation and common error patterns); error types covered are deadlocks (35%), race conditions (25%), type mismatches (20%), and buffer/communication errors (20%); the baseline uses zero-shot prompting of GPT-3.5-turbo with the identical task prompt and input format; we performed 5-fold cross-validation and report McNemar's test results confirming statistical significance (p < 0.001). These additions confirm the gains are attributable to the proposed FSL+CoT+RAG techniques. revision: yes
-
Referee: [Experiments] Generalization experiments: The claim that the bug-referencing technique generalizes well to other LLMs lacks concrete details on which models were tested, the exact accuracy numbers obtained, or the evaluation protocol used to measure generalization. Without these, the broader applicability assertion cannot be assessed.
Authors: We acknowledge the need for concrete details. In the revised manuscript, we have added a new subsection in the Experiments section reporting results on GPT-4, Claude 2, and Llama-2 (70B). Using the identical bug-reference RAG database and the same 200-example test set with 5-fold cross-validation, the accuracies improved from 48% to 81% (GPT-4), 41% to 74% (Claude 2), and 39% to 69% (Llama-2). This demonstrates consistent gains across models under the same evaluation protocol. revision: yes
Circularity Check
No circularity: empirical accuracy gains rest on held-out test comparisons, not self-referential definitions or fitted inputs
full rationale
The paper reports an experimental comparison of LLM error detection accuracy (44% baseline vs. 77% with FSL+CoT+RAG+bug references) on MPI programs. No derivation chain exists; the central claim is a measured delta between two prompting configurations evaluated on the same test cases. No equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear. The result is falsifiable by re-running the experiments on independent MPI bug corpora and does not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Providing curated bug references and standard prompting techniques will reliably improve LLM performance on domain-specific code error detection without introducing new failure modes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
such enhancements lead to a significant improvement, from 44% to 77%, in error detection accuracy compared to baseline methods that use ChatGPT directly
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Few-Shot Learning (FSL), Chain-of-Thought (CoT) reasoning, and Retrieval Augmented Generation (RAG)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Laurent, E. Saillard, M. Quinson, The mpi bugs initiative: a frame- work for mpi verification tools evaluation, in: 2021 IEEE/ACM 5th International Workshop on Software Correctness for HPC Applications, 2021, pp. 1–9.doi:10.1109/Correctness54621.2021.00008
-
[2]
A. Droste, M. Kuhn, T. Ludwig, Mpi-checker: static analysis for mpi, in: Proceedings of the Second Workshop on the LLVM Compiler In- frastructure in HPC, LLVM ’15, Association for Computing Machinery, New York, NY, USA, 2015.doi:10.1145/2833157.2833159. URLhttps://doi.org/10.1145/2833157.2833159
-
[3]
H. Ma, L. Wang, K. Krishnamoorthy, Detecting thread-safety violations in hybrid openmp/mpi programs, in: 2015 IEEE International Confer- ence on Cluster Computing, IEEE, 2015, pp. 460–463
work page 2015
-
[4]
S. S. Vakkalanka, S. Sharma, G. Gopalakrishnan, R. M. Kirby, Isp: a tool for model checking mpi programs, in: Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Program- ming, PPoPP ’08, Association for Computing Machinery, New York, NY, USA, 2008, p. 285–286.doi:10.1145/1345206.1345258. URLhttps://doi.org/10.1145/1345206...
-
[5]
T. Hilbrich, J. Protze, M. Schulz, B. R. de Supinski, M. S. Muller, Mpi runtime error detection with must: Advances in deadlock detection, in: SC ’12: Proceedings of the International Conference on High Perfor- mance Computing, Networking, Storage and Analysis, 2012, pp. 1–10. doi:10.1109/SC.2012.79
-
[6]
H. Li, S. Li, Z. Benavides, Z. Chen, R. Gupta, Compi: Concolic test- ing for mpi applications, in: 2018 IEEE International Parallel and Dis- tributed Processing Symposium (IPDPS), 2018, pp. 865–874.doi: 10.1109/IPDPS.2018.00096
-
[7]
1364–1375.doi:10.1109/IPDPS.2012.123
T.Hilbrich, M.S.Müller, B.R.deSupinski, M.Schulz, W.E.Nagel, Gti: A generic tools infrastructure for event-based tools in parallel systems, in: 2012 IEEE 26th International Parallel and Distributed Processing Symposium, 2012, pp. 1364–1375.doi:10.1109/IPDPS.2012.123
-
[8]
H. Li, Z. Chen, R. Gupta, Efficient concolic testing of mpi applications, in: Proceedings of the 28th International Conference on Compiler Con- struction, CC 2019, Association for Computing Machinery, New York, NY, USA, 2019, p. 193–204.doi:10.1145/3302516.3307353. URLhttps://doi.org/10.1145/3302516.3307353
-
[9]
S. F. Siegel, T. K. Zirkel, Automatic formal verification of mpi-based parallel programs, SIGPLAN Not. 46 (8) (2011) 309–310.doi:10.1145/ 2038037.1941603. URLhttps://doi.org/10.1145/2038037.1941603
-
[10]
Z. Chen, H. Yu, X. Fu, J. Wang, Mpi-sv: A symbolic verifier for mpi programs, in: 2020 IEEE/ACM 42nd International Conference on Soft- ware Engineering: Companion Proceedings (ICSE-Companion), 2020, pp. 93–96
work page 2020
-
[11]
N. Hu, Z. Bian, Z. Shuai, Z. Chen, Y. Zhang, Symbolic execution of mpi programs with one-sided communications, in: 2023 30th Asia-Pacific Software Engineering Conference (APSEC), 2023, pp. 657–658.doi: 10.1109/APSEC60848.2023.00096
-
[12]
G. Cooperman, D. Li, Z. Zhao, Debugging mpi implementations via reduction-to-primitives, in: 2022 IEEE/ACM Third International Sym- posium on Checkpointing for Supercomputing (SuperCheck), 2022, pp. 1–9.doi:10.1109/SuperCheck56652.2022.00007. 28
-
[13]
Y. Qin, S. Wang, Y. Lou, J. Dong, K. Wang, X. Li, X. Mao, Soapfl: A standard operating procedure for llm-based method-level fault local- ization, IEEE Transactions on Software Engineering (2025) 1–15doi: 10.1109/TSE.2025.3543187
- [14]
-
[15]
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, J. M. Zhang, Large language models for software engineering: Survey and open problems, in: 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), 2023, pp. 31–53.doi:10.1109/ICSE-FoSE59343.2023.00008
-
[16]
D.Zou, J.Liang, Y.Xiong, M.D.Ernst, L.Zhang, Anempiricalstudyof fault localization families and their combinations, IEEE Transactions on Software Engineering 47 (2) (2021) 332–347.doi:10.1109/TSE.2019. 2892102
-
[17]
H. Li, Y. Hao, Y. Zhai, Z. Qian, Enhancing static analysis for practical bug detection: An llm-integrated approach, Proc. ACM Program. Lang. 8 (OOPSLA1) (Apr. 2024).doi:10.1145/3649828. URLhttps://doi.org/10.1145/3649828
-
[18]
H. Li, Y. Hao, Y. Zhai, Z. Qian, Assisting static analysis with large lan- guage models: A chatgpt experiment, in: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, Association for Computing Machinery, New York, NY, USA, 2023, p. 2107–2111. doi:10.1145/361164...
-
[19]
Y. Wu, X. Xie, C. Peng, D. Liu, H. Wu, M. Fan, T. Liu, H. Wang, Advscanner: Generating adversarial smart contracts to exploit reen- trancy vulnerabilities using llm and static analysis, in: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, Association for Computing Machinery, New York, 29 NY, USA, 2024, ...
-
[20]
P. Nie, R. Banerjee, J. J. Li, R. J. Mooney, M. Gligoric, Learning deep semantics for test completion, in: Proceedings of the 45th International Conference on Software Engineering, ICSE ’23, IEEE Press, 2023, p. 2111–2123.doi:10.1109/ICSE48619.2023.00178. URLhttps://doi.org/10.1109/ICSE48619.2023.00178
-
[21]
N. Rao, K. Jain, U. Alon, C. L. Goues, V. J. Hellendoorn, Cat- lm training language models on aligned code and tests, in: Proceed- ings of the 38th IEEE/ACM International Conference on Automated Software Engineering, ASE ’23, IEEE Press, 2024, p. 409–420.doi: 10.1109/ASE56229.2023.00193. URLhttps://doi.org/10.1109/ASE56229.2023.00193
- [22]
-
[23]
M. Lajko, V. Csuvik, T. Gyimothy, L. Vidacs, Automated program repair with the gpt family, including gpt-2, gpt-3 and codex, in: Pro- ceedings of the 5th ACM/IEEE International Workshop on Automated Program Repair, APR ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 34–41.doi:10.1145/3643788.3648021. URLhttps://doi.org/10.1145/364378...
-
[24]
Z. Chen, S. Kommrusch, M. Tufano, L.-N. Pouchet, D. Poshyvanyk, M. Monperrus, Sequencer: Sequence-to-sequence learning for end-to- end program repair, IEEE Transactions on Software Engineering 47 (9) (2021) 1943–1959.doi:10.1109/TSE.2019.2940179
-
[25]
J. Zhao, D. Yang, L. Zhang, X. Lian, Z. Yang, F. Liu, Enhancing au- tomated program repair with solution design, in: Proceedings of the 39th IEEE/ACM International Conference on Automated Software En- gineering, ASE ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 1706–1718.doi:10.1145/3691620.3695537. URLhttps://doi.org/10.1145/36916...
-
[26]
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, M. Zhou, Codebert: A pre-trained model for program- ming and natural languages (2020).arXiv:2002.08155. URLhttps://arxiv.org/abs/2002.08155
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[27]
Q. Guo, J. Cao, X. Xie, S. Liu, X. Li, B. Chen, X. Peng, Exploring the potential of chatgpt in automated code refinement: An empirical study, in: 2024 IEEE/ACM 46th International Conference on Software Engi- neering (ICSE), 2024, pp. 390–402.doi:10.1145/3597503.3623306
-
[28]
E. Mashhadi, H. Hemmati, Applying codebert for automated program repair of java simple bugs, in: 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR), 2021, pp. 505–509. doi:10.1109/MSR52588.2021.00063
-
[29]
Z. Xiong, W. Dong, Vuld-codebert: Codebert-based vulnerability de- tection model for c/c++ code, in: 2024 6th International Confer- ence on Communications, Information System and Computer Engi- neering (CISCE), 2024, pp. 914–919.doi:10.1109/CISCE62493.2024. 10653337
- [30]
- [31]
-
[32]
R. Baldoni, E. Coppa, D. C. D’elia, C. Demetrescu, I. Finocchi, A survey of symbolic execution techniques, ACM Comput. Surv. 51 (3) (May 2018).doi:10.1145/3182657. URLhttps://doi.org/10.1145/3182657
- [33]
-
[34]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al., Chain-of-thought prompting elicits reasoning in large 31 language models, Advances in neural information processing systems 35 (2022) 24824–24837
work page 2022
-
[35]
Z. Luo, M. Zheng, S. F. Siegel, Verification of mpi programs using civl, in: Proceedings of the 24th European MPI Users’ Group Meeting, Eu- roMPI ’17, Association for Computing Machinery, New York, NY, USA, 2017.doi:10.1145/3127024.3127032. URLhttps://doi.org/10.1145/3127024.3127032
-
[36]
V. M. Nguyen, E. Saillard, J. Jaeger, D. Barthou, P. Carribault, Par- coach extension for static mpi nonblocking and persistent communica- tion validation, in: 2020 IEEE/ACM 4th International Workshop on Software Correctness for HPC Applications, 2020, pp. 31–39.doi: 10.1109/Correctness51934.2020.00009
-
[37]
H. Zamani, F. Diaz, M. Dehghani, D. Metzler, M. Bendersky, Retrieval- enhanced machine learning, in: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’22, Association for Computing Machinery, New York, NY, USA, 2022, p. 2875–2886.doi:10.1145/3477495.3531722. URLhttps://doi.org/10.1145/3...
-
[38]
A. Salemi, H. Zamani, Evaluating retrieval quality in retrieval- augmented generation, in: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Re- trieval, SIGIR ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 2395–2400.doi:10.1145/3626772.3657957. URLhttps://doi.org/10.1145/3626772.3657957
-
[39]
S. Jacobs, S. Jaschke, Leveraging lecture content for improved feed- back: Explorations with gpt-4 and retrieval augmented generation, in: 2024 36th International Conference on Software Engineering Ed- ucation and Training (CSEE&amp;T), IEEE, 2024, p. 1–5.doi: 10.1109/cseet62301.2024.10663001. URLhttp://dx.doi.org/10.1109/CSEET62301.2024.10663001
-
[40]
S. Barnett, S. Kurniawan, S. Thudumu, Z. Brannelly, M. Abdelrazek, Seven failure points when engineering a retrieval augmented generation system (2024).arXiv:2401.05856. URLhttps://arxiv.org/abs/2401.05856 32
-
[41]
Z. Sheng, Z. Chen, S. Gu, H. Huang, G. Gu, J. Huang, Llms in software security: A survey of vulnerability detection techniques and insights, ACM Comput. Surv. 58 (5) (Nov. 2025).doi:10.1145/3769082. URLhttps://doi.org/10.1145/3769082
-
[42]
Code Llama: Open Foundation Models for Code
B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, R. Sauvestre, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. Défossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, G. Synnaeve, Code llama: Open foundation models for code (2024). arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, K. Dang, Y. Fan, Y. Zhang, A. Yang, R. Men, F. Huang, B. Zheng, Y. Miao, S. Quan, Y. Feng, X. Ren, X. Ren, J. Zhou, J. Lin, Qwen2.5-coder technical report (2024).arXiv:2409.12186. URLhttps://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hos- seini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korene...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.