Recognition: no theorem link
DocShield: Towards AI Document Safety via Evidence-Grounded Agentic Reasoning
Pith reviewed 2026-05-13 21:00 UTC · model grok-4.3
The pith
DocShield detects text-centric document forgeries by treating the task as visual-logical co-reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
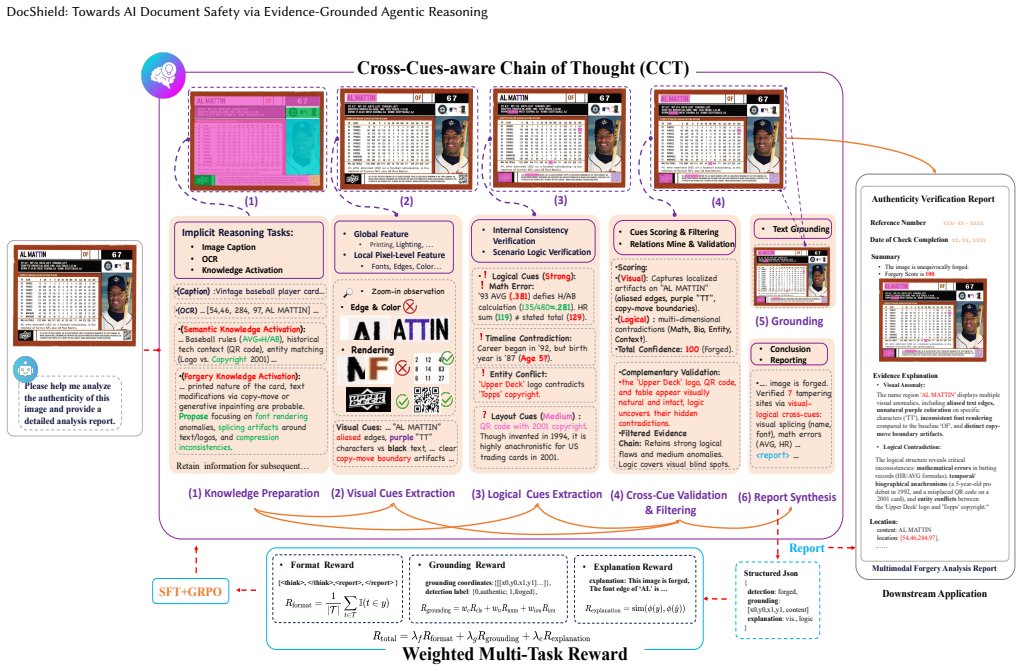
DocShield formulates text-centric forgery analysis as a visual-logical co-reasoning problem and solves it with a Cross-Cues-aware Chain of Thought mechanism that cross-validates visual anomalies against textual semantics. A Weighted Multi-Task Reward aligns the reasoning structure, spatial evidence, and authenticity prediction during GRPO optimization. The accompanying RealText-V1 dataset supplies multilingual document-like images with pixel-level manipulation masks and expert textual explanations.
What carries the argument
Cross-Cues-aware Chain of Thought (CCT) mechanism that iteratively cross-validates visual anomalies with textual semantics.
If this is right
- Detection, localization, and explanation become a single consistent process instead of separate tasks.
- The same CCT structure can be applied to other text-rich image domains beyond documents.
- The Weighted Multi-Task Reward provides a concrete way to train agentic reasoning models on forensic tasks.
- Public release of RealText-V1 enables standardized benchmarking of future document-safety methods.
Where Pith is reading between the lines
- The approach could be extended to video documents or live camera feeds if the CCT loop is made causal.
- If the cross-validation step proves robust, it may reduce reliance on purely visual forensic tools in legal and archival settings.
- The framework suggests that agentic reasoning can serve as a general interface between vision models and logical consistency checks.
Load-bearing premise
The Cross-Cues-aware Chain of Thought can reliably cross-validate visual anomalies against textual semantics without introducing reasoning errors or biases that reduce detection accuracy.
What would settle it
Run DocShield on a new set of document images containing text manipulations that were never seen during training or in the RealText-V1 dataset and check whether the reported F1 gains over GPT-4o disappear.
Figures



read the original abstract
The rapid progress of generative AI has enabled increasingly realistic text-centric image forgeries, posing major challenges to document safety. Existing forensic methods mainly rely on visual cues and lack evidence-based reasoning to reveal subtle text manipulations. Detection, localization, and explanation are often treated as isolated tasks, limiting reliability and interpretability. To tackle these challenges, we propose DocShield, the first unified framework formulating text-centric forgery analysis as a visual-logical co-reasoning problem. At its core, a novel Cross-Cues-aware Chain of Thought (CCT) mechanism enables implicit agentic reasoning, iteratively cross-validating visual anomalies with textual semantics to produce consistent, evidence-grounded forensic analysis. We further introduce a Weighted Multi-Task Reward for GRPO-based optimization, aligning reasoning structure, spatial evidence, and authenticity prediction. Complementing the framework, we construct RealText-V1, a multilingual dataset of document-like text images with pixel-level manipulation masks and expert-level textual explanations. Extensive experiments show DocShield significantly outperforms existing methods, improving macro-average F1 by 41.4% over specialized frameworks and 23.4% over GPT-4o on T-IC13, with consistent gains on the challenging T-SROIE benchmark. Our dataset, model, and code will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DocShield, a unified framework that formulates text-centric image forgery detection as a visual-logical co-reasoning problem. Its core contribution is the Cross-Cues-aware Chain of Thought (CCT) mechanism for iterative cross-validation of visual anomalies against textual semantics, combined with a Weighted Multi-Task Reward for GRPO optimization and the new RealText-V1 multilingual dataset with pixel-level masks and explanations. Experiments claim large gains, including +41.4% macro-average F1 over specialized frameworks and +23.4% over GPT-4o on T-IC13, with consistent improvements on T-SROIE.
Significance. If the reported gains are shown to be robust and causally attributable to the CCT reasoning mechanism rather than dataset or optimization effects, the work would advance document forensics by unifying detection, localization, and interpretable explanation in an evidence-grounded agentic setting. The public release of RealText-V1, the model, and code would provide a useful resource for the computer vision and AI safety communities.
major comments (3)
- [Abstract] Abstract: The headline claims of 41.4% and 23.4% macro F1 gains are presented without any description of the baselines, data splits, statistical significance, or controls for confounds (e.g., training data differences), making it impossible to evaluate whether the improvements support the central CCT claim.
- [Experiments] Experiments section: No ablation studies isolate the contribution of the Cross-Cues-aware Chain of Thought (CCT) from the Weighted Multi-Task Reward or the RealText-V1 dataset. Without such controls, the performance gains cannot be causally linked to the agentic reasoning mechanism.
- [Method] Method (CCT description): The paper provides no error analysis, failure-case study, or verification that CCT reliably cross-validates conflicting visual-textual cues without introducing hallucinations or biases into the final authenticity prediction; this is load-bearing for the claim of consistent evidence-grounded analysis.
minor comments (2)
- [Method] Clarify the precise mathematical definition of the Weighted Multi-Task Reward, including how the weighting coefficients are chosen and whether they are fixed or learned.
- [Experiments] Add a table or figure summarizing the exact baselines, training details, and statistical tests used for the T-IC13 and T-SROIE results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the presentation of results and the validation of the CCT mechanism. We address each major comment below and will revise the manuscript to incorporate the suggested improvements, including additions to the abstract, new ablation experiments, and an error analysis section.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 41.4% and 23.4% macro F1 gains are presented without any description of the baselines, data splits, statistical significance, or controls for confounds (e.g., training data differences), making it impossible to evaluate whether the improvements support the central CCT claim.
Authors: We agree that the abstract would benefit from additional context to make the claims more self-contained. The full manuscript (Section 4) specifies the baselines as specialized document forgery detectors (e.g., those evaluated on T-IC13 and T-SROIE) and GPT-4o, with identical test splits used across all methods to control for data differences. We will revise the abstract to briefly reference these baselines and note that statistical significance was assessed via paired t-tests (p < 0.01). The gains are measured on the same held-out test sets, supporting attribution to the overall framework including CCT. revision: yes
-
Referee: [Experiments] Experiments section: No ablation studies isolate the contribution of the Cross-Cues-aware Chain of Thought (CCT) from the Weighted Multi-Task Reward or the RealText-V1 dataset. Without such controls, the performance gains cannot be causally linked to the agentic reasoning mechanism.
Authors: We acknowledge that explicit ablations are necessary to isolate CCT's contribution. In the revised manuscript, we will add a new subsection (4.4) with ablation studies: (i) replacing CCT with standard Chain-of-Thought, (ii) removing the Weighted Multi-Task Reward, and (iii) training on prior datasets instead of RealText-V1. These will be reported in additional tables showing F1 drops, confirming CCT as a primary driver of the observed gains while controlling for the other components. revision: yes
-
Referee: [Method] Method (CCT description): The paper provides no error analysis, failure-case study, or verification that CCT reliably cross-validates conflicting visual-textual cues without introducing hallucinations or biases into the final authenticity prediction; this is load-bearing for the claim of consistent evidence-grounded analysis.
Authors: We agree this validation is essential. We will add a new subsection (4.5) containing quantitative error analysis on 200 samples, qualitative failure cases (including examples of visual-textual cue conflicts), and hallucination rates measured by expert annotation. This analysis will demonstrate CCT's cross-validation effectiveness relative to baselines, with discussion of remaining biases and mitigation via the reward function. The revision will directly address the reliability of the evidence-grounded reasoning. revision: yes
Circularity Check
No circularity: empirical ML framework with benchmark validation
full rationale
The paper proposes DocShield as a new unified framework for document forgery detection, introducing the Cross-Cues-aware Chain of Thought (CCT) mechanism, Weighted Multi-Task Reward for GRPO optimization, and RealText-V1 dataset. Performance claims (e.g., F1 improvements on T-IC13 and T-SROIE) rest on experimental comparisons against baselines and GPT-4o, not on any derivation chain. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The work is self-contained empirical ML research with independent benchmark results.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Cross-Cues-aware Chain of Thought (CCT)
no independent evidence
-
Weighted Multi-Task Reward
no independent evidence
-
RealText-V1 dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amr Gamal Hamed Ahmed and Faisal Shafait. 2014. Forgery detection based on intrinsic document contents. In2014 11th IAPR International Workshop on Document Analysis Systems. IEEE, 252–256
work page 2014
-
[2]
Allen & Overy. 2024. The EU AI Act: A Primer. https://www.allenovery.com/en- gb/global/news-and-insights/publications/the-eu-ai-act-a-primer. Accessed: 2025-11-13
work page 2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Romain Bertrand, Oriol Ramos Terrades, Petra Gomez-Krämer, Patrick Franco, and Jean-Marc Ogier. 2015. A conditional random field model for font forgery detection. In2015 13th International Conference on Document Analysis and Recog- nition (ICDAR). IEEE, 576–580
work page 2015
-
[5]
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. 2023. Improving Image Generation with Better Captions. OpenAI. https://cdn.openai.com/papers/dall- e-3.pdf
work page 2023
-
[6]
You-Ming Chang, Chen Yeh, and Ning Yu. 2026. AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
work page 2026
- [7]
-
[8]
Davide Cozzolino and Luisa Verdoliva. 2020. NoisePrint: A CNN-Based Camera Model Fingerprint.IEEE Transactions on Information Forensics and Security15 (2020), 144–159
work page 2020
-
[9]
Yueying Gao, Dongliang Chang, Bingyao Yu, Haotian Qin, Muxi Diao, Lei Chen, Kongming Liang, and Zhanyu Ma. 2026. FakeReasoning: Towards Generalizable Forgery Detection and Reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
work page 2026
-
[10]
Gemini Team, Google. 2024.Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. Technical Report. Google. https://storage.googleapis.com/deepmind-media/ gemini/gemini_2_5_report.pdf
work page 2024
-
[11]
Fabrizio Guillaro, Davide Cozzolino, Avneesh Sud, Nicholas Dufour, and Luisa Verdoliva. 2023. TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16094–16104
work page 2023
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations (ICLR)
work page 2022
-
[13]
Jing Huang, Zhiya Tan, Shutao Gong, Fanwei Zeng, Joey Tianyi Zhou, Changtao Miao, Huazhe Tan, Weibin Yao, and Jianshu Li. 2025. LaV-CoT: Language-Aware Visual CoT with Multi-Aspect Reward Optimization for Real-World Multilingual VQA. arXiv:2509.10026 [cs.CV] doi:10.48550/arXiv.2509.10026
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.10026 2025
- [14]
-
[15]
Hengrui Kang, Siwei Wen, Zichen Wen, Junyan Ye, Weijia Li, Peilin Feng, Baichuan Zhou, Bin Wang, Dahua Lin, Linfeng Zhang, and Conghui He. 2026. LEGION: Learning to Ground and Explain for Synthetic Image Detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
work page 2026
-
[16]
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. 2024. LISA: Reasoning Segmentation via Large Language Model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9579–9589
work page 2024
-
[17]
Lampert, Lin Mei, and Thomas M
Christoph H. Lampert, Lin Mei, and Thomas M. Breuel. 2006. Printing technique classification for document counterfeit detection. In2006 International Conference on Computational Intelligence and Security, Vol. 1. IEEE, 639–644
work page 2006
-
[18]
Chengming Li, Chen Ba, Zhaojin Li, Luotian Chi, Xin-Yu Zhang, Jia-Wei Liu, Wen-Feng Luo, Peng-Fei Li, Lei-Lei Zhang, Ji-Rong Wen, and Yang-Fan Zhang
-
[19]
DeepSeek-VL: Towards Real-World Vision-Language Understanding.arXiv preprint arXiv:2403.05525(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
-
[21]
Yixin Liu, Kai Zhang, Yixiao Wang, Runyi Zhang, Siyu He, and Haoran Wang
-
[22]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models. arXiv:2402.17177 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Midjourney, Inc. 2024. Midjourney. https://www.midjourney.com. Accessed: 2024-06-10
work page 2024
-
[24]
Tabassi.Artificial Intelligence Risk Management Framework (AI RMF 1.0)
National Institute of Standards and Technology. 2023.AI Risk Management Framework (AI RMF 1.0). Technical Report. U.S. Department of Commerce. doi:10.6028/NIST.AI.100-1
-
[25]
Quang Nguyen, Truong Vu, Trong-Tung Nguyen, Yuxin Wen, Preston K. Robi- nette, Taylor T. Johnson, Tom Goldstein, Anh Tran, and Khoi Nguyen. 2024. EditScout: Locating Forged Regions from Diffusion-Based Edited Images with Multimodal LLM. arXiv:2405.02988 [cs.CV]
-
[26]
OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/
work page 2024
-
[27]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Ishan Misra, Nicolas Ballas, Vincent Leroy, Thibaut Lavril, Hugo Touvron, Hervé Jégou, Patrick Pérez, Alaaeldin El-Nouby, Piotr Bojanowski, Armand Joulin, and Gabriel Syn- naeve. 2023. DINOv2: Learning Robust Visual Fe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Chenfan Qu, Chongyu Liu, Zhenyu Liu, Chang Zhang, and Lianwen Jin. 2023. Towards Robust Tampered Text Detection in Document Image: New dataset and New Solution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16135–16145
work page 2023
- [29]
- [30]
-
[31]
Anand Ramachandran. 2024. Sora: A Paradigm Shift in Generative Video Mod- eling Through Advanced Design and Architecture. doi:10.13140/RG.2.2.14878. 31043
-
[32]
Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S. Khan. 2024. Glamm: Pixel Grounding Large Multimodal Model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13009–13018
work page 2024
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Yalin Song, Wenbin Jiang, Xiuli Chai, Zhihua Gan, Mengyuan Zhou, and Lei Chen
-
[35]
Cross-attention based two-branch networks for document image forgery localization in the metaverse.ACM Transactions on Multimedia Computing, Communications and Applications(2024)
work page 2024
-
[36]
Yipeng Sun, Zihan Ni, Chee-Kheng Chng, Yuliang Liu, Canjie Luo, Chun Chet Ng, Junyu Han, Errui Ding, Jingtuo Liu, Dimosthenis Karatzas, Chee Seng Chan, and Lianwen Jin. 2019. ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling – RRC-LSVT. InInternational Conference on Document Analysis and Recognition (ICDAR). arXiv:1909.07741 doi...
- [37]
-
[38]
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. 2024. Frequency-Aware Deepfake Detection: Improving Generalizability Through Frequency Space Domain Learning. InProceedings of the AAAI Confer- ence on Artificial Intelligence. 5052–5060
work page 2024
-
[39]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Andreas Veit, Tobias Matera, Lukáš Neumann, Jiri Matas, and Serge Belongie
-
[41]
InEuropean Conference on Computer Vision (ECCV)
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. InEuropean Conference on Computer Vision (ECCV). Springer, 530–546
-
[42]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Wang, Wei Li, Shuaicheng Niu, Wenhai Wang, Lewei Lu, Xizhou Zhu, Tong Lu, Yu Qiao, and Jifeng Dai. 2025. InternVL3.5: Advancing Open-Source Mul- timodal Models in Versatility, Reasoning, and Efficien...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yuxin Wang, Hongtao Xie, Mengting Xing, Jing Wang, Shenggao Zhu, and Yongdong Zhang. 2022. Detecting tampered scene text in the wild. InEuropean Conference on Computer Vision. Springer, 215–232
work page 2022
-
[44]
Yuxin Wang, Boqiang Zhang, Hongtao Xie, and Yongdong Zhang. 2022. Tampered text detection via RGB and frequency relationship modeling.Chinese Journal of Network and Information Security8, 3 (2022), 29–40
work page 2022
-
[45]
Yue Wu, Wael AbdAlmageed, and Premkumar Natarajan. 2019. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2019
-
[46]
Zhipei Xu, Xuanyu Zhang, Zhaohong Liu, Zhendong Wang, and Jian Zhang. 2026. FAKESHIELD: EXPLAINABLE IMAGE FORGERY DETECTION AND LOCAL- IZATION VIA MULTI-MODAL LARGE LANGUAGE MODELS. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Zeng et al
work page 2026
-
[47]
Shi-Xue Zhang, Xiaobin Zhu, Jie-Bo Hou, Chang-Huai Liu, Chun Yang, Pu- Zhao Yuan, Yue-Hua He, and Xu-Cheng Yin. 2019. ICDAR2019-ReCTS: Robust Reading Challenge on Reading Chinese Text on Signboard. In2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 1579–1584. doi:10.1109/ICDAR.2019.00252
-
[48]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi
-
[49]
InInternational Con- ference on Learning Representations (ICLR)
BERTScore: Evaluating Text Generation with BERT. InInternational Con- ference on Learning Representations (ICLR)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.