Recognition: 2 theorem links
· Lean TheoremRayMamba: Ray-Aligned Serialization for Long-Range 3D Object Detection
Pith reviewed 2026-05-13 20:21 UTC · model grok-4.3
The pith
Ray-aligned serialization of sparse voxels improves long-range 3D object detection by preserving directional context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
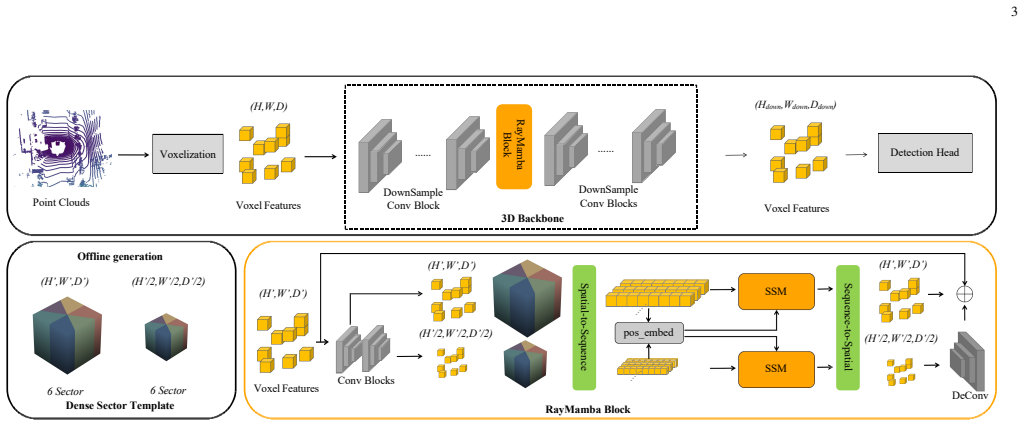
RayMamba introduces ray-aligned serialization that arranges sparse voxels into sector-wise ordered sequences to maintain directional continuity and occlusion-related context for subsequent Mamba modeling in long-range 3D object detection.
What carries the argument
Ray-aligned serialization strategy that orders voxels sector-wise along rays to preserve geometric neighborhoods for Mamba-based context modeling.
Load-bearing premise
Sector-wise ray-aligned ordering of sparse voxels preserves meaningful directional continuity and occlusion-related context better than generic serialization strategies.
What would settle it
Replace the ray-aligned ordering with random or distance-based voxel sequencing in the same detectors and test whether the reported long-range mAP and NDS gains on nuScenes disappear.
Figures




read the original abstract
Long-range 3D object detection remains challenging because LiDAR observations become highly sparse and fragmented in the far field, making reliable context modeling difficult for existing detectors. To address this issue, recent state space model (SSM)-based methods have improved long-range modeling efficiency. However, their effectiveness is still limited by generic serialization strategies that fail to preserve meaningful contextual neighborhoods in sparse scenes. To address this issue, we propose RayMamba, a geometry-aware plug-and-play enhancement for voxel-based 3D detectors. RayMamba organizes sparse voxels into sector-wise ordered sequences through a ray-aligned serialization strategy, which preserves directional continuity and occlusion-related context for subsequent Mamba-based modeling. It is compatible with both LiDAR-only and multimodal detectors, while introducing only modest overhead. Extensive experiments on nuScenes and Argoverse 2 demonstrate consistent improvements across strong baselines. In particular, RayMamba achieves up to 2.49 mAP and 1.59 NDS gain in the challenging 40--50 m range on nuScenes, and further improves VoxelNeXt on Argoverse 2 from 30.3 to 31.2 mAP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RayMamba, a plug-and-play module for voxel-based 3D detectors that applies ray-aligned serialization: sparse voxels are partitioned into angular sectors and ordered within each sector before concatenation into sequences for Mamba-based context modeling. The central claim is that this geometry-aware ordering preserves directional continuity and occlusion neighborhoods better than generic serialization, yielding empirical gains of up to 2.49 mAP and 1.59 NDS in the 40-50 m range on nuScenes and lifting VoxelNeXt from 30.3 to 31.2 mAP on Argoverse 2.
Significance. If the reported gains prove robust and attributable to the serialization strategy, the work would offer a lightweight, geometry-informed way to improve long-range context modeling in sparse LiDAR scenes. This could meaningfully extend SSM-based detectors and encourage further research on directional ordering for point-cloud sequences.
major comments (2)
- [Abstract] Abstract: the load-bearing claim that sector-wise ray ordering 'preserves directional continuity and occlusion-related context' is asserted without any description of inter-sector handling (angular wrapping, overlap, or global re-sorting). In the absence of such detail, the hard sequence breaks at sector boundaries risk severing precisely the occlusion neighborhoods the method is intended to maintain, especially in the sparse 40-50 m regime.
- [Abstract] Abstract / Experiments: the reported improvements (2.49 mAP, 1.59 NDS) are presented without ablation studies, error bars, or implementation details. This leaves open whether the gains arise from the ray-aligned ordering itself or from other unexamined factors, rendering the central empirical claim unverifiable from the given text.
minor comments (2)
- [Abstract] The phrase 'modest overhead' is imprecise; quantitative figures for added latency or parameters should be supplied.
- Prior SSM-based 3D detection works are referenced only at a high level; explicit citations and a brief comparison table would clarify the novelty of the serialization choice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying details from the full manuscript and making targeted revisions to improve verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the load-bearing claim that sector-wise ray ordering 'preserves directional continuity and occlusion-related context' is asserted without any description of inter-sector handling (angular wrapping, overlap, or global re-sorting). In the absence of such detail, the hard sequence breaks at sector boundaries risk severing precisely the occlusion neighborhoods the method is intended to maintain, especially in the sparse 40-50 m regime.
Authors: We agree the abstract is brief on this point. Section 3.2 of the manuscript specifies that voxels are partitioned into fixed non-overlapping angular sectors (no wrapping or overlap), sorted by radial distance within each sector, and concatenated into one sequence. Boundary breaks are intentional to avoid fabricating cross-sector links; Mamba's selective state mechanism then models dependencies across the full sequence. We have revised the abstract to note the concatenation step and expanded Section 3.2 with a paragraph and diagram on boundary handling. revision: yes
-
Referee: [Abstract] Abstract / Experiments: the reported improvements (2.49 mAP, 1.59 NDS) are presented without ablation studies, error bars, or implementation details. This leaves open whether the gains arise from the ray-aligned ordering itself or from other unexamined factors, rendering the central empirical claim unverifiable from the given text.
Authors: The abstract condenses results; the body (Section 4.3) already contains ablations comparing ray-aligned ordering against random, distance-only, and angular-only baselines, isolating the contribution of directional continuity. Implementation details appear in Section 3.4 and the supplement. To strengthen verifiability we have added error bars (std. dev. over 3 seeds) to the main tables and highlighted the ablation isolating the serialization strategy. revision: partial
Circularity Check
No circularity: empirical proposal of serialization strategy with no derivation chain or fitted inputs
full rationale
The paper introduces RayMamba as a plug-and-play ray-aligned serialization for sparse voxels in long-range 3D detection, asserting that sector-wise ordering preserves directional continuity and occlusion context for Mamba modeling. No equations, parameters, or uniqueness theorems are presented that reduce by construction to the method's own inputs. All claims rest on direct empirical comparisons against baselines on nuScenes and Argoverse 2, with reported mAP/NDS gains. No self-citation load-bearing steps, ansatzes smuggled via prior work, or renaming of known results appear; the approach is self-contained as a heuristic enhancement whose validity is tested externally rather than derived tautologically.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
voxels are partitioned into azimuth sectors and ordered within each sector according to vertical and angular continuity, forming a sector-wise layered angular ordering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
work page 2020
-
[2]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Ponteset al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,”arXiv preprint arXiv:2301.00493, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
work page 2018
-
[4]
V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,
Y . Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 21 674–21 683
work page 2023
-
[5]
Spherical transformer for lidar- based 3d recognition,
X. Lai, Y . Chen, F. Lu, J. Liu, and J. Jia, “Spherical transformer for lidar- based 3d recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 545–17 555
work page 2023
-
[6]
V oxel transformer for 3d object detection,
J. Mao, Y . Xue, M. Niu, H. Bai, J. Feng, X. Liang, H. Xu, and C. Xu, “V oxel transformer for 3d object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3164–3173
work page 2021
-
[7]
Embracing single stride 3d object detector with sparse transformer,
L. Fan, Z. Pang, T. Zhang, Y .-X. Wang, H. Zhao, F. Wang, N. Wang, and Z. Zhang, “Embracing single stride 3d object detector with sparse transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8458–8468
work page 2022
-
[8]
Centerformer: Center-based transformer for 3d object detection,
Z. Zhou, X. Zhao, Y . Wang, P. Wang, and H. Foroosh, “Centerformer: Center-based transformer for 3d object detection,” inEuropean Confer- ence on Computer Vision. Springer, 2022, pp. 496–513
work page 2022
-
[10]
Octr: Octree-based transformer for 3d object detection,
C. Zhou, Y . Zhang, J. Chen, and D. Huang, “Octr: Octree-based transformer for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5166– 5175
work page 2023
-
[11]
X. Jin, H. Su, K. Liu, C. Ma, W. Wu, F. Hui, and J. Yan, “Uni- mamba: Unified spatial-channel representation learning with group- efficient mamba for lidar-based 3d object detection,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1407–1417
work page 2025
-
[12]
V oxel mamba: Group-free state space models for point cloud based 3d object detection,
G. Zhang, L. Fan, C. He, Z. Lei, Z. Zhang, and L. Zhang, “V oxel mamba: Group-free state space models for point cloud based 3d object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 81 489–81 509, 2024
work page 2024
-
[13]
Mambafusion: Height-fidelity dense global fusion for multi-modal 3d object detection,
H. Wang, J. Gao, W. Hu, and Z. Zhang, “Mambafusion: Height-fidelity dense global fusion for multi-modal 3d object detection,”arXiv preprint arXiv:2507.04369, 2025
-
[14]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
work page 2021
-
[15]
Mv2dfusion: Lever- aging modality-specific object semantics for multi-modal 3d detection,
Z. Wang, Z. Huang, Y . Gao, N. Wang, and S. Liu, “Mv2dfusion: Lever- aging modality-specific object semantics for multi-modal 3d detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[16]
Y . Chen, S. Liu, X. Shen, and J. Jia, “Fast point r-cnn,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9775–9784
work page 2019
-
[17]
Std: Sparse-to-dense 3d object detector for point cloud,
Z. Yang, Y . Sun, S. Liu, X. Shen, and J. Jia, “Std: Sparse-to-dense 3d object detector for point cloud,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1951–1960
work page 2019
-
[18]
Deep hough voting for 3d object detection in point clouds,
C. R. Qi, O. Litany, K. He, and L. J. Guibas, “Deep hough voting for 3d object detection in point clouds,” inproceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9277–9286
work page 2019
-
[19]
Back-tracing representative points for voting-based 3d object detection in point clouds,
B. Cheng, L. Sheng, S. Shi, M. Yang, and D. Xu, “Back-tracing representative points for voting-based 3d object detection in point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8963–8972
work page 2021
-
[20]
Group-free 3d object detection via transformers,
Z. Liu, Z. Zhang, Y . Cao, H. Hu, and X. Tong, “Group-free 3d object detection via transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2949–2958
work page 2021
-
[21]
V oxelnet: End-to-end learning for point cloud based 3d object detection,
Y . Zhou and O. Tuzel, “V oxelnet: End-to-end learning for point cloud based 3d object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499
work page 2018
-
[22]
Mssvt: Mixed-scale sparse voxel transformer for 3d object detection on point clouds,
S. Dong, L. Ding, H. Wang, T. Xu, X. Xu, J. Wang, Z. Bian, Y . Wang, and J. Li, “Mssvt: Mixed-scale sparse voxel transformer for 3d object detection on point clouds,”Advances in Neural Information Processing Systems, vol. 35, pp. 11 615–11 628, 2022
work page 2022
-
[23]
Tanet: Robust 3d object detection from point clouds with triple attention,
Z. Liu, X. Zhao, T. Huang, R. Hu, Y . Zhou, and X. Bai, “Tanet: Robust 3d object detection from point clouds with triple attention,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 11 677–11 684
work page 2020
-
[24]
Focal sparse convolutional networks for 3d object detection,
Y . Chen, Y . Li, X. Zhang, J. Sun, and J. Jia, “Focal sparse convolutional networks for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5428– 5437
work page 2022
-
[25]
Largekernel3d: Scaling up kernels in 3d sparse cnns,
Y . Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “Largekernel3d: Scaling up kernels in 3d sparse cnns,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 13 488–13 498
work page 2023
-
[26]
Link: Linear kernel for lidar-based 3d perception,
T. Lu, X. Ding, H. Liu, G. Wu, and L. Wang, “Link: Linear kernel for lidar-based 3d perception,” inProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, 2023, pp. 1105–1115
work page 2023
-
[27]
Fully sparse 3d object detection,
L. Fan, F. Wang, N. Wang, and Z.-X. Zhang, “Fully sparse 3d object detection,”Advances in Neural Information Processing Systems, vol. 35, pp. 351–363, 2022
work page 2022
-
[28]
Pointmamba: A simple state space model for point cloud analysis,
D. Liang, X. Zhou, W. Xu, X. Zhu, Z. Zou, X. Ye, X. Tan, and X. Bai, “Pointmamba: A simple state space model for point cloud analysis,” Advances in neural information processing systems, vol. 37, pp. 32 653– 32 677, 2024
work page 2024
-
[29]
Lion: Linear group rnn for 3d object detection in point clouds,
Z. Liu, J. Hou, X. Wang, X. Ye, J. Wang, H. Zhao, and X. Bai, “Lion: Linear group rnn for 3d object detection in point clouds,”Advances in Neural Information Processing Systems, vol. 37, pp. 13 601–13 626, 2024
work page 2024
-
[30]
Swformer: Sparse window transformer for 3d object detection in point clouds,
P. Sun, M. Tan, W. Wang, C. Liu, F. Xia, Z. Leng, and D. Anguelov, “Swformer: Sparse window transformer for 3d object detection in point clouds,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 426–442
work page 2022
-
[31]
Dsvt: Dynamic sparse voxel transformer with rotated sets,
H. Wang, C. Shi, S. Shi, M. Lei, S. Wang, D. He, B. Schiele, and L. Wang, “Dsvt: Dynamic sparse voxel transformer with rotated sets,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 520–13 529
work page 2023
-
[32]
Point cloud mamba: Point cloud learning via state space model,
T. Zhang, H. Yuan, L. Qi, J. Zhang, Q. Zhou, S. Ji, S. Yan, and X. Li, “Point cloud mamba: Point cloud learning via state space model,” in Proceedings of the AAAI conference on artificial intelligence, vol. 39, no. 10, 2025, pp. 10 121–10 130
work page 2025
-
[33]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705
work page 2019
-
[34]
Ssn: Shape signature networks for multi-class object detection from point clouds,
X. Zhu, Y . Ma, T. Wang, Y . Xu, J. Shi, and D. Lin, “Ssn: Shape signature networks for multi-class object detection from point clouds,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 581– 597
work page 2020
-
[35]
Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,
X. Bai, Z. Hu, X. Zhu, Q. Huang, Y . Chen, H. Fu, and C.-L. Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1090–1099
work page 2022
-
[36]
Bevfusion: A simple and robust lidar-camera fusion 9 framework,
T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y . Wang, T. Tang, B. Wang, and Z. Tang, “Bevfusion: A simple and robust lidar-camera fusion 9 framework,”Advances in neural information processing systems, vol. 35, pp. 10 421–10 434, 2022
work page 2022
-
[37]
H. Cai, Z. Zhang, Z. Zhou, Z. Li, W. Ding, and J. Zhao, “Bevfusion4d: Learning lidar-camera fusion under bird’s-eye-view via cross-modality guidance and temporal aggregation,”arXiv preprint arXiv:2303.17099, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.