Recognition: no theorem link
Learning from Synthetic Data via Provenance-Based Input Gradient Guidance
Pith reviewed 2026-05-13 19:38 UTC · model grok-4.3
The pith
Provenance information from synthetic data synthesis is used to suppress input gradients over non-target regions, directing models to learn discriminative features from target objects instead of artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
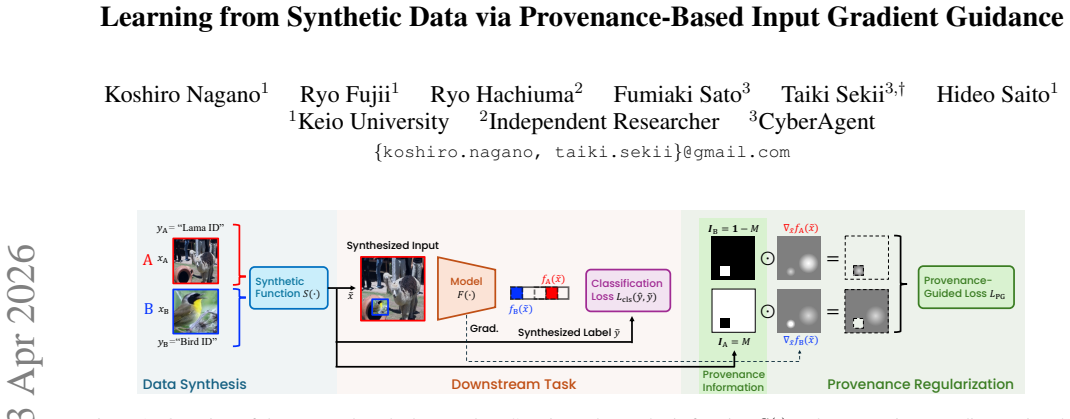
Input gradients are decomposed according to target versus non-target provenance labels obtained during data synthesis; gradient guidance then reduces the contribution of non-target regions. This directly discourages the model from relying on synthesis biases and artifacts, thereby promoting the acquisition of representations that discriminate based on the intended target regions.
What carries the argument
Provenance-based input gradient guidance, which decomposes gradients using target and non-target region masks from the synthesis process and applies suppression to the non-target components.
If this is right
- Models exhibit reduced dependence on synthesis artifacts during weakly supervised object localization.
- Performance improves on spatio-temporal action localization by concentrating gradients on relevant moving objects.
- Image classification accuracy rises because the network avoids learning correlations tied to background or rendering biases.
- The same guidance mechanism applies without modification across different tasks and input modalities.
Where Pith is reading between the lines
- The technique could lower the volume of real labeled data needed for robust vision models by making synthetic sources more reliable.
- Extending provenance tracking to video synthesis or 3-D rendering pipelines would allow similar gradient control in those domains.
- Combining the guidance with existing domain-randomization methods might yield additive gains by attacking different sources of spurious correlation.
Load-bearing premise
Provenance labels from the synthesis process correctly mark target versus non-target regions, and reducing gradients in the non-target areas improves focus on useful features without discarding helpful information or adding new biases.
What would settle it
Training the same model on the same synthetic data both with and without the gradient suppression step and finding no consistent improvement (or a drop) on localization or classification benchmarks would falsify the central claim.
Figures



read the original abstract
Learning methods using synthetic data have attracted attention as an effective approach for increasing the diversity of training data while reducing collection costs, thereby improving the robustness of model discrimination. However, many existing methods improve robustness only indirectly through the diversification of training samples and do not explicitly teach the model which regions in the input space truly contribute to discrimination; consequently, the model may learn spurious correlations caused by synthesis biases and artifacts. Motivated by this limitation, this paper proposes a learning framework that uses provenance information obtained during the training data synthesis process, indicating whether each region in the input space originates from the target object, as an auxiliary supervisory signal to promote the acquisition of representations focused on target regions. Specifically, input gradients are decomposed based on information about target and non-target regions during synthesis, and input gradient guidance is introduced to suppress gradients over non-target regions. This suppresses the model's reliance on non-target regions and directly promotes the learning of discriminative representations for target regions. Experiments demonstrate the effectiveness and generality of the proposed method across multiple tasks and modalities, including weakly supervised object localization, spatio-temporal action localization, and image classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a learning framework for synthetic data that uses provenance information from the synthesis process as an auxiliary supervisory signal. Input gradients are decomposed according to target versus non-target regions identified during synthesis, and a guidance mechanism is introduced to suppress gradients over non-target regions, with the goal of reducing reliance on synthesis artifacts and promoting discriminative representations focused on target regions. Experiments are presented on weakly supervised object localization, spatio-temporal action localization, and image classification, claiming improved effectiveness and generality across tasks and modalities.
Significance. If the provenance masks prove accurate and the gradient suppression reliably improves target focus without discarding useful context, the approach could meaningfully advance synthetic-data training in computer vision by providing an explicit, provenance-derived corrective signal against spurious correlations. The multi-task evaluation suggests potential breadth, but only if the core assumption about mask fidelity holds under realistic synthesis conditions.
major comments (2)
- [§3] §3 (Method): The central claim that gradient decomposition and non-target suppression 'directly promotes' target-focused discriminative representations rests on the unverified assumption that provenance masks accurately label every pixel/region without boundary or occlusion errors. No quantitative mask-fidelity metrics (e.g., IoU against ground-truth object masks) or ablation on mask noise are reported, leaving open the possibility that suppression artifacts reinforce rather than mitigate biases.
- [§4] §4 (Experiments): The reported gains on weakly supervised localization and action localization lack error bars, statistical significance tests, and controls that isolate the contribution of the provenance guidance from standard data augmentation or loss weighting. Without these, it is impossible to confirm that the observed improvements are attributable to the proposed mechanism rather than other factors.
minor comments (2)
- [Abstract] Abstract: The abstract states experimental effectiveness but supplies no numerical results, baselines, or dataset details, which reduces clarity for readers seeking a quick assessment of impact.
- [§3.2] Notation: The description of gradient decomposition would benefit from an explicit equation showing how the provenance mask is multiplied into the input gradient before the guidance step.
Simulated Author's Rebuttal
Thank you for the thorough review and constructive suggestions. We address the major comments point-by-point below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central claim that gradient decomposition and non-target suppression 'directly promotes' target-focused discriminative representations rests on the unverified assumption that provenance masks accurately label every pixel/region without boundary or occlusion errors. No quantitative mask-fidelity metrics (e.g., IoU against ground-truth object masks) or ablation on mask noise are reported, leaving open the possibility that suppression artifacts reinforce rather than mitigate biases.
Authors: We appreciate this observation. The provenance masks in our method are obtained directly from the synthesis process, ensuring they accurately delineate target and non-target regions by construction, without the errors associated with independent mask estimation. This is a key advantage over methods relying on approximate masks. To address potential concerns about robustness, we will include an ablation study on mask noise in the revised manuscript and discuss the fidelity of the masks in more detail. revision: partial
-
Referee: [§4] §4 (Experiments): The reported gains on weakly supervised localization and action localization lack error bars, statistical significance tests, and controls that isolate the contribution of the provenance guidance from standard data augmentation or loss weighting. Without these, it is impossible to confirm that the observed improvements are attributable to the proposed mechanism rather than other factors.
Authors: We agree that these elements would improve the clarity and rigor of our experimental results. In the revised manuscript, we will add error bars based on multiple random seeds, include statistical significance testing, and provide additional ablation studies that control for data augmentation and loss weighting to isolate the effect of the provenance-based guidance. revision: yes
Circularity Check
No significant circularity; guidance signal derived from external synthesis provenance
full rationale
The paper's central mechanism decomposes input gradients using provenance masks generated during synthetic data creation to suppress non-target regions. This auxiliary signal originates outside the model's parameters and training loop, rather than being fitted from the target task data or defined in terms of the model's own outputs. No equations or steps in the provided description reduce by construction to their inputs, and the abstract contains no self-citation chains, uniqueness theorems, or ansatzes that would force the result. The derivation remains self-contained against the external provenance data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep speech 2: End- to-end speech recognition in english and mandarin
Dario Amodei, Sundaram Ananthanarayanan, Rishita Anub- hai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, Jie Chen, Jingdong Chen, Zhijie Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Ke Ding, Niandong Du, Erich Elsen, Jesse Engel, Weiwei Fang, Linxi Fan, Christopher Fougner, Liang Gao, Caixia Go...
-
[2]
Uncertainty-Aware Weakly Supervised Action De- tection from Untrimmed Videos
Anurag Arnab, Chen Sun, Arsha Nagrani, and Cordelia Schmid. Uncertainty-Aware Weakly Supervised Action De- tection from Untrimmed Videos. InECCV, 2020. 7
work page 2020
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InNeurIPS, 2020. 1
work page 2020
-
[4]
SCM: Spatial Continuity Modeling for Weakly Supervised Object Localization
Haotian Bai, Ruimao Zhang, Jiong Wang, and Xiang Wan. SCM: Spatial Continuity Modeling for Weakly Supervised Object Localization. InECCV, 2022. 6
work page 2022
-
[5]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen M. Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin,...
work page 2020
-
[6]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Joao Carreira and Andrew Zisserman. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In CVPR, 2017. 6
work page 2017
-
[7]
A flexible model for training action local- ization with varying levels of supervision
Guilhem Ch ´eron, Jean-Baptiste Alayrac, Ivan Laptev, and Cordelia Schmid. A flexible model for training action local- ization with varying levels of supervision. InNeurIPS, 2018. 7
work page 2018
-
[8]
Evaluating weakly supervised object localization methods right
Junsuk Choe, Seong Joon Oh, Seungho Lee, Sanghyuk Chun, Zeynep Akata, and Hyunjung Shim. Evaluating weakly supervised object localization methods right. In CVPR, 2020. 6
work page 2020
-
[9]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InNAACL, 2019. 1
work page 2019
-
[10]
Lisa Dunlap, Alyssa Umino, Han Zhang, Jiezhi Yang, Joseph E. Gonzalez, and Trevor Darrell. Diversify Your Vision Datasets with Automatic Diffusion-based Augmen- tation. InNeurIPS, 2023. 2, 3, 4, 6, 7, 1
work page 2023
-
[11]
Scaling laws of synthetic images for model training
Lijie Fan, Kaifeng Chen, Dilip Krishnan, Dina Katabi, Phillip Isola, and Yonglong Tian. Scaling laws of synthetic images for model training... for now. InCVPR, 2024. 3
work page 2024
-
[12]
Attention branch network: Learning of attention mechanism for visual explanation
Hiroshi Fukui, Tsubasa Hirakawa, Takayoshi Yamashita, and Hironobu Fujiyoshi. Attention branch network: Learning of attention mechanism for visual explanation. InCVPR, 2019. 3
work page 2019
-
[13]
TS-CAM: To- ken Semantic Coupled Attention Map for Weakly Supervised Object Localization
Wei Gao, Fang Wan, Xingjia Pan, Zhiliang Peng, Qi Tian, Zhenjun Han, Bolei Zhou, and Qixiang Ye. TS-CAM: To- ken Semantic Coupled Attention Map for Weakly Supervised Object Localization. InICCV, 2021. 6
work page 2021
- [14]
-
[15]
Unified Keypoint-Based Action Recognition Framework via Struc- tured Keypoint Pooling
Ryo Hachiuma, Fumiaki Sato, and Taiki Sekii. Unified Keypoint-Based Action Recognition Framework via Struc- tured Keypoint Pooling. InCVPR, 2023. 4, 5, 6, 7
work page 2023
-
[16]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. InCVPR,
-
[17]
On the Unreasonable Effectiveness of Last- Layer Retraining
John Collins Hill, Tyler LaBonte, Xinchen Zhang, and Vidya Muthukumar. On the Unreasonable Effectiveness of Last- Layer Retraining. InICLRW, 2025. 3
work page 2025
-
[18]
Gaurav Joshi. Mitigating Simplicity Bias in Neural Net- works: A Feature Sieve Modification, Regularization, and Self-Supervised Augmentation Approach. InICLRW, 2025. Workshop. 3
work page 2025
-
[19]
Puz- zle mix: Exploiting saliency and local statistics for optimal mixup
Jang-Hyun Kim, Wonho Choo, and Hyun Oh Song. Puz- zle mix: Exploiting saliency and local statistics for optimal mixup. InICML, 2020. 4, 6
work page 2020
-
[20]
Wilds: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. InICML, 2021. 6, 1
work page 2021
-
[21]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. InNeurIPS, 2012. 3
work page 2012
-
[22]
Nobuyuki Otsu. A threshold selection method from gray- level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66, 1979. 4, 1
work page 1979
-
[23]
ResizeMix: Mixing Data with Preserved Object Information and True Labels
Jie Qin, Jiemin Fang, Qian Zhang, Wenyu Liu, Xin- gang Wang, and Xinggang Wang. ResizeMix: Mixing Data with Preserved Object Information and True Labels. arXiv:2012.11101, 2020. 4, 6
-
[24]
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection. InCVPR, 2016. 1
work page 2016
-
[25]
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. InNeurIPS, 2015. 1
work page 2015
-
[26]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. InACM SIGKDD, 2016. 2
work page 2016
-
[27]
Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun
Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for Data: Ground Truth from Computer Games. InECCV, 2016. 3 9
work page 2016
-
[28]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 3
work page 2022
-
[29]
Hughes, and Finale Doshi- Velez
Andrew Slavin Ross, Michael C. Hughes, and Finale Doshi- Velez. Right for the right reasons: Training differentiable models by constraining their explanations. InIJCAI, 2017. 3
work page 2017
-
[30]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Chal- lenge.IJCV, 2015. 6
work page 2015
-
[31]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization.arXiv:1911.08731, 2019. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[32]
Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones
Mert B ¨ulent Sarıyıldız, Karteek Alahari, Diane Larlus, and Yannis Kalantidis. Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones. In CVPR, 2023. 3
work page 2023
-
[33]
Grad-CAM: visual explanations from deep networks via gradient-based localization.IJCV, 2020
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: visual explanations from deep networks via gradient-based localization.IJCV, 2020. 7
work page 2020
-
[34]
Feifei Shao, Yawei Luo, Lei Chen, Ping Liu, Wei Yang, Yi Yang, and Jun Xiao. Counterfactual Co-occurring Learning for Bias Mitigation in Weakly-supervised Object Localiza- tion.IEEE Transactions on Multimedia, 2026. 3
work page 2026
-
[35]
Very Deep Con- volutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very Deep Con- volutional Networks for Large-Scale Image Recognition. In ICLR, 2015. 6, 3
work page 2015
-
[36]
K.K. Singh and Y .J. Lee. Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-supervised Object and Action Localization. InICCV, 2017. 3
work page 2017
-
[37]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild.arXiv:1212.0402, 2012. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[38]
Deep High-Resolution Representation Learning for Human Pose Estimation
Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep High-Resolution Representation Learning for Human Pose Estimation. InCVPR, 2019. 6
work page 2019
-
[39]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Woj- ciech Zaremba, and Pieter Abbeel. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. InIROS, 2017. 3
work page 2017
-
[40]
Training Data-Efficient Image Transformers & Distillation through Attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv ´e J´egou. Training Data-Efficient Image Transformers & Distillation through Attention. InICML, 2021. 6, 3
work page 2021
-
[41]
Black, Ivan Laptev, and Cordelia Schmid
Gul Varol, Javier Romero, Xavier Martin, Naureen Mah- mood, Michael J. Black, Ivan Laptev, and Cordelia Schmid. Learning from Synthetic Humans. InCVPR, 2017. 3
work page 2017
-
[42]
The Caltech-UCSD Birds-200- 2011 Dataset.Caltech Technical Report, 2011
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The Caltech-UCSD Birds-200- 2011 Dataset.Caltech Technical Report, 2011. 5, 1
work page 2011
-
[43]
Spatial-Aware Token for Weakly Supervised Object Localization
Pingyu Wu, Wei Zhai, Yang Cao, Jiebo Luo, and Zheng- Jun Zha. Spatial-Aware Token for Weakly Supervised Object Localization. InICCV, 2023. 6
work page 2023
-
[44]
Pro2SAM: Mask Prompt to SAM with Grid Points for Weakly Supervised Object Localization
Xi Yang, Songsong Duan, Nannan Wang, and Xinbo Gao. Pro2SAM: Mask Prompt to SAM with Grid Points for Weakly Supervised Object Localization. InECCV, 2024. 6
work page 2024
-
[45]
CutMix: Regular- ization Strategy to Train Strong Classifiers With Localizable Features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. CutMix: Regular- ization Strategy to Train Strong Classifiers With Localizable Features. InICCV, 2019. 2, 3, 4, 5, 6, 7
work page 2019
-
[46]
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond Empirical Risk Mini- mization. InICLR, 2018. 2, 3
work page 2018
-
[47]
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. In CVPR, 2016. 6 10 Learning from Synthetic Data via Provenance-Based Input Gradient Guidance Supplementary Material Table 8. Hyperparameters of each dataset during training. Training datasetUCF101-24 [37] CUB [42] iWildCam [20]Waterbirds [...
work page 2016
-
[48]
Amount of Augmented Data Added
Implementation Details In this section, we provide details on data augmentation and training hyperparameters. As described in Sec. 3.2.3, provenance information is de- rived by computing a difference image between the gener- ated and source images, followed by Otsu binarization [22], to produce a binary mask distinguishing target regions from non-target r...
-
[49]
Ablation Study 7.1. Training Efficiency As accuracy results are presented in Secs. 4.3.1 and 4.3.3, this section focuses on training efficiency. We measure effi- ciency by the number of epochs required to reach peak val- 1 idation performance (“Best epoch”) under identical setups in Sec. 4.2, as summarized in Tabs. 9 and 10. 7.1.1. Image mixing Compared w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.