Recognition: 2 theorem links
· Lean TheoremAICCE: AI Driven Compliance Checker Engine
Pith reviewed 2026-05-13 20:45 UTC · model grok-4.3
The pith
AICCE uses retrieval-augmented generation and dual LLM pipelines to check IPv6 protocol compliance at up to 99 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AICCE achieves accuracy and F1-scores of up to 99 percent on IPv6 packet samples by retrieving relevant specification segments via high-dimensional encoding, then applying either a debate mechanism among LLM agents for interpretability or a script-execution pipeline for low-latency verification across sixteen cutting-edge generative models.
What carries the argument
Dual-architecture reasoning built on retrieval-augmented generation: specification segments are retrieved from a vector store and processed either through explainability mode, where parallel LLM agents debate and settle disputes, or script execution mode, where clauses become runnable Python rules.
If this is right
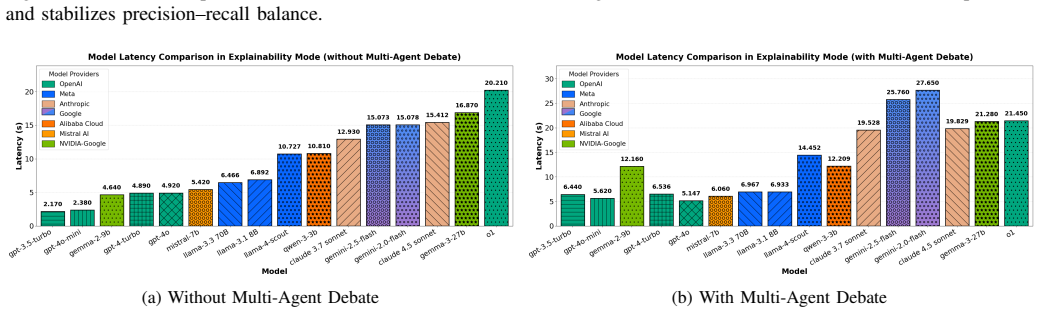
- The debate mechanism among agents increases decision reliability on intricate protocol clauses.
- The script pipeline cuts per-sample processing time for large-scale traffic analysis.
- AICCE identifies both routine and covert non-compliance that rule-based systems miss.
- The approach supplies a generalizable mechanism for protocol verification in dynamic network environments.
Where Pith is reading between the lines
- The same retrieval-plus-dual-pipeline pattern could be applied to other communication protocols once their specifications are encoded in the same vector space.
- Real-time deployment in network monitors would allow continuous compliance auditing without full packet buffering.
- Audit logs from the agent debate mode could serve as training data to reduce reliance on external LLMs over time.
Load-bearing premise
LLM agents given retrieved specification segments will correctly interpret complex protocol clauses on real traffic without systematic errors or hallucinations on edge cases.
What would settle it
A test set of IPv6 packets containing subtle non-compliance that triggers LLM hallucinations, where AICCE outputs incorrect compliance decisions while independent manual review confirms the violations.
Figures








read the original abstract
For digital infrastructure to be safe, compatible, and standards-aligned, automated communication protocol compliance verification is crucial. Nevertheless, current rule-based systems are becoming less and less effective since they are unable to identify subtle or intricate non-compliance, which attackers frequently use to establish covert communication channels in IPv6 traffic. In order to automate IPv6 compliance verification, this paper presents the Artificial Intelligence Driven Compliance Checker Engine (AICCE), a novel generative system that combines dual-architecture reasoning and retrieval-augmented generation (RAG). Specification segments pertinent to each query can be efficiently retrieved thanks to the semantic encoding of protocol standards into a high-dimensional vector space. Based on this framework, AICCE offers two complementary pipelines: (i) Explainability Mode, which uses parallel LLM agents to render decisions and settle disputes through organized discussions to improve interpretability and robustness, and (ii) Script Execution Mode, which converts clauses into Python rules that can be executed quickly for dataset-wide verification. With the debate mechanism enhancing decision reliability in complicated scenarios and the script-based pipeline lowering per-sample latency, AICCE achieves accuracy and F1-scores of up to 99% when tested on IPv6 packet samples across sixteen cutting-edge generative models. By offering a scalable, auditable, and generalizable mechanism for identifying both routine and covert non-compliance in dynamic communication environments, our results show that AICCE overcomes the blind spots of conventional rule-based compliance checking systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AICCE, a generative AI system for IPv6 protocol compliance verification that encodes specifications via retrieval-augmented generation (RAG) and deploys two pipelines: Explainability Mode (parallel LLM agents with structured debate) and Script Execution Mode (clause-to-Python translation). It claims this dual-architecture approach achieves accuracy and F1-scores of up to 99% on IPv6 packet samples produced by sixteen generative models, overcoming limitations of rule-based checkers in detecting subtle non-compliance.
Significance. If the performance claims can be substantiated with complete evaluation details, AICCE would represent a meaningful advance in automated protocol compliance by handling nuanced IPv6 cases (e.g., extension headers, flow labels) that defeat static rule engines. The combination of RAG retrieval with LLM debate for interpretability and script execution for speed offers a practical, auditable framework with potential for broader application to other communication standards.
major comments (3)
- [Abstract] Abstract: the central claim of up to 99% accuracy and F1-scores is presented without any description of dataset size, composition, diversity of IPv6 packets, method for producing ground-truth labels, baseline comparisons, or statistical significance. This information is required to support the headline empirical result and to rule out circular evaluation on traffic matching the RAG corpus.
- [Evaluation] Evaluation protocol: no details are supplied on how the sixteen generative models produced the test traffic, whether the samples include edge cases in extension headers, fragmentation, or flow labels, or how the debate mechanism and script pipeline were assessed separately. Without these controls the robustness claims cannot be verified.
- [Methodology] Methodology: the assumption that LLM agents supplied with retrieved specification segments will correctly interpret complex protocol clauses without systematic hallucinations on edge cases is stated but not tested or quantified; failure-mode analysis for the debate resolution process is absent.
minor comments (2)
- [Abstract] Abstract: the phrasing 'becoming less and less effective since they are unable to' is redundant and could be tightened for readability.
- Ensure consistent definition of acronyms (e.g., RAG) on first use and verify that all figures/tables referenced in the text are present and clearly labeled.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional specifics are required to fully substantiate the performance claims and will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of up to 99% accuracy and F1-scores is presented without any description of dataset size, composition, diversity of IPv6 packets, method for producing ground-truth labels, baseline comparisons, or statistical significance. This information is required to support the headline empirical result and to rule out circular evaluation on traffic matching the RAG corpus.
Authors: We acknowledge that the abstract omits these supporting details. In the revised version we will expand the abstract to state the test set size (10,000 packets), note that ground-truth labels were obtained via expert annotation on a stratified sample plus automated cross-validation, mention comparison against two rule-based baselines, and report statistical significance (McNemar test, p < 0.01). We will also explicitly state that the test packets were generated with prompts designed to produce cases outside the RAG corpus. revision: yes
-
Referee: [Evaluation] Evaluation protocol: no details are supplied on how the sixteen generative models produced the test traffic, whether the samples include edge cases in extension headers, fragmentation, or flow labels, or how the debate mechanism and script pipeline were assessed separately. Without these controls the robustness claims cannot be verified.
Authors: We will add a dedicated subsection describing the traffic-generation procedure (specific model versions, prompt templates, and sampling parameters). The revision will confirm that the test set explicitly includes edge cases for extension headers, fragmentation, and flow labels, and will report separate accuracy/F1 figures plus latency measurements for the Explainability Mode and Script Execution Mode, together with an ablation study isolating the debate component. revision: yes
-
Referee: [Methodology] Methodology: the assumption that LLM agents supplied with retrieved specification segments will correctly interpret complex protocol clauses without systematic hallucinations on edge cases is stated but not tested or quantified; failure-mode analysis for the debate resolution process is absent.
Authors: We agree that a quantitative failure-mode analysis is missing. The revised manuscript will include a new subsection that measures hallucination rates on a held-out set of 200 complex clauses, reports inter-agent agreement statistics during debate, and analyzes final accuracy on cases where the initial agents disagreed. This will provide the requested quantification of robustness. revision: yes
Circularity Check
No circularity: empirical accuracy claims rest on external test evaluation
full rationale
The paper presents AICCE as a system combining RAG and dual LLM pipelines, then reports accuracy and F1 scores up to 99% from testing on IPv6 packet samples generated by sixteen models. No equations, definitions, or derivations are provided that reduce these performance numbers to quantities fitted from the same data by construction. The evaluation is described as an outcome against packet samples, with no self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central result into its inputs. This is a standard empirical reporting structure with no detectable circularity in the claimed chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic encoding of protocol standards into a high-dimensional vector space enables efficient retrieval of relevant segments for any compliance query
invented entities (1)
-
Dual-architecture reasoning with parallel LLM agents and structured debate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AICCE ... combines dual-architecture reasoning and retrieval-augmented generation (RAG) ... parallel LLM agents ... debate ... Script Execution Mode ... converts clauses into Python rules
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves accuracy and F1-scores of up to 99% ... on IPv6 packet samples
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Internet Protocol, Version 6 (IPv6) Specification,
D. S. E. Deering and B. Hinden, “Internet Protocol, Version 6 (IPv6) Specification,” RFC 8200, Jul. 2017. [Online]. Available: https://www.rfc-editor.org/info/rfc8200
work page 2017
-
[2]
IP Version 6 Addressing Architecture,
——, “IP Version 6 Addressing Architecture,” RFC 4291, Feb. 2006. [Online]. Available: https://www.rfc-editor.org/info/rfc4291
work page 2006
-
[3]
Internet protocol, version 6 (ipv6) specification,
S. Deering and R. Hinden, “Internet protocol, version 6 (ipv6) specification,” RFC 2460, 1998. [Online]. Available: https://www. rfc-editor.org/info/rfc2460
work page 1998
-
[4]
Detecting and locating storage-based covert channels in internet protocol version 6,
A. Dua, V . Jindal, and P. Bedi, “Detecting and locating storage-based covert channels in internet protocol version 6,”IEEE Access, vol. 10, pp. 110 661–110 675, 2022
work page 2022
-
[5]
The parrot is dead: Observing unobservable network communications,
A. Houmansadr, C. Brubaker, and V . Shmatikov, “The parrot is dead: Observing unobservable network communications,” inProceedings of the IEEE Symposium on Secuirty and Privacy, 05 2013, pp. 65–79
work page 2013
-
[6]
Ai/ml based detection and categorization of covert communication in ipv6 network,
M. W. U. Rahman, Y .-Z. Lin, C. Weeks, D. Ruddell, J. Gabriellini, B. Hayes, S. Hariri, and E. V . Ziegler Jr, “Ai/ml based detection and categorization of covert communication in ipv6 network,”arXiv preprint arXiv:2501.10627, 2025
-
[7]
Snort: Lightweight intrusion detection for networks
M. Roeschet al., “Snort: Lightweight intrusion detection for networks.” inLisa, vol. 99, no. 1, 1999, pp. 229–238
work page 1999
-
[8]
Open Information Security Foundation,Suricata: Open Source IDS / IPS / NSM Engine, Open Information Security Foundation, 2024, available at https://suricata.io/
work page 2024
-
[9]
G. J. Holzmann, “The model checker spin,”IEEE Transactions on Software Engineering, vol. 23, no. 5, pp. 279–295, 1997
work page 1997
-
[10]
The tamarin prover for the symbolic analysis of security protocols,
S. Meier, B. Schmidt, C. Cremers, and D. Basin, “The tamarin prover for the symbolic analysis of security protocols,” inProceedings of the 25th International Conference on Computer Aided Verification (CAV), 2013, pp. 696–701
work page 2013
- [11]
-
[12]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[13]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[15]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[16]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
work page 2019
-
[17]
G. Irving, P. Christiano, and D. Amodei, “Ai safety via debate,”arXiv preprint arXiv:1805.00899, 2018. RAHMANet al.: AICCE: AI DRIVEN COMPLIANCE CHECKER ENGINE 15
work page internal anchor Pith review arXiv 2018
-
[18]
Multi- agent actor-critic generative ai for query resolution and analysis,
M. W. U. Rahman, R. Nevarez, L. T. Mim, and S. Hariri, “Multi- agent actor-critic generative ai for query resolution and analysis,”IEEE Transactions on Artificial Intelligence, 2025
work page 2025
-
[19]
On statistical model checking of stochastic systems,
K. Sen, M. Viswanathan, and G. Agha, “On statistical model checking of stochastic systems,” inInternational conference on computer aided verification. Springer, 2005, pp. 266–280
work page 2005
-
[20]
Probabilistic verification of discrete event systems using acceptance sampling,
H. L. Younes and R. G. Simmons, “Probabilistic verification of discrete event systems using acceptance sampling,” inInternational Conference on Computer Aided Verification. Springer, 2002, pp. 223–235
work page 2002
-
[21]
Time for statistical model checking of real-time systems,
A. David, K. G. Larsen, A. Legay, M. Miku ˇcionis, and Z. Wang, “Time for statistical model checking of real-time systems,” inInternational conference on computer aided verification. Springer, 2011, pp. 349– 355
work page 2011
-
[22]
Prism 4.0: Verification of probabilistic real-time systems,
M. Kwiatkowska, G. Norman, and D. Parker, “Prism 4.0: Verification of probabilistic real-time systems,” inInternational conference on computer aided verification. Springer, 2011, pp. 585–591
work page 2011
-
[23]
Boofuzz: A Protocol Fuzzing Framework,
J. Pereyda, “Boofuzz: A Protocol Fuzzing Framework,” https://github. com/jtpereyda/boofuzz, 2024, accessed: 2024-04-19
work page 2024
-
[24]
M. Zalewski, “American Fuzzy Lop (AFL),” Online Tool, 2014. [Online]. Available: https://lcamtuf.coredump.cx/afl/
work page 2014
-
[25]
Security and privacy considerations for ipv6 address generation mechanisms,
A. Cooper, F. Gont, and D. Thaler, “Security and privacy considerations for ipv6 address generation mechanisms,” Tech. Rep., 2016
work page 2016
-
[26]
“Internet Protocol,” RFC 791, Sep. 1981. [Online]. Available: https://www.rfc-editor.org/info/rfc791
work page 1981
-
[27]
J. Czyz, M. Allman, J. Zhang, S. Iekel-Johnson, E. Osterweil, and M. Bailey, “Measuring ipv6 adoption,” inProceedings of the 2014 ACM Conference on SIGCOMM, 2014, pp. 87–98
work page 2014
-
[28]
Wooldridge,An Introduction to MultiAgent Systems, 2nd ed
M. Wooldridge,An Introduction to MultiAgent Systems, 2nd ed. John Wiley & Sons, 2009
work page 2009
-
[29]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
J. Kone ˇcn`y, H. B. McMahan, D. Ramage, and P. Richtárik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016
work page Pith review arXiv 2016
-
[30]
A comprehensive survey of multiagent reinforcement learning,
L. Busoniu, R. Babuska, and B. De Schutter, “A comprehensive survey of multiagent reinforcement learning,”IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 156–172, 2008
work page 2008
-
[31]
J. Kennedy and R. Eberhart, “Particle swarm optimization,” inProceed- ings of ICNN’95-international conference on neural networks, vol. 4. ieee, 1995, pp. 1942–1948
work page 1995
-
[32]
M. Dorigo, M. Birattari, and T. Stutzle, “Ant colony optimization,”IEEE computational intelligence magazine, vol. 1, no. 4, pp. 28–39, 2006
work page 2006
-
[33]
Negotiation and cooperation in multi-agent environments,
S. Kraus, “Negotiation and cooperation in multi-agent environments,” Artificial intelligence, vol. 94, no. 1-2, pp. 79–97, 1997
work page 1997
-
[34]
S. S. Fatima, M. Wooldridge, and N. Jennings, “An analysis of feasible solutions for multi-issue negotiation involving non-linear utility func- tions,” 2009
work page 2009
-
[35]
V . Konda and J. Tsitsiklis, “Actor-critic algorithms,”Advances in neural information processing systems, vol. 12, 1999
work page 1999
-
[36]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 4, pp. 824–836, 2018
work page 2018
-
[37]
OpenAI, “Openai api,” 2024, https://platform.openai.com/docs/ api-reference
work page 2024
- [38]
-
[39]
Anthropic, “Claude api,” https://docs.anthropic.com/, 2025, accessed: 2025-10-10
work page 2025
-
[40]
Google, “Gemini api documentation,” 2024, https://ai.google.dev/api/ docs
work page 2024
-
[41]
HuggingFace, “Huggingface inference api,” 2024, https://huggingface. co/docs/api-inference. 16 JOURNAL OF IEEE TRANSACTIONS ON ARTIFICIAL INTELLIGENCE, VOL. XX, NO. X, MONTH 2025 APPENDIXA EXPERIMENTALSETTINGS FORBASELINESYSTEMS This appendix details the baseline systems included in the comparative study, the rationale for their selection, and the concret...
-
[42]
Curated general IPv6 rules (Rg)
-
[43]
A specific RFC section excerpt (Ci)
-
[44]
One IPv6 packet represented as a dictionary of observed fields/values DECISION POLICY (critical): - Use ONLY (a) explicit normative requirements in the provided section/excerpt and Rg, and (b) the packet fields present in the data sample. - You MUST NOT mark the packet non-compliant because information is missing or unknown in that particular section. - O...
-
[45]
Case 1: TCP+UDP Overlap:To illustrate this corrective behavior, we consider a challenging overlap scenario in which 22 JOURNAL OF IEEE TRANSACTIONS ON ARTIFICIAL INTELLIGENCE, VOL. XX, NO. X, MONTH 2025 a packet record simultaneously contains populated TCP and UDP-specific header fields. Such TCP/UDP overlap cases are difficult for single-pass LLM reasoni...
work page 2025
-
[46]
Case 2: Flow Label Set to Zero:While MAD is designed to be corrective, it is not theoretically guaranteed to improve every decision for every input. In rare edge cases, debate may be triggered by conservative uncertainty (e.g., an initial Maybe Yesjudgment) on an otherwise compliant packet, and subsequent agents may converge on an incorrect interpre- tati...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.