Recognition: 2 theorem links
· Lean TheoremRL-Driven Sustainable Land-Use Allocation for the Lake Malawi Basin
Pith reviewed 2026-05-13 17:04 UTC · model grok-4.3
The pith
A PPO reinforcement learning agent reallocates land uses across a Lake Malawi grid to raise total ecosystem service value.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a deep reinforcement learning framework that uses Proximal Policy Optimization with action masking to transfer land-use pixels between nine Sentinel-2 classes on a 50x50 grid. The reward combines per-cell ESV with contiguity bonuses for forest, cropland and built-area patches plus buffer penalties near water bodies. Across pure ESV maximization, spatially shaped, and regenerative agriculture scenarios the agent increases total ESV and steers allocations toward homogeneous clustering and modest forest consolidation near water.
What carries the argument
PPO agent operating on a grid environment whose actions transfer pixels between modifiable land-use classes, with a composite reward that adds per-cell ESV to spatial coherence terms for contiguous patches and water buffers.
If this is right
- The agent learns policies that raise total ESV relative to the initial allocation.
- Spatial reward shaping produces homogeneous land-use clusters and slight forest consolidation near water bodies.
- Changing policy parameters such as regenerative agriculture incentives produces distinct, interpretable allocation shifts.
- The framework functions as a scenario-analysis tool that lets planners test alternative policy weightings.
Where Pith is reading between the lines
- The same RL loop could incorporate time-varying drivers such as rainfall or population pressure if those layers were added to the environment.
- Running the trained agent on higher-resolution imagery or additional ecosystem-service layers would test whether the clustering pattern persists.
- Comparing the optimized maps against observed land-use transitions from recent Sentinel time series would provide an external check on the learned preferences.
Load-bearing premise
The ecosystem service value coefficients taken from global benefit-transfer tables accurately reflect local ecological and economic conditions when applied to the nine Sentinel-2 land-cover classes in the Lake Malawi Basin.
What would settle it
Field or household surveys that produce ESV estimates for the same land-cover classes in the Lake Malawi Basin differing by more than 30 percent from the applied coefficients would falsify the model's valuation layer.
Figures









read the original abstract
Unsustainable land-use practices in ecologically sensitive regions threaten biodiversity, water resources, and the livelihoods of millions. This paper presents a deep reinforcement learning (RL) framework for optimizing land-use allocation in the Lake Malawi Basin to maximize total ecosystem service value (ESV). Drawing on the benefit transfer methodology of Costanza et al., we assign biome-specific ESV coefficients -- locally anchored to a Malawi wetland valuation -- to nine land-cover classes derived from Sentinel-2 imagery. The RL environment models a 50x50 cell grid at 500m resolution, where a Proximal Policy Optimization (PPO) agent with action masking iteratively transfers land-use pixels between modifiable classes. The reward function combines per-cell ecological value with spatial coherence objectives: contiguity bonuses for ecologically connected land-use patches (forest, cropland, built area etc.) and buffer zone penalties for high-impact development adjacent to water bodies. We evaluate the framework across three scenarios: (i) pure ESV maximization, (ii) ESV with spatial reward shaping, and (iii) a regenerative agriculture policy scenario. Results demonstrate that the agent effectively learns to increase total ESV; that spatial reward shaping successfully steers allocations toward ecologically sound patterns, including homogeneous land-use clustering and slight forest consolidation near water bodies; and that the framework responds meaningfully to policy parameter changes, establishing its utility as a scenario-analysis tool for environmental planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a deep reinforcement learning framework employing Proximal Policy Optimization (PPO) to optimize land-use allocation in the Lake Malawi Basin. Using Sentinel-2 imagery to derive nine land-cover classes, it assigns ecosystem service value (ESV) coefficients via the benefit transfer method of Costanza et al., with local anchoring to a Malawi wetland study. The environment is a 50x50 grid at 500m resolution, where the agent iteratively reassigns land-use types under action masking. The reward combines per-cell ESV with spatial coherence bonuses for contiguity and penalties for development near water bodies. Three scenarios are evaluated: pure ESV maximization, ESV with spatial reward shaping, and a regenerative agriculture policy scenario. The central claims are that the agent increases total ESV, produces ecologically sound spatial patterns such as homogeneous clustering and forest consolidation, and responds to policy changes.
Significance. If the quantitative results hold and the ESV coefficients prove robust under local validation, this represents a useful application of RL to spatial environmental planning in data-scarce tropical basins, with potential as a scenario-analysis tool. The spatial reward shaping component is a constructive element. However, the current lack of reported metrics, baselines, and sensitivity analysis on the core valuation assumptions substantially limits the demonstrated significance.
major comments (2)
- [Abstract] Abstract: The abstract asserts that 'Results demonstrate that the agent effectively learns to increase total ESV' and describes outcomes including 'homogeneous land-use clustering and slight forest consolidation near water bodies', yet provides no quantitative values, tables, figures, error bars, baseline comparisons, or statistical metrics. This absence prevents any assessment of effect sizes or reliability of the central claims.
- [Methods (ESV assignment)] ESV coefficient assignment (Methods section): ESV coefficients for the nine Sentinel-2 classes are assigned via Costanza et al. benefit transfer, locally anchored only to a single Malawi wetland valuation study. No sensitivity analysis, uncertainty bounds, or additional local validation data are supplied for the other eight classes. Because the reward function is defined directly from these fixed coefficients, this assumption is load-bearing for all reported ESV deltas, clustering patterns, and policy responses.
minor comments (3)
- [Abstract] Abstract: Specify which of the nine land-cover classes are modifiable versus fixed.
- [Methods] Methods: Provide implementation details on the contiguity bonus and buffer penalty terms, including any weighting hyperparameters.
- [Results] Results: Include training stability metrics or learning curves to confirm reliable PPO convergence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will make the indicated revisions to improve clarity, robustness, and quantitative support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that 'Results demonstrate that the agent effectively learns to increase total ESV' and describes outcomes including 'homogeneous land-use clustering and slight forest consolidation near water bodies', yet provides no quantitative values, tables, figures, error bars, baseline comparisons, or statistical metrics. This absence prevents any assessment of effect sizes or reliability of the central claims.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report specific effect sizes (e.g., percentage ESV increase relative to the initial allocation), mention baseline comparisons, and reference the figures that display spatial patterns and clustering metrics. Corresponding numerical values, error bars, and statistical summaries will be added to the Results section to allow readers to evaluate reliability. revision: yes
-
Referee: [Methods (ESV assignment)] ESV coefficient assignment (Methods section): ESV coefficients for the nine Sentinel-2 classes are assigned via Costanza et al. benefit transfer, locally anchored only to a single Malawi wetland valuation study. No sensitivity analysis, uncertainty bounds, or additional local validation data are supplied for the other eight classes. Because the reward function is defined directly from these fixed coefficients, this assumption is load-bearing for all reported ESV deltas, clustering patterns, and policy responses.
Authors: We acknowledge that the fixed ESV coefficients constitute a central modeling assumption. While we selected the Costanza et al. values with the only available local wetland anchor, we agree that sensitivity testing is needed. In the revision we will add a dedicated sensitivity analysis subsection that perturbs the eight non-anchored coefficients across literature-derived ranges, reports resulting ESV deltas and spatial metrics, and supplies uncertainty bounds. This will demonstrate the robustness of the reported outcomes to coefficient variation. revision: yes
Circularity Check
No significant circularity; optimization objective is explicit and externally anchored.
full rationale
The paper defines the reward function directly from imported ESV coefficients (Costanza et al. benefit transfer, locally anchored to one external Malawi wetland study) plus explicit spatial bonuses/penalties. The PPO agent is trained to maximize this reward, so reported ESV increases and spatial patterns are the direct consequence of successful optimization rather than an independent derivation. No equations reduce a claimed prediction to a fitted input by construction, no self-citations are load-bearing, and no ansatz or uniqueness claim is smuggled in. The framework is self-contained against its stated objective; external validity of the ESV coefficients is a separate assumption risk, not a circularity issue.
Axiom & Free-Parameter Ledger
free parameters (1)
- ESV coefficients
axioms (2)
- domain assumption Benefit transfer methodology produces usable local ESV estimates
- domain assumption Spatial contiguity and buffer penalties correctly capture ecological coherence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The reward function combines per-cell ecological value with spatial coherence objectives: contiguity bonuses... and buffer zone penalties... V(s) = V_eco(s) + V_spatial(s)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Biome-specific ESV coefficients are derived via benefit transfer from Costanza et al. and locally anchored to a Malawi wetland valuation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Washington, DC: Island Press, 2005
Millennium Ecosystem Assessment,Ecosystems and Human Well-Being: Synthesis. Washington, DC: Island Press, 2005
work page 2005
-
[2]
The value of the world’s ecosystem services and natural capital,
R. Costanza, R. d’Arge, R. de Groot, S. Farber, M. Grasso, B. Hannon, K. Limburg, S. Naeem, R. V . O’Neill, J. Paruelo, R. G. Raskin, P. Sutton, and M. van den Belt, “The value of the world’s ecosystem services and natural capital,”Nature, vol. 387, pp. 253–260, 1997
work page 1997
-
[3]
Global estimates of the value of ecosystems and their services in monetary units,
R. de Groot, L. Brander, S. van der Ploeg, R. Costanza, F. Bernard, L. Braat, M. Christie, N. Crossman, A. Ghermandi, L. Heinet al., “Global estimates of the value of ecosystems and their services in monetary units,”Ecosystem Services, vol. 1, no. 1, pp. 50–61, 2012
work page 2012
-
[4]
Changes in the global value of ecosystem services,
R. Costanza, R. de Groot, P. Sutton, S. van der Ploeg, S. J. Anderson, I. Kubiszewski, S. Farber, and R. K. Turner, “Changes in the global value of ecosystem services,”Global Environmental Change, vol. 26, pp. 152–158, 2014
work page 2014
-
[5]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 2nd ed. MIT Press, 2018
work page 2018
-
[6]
Spatial planning of urban communities via deep reinforcement learning,
Y . Zheng, Y . Lin, L. Zhao, T. Wu, D. Jin, and Y . Li, “Spatial planning of urban communities via deep reinforcement learning,” vol. 3, no. 9, pp. 748–762. [Online]. Available: https://www.nature. com/articles/s43588-023-00503-5
-
[7]
Urban travel carbon emission mitigation approach using deep reinforcement learning,
J. Shen, F. Zheng, Y . Ma, W. Deng, and Z. Zhang, “Urban travel carbon emission mitigation approach using deep reinforcement learning,” vol. 14, no. 1, p. 27778. [Online]. Available: https: //www.nature.com/articles/s41598-024-79142-3
-
[8]
J. Shen, F. Zheng, T. Chen, W. Deng, A. Bellotti, F. B. Tesema, and E. Lucchi, “Optimizing urban land-use through deep reinforcement learning: A case study in hangzhou for reducing carbon emissions,” vol. 14, no. 12. [Online]. Available: https: //www.mdpi.com/2073-445X/14/12/2368
work page 2073
-
[9]
Effects of habitat fragmentation on biodiversity,
L. Fahrig, “Effects of habitat fragmentation on biodiversity,”Annual Review of Ecology, Evolution, and Systematics, vol. 34, pp. 487–515, 2003
work page 2003
-
[10]
Riparian forests as nutrient filters in agricultural watersheds,
R. Lowrance, R. Todd, J. Fail, O. Hendrickson, R. Leonard, and L. As- mussen, “Riparian forests as nutrient filters in agricultural watersheds,” BioScience, vol. 34, no. 6, pp. 374–377, 1984
work page 1984
-
[11]
ESA WorldCover 10 m 2021 v200,
D. Zanaga, R. Van De Kerchove, D. Daels, W. De Keersmaecker, C. Brockmann, G. Kirches, J. Wevers, O. Cartus, M. Santoro, S. Fritz et al., “ESA WorldCover 10 m 2021 v200,”Zenodo, 2022
work page 2021
-
[12]
MOD16A2 MODIS/Terra Net Evapotranspiration 8-Day L4 Global 500m SIN Grid V061,
S. Running, Q. Mu, M. Zhao, and A. Moreno, “MOD16A2 MODIS/Terra Net Evapotranspiration 8-Day L4 Global 500m SIN Grid V061,” 2021
work page 2021
-
[13]
The economic valuation of Lake Chiuta wetland: A case study of Machinga district,
F. Zuze, “The economic valuation of Lake Chiuta wetland: A case study of Machinga district,” Master’s thesis, University of Malawi, Chancellor College, 2013
work page 2013
-
[14]
Global climate and ecosystem restoration
B. W. Mueller, “Global climate and ecosystem restoration.”
-
[15]
A closer look at invalid action masking in policy gradient algorithms,
S. Huang and S. Onta ˜n´on, “A closer look at invalid action masking in policy gradient algorithms,” inThe International FLAIRS Conference Proceedings, vol. 35, 2022
work page 2022
-
[16]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
work page 2021
-
[17]
Proximal Policy Optimization Algorithms
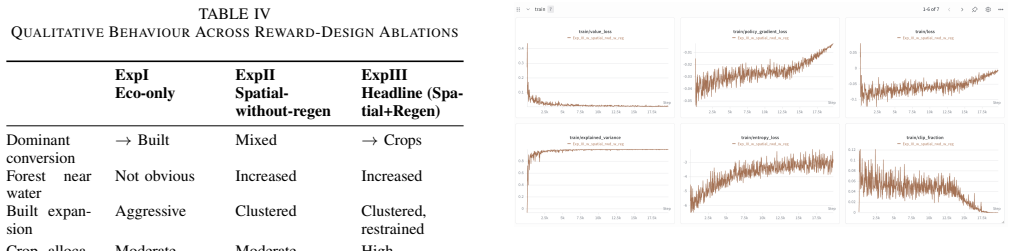
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017. APPENDIXA SCENARIOABLATIONS We report two reward-design ablations alongside the head- line configuration of the main body. Unless noted, all three runs share the same MaskablePPO algorithm, action masks (includ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.