Recognition: 1 theorem link
· Lean TheoremRetrieval Augmented Conversational Recommendation with Reinforcement Learning
Pith reviewed 2026-05-10 20:24 UTC · model grok-4.3
The pith
RAR uses reinforcement learning with LLM feedback to dynamically bridge retrieval and generation in conversational recommender systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
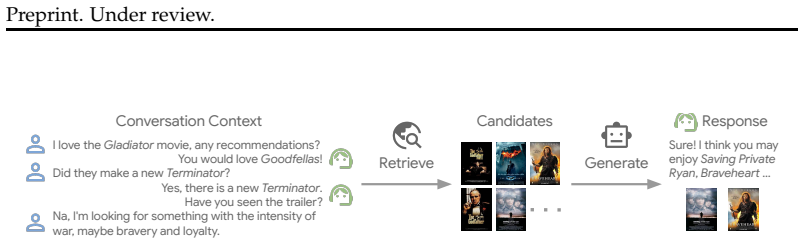
RAR departs from standard two-stage conversational recommender systems by dynamically bridging retrieval and generation stages. A retriever first generates candidate items from user history, then an LLM refines them using conversational context. A novel reinforcement learning approach leverages LLM feedback to iteratively update the retriever by reinforcing candidate sets with higher ranking metrics. This collaborative loop, grounded in a large movie corpus with rich metadata, allows the system to capture subtle user intentions and produce context-aware recommendations with reduced hallucinations.
What carries the argument
The RL feedback loop where LLM evaluations reinforce sampled candidate sets to improve the retriever and align it with the generation stage.
If this is right
- RAR achieves superior performance over state-of-the-art baselines on multiple benchmarks.
- The method mitigates misalignment between retrieval and generation stages.
- Recommendations show reduced hallucinations due to grounding in factual metadata.
- Subtle user intentions are better captured through the iterative RL updates.
Where Pith is reading between the lines
- This approach could be extended to non-movie domains by constructing similar unified corpora for other recommendation areas.
- The RL-driven alignment might improve other retrieval-augmented LLM applications beyond recommendation.
- Long-term user conversations could benefit from the adaptive retriever updates for more personalized results over time.
Load-bearing premise
LLM-generated feedback reliably improves the retriever without introducing new biases or errors, and the movie corpus with benchmarks sufficiently demonstrates the benefits.
What would settle it
Running the full RAR pipeline on the movie benchmarks and finding no gains in ranking metrics or factuality scores compared to baselines, or increased hallucinations in generated recommendations, would disprove the effectiveness of the RL alignment.
Figures




read the original abstract
Large language models (LLMs) exhibit enhanced capabilities in language understanding and generation. By utilizing their embedded knowledge, LLMs are increasingly used as conversational recommender systems (CRS), achieving improved performance across diverse scenarios. However, existing LLM-based methods rely on pretrained knowledge without external retrieval mechanisms for novel items. Additionally, the lack of a unified corpus poses challenges for integrating retrieval augmentation into CRS. Motivated by these challenges, we present RAR, a novel two-stage retrieval augmented conversational recommendation framework that aligns retrieval and generation to enhance both performance and factuality. To support this framework and provide a unified corpus, we construct a large-scale movie corpus, comprising over 300k movies with rich metadata, such as titles, casts and plot summaries. Leveraging this data, our primary contribution is RAR, the first framework to departs from standard two-stage CRS by dynamically bridging retrieval and generation. First, a retriever model generates candidate items based on user history; in the subsequent stage, an LLM refines the recommendations by incorporating conversational context with retrieved results. In addition, we introduce a novel reinforcement learning (RL) method that leverages LLM feedback to iteratively update the retriever. By creating a collaborative feedback loop that reinforces sampled candidate sets with higher ranking metrics, RAR effectively mitigates the misalignment between the retrieval and generation stages. Furthermore, grounding the LLM in factual metadata allows our RL-driven approach to capture subtle user intentions and generate context-aware recommendations with reduced hallucinations. We validate our approach through extensive experiments on multiple benchmarks, where RAR consistently outperforms state-of-the-art baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RAR, a two-stage retrieval-augmented conversational recommender system (CRS) framework. A retriever first generates candidate items from user history; an LLM then refines recommendations using conversational context and retrieved results. A novel RL loop uses LLM feedback to iteratively update the retriever by reinforcing higher-ranking candidate sets, with the goal of aligning the stages and reducing hallucinations via grounding in factual metadata. The authors also construct a large-scale movie corpus (>300k items with titles, casts, and plot summaries) to support the framework and claim that RAR is the first to dynamically bridge retrieval and generation, consistently outperforming SOTA baselines on multiple benchmarks.
Significance. If the empirical results and RL alignment claims hold, the work would be significant for CRS research by showing how RL-driven feedback can mitigate retrieval-generation misalignment and improve factuality in LLM-based systems. The large movie corpus with rich metadata is a clear practical contribution that could serve as a reusable resource for the community.
major comments (2)
- [Abstract] Abstract: The central claim that 'RAR consistently outperforms state-of-the-art baseline methods' and achieves 'reduced hallucinations' is asserted without any quantitative results, specific metrics, baseline names, ablation studies, or error analysis. This leaves the primary empirical validation unsupported by visible evidence and is load-bearing for the paper's contribution.
- [Abstract] Abstract: The RL method is described as using 'LLM feedback to iteratively update the retriever' by 'creating a collaborative feedback loop that reinforces sampled candidate sets with higher ranking metrics,' yet no details are supplied on reward formulation, LLM prompt design for feedback, temperature/consistency controls, or ablations isolating LLM bias effects versus net-positive gains. This assumption is load-bearing for the claim that the loop 'effectively mitigates the misalignment between the retrieval and generation stages.'
minor comments (2)
- [Abstract] Abstract: Grammatical error in 'the first framework to departs from standard two-stage CRS' (should be 'that departs').
- [Abstract] Abstract: The phrase 'extensive experiments on multiple benchmarks' is used without naming the benchmarks, datasets, or even high-level result trends, reducing clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting areas where the abstract could better support our claims. We address each major comment point by point below. We have revised the abstract to incorporate key quantitative highlights and a brief preview of the RL details while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'RAR consistently outperforms state-of-the-art baseline methods' and achieves 'reduced hallucinations' is asserted without any quantitative results, specific metrics, baseline names, ablation studies, or error analysis. This leaves the primary empirical validation unsupported by visible evidence and is load-bearing for the paper's contribution.
Authors: We agree that the abstract, as a high-level summary, would be strengthened by including concrete empirical anchors. The full validation—including specific metrics (e.g., Recall@K and NDCG improvements), named baselines, ablation studies, and hallucination error analysis—is presented with tables and discussion in Section 5. To directly address the concern, we have revised the abstract to reference key quantitative gains and the hallucination reduction observed in our analysis. This change makes the primary claims more self-contained without expanding the abstract beyond standard length. revision: yes
-
Referee: [Abstract] Abstract: The RL method is described as using 'LLM feedback to iteratively update the retriever' by 'creating a collaborative feedback loop that reinforces sampled candidate sets with higher ranking metrics,' yet no details are supplied on reward formulation, LLM prompt design for feedback, temperature/consistency controls, or ablations isolating LLM bias effects versus net-positive gains. This assumption is load-bearing for the claim that the loop 'effectively mitigates the misalignment between the retrieval and generation stages.'
Authors: The reward formulation (ranking-metric improvement as reinforcement signal), LLM prompt templates for feedback, temperature settings for output consistency, and ablations separating LLM bias from net gains are fully specified in Section 4.3 (RL Loop) and evaluated in Section 5. We recognize that the abstract could better preview these elements to support the alignment claim. In revision we have added a concise clause describing the RL feedback mechanism and its role in stage alignment. This provides upfront context while the detailed formulation and ablations remain in the body. revision: yes
Circularity Check
No circularity: empirical RL framework validated on external benchmarks
full rationale
The paper describes a two-stage retrieval-augmented CRS with an RL loop that uses LLM feedback to update the retriever, evaluated on multiple benchmarks after constructing a movie corpus. No derivation chain reduces by construction to its inputs; there are no equations showing fitted parameters renamed as predictions, no self-definitional claims, and no load-bearing self-citations that substitute for independent evidence. The central results are presented as empirical outcomes from training and testing against SOTA baselines, which are external to the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM feedback can serve as a reliable reward signal for updating the retriever in recommendation tasks
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.RealityFromDistinctionwashburn_uniqueness_aczel / reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
novel reinforcement learning (RL) method that leverages LLM feedback to iteratively update the retriever... collaborative feedback loop that reinforces sampled candidate sets with higher ranking metrics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pp.\ 2206--2240. PMLR, 2022
2022
-
[3]
Imdb media
BrightData. Imdb media. https://huggingface.co/datasets/BrightData/IMDb-Media. Accessed: December 2024
2024
-
[4]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M 3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 2318--2335, Bangkok, Tha...
-
[5]
Towards knowledge-based recommender dialog system
Qibin Chen, Junyang Lin, Yichang Zhang, Ming Ding, Yukuo Cen, Hongxia Yang, and Jie Tang. Towards knowledge-based recommender dialog system. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language P...
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
A large language model enhanced conversational recommender system
Yue Feng, Shuchang Liu, Zhenghai Xue, Qingpeng Cai, Lantao Hu, Peng Jiang, Kun Gai, and Fei Sun. A large language model enhanced conversational recommender system. arXiv preprint arXiv:2308.06212, 2023
-
[9]
arXiv preprint arXiv:2303.14524 , year=
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat-rec: Towards interactive and explainable llms-augmented recommender system. arXiv preprint arXiv:2303.14524, 2023
-
[10]
Shortcut learning in deep neural networks
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2 0 (11): 0 665--673, 2020
2020
-
[11]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International conference on machine learning, pp.\ 3929--3938. PMLR, 2020
2020
-
[12]
The movielens datasets: History and context
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis), 5 0 (4): 0 1--19, 2015
2015
-
[13]
Inspired: Toward sociable recommendation dialog systems
Shirley Anugrah Hayati, Dongyeop Kang, Qingxiaoyang Zhu, Weiyan Shi, and Zhou Yu. Inspired: Toward sociable recommendation dialog systems. arXiv preprint arXiv:2009.14306, 2020
-
[14]
Large language models as zero-shot conversational recommenders
Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian McAuley. Large language models as zero-shot conversational recommenders. In Proceedings of the 32nd ACM international conference on information and knowledge management, pp.\ 720--730, 2023
2023
-
[15]
Reindex-then-adapt: Improving large language models for conversational recommendation
Zhankui He, Zhouhang Xie, Harald Steck, Dawen Liang, Rahul Jha, Nathan Kallus, and Julian McAuley. Reindex-then-adapt: Improving large language models for conversational recommendation. arXiv preprint arXiv:2405.12119, 2024
-
[16]
Session-based Recommendations with Recurrent Neural Networks
B Hidasi. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939, 2015
work page internal anchor Pith review arXiv 2015
-
[17]
Building and deploying a multi-stage recommender system with merlin
Karl Higley, Even Oldridge, Ronay Ak, Sara Rabhi, and Gabriel de Souza Pereira Moreira. Building and deploying a multi-stage recommender system with merlin. In Proceedings of the 16th ACM Conference on Recommender Systems, pp.\ 632--635, 2022
2022
-
[18]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Reinforcement Learning via Self-Distillation
Jonas H \"u botter, Frederike L \"u beck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review arXiv 2026
-
[20]
Toward safe and human-aligned game conversational recommendation via multi-agent decomposition
Zheng Hui, Xiaokai Wei, Yexi Jiang, Kevin Gao, Chen Wang, Se-eun Yoon, Rachit Pareek, and Michelle Gong. Toward safe and human-aligned game conversational recommendation via multi-agent decomposition. In Findings of the Association for Computational Linguistics: EACL 2026, pp.\ 4568--4584, 2026
2026
-
[21]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and \'E douard Grave. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp.\ 874--880, 2021
2021
-
[23]
Atlas: Few-shot learning with retrieval augmented language models
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24 0 (251): 0 1--43, 2023
2023
-
[24]
A survey on conversational recommender systems
Dietmar Jannach, Ahtsham Manzoor, Wanling Cai, and Li Chen. A survey on conversational recommender systems. ACM Computing Surveys (CSUR), 54 0 (5): 0 1--36, 2021
2021
-
[25]
Adapting large vision-language models to visually-aware conversational recommendation
Hyunsik Jeon, Satoshi Koide, Yu Wang, Zhankui He, and Julian McAuley. Adapting large vision-language models to visually-aware conversational recommendation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pp.\ 1037--1048, 2025
2025
-
[26]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 7969--7992, 2023
2023
-
[27]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025
work page Pith review arXiv 2025
-
[28]
Recommendation as a communication game: Self-supervised bot-play for goal-oriented dialogue
Dongyeop Kang, Anusha Balakrishnan, Pararth Shah, Paul Crook, Y-Lan Boureau, and Jason Weston. Recommendation as a communication game: Self-supervised bot-play for goal-oriented dialogue. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter...
-
[29]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM), pp.\ 197--206. IEEE, 2018
2018
-
[30]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 6769--6781, 2020
2020
-
[31]
Retrieval-augmented conversational recommendation with prompt-based semi-structured natural language state tracking
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Korikov, and Scott Sanner. Retrieval-augmented conversational recommendation with prompt-based semi-structured natural language state tracking. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.\ 2786--2790, 2024
2024
-
[32]
Estimation-action-reflection: Towards deep interaction between conversational and recommender systems
Wenqiang Lei, Xiangnan He, Yisong Miao, Qingyun Wu, Richang Hong, Min-Yen Kan, and Tat-Seng Chua. Estimation-action-reflection: Towards deep interaction between conversational and recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining, pp.\ 304--312, 2020
2020
-
[33]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33: 0 9459--9474, 2020
2020
-
[34]
Incorporating external knowledge and goal guidance for llm-based conversational recommender systems
Chuang Li, Yang Deng, Hengchang Hu, Min-Yen Kan, and Haizhou Li. Incorporating external knowledge and goal guidance for llm-based conversational recommender systems. arXiv preprint arXiv:2405.01868, 2024
-
[35]
Towards deep conversational recommendations
Raymond Li, Samira Ebrahimi Kahou, Hannes Schulz, Vincent Michalski, Laurent Charlin, and Chris Pal. Towards deep conversational recommendations. Advances in neural information processing systems, 31, 2018
2018
-
[36]
RA-DIT : Retrieval-augmented dual instruction tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Richard James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, et al. RA-DIT : Retrieval-augmented dual instruction tuning. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[37]
R ev C ore: Review-augmented conversational recommendation
Yu Lu, Junwei Bao, Yan Song, Zichen Ma, Shuguang Cui, Youzheng Wu, and Xiaodong He. R ev C ore: Review-augmented conversational recommendation. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp.\ 1161--1173, Online, August 2021. Association for Computational Li...
-
[38]
Off-policy learning in two-stage recommender systems
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Ji Yang, Minmin Chen, Jiaxi Tang, Lichan Hong, and Ed H Chi. Off-policy learning in two-stage recommender systems. In Proceedings of The Web Conference 2020, pp.\ 463--473, 2020
2020
-
[39]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems, 37: 0 124198--124235, 2024
2024
-
[40]
Simpo: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems, 37: 0 124198--124235, 2025
2025
-
[41]
Asynchronous methods for deep reinforcement learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp.\ 1928--1937. PmLR, 2016
1928
-
[42]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35: 0 27730--27744, 2022
2022
-
[43]
arXiv preprint arXiv:2408.08921 (2024) A CQ-Driven RAG Workflow for Digital Storytelling 19
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey. arXiv preprint arXiv:2408.08921, 2024
-
[44]
The analysis of permutations
Robin L Plackett. The analysis of permutations. Journal of the Royal Statistical Society Series C: Applied Statistics, 24 0 (2): 0 193--202, 1975
1975
-
[45]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36: 0 53728--53741, 2023
2023
-
[46]
Imdb movies dataset based on genre
Chidambara Raju. Imdb movies dataset based on genre. https://www.kaggle.com/datasets/rajugc/imdb-movies-dataset-based-on-genre. Accessed: December 2024
2024
-
[47]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Nils Reimers and Iryna Gurevych. Sentence- BERT : Sentence embeddings using S iamese BERT -networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 3982--399...
-
[49]
RAPTOR : Recursive abstractive processing for tree-organized retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. RAPTOR : Recursive abstractive processing for tree-organized retrieval. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[50]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
REPLUG : Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. REPLUG : Retrieval-augmented black-box language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 8364--8...
2024
-
[53]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Rohan Surana, Junda Wu, Zhouhang Xie, Yu Xia, Harald Steck, Dawen Liang, Nathan Kallus, and Julian McAuley. From reviews to dialogues: Active synthesis for zero-shot llm-based conversational recommender system. arXiv preprint arXiv:2504.15476, 2025
-
[55]
Reinforcement learning: An introduction, volume 1
Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[56]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999
1999
-
[57]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 10014--10037, 2023
2023
-
[58]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022 a
work page internal anchor Pith review arXiv 2022
-
[59]
Towards unified conversational recommender systems via knowledge-enhanced prompt learning
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. Towards unified conversational recommender systems via knowledge-enhanced prompt learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 1929--1937, 2022 b
1929
-
[60]
Train once, deploy anywhere: Matryoshka representation learning for multimodal recommendation
Yueqi Wang, Zhenrui Yue, Huimin Zeng, Dong Wang, and Julian McAuley. Train once, deploy anywhere: Matryoshka representation learning for multimodal recommendation. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 13461--13472, Miami, Florida, USA, November 2024. Associ...
-
[61]
Coral: Collaborative retrieval-augmented large language models improve long-tail recommendation
Junda Wu, Cheng-Chun Chang, Tong Yu, Zhankui He, Jianing Wang, Yupeng Hou, and Julian McAuley. Coral: Collaborative retrieval-augmented large language models improve long-tail recommendation. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp.\ 3391--3401, 2024
2024
-
[62]
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu. Is dpo superior to ppo for llm alignment? a comprehensive study. arXiv preprint arXiv:2404.10719, 2024
-
[63]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review arXiv 2024
-
[64]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Unleashing the retrieval potential of large language models in conversational recommender systems
Ting Yang and Li Chen. Unleashing the retrieval potential of large language models in conversational recommender systems. In Proceedings of the 18th ACM Conference on Recommender Systems, pp.\ 43--52, 2024
2024
-
[67]
Making retrieval-augmented language models robust to irrelevant context
Ori Yoran, Tomer Wolfson, Ori Ram, and Jonathan Berant. Making retrieval-augmented language models robust to irrelevant context. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[68]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Linear recurrent units for sequential recommendation
Zhenrui Yue, Yueqi Wang, Zhankui He, Huimin Zeng, Julian McAuley, and Dong Wang. Linear recurrent units for sequential recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, pp.\ 930--938, 2024 a
2024
-
[70]
Zhenrui Yue, Honglei Zhuang, Aijun Bai, Kai Hui, Rolf Jagerman, Hansi Zeng, Zhen Qin, Dong Wang, Xuanhui Wang, and Michael Bendersky. Inference scaling for long-context retrieval augmented generation. arXiv preprint arXiv:2410.04343, 2024 b
-
[71]
Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. Hybrid latent reasoning via reinforcement learning. arXiv preprint arXiv:2505.18454, 2025
- [72]
-
[73]
Conversational graph-llm reasoning for interactive preference modeling and explainable recommendation, 2025
Gholamreza Zare and P Malekpour Alamdari. Conversational graph-llm reasoning for interactive preference modeling and explainable recommendation, 2025
2025
-
[74]
Variational reasoning over incomplete knowledge graphs for conversational recommendation
Xiaoyu Zhang, Xin Xin, Dongdong Li, Wenxuan Liu, Pengjie Ren, Zhumin Chen, Jun Ma, and Zhaochun Ren. Variational reasoning over incomplete knowledge graphs for conversational recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pp.\ 231--239, 2023
2023
-
[75]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Towards conversational search and recommendation: System ask, user respond
Yongfeng Zhang, Xu Chen, Qingyao Ai, Liu Yang, and W Bruce Croft. Towards conversational search and recommendation: System ask, user respond. In Proceedings of the 27th acm international conference on information and knowledge management, pp.\ 177--186, 2018
2018
-
[77]
Improving conversational recommender systems via knowledge graph based semantic fusion
Kun Zhou, Wayne Xin Zhao, Shuqing Bian, Yuanhang Zhou, Ji-Rong Wen, and Jingsong Yu. Improving conversational recommender systems via knowledge graph based semantic fusion. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pp.\ 1006--1014, 2020
2020
-
[78]
Filter-enhanced mlp is all you need for sequential recommendation
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. Filter-enhanced mlp is all you need for sequential recommendation. In Proceedings of the ACM web conference 2022, pp.\ 2388--2399, 2022
2022
-
[79]
A llm-based controllable, scalable, human-involved user simulator framework for conversational recommender systems
Lixi Zhu, Xiaowen Huang, and Jitao Sang. A llm-based controllable, scalable, human-involved user simulator framework for conversational recommender systems. In Proceedings of the ACM on Web Conference 2025, pp.\ 4653--4661, 2025
2025
-
[80]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.