Recognition: 2 theorem links
· Lean TheoremSelf-Supervised Foundation Model for Calcium-imaging Population Dynamics
Pith reviewed 2026-05-13 18:27 UTC · model grok-4.3
The pith
A self-supervised model pretrained on calcium traces forecasts neural population dynamics better than specialized baselines and adapts to decode behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
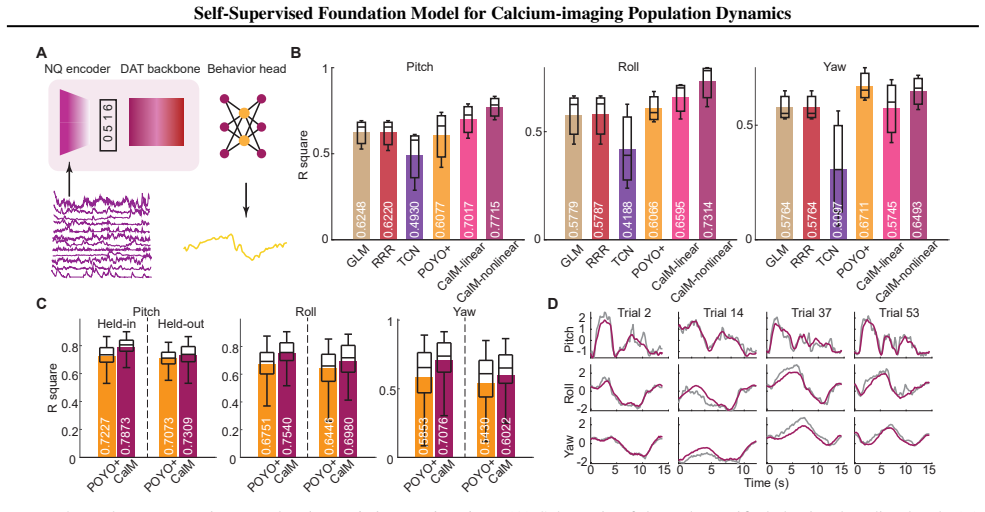
CalM is a self-supervised foundation model for calcium-imaging population dynamics trained solely on neuronal calcium traces. Its pretraining framework consists of a high-performance tokenizer that maps single-neuron traces into a shared discrete vocabulary and a dual-axis autoregressive transformer that models dependencies along both the neural and temporal axes. On the neural population dynamics forecasting task, CalM outperforms strong specialized baselines after pretraining. With a task-specific head, CalM further adapts to the behavior decoding task and achieves superior results compared with supervised decoding models. Linear analyses of CalM representations reveal interpretable func
What carries the argument
Tokenizer mapping single-neuron calcium traces to a shared discrete vocabulary paired with dual-axis autoregressive transformer capturing neural and temporal dependencies
If this is right
- Pretrained CalM outperforms specialized baselines on neural population dynamics forecasting.
- Adding a task-specific head lets CalM decode behavior more accurately than fully supervised models.
- Linear analyses of the representations uncover interpretable functional structures in the neural population.
- The approach supports scalable pretraining for multiple functional neural analysis tasks.
Where Pith is reading between the lines
- Pretrained representations could reduce the amount of labeled data needed for new neuroscience experiments.
- The same backbone might adapt to other recording modalities such as electrophysiology with limited retraining.
- Broad pretraining across animals could capture shared dynamical motifs that generalize across sessions or individuals.
- Foundation-style models may eventually serve as starting points for analyzing many types of population recordings.
Load-bearing premise
The self-supervised pretraining with the tokenizer and dual-axis transformer learns representations that transfer effectively to multiple downstream tasks without requiring extensive task-specific architectural changes or data curation.
What would settle it
If a held-out multi-animal calcium dataset shows that pretrained CalM no longer outperforms baselines on forecasting accuracy or behavior decoding after adding the task head, the claimed transfer benefit would be falsified.
Figures







read the original abstract
Recent work suggests that large-scale, multi-animal modeling can significantly improve neural recording analysis. However, for functional calcium traces, existing approaches remain task-specific, limiting transfer across common neuroscience objectives. To address this challenge, we propose \textbf{CalM}, a self-supervised neural foundation model trained solely on neuronal calcium traces and adaptable to multiple downstream tasks, including forecasting and decoding. Our key contribution is a pretraining framework, composed of a high-performance tokenizer mapping single-neuron traces into a shared discrete vocabulary, and a dual-axis autoregressive transformer modeling dependencies along both the neural and the temporal axis. We evaluate CalM on a large-scale, multi-animal, multi-session dataset. On the neural population dynamics forecasting task, CalM outperforms strong specialized baselines after pretraining. With a task-specific head, CalM further adapts to the behavior decoding task and achieves superior results compared with supervised decoding models. Moreover, linear analyses of CalM representations reveal interpretable functional structures beyond predictive accuracy. Taken together, we propose a novel and effective self-supervised pretraining paradigm for foundation models based on calcium traces, paving the way for scalable pretraining and broad applications in functional neural analysis. Code will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CalM, a self-supervised foundation model for calcium-imaging population dynamics. It consists of a tokenizer that maps single-neuron calcium traces to a shared discrete vocabulary and a dual-axis autoregressive transformer that models dependencies along both neural and temporal axes. Pretrained on a large multi-animal, multi-session dataset, CalM is claimed to outperform specialized baselines on neural population dynamics forecasting; with an added task-specific head it further achieves superior performance on behavior decoding relative to supervised models. Linear probes on the learned representations are said to reveal interpretable functional structures.
Significance. If the performance claims are substantiated with quantitative metrics, error bars, and statistical tests, the work would represent a meaningful step toward scalable, transferable representations for calcium-imaging data, potentially reducing reliance on task-specific architectures in functional neural analysis.
major comments (3)
- [Abstract and §4] Abstract and §4 (Results): the central claims of outperformance on forecasting and decoding are stated without any numerical metrics, error bars, dataset sizes (number of neurons, sessions, animals), ablation results, or statistical tests, preventing evaluation of the reported gains over baselines.
- [§3.2 and §3.3] §3.2 (Tokenizer) and §3.3 (Dual-axis transformer): the discretization thresholds and vocabulary size are listed as free parameters, yet no sensitivity analysis or ablation is provided to show that the claimed transferability does not depend on these choices.
- [§4.2] §4.2 (Behavior decoding): the adaptation with a task-specific head is asserted to surpass supervised decoding models, but no details on the supervised baselines, training regimes, or cross-validation procedure are supplied, leaving the superiority claim unsupported.
minor comments (2)
- [§3.3] Notation for the dual-axis attention is introduced without an explicit equation; adding a compact formulation (e.g., Eq. (X)) would improve clarity.
- [Abstract] The manuscript states 'Code will be released soon' but provides no link or repository; a concrete availability statement is needed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for clarification. We address each major point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): the central claims of outperformance on forecasting and decoding are stated without any numerical metrics, error bars, dataset sizes (number of neurons, sessions, animals), ablation results, or statistical tests, preventing evaluation of the reported gains over baselines.
Authors: We agree that the abstract and narrative in §4 are qualitative. The quantitative results—including specific performance metrics, error bars, dataset statistics (e.g., neuron counts, session and animal numbers), ablation tables, and statistical tests—are provided in the figures and tables of §4. In the revision we will insert the key numerical values and explicit cross-references into the main text of §4 and the abstract to make the gains immediately evaluable. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (Tokenizer) and §3.3 (Dual-axis transformer): the discretization thresholds and vocabulary size are listed as free parameters, yet no sensitivity analysis or ablation is provided to show that the claimed transferability does not depend on these choices.
Authors: The chosen thresholds and vocabulary size were determined via preliminary tuning for reconstruction fidelity and computational tractability. While the manuscript does not contain a dedicated sensitivity study, we recognize that explicit ablations would better support the transferability claim. We will add a new subsection (or appendix) reporting performance across a range of discretization thresholds and vocabulary sizes on the forecasting and decoding tasks. revision: yes
-
Referee: [§4.2] §4.2 (Behavior decoding): the adaptation with a task-specific head is asserted to surpass supervised decoding models, but no details on the supervised baselines, training regimes, or cross-validation procedure are supplied, leaving the superiority claim unsupported.
Authors: We regret the lack of these implementation details. The supervised baselines comprise standard models (linear regression, LSTM, and transformer variants) trained on identical data partitions and with the same cross-validation folds used for CalM. In the revision we will expand §4.2 with explicit descriptions of each baseline architecture, training hyperparameters, optimization settings, and the cross-validation protocol, together with the corresponding performance numbers. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical self-supervised pretraining framework (tokenizer + dual-axis autoregressive transformer) for calcium traces, with performance claims resting on direct comparisons to external specialized baselines on forecasting and decoding tasks. No load-bearing derivation reduces by construction to fitted parameters, self-citations, or self-definitional quantities. The pretraining objective and architecture choices are stated independently of the reported downstream gains, and linear analyses of representations are post-hoc interpretations rather than circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- Tokenizer vocabulary size and discretization thresholds
- Transformer layer count, hidden dimension, and attention heads
axioms (1)
- domain assumption Calcium imaging traces from multiple animals and sessions share common underlying population dynamics that can be captured by self-supervised pretraining.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high-performance vector-quantized (VQ) tokenizer ... dual-axis autoregressive transformer ... autoregressive objective ... CE loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no reference to recognition cost J(x), phi-ladder or 8-tick period
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Bai, S. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y ., L´eonard, N., and Courville, A. Estimating or propagating gradients through stochastic neurons for con- ditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[5]
Duan, Y ., Chaudhry, H. T., Ahrens, M. B., Harvey, C. D., Perich, M. G., Deisseroth, K., and Rajan, K. Poco: Scal- able neural forecasting through population conditioning. arXiv preprint arXiv:2506.14957,
-
[6]
Categorical Reparameterization with Gumbel-Softmax
Jang, E., Gu, S., and Poole, B. Categorical repa- rameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Jolliffe, I. T. and Cadima, J. Principal component analysis: a review and recent developments.Philosophical transac- tions of the royal society A: Mathematical, Physical and Engineering Sciences, 374(2065):20150202,
work page 2065
-
[8]
Linderman, S. W., Miller, A. C., Adams, R. P., Blei, D. M., Paninski, L., and Johnson, M. J. Recurrent switching lin- ear dynamical systems.arXiv preprint arXiv:1610.08466,
-
[9]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Liu, Y ., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., and Long, M. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625,
work page internal anchor Pith review arXiv
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y . A time series is worth 64words: Long-term forecast- ing with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review arXiv
-
[11]
G., Chall´u, C., Garza, A., Canseco, M
Olivares, K. G., Chall´u, C., Garza, A., Canseco, M. M., and Dubrawski, A. NeuralForecast: User friendly state-of- the-art neural forecasting models. PyCon Salt Lake City, Utah, US 2022,
work page 2022
-
[12]
GLU Variants Improve Transformer
Shazeer, N. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[13]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lfads-latent factor analysis via dynamical systems.arXiv preprint arXiv:1608.06315,
Sussillo, D., Jozefowicz, R., Abbott, L., and Pandarinath, C. Lfads-latent factor analysis via dynamical systems.arXiv preprint arXiv:1608.06315,
-
[15]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Xia, J., Zhang, Y ., Wang, S., Allen, G. I., Paninski, L., Hurwitz, C. L., and Miller, K. D. Inpainting the neural picture: Inferring unrecorded brain area dynamics from multi-animal datasets.arXiv preprint arXiv:2510.11924,
-
[17]
arXiv preprint arXiv:2108.01210 , year=
Ye, J. and Pandarinath, C. Representation learning for neural population activity with neural data transformers.arXiv preprint arXiv:2108.01210,
-
[18]
Zhang, Y ., Lyu, H., Hurwitz, C., Wang, S., Findling, C., Wang, Y ., Hubert, F., Pouget, A., Varol, E., and Paninski, L. Exploiting correlations across trials and behavioral sessions to improve neural decoding.Neuron, 2025a. Zhang, Y ., Wang, Y ., Azabou, M., Andre, A., Wang, Z., Lyu, H., Laboratory, T. I. B., Dyer, E., Paninski, L., and Hurwitz, C. Neura...
-
[19]
is added to the traces. St ∼Poisson( tanh (rt) + 1 2 ×dt×λ max)(17) K= exp (− t τr )−exp (− t τca )(18) We generate three sessions using three different random seeds. Each session consists of 400 trials, which are split into training, validation, and test sets with a ratio of 70:15:15. Each trial contains calcium traces from 200 neurons over 100 time step...
work page 2004
-
[20]
Neural activity is represented as a collection of univariate time series
is implemented using the NeuralForecast (Olivares et al., 2022). Neural activity is represented as a collection of univariate time series. PatchTST tokenizes the input sequence into overlapping temporal patches. In our implementation, the patch length is set to 8 time steps with a stride of
work page 2022
-
[21]
We set the model dimension 64 with 4 attention heads and 2 transformer layers
is also implemented using the NeuralForecast framework and follows the same data representation and evaluation protocol as PatchTST. We set the model dimension 64 with 4 attention heads and 2 transformer layers. Dropout is set to 0.1. The model is trained using the Adam optimizer with a learning rate of10 −3. POCO For POCO (Duan et al., 2025), we preproce...
work page 2025
-
[22]
Only the learning rate is adjusted to ensure effective training
on multi-session decoding task, we perform a broad hyperparameter search on a small dataset containing 9 sessions and apply the best hyperparameters to the full 189 pre-train dataset. Only the learning rate is adjusted to ensure effective training. For single session decoding, we perform a grid search on model size, latent step, number of latents and drop...
work page 2079
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.