Recognition: no theorem link
Hierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
Pith reviewed 2026-05-10 18:50 UTC · model grok-4.3
The pith
Hierarchical tokenization breaks SVG strings into atomic elements and geometry-constrained segments so autoregressive models can generate vector graphics with shorter sequences and fewer spatial errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
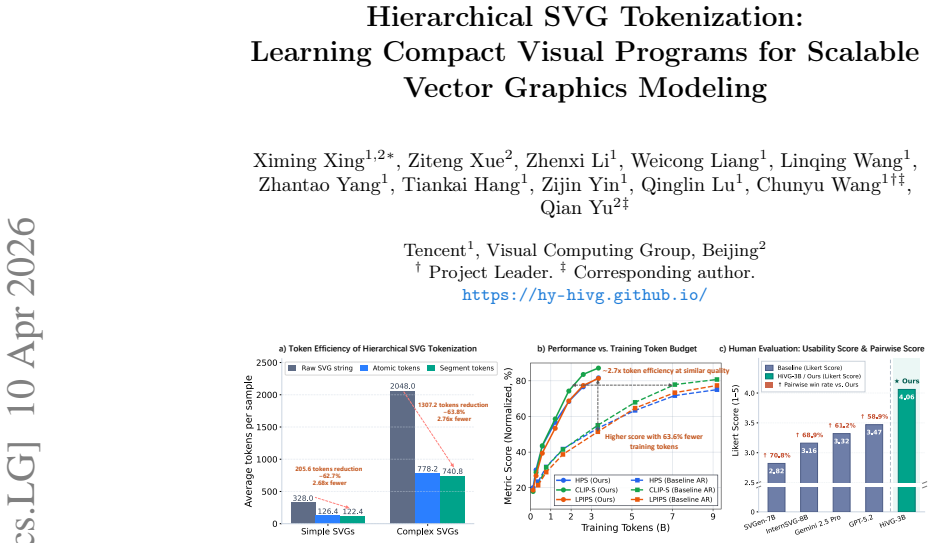
HiVG decomposes raw SVG strings into structured atomic tokens and further compresses executable command-parameter groups into geometry-constrained segment tokens, substantially improving sequence efficiency while preserving syntactic validity. A Hierarchical Mean-Noise initialization strategy injects numerical ordering signals and semantic priors into the new token embeddings. When paired with curriculum training that gradually raises program complexity, the method produces more stable learning of executable SVG programs that outperform conventional tokenization on fidelity, spatial consistency, and length.
What carries the argument
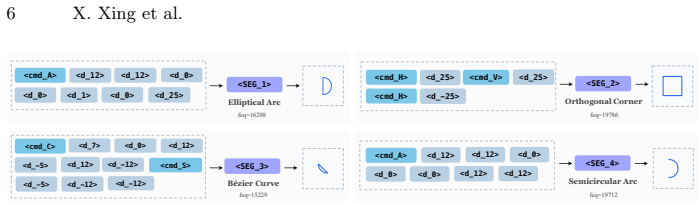
Hierarchical decomposition of SVG into atomic tokens for individual elements and segment tokens for grouped command-parameter sets that respect geometry, plus HMN embedding initialization.
If this is right
- Generated SVG sequences require fewer tokens, which reduces memory and compute during autoregressive sampling.
- Spatial relationships between coordinates are less likely to be hallucinated because segment tokens encode geometric constraints directly.
- Program outputs remain syntactically valid by construction, lowering the rate of invalid drawings.
- Curriculum training stabilizes learning so models can handle increasing program length without collapse.
- Both text-to-SVG and image-to-SVG tasks show higher fidelity than generic tokenization on the same model backbone.
Where Pith is reading between the lines
- The same grouping of commands into constrained segments could apply to other structured output domains such as circuit netlists or molecular graphs where local geometry must stay consistent.
- Because segment tokens carry explicit command semantics, downstream editing tools might modify only part of a generated SVG without regenerating the entire sequence.
- The observed reduction in coordinate hallucination suggests the approach could improve reliability in any autoregressive model that must output precise numeric parameters.
Load-bearing premise
The proposed split into atomic and segment tokens keeps every geometric relationship and syntactic rule from the original SVG without creating mismatches that would require fixes after generation.
What would settle it
On a fixed test set of SVGs, measure both the average number of tokens per valid rendering and the pixel-level difference between generated and reference images; if HiVG sequences are not shorter or the rendering error is higher than byte-level tokenization, the efficiency and fidelity claims do not hold.
Figures








read the original abstract
Recent large language models have shifted SVG generation from differentiable rendering optimization to autoregressive program synthesis. However, existing approaches still rely on generic byte-level tokenization inherited from natural language processing, which poorly reflects the geometric structure of vector graphics. Numerical coordinates are fragmented into discrete symbols, destroying spatial relationships and introducing severe token redundancy, often leading to coordinate hallucination and inefficient long-sequence generation. To address these challenges, we propose HiVG, a hierarchical SVG tokenization framework tailored for autoregressive vector graphics generation. HiVG decomposes raw SVG strings into structured \textit{atomic tokens} and further compresses executable command--parameter groups into geometry-constrained \textit{segment tokens}, substantially improving sequence efficiency while preserving syntactic validity. To further mitigate spatial mismatch, we introduce a Hierarchical Mean--Noise (HMN) initialization strategy that injects numerical ordering signals and semantic priors into new token embeddings. Combined with a curriculum training paradigm that progressively increases program complexity, HiVG enables more stable learning of executable SVG programs. Extensive experiments on both text-to-SVG and image-to-SVG tasks demonstrate improved generation fidelity, spatial consistency, and sequence efficiency compared with conventional tokenization schemes. Our code is publicly available at https://github.com/ximinng/HiVG
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HiVG, a hierarchical SVG tokenization framework for autoregressive vector graphics generation. It decomposes raw SVG strings into atomic tokens and compresses command-parameter groups into geometry-constrained segment tokens to improve sequence efficiency, introduces Hierarchical Mean-Noise (HMN) initialization to inject numerical ordering and semantic priors, and employs a curriculum training paradigm that progressively increases program complexity. Experiments on text-to-SVG and image-to-SVG tasks are reported to yield gains in generation fidelity, spatial consistency, and efficiency relative to conventional byte-level tokenization.
Significance. If the hierarchical decomposition and HMN strategy deliver the claimed efficiency gains without compromising geometric fidelity or syntactic validity, the work would meaningfully advance domain-specific tokenization for structured program synthesis in graphics. The public code release supports reproducibility and follow-up research. The approach of moving beyond generic NLP tokenizers toward geometry-aware representations addresses a recognized bottleneck in LLM-based SVG modeling.
major comments (1)
- Abstract: the claim that segment-token compression 'preserves syntactic validity' and enables 'more stable learning of executable SVG programs' is load-bearing for the central contribution, yet the abstract supplies no quantitative round-trip reconstruction metric (e.g., exact-match rate, coordinate-wise L2 error, or edge-case coverage for high-precision Bézier points and long paths). Without such verification, it remains possible that efficiency improvements trade off against geometric fidelity, directly affecting the validity of the reported fidelity and consistency gains.
minor comments (1)
- The abstract would benefit from explicit mention of the datasets, baseline tokenizers, and primary metrics (e.g., FID, IoU, or sequence-length reduction) used to support the 'improved generation fidelity' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment highlighting the need for quantitative grounding of our central claims in the abstract. We address the point directly below and commit to a targeted revision.
read point-by-point responses
-
Referee: [—] Abstract: the claim that segment-token compression 'preserves syntactic validity' and enables 'more stable learning of executable SVG programs' is load-bearing for the central contribution, yet the abstract supplies no quantitative round-trip reconstruction metric (e.g., exact-match rate, coordinate-wise L2 error, or edge-case coverage for high-precision Bézier points and long paths). Without such verification, it remains possible that efficiency improvements trade off against geometric fidelity, directly affecting the validity of the reported fidelity and consistency gains.
Authors: We agree that the abstract would be strengthened by including a concise quantitative reference to round-trip reconstruction fidelity. While the experimental sections already report generation fidelity, spatial consistency, and validity metrics that depend on correct tokenization (including handling of complex Bézier paths), we will revise the abstract to explicitly note the reconstruction accuracy achieved by the segment tokens. This will directly address the possibility of a fidelity-efficiency trade-off and make the load-bearing claim verifiable at the summary level. revision: yes
Circularity Check
No circularity: novel tokenization and initialization presented as independent construction
full rationale
The paper introduces HiVG as a new hierarchical tokenization that decomposes SVG strings into atomic tokens and geometry-constrained segment tokens, plus HMN embedding initialization and curriculum training. These elements are defined directly by the authors' design rules for preserving syntactic validity and injecting numerical ordering, without any equations, fitted parameters, or predictions that reduce by construction to the target outputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the abstract and description frame the approach as a tailored alternative to generic byte-level tokenization. Effectiveness is asserted via external experiments on text-to-SVG and image-to-SVG tasks rather than internal tautologies. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive transformer models can learn to generate valid executable SVG programs when provided with appropriately structured token sequences.
Reference graph
Works this paper leans on
-
[1]
Anthropic: Claude 4.5 model card (2025),https://www- cdn.anthropic.com/ claude-4-5-model-card.pdf, accessed: 2026-03-04
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Advances in Neural Information Processing Systems33, 16351–16361 (2020)
Carlier, A., Danelljan, M., Alahi, A., Timofte, R.: Deepsvg: A hierarchical gen- erative network for vector graphics animation. Advances in Neural Information Processing Systems33, 16351–16361 (2020)
2020
-
[4]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
DeepSeek-AI: Deepseek-v3.2: Pushing the frontier of open large language models (2025),https://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Language Modeling Is Compression , year =
Delétang, G., Ruoss, A., Duquenne, P.A., Catt, E., Genewein, T., Mattern, C., Grau-Moya, J., Wenliang, L.K., Aitchison, M., Orseau, L., et al.: Language mod- eling is compression. arXiv preprint arXiv:2309.10668 (2023)
-
[7]
In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022)
Frans, K., Soros, L., Witkowski, O.: CLIPDraw: Exploring text-to-drawing syn- thesis through language-image encoders. In: Advances in Neural Information Pro- cessing Systems (NeurIPS) (2022)
2022
-
[8]
arXiv preprint arXiv:2108.04172 (2021)
Ghojogh, B., Ghodsi, A., Karray, F., Crowley, M.: Johnson-lindenstrauss lemma, linear and nonlinear random projections, random fourier features, and random kitchen sinks: Tutorial and survey. arXiv preprint arXiv:2108.04172 (2021)
-
[9]
Google DeepMind: Gemini 3 Pro model card.https://deepmind.google/models/ gemini/pro/(2025), Model Card, December 2025
2025
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13418–13427 (2024)
2024
-
[11]
In: First Conference on Language Modeling (2024),https://openreview.net/ forum?id=SHMj84U5SH
Huang, Y., Zhang, J., Shan, Z., He, J.: Compression represents intelligence linearly. In: First Conference on Language Modeling (2024),https://openreview.net/ forum?id=SHMj84U5SH
2024
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Jain, A., Xie, A., Abbeel, P.: Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 1911–1920 (2023)
1911
-
[13]
Advances in neural information processing systems36, 36652–36663 (2023)
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023)
2023
-
[14]
In: Proceedings of the 2018 conference on empirical methods in natural language processing: System demonstrations
Kudo, T., Richardson, J.: Sentencepiece: A simple and language independent sub- word tokenizer and detokenizer for neural text processing. In: Proceedings of the 2018 conference on empirical methods in natural language processing: System demonstrations. pp. 66–71 (2018)
2018
-
[15]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, J., Yu, J., Wei, C., Dong, H., Lin, Q., Yang, L., Wang, Z., Hao, Y.: Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 13156–13163 (2025)
2025
-
[16]
ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020) 10 X
Li, T.M., Lukáč, M., Gharbi, M., Ragan-Kelley, J.: Differentiable vector graph- ics rasterization for editing and learning. ACM Transactions on Graphics (TOG) 39(6), 1–15 (2020) 10 X. Xing et al
2020
-
[17]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/ forum?id=LBE7HKLQDa
Liu, J., Weng, H., Lei, B., Yang, X., Zhao, Z., Chen, Z., Guo, S., Han, T., Guo, C.: Freemesh: Boosting mesh generation with coordinates merging. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/ forum?id=LBE7HKLQDa
2025
-
[18]
OpenAI: Update to GPT-5 System Card: GPT-5.2.https://openai.com/index/ introducing-gpt-5-2/(2025), System Card, December 2025
2025
-
[19]
Transactions on Machine Learning Research (TMLR) (2024),https://openreview.net/forum? id=a68SUt6zFt
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[20]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747 (2025)
work page internal anchor Pith review arXiv 2025
-
[21]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.5
2026
-
[22]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763. PMLR (2021)
2021
-
[23]
In: Pro- ceedings of the 21st International Conference on Neural Information Processing Systems
Rahimi, A., Recht, B.: Random features for large-scale kernel machines. In: Pro- ceedings of the 21st International Conference on Neural Information Processing Systems. p. 1177–1184. NIPS’07, Curran Associates Inc., Red Hook, NY, USA (2007)
2007
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Rodriguez, J.A., Puri, A., Agarwal, S., Laradji, I.H., Rodriguez, P., Rajeswar, S., Vazquez, D., Pal, C., Pedersoli, M.: Starvector: Generating scalable vector graphics code from images and text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16175–16186 (2025)
2025
-
[25]
A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M
Rodriguez, J.A., Zhang, H., Puri, A., Feizi, A., Pramanik, R., Wichmann, P., Mondal, A., Samsami, M.R., Awal, R., Taslakian, P., et al.: Rendering-aware rein- forcement learning for vector graphics generation. arXiv preprint arXiv:2505.20793 (2025)
-
[26]
com / christophschuhmann/improved-aesthetic-predictor(2022)
Schuhmann, C.: Improved aesthetic predictor.https : / / github . com / christophschuhmann/improved-aesthetic-predictor(2022)
2022
-
[27]
In: Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers)
Sennrich, R., Haddow, B., Birch, A.: Neural machine translation of rare words with subword units. In: Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers). pp. 1715–1725 (2016)
2016
-
[28]
In: Proceedings of the 41st International Conference on Machine Learning
Tang, Z., Wu, C., Zhang, Z., Ni, M., Yin, S., Liu, Y., Yang, Z., Wang, L., Liu, Z., Li, J., Duan, N.: Strokenuwa: tokenizing strokes for vector graphic synthesis. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[29]
In: Artificial Intelligence in Music, Sound, Art and Design
Tian,Y.,Ha,D.:Modernevolutionstrategiesforcreativity:Fittingconcreteimages and abstract concepts. In: Artificial Intelligence in Music, Sound, Art and Design. pp. 275–291. Springer (2022)
2022
-
[30]
ACM Transactions on Graphics (TOG)41(4), 1–11 (2022) Hierarchical SVG Tokenization 11
Vinker, Y., Pajouheshgar, E., Bo, J.Y., Bachmann, R.C., Bermano, A.H., Cohen- Or, D., Zamir, A., Shamir, A.: Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG)41(4), 1–11 (2022) Hierarchical SVG Tokenization 11
2022
-
[31]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang,F.,Zhao,Z.,Liu,Y.,Zhang,D.,Gao,J.,Sun,H.,Li,X.:Svgen:Interpretable vector graphics generation with large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9608–9617 (2025)
2025
-
[32]
arXiv preprint arXiv:2510.11341 (2025)
Wang, H., Yin, J., Wei, Q., Zeng, W., Gu, L., Ye, S., Gao, Z., Wang, Y., Zhang, Y., Li, Y., et al.: Internsvg: Towards unified svg tasks with multimodal large language models. arXiv preprint arXiv:2510.11341 (2025)
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, S., Chen, C., Le, X., Xu, Q., Xu, L., Zhang, Y., Yang, J.: Cad-gpt: Syn- thesising cad construction sequence with spatial reasoning-enhanced multimodal llms. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7880–7888 (2025)
2025
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, R., Su, W., Liao, J.: Chat2svg: Vector graphics generation with large language models and image diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23690–23700 (2025)
2025
-
[35]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review arXiv 2023
-
[36]
Xing, X., Guan, Y., Zhang, J., Xu, D., Yu, Q.: Reason-svg: Hybrid reward rl for aha-moments in vector graphics generation. arXiv preprint arXiv:2505.24499 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xing, X., Hu, J., Liang, G., Zhang, J., Xu, D., Yu, Q.: Empowering llms to un- derstand and generate complex vector graphics. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19487–19497 (2025)
2025
-
[38]
SVGFusion: A VAE-Diffusion Transformer for Vector Graphic Generation
Xing, X., Hu, J., Zhang, J., Xu, D., Yu, Q.: Svgfusion: Scalable text-to-svg gener- ation via vector space diffusion. arXiv preprint arXiv:2412.10437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023)
Xing, X., Wang, C., Zhou, H., Zhang, J., Yu, Q., Xu, D.: Diffsketcher: Text guided vector sketch synthesis through latent diffusion models. Advances in Neural Infor- mation Processing Systems36, 15869–15889 (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xing, X., Zhou, H., Wang, C., Zhang, J., Xu, D., Yu, Q.: Svgdreamer: Text guided svg generation with diffusion model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4546–4555 (2024)
2024
-
[41]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[42]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al.: Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025b
Yang, Y., Cheng, W., Chen, S., Zeng, X., Yin, F., Zhang, J., Wang, L., Yu, G., Ma, X., Jiang, Y.G.: Omnisvg: A unified scalable vector graphics generation model. arXiv preprint arXiv:2504.06263 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.