Recognition: no theorem link
SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
Pith reviewed 2026-05-10 20:16 UTC · model grok-4.3
The pith
SVAgent improves long video question answering by having agents collaboratively construct an evolving storyline instead of selecting isolated frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
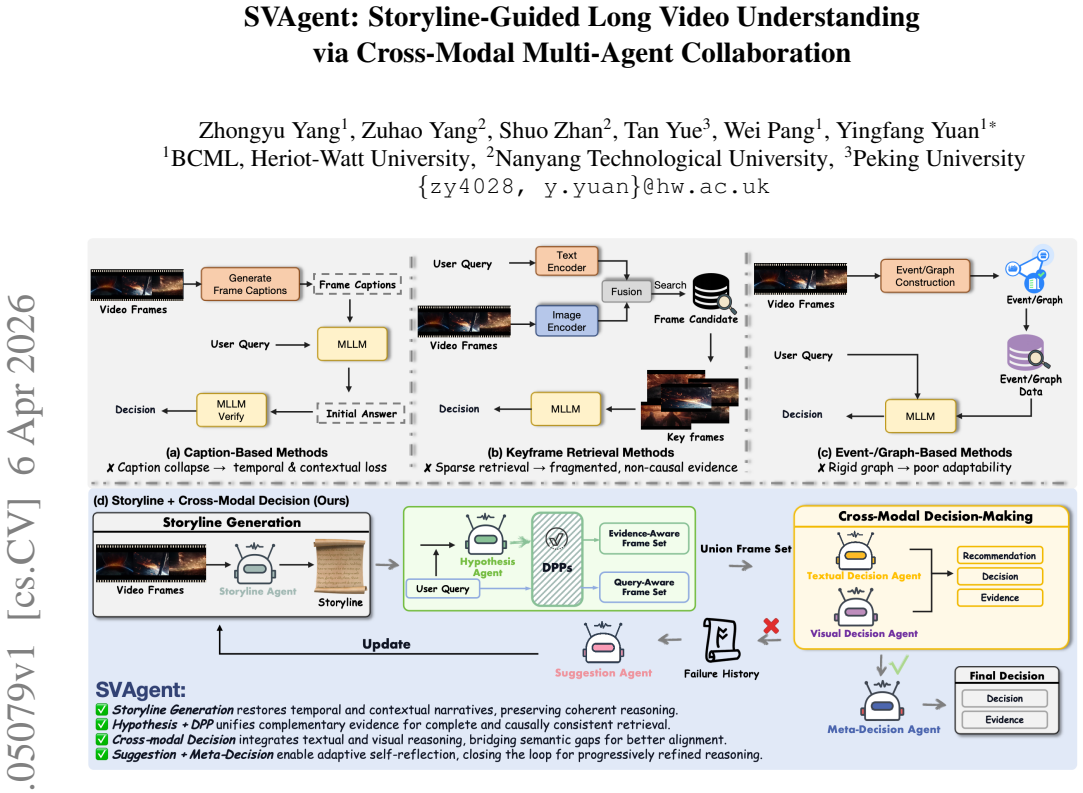
SVAgent is a storyline-guided cross-modal multi-agent framework for VideoQA. The storyline agent progressively constructs a narrative representation based on frames suggested by a refinement suggestion agent that analyzes historical failures. In addition, cross-modal decision agents independently predict answers from visual and textual modalities under the guidance of the evolving storyline. Their outputs are then evaluated by a meta-agent to align cross-modal predictions and enhance reasoning robustness and answer consistency. Experimental results demonstrate that SVAgent achieves superior performance and interpretability by emulating human-like storyline reasoning in video understanding.
What carries the argument
A cross-modal multi-agent collaboration system in which a storyline agent builds a progressive narrative, a refinement suggestion agent uses historical failures to propose frames, cross-modal decision agents generate independent visual and textual predictions, and a meta-agent aligns those predictions.
If this is right
- More robust handling of temporal dynamics in long videos through explicit narrative tracking.
- Increased interpretability because the evolving storyline provides an explicit reasoning trace.
- Better answer consistency by reconciling independent visual and textual predictions via the meta-agent.
- Improved performance on VideoQA tasks that require understanding of event sequences rather than isolated moments.
Where Pith is reading between the lines
- The same agent structure could be tested on other sequential multimodal tasks such as audio narration or live event description.
- Failure-driven refinement might be applied more broadly to iterative reasoning loops in agent systems beyond video.
- If the storyline representation can be made explicit and editable, it could support interactive video analysis tools for users.
Load-bearing premise
That the progressive storyline construction by the storyline agent, informed by the refinement suggestion agent's analysis of historical failures, combined with cross-modal alignment by the meta-agent, will produce more robust and contextually grounded predictions than frame-locating methods.
What would settle it
A direct comparison on a long-video QA benchmark where SVAgent is run against standard frame-locating baselines and shows no measurable gain in answer accuracy, consistency, or human-judged interpretability.
Figures



read the original abstract
Video question answering (VideoQA) is a challenging task that requires integrating spatial, temporal, and semantic information to capture the complex dynamics of video sequences. Although recent advances have introduced various approaches for video understanding, most existing methods still rely on locating relevant frames to answer questions rather than reasoning through the evolving storyline as humans do. Humans naturally interpret videos through coherent storylines, an ability that is crucial for making robust and contextually grounded predictions. To address this gap, we propose SVAgent, a storyline-guided cross-modal multi-agent framework for VideoQA. The storyline agent progressively constructs a narrative representation based on frames suggested by a refinement suggestion agent that analyzes historical failures. In addition, cross-modal decision agents independently predict answers from visual and textual modalities under the guidance of the evolving storyline. Their outputs are then evaluated by a meta-agent to align cross-modal predictions and enhance reasoning robustness and answer consistency. Experimental results demonstrate that SVAgent achieves superior performance and interpretability by emulating human-like storyline reasoning in video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SVAgent, a storyline-guided cross-modal multi-agent framework for VideoQA. A storyline agent progressively builds a narrative representation from frames suggested by a refinement suggestion agent that analyzes historical failures. Cross-modal decision agents generate independent predictions from visual and textual streams under storyline guidance, and a meta-agent aligns these outputs to improve robustness and consistency. The central claim is that this architecture emulates human-like storyline reasoning and thereby delivers superior performance and interpretability relative to frame-locating baselines.
Significance. If the experimental results hold, the work could meaningfully shift VideoQA research toward agent-based, storyline-centric reasoning rather than isolated frame retrieval. The multi-agent decomposition offers a concrete mechanism for incorporating failure-driven refinement and cross-modal alignment, which may improve robustness on long, narratively complex videos and provide a more interpretable reasoning trace than end-to-end models.
major comments (1)
- [Abstract] Abstract: the claim that 'Experimental results demonstrate that SVAgent achieves superior performance and interpretability' is unsupported by any metrics, baselines, datasets, error analysis, or implementation details. This absence is load-bearing for the central assertion of superiority over frame-locating methods.
minor comments (2)
- The roles and interaction protocol among the storyline agent, refinement suggestion agent, cross-modal decision agents, and meta-agent are described at a high level only; a diagram or pseudocode of the message-passing schedule would improve clarity and reproducibility.
- The abstract introduces several new agent names without referencing prior multi-agent VideoQA literature; a brief positioning paragraph would help readers assess novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experimental results demonstrate that SVAgent achieves superior performance and interpretability' is unsupported by any metrics, baselines, datasets, error analysis, or implementation details. This absence is load-bearing for the central assertion of superiority over frame-locating methods.
Authors: We agree that the abstract would be strengthened by including more specific supporting details for the performance claim. While the full manuscript provides quantitative results, dataset descriptions, baseline comparisons (including frame-locating methods), error analyses, and implementation details in the Experiments section, the abstract currently summarizes these at a high level. In the revised version, we will update the abstract to briefly reference the key datasets, the magnitude of improvements over baselines, and the interpretability aspects to better ground the claim of superiority without exceeding length constraints. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes SVAgent as a multi-agent architectural framework for VideoQA, with agents for progressive storyline construction, failure analysis, cross-modal prediction, and meta-alignment. No equations, fitted parameters, self-referential definitions, or mathematical derivations are present in the provided text. Claims of superior performance rest on experimental demonstration rather than any reduction to prior inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are visible. The derivation chain is self-contained as a descriptive system design without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Storyline agent
no independent evidence
-
Refinement suggestion agent
no independent evidence
-
Cross-modal decision agents
no independent evidence
-
Meta-agent
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Script-a-Video: Deep Structured Audio-visual Captions via Factorized Streams and Relational Grounding
MTSS replaces monolithic video captions with factorized streams and relational grounding, yielding reported gains in understanding benchmarks and generation consistency.
Reference graph
Works this paper leans on
-
[1]
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Es- sam Sleiman, Deyao Zhu, Jian Ding, and Mohamed El- hoseiny. Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens. arXiv preprint arXiv:2404.03413, 2024. 2
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning.arXiv preprint arXiv:2310.09478, 2023. 2
-
[4]
Fast greedy map inference for determinantal point process to improve recommendation diversity.Advances in neural information processing systems, 31, 2018
Laming Chen, Guoxin Zhang, and Eric Zhou. Fast greedy map inference for determinantal point process to improve recommendation diversity.Advances in neural information processing systems, 31, 2018. 4
2018
-
[5]
Bring reason to vision: Understanding perception and reasoning through model merging
Shiqi Chen, Jinghan Zhang, Tongyao Zhu, Wei Liu, Siyang Gao, Miao Xiong, Manling Li, and Junxian He. Bring reason to vision: Understanding perception and reasoning through model merging. InForty-second International Conference on Machine Learning, 2025. 3
2025
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[8]
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding.arXiv preprint arXiv:2403.11481, 2024. 2
-
[9]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever compre- hensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[10]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
M-llm based video frame selection for effi- cient video understanding
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, et al. M-llm based video frame selection for effi- cient video understanding. InCVPR, 2025. 2
2025
-
[12]
Duo Li, Zuhao Yang, Xiaoqin Zhang, Ling Shao, and Shijian Lu. A comprehensive study on visual token redundancy for discrete diffusion-based multimodal large language models. arXiv preprint arXiv:2511.15098, 2025. 2
-
[13]
Duo Li, Zuhao Yang, Xiaoqin Zhang, Ling Shao, and Shijian Lu. Todre: Effective visual token pruning via token diversity and task relevance.arXiv preprint arXiv:2505.18757, 2025. 2
-
[14]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[15]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InCVPR, 2024. 2
2024
-
[16]
arXiv preprint arXiv:2504.06958 (2025)
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning.arXiv preprint arXiv:2504.06958, 2025
-
[17]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual represen- tation by alignment before projection.arXiv preprint arXiv:2311.10122, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[18]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 2
2024
-
[19]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024. 2
2024
-
[20]
Xuyang Liu, Xiyan Gui, Yuchao Zhang, and Linfeng Zhang. Mixing importance with diversity: Joint optimization for kv cache compression in large vision-language models.arXiv preprint arXiv:2510.20707, 2025. 2
-
[21]
Video compression commander: Plug-and-play inference ac- celeration for video large language models
Xuyang Liu, Yiyu Wang, Junpeng Ma, and Linfeng Zhang. Video compression commander: Plug-and-play inference ac- celeration for video large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1910–1924, 2025. 2
2025
-
[22]
Xuyang Liu, Zichen Wen, Shaobo Wang, Junjie Chen, Zhis- han Tao, Yubo Wang, Tailai Chen, Xiangqi Jin, Chang Zou, Yiyu Wang, et al. Shifting ai efficiency from model-centric to data-centric compression.arXiv preprint arXiv:2505.19147,
-
[23]
Global compression commander: Plug- and-play inference acceleration for high-resolution large vision-language models
Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, and Honggang Chen. Global compression commander: Plug- and-play inference acceleration for high-resolution large vision-language models. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 7350–7358, 2026. 2
2026
-
[24]
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. Videomind: A chain-of-lora agent for long video reasoning.arXiv preprint arXiv:2503.13444,
-
[25]
arXiv preprint arXiv:2306.07207 , year=
Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Minghui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability. arXiv preprint arXiv:2306.07207, 2023. 2
-
[27]
Yongdong Luo, Xiawu Zheng, Xiao Yang, Guilin Li, Haojia Lin, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, and Rongrong Ji. Video-rag: Visually-aligned retrieval- augmented long video comprehension.arXiv preprint arXiv:2411.13093, 2024. 5
-
[28]
Gpt-4o system card, 2024
OpenAI. Gpt-4o system card, 2024. 5
2024
-
[29]
Yi-Xing Peng, Qize Yang, Yu-Ming Tang, Shenghao Fu, Kun-Yu Lin, Xihan Wei, and Wei-Shi Zheng. Ac- tionart: Advancing multimodal large models for fine- grained human-centric video understanding.arXiv preprint arXiv:2504.18152, 2025. 2
-
[30]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 7
2021
-
[31]
Videorag: Retrieval-augmented generation with extreme long-context videos, 2025
Xubin Ren, Lingrui Xu, Long Xia, Shuaiqiang Wang, Dawei Yin, and Chao Huang. Videorag: Retrieval-augmented gen- eration with extreme long-context videos.arXiv preprint arXiv:2502.01549, 2025. 2
-
[32]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Bal- akrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoor- thi, Mohamed Elhoseiny, and Vikas Chandra. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv pr...
-
[33]
Vgent: Graph-based retrieval-reasoning- augmented generation for long video understanding
Xiaoqian Shen, Wenxuan Zhang, Jun Chen, and Mo- hamed Elhoseiny. Vgent: Graph-based retrieval-reasoning- augmented generation for long video understanding. InThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems, 2025. 2, 5
2025
-
[34]
Video understanding with large language models: A survey.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Sys- tems for Video Technology, 2025. 3
2025
-
[35]
Qwen3-vl system card, 2025
Qwen Team. Qwen3-vl system card, 2025. 5
2025
-
[36]
Qwen3-vl
Qwen3-VL Team. Qwen3-vl. https : / / qwen . ai / blog ? id = 99f0335c4ad9ff6153e517418d48535ab6d8afef& from = research . latest - advancements - list,
-
[37]
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian- 1: A fully open, vision-centric exploration of multimodal llms.arXiv preprint arXiv:2406.16860, 2024. 2
-
[38]
Alvarez, Lei Zhang, and Zhiding Yu
Shihao Wang, Guo Chen, De-An Huang, Zhiqi Li, Minghan Li, Guilin Liu, Jose M. Alvarez, Lei Zhang, and Zhiding Yu. Videoitg: Multimodal video understanding with instructed temporal grounding.arXiv preprint arXiv:2507.13353,
-
[39]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiao- han Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, et al. Lvbench: An extreme long video understanding benchmark. InICCV, 2025. 6
2025
-
[40]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understand- ing with large language model as agent.arXiv preprint arXiv:2403.10517, 2024. 2, 6
-
[41]
Yiyu Wang, Xuyang Liu, Xiyan Gui, Xinying Lin, Boxue Yang, Chenfei Liao, Tailai Chen, and Linfeng Zhang. Ac- celerating streaming video large language models via hierar- chical token compression.arXiv preprint arXiv:2512.00891,
-
[42]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2025
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2025. 6
2025
-
[43]
Vca: Video curious agent for long video un- derstanding
Zeyuan Yang, Delin Chen, Xueyang Yu, Maohao Shen, and Chuang Gan. Vca: Video curious agent for long video un- derstanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20168–20179, 2025. 3
2025
-
[44]
Wikiautogen: Towards multi-modal wikipedia- style article generation
Zhongyu Yang, Jun Chen, Dannong Xu, Junjie Fei, Xiao- qian Shen, Liangbing Zhao, Chun-Mei Feng, and Mohamed Elhoseiny. Wikiautogen: Towards multi-modal wikipedia- style article generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15532–15541, 2025. 2
2025
-
[45]
MERMAID: Multi-perspective self- reflective agents with generative augmentation for emotion recognition
Zhongyu Yang, Junhao Song, Siyang Song, Wei Pang, and Yingfang Yuan. MERMAID: Multi-perspective self- reflective agents with generative augmentation for emotion recognition. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24650–24666, Suzhou, China, 2025. Association for Com- putational Linguistics. 2
2025
-
[46]
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Bo Li, Chengwei Qin, Shijian Lu, Xingxuan Li, et al. Longvt: Incentivizing” thinking with long videos” via native tool calling.arXiv preprint arXiv:2511.20785, 2025. 2
-
[47]
Script: Graph-structured and query-conditioned semantic to- ken pruning for multimodal large language models.Trans- actions on Machine Learning Research, 2025
Zhongyu Yang, Dannong Xu, Wei Pang, and Yingfang Yuan. Script: Graph-structured and query-conditioned semantic to- ken pruning for multimodal large language models.Trans- actions on Machine Learning Research, 2025. 2
2025
-
[48]
Timeexpert: An expert-guided video llm for video temporal grounding
Zuhao Yang, Yingchen Yu, Yunqing Zhao, Shijian Lu, and Song Bai. Timeexpert: An expert-guided video llm for video temporal grounding. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 24286–24296, 2025. 2
2025
-
[49]
Xr: Cross-modal agents for composed image retrieval.arXiv preprint arXiv:2601.14245, 2026
Zhongyu Yang, Wei Pang, and Yingfang Yuan. Xr: Cross-modal agents for composed image retrieval.ArXiv, abs/2601.14245, 2026. 2
-
[50]
Inex: Hallucination mitigation via introspec- tion and cross-modal multi-agent collaboration, 2026
Zhongyu Yang, Yingfang Yuan, Xuanming Jiang, Baoyi An, and Wei Pang. Inex: Hallucination mitigation via introspec- tion and cross-modal multi-agent collaboration, 2026. 2
2026
-
[51]
Think with videos for agentic long-video understanding, 2025
Huaying Yuan, Zheng Liu, Junjie Zhou, Hongjin Qian, Yan Shu, Nicu Sebe, Ji-Rong Wen, and Zhicheng Dou. Think with videos for agentic long-video understanding, 2025. 2
2025
-
[52]
Sigmoid loss for language image pre-training,
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training,
-
[53]
Long-clip: Unlocking the long-text capa- bility of clip
Beichen Zhang, Pan Zhang, Xiao wen Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capa- bility of clip. InEuropean Conference on Computer Vision,
- [54]
-
[55]
OmAgent: A multi-modal agent framework for complex video understanding with task divide-and-conquer
Lu Zhang, Tiancheng Zhao, Heting Ying, Yibo Ma, and Kyu- song Lee. OmAgent: A multi-modal agent framework for complex video understanding with task divide-and-conquer. InProceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 10031–10045, Miami, Florida, USA, 2024. Association for Computational Linguistics. 2
2024
-
[56]
Q-frame: Query-aware frame selection and multi- resolution adaptation for video-llms
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-frame: Query-aware frame selection and multi- resolution adaptation for video-llms. InICCV, 2025. 2
2025
-
[57]
Deep video discovery: Agentic search with tool use for long-form video understanding
Xiaoyi Zhang, Zhaoyang Jia, Zongyu Guo, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Deep video discovery: Agentic search with tool use for long-form video understanding. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 2
2025
-
[58]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 2
work page Pith review arXiv 2024
-
[59]
LLaV A-video: Video instruction tuning with synthetic data.Transactions on Machine Learn- ing Research, 2025
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun MA, Zi- wei Liu, and Chunyuan Li. LLaV A-video: Video instruction tuning with synthetic data.Transactions on Machine Learn- ing Research, 2025. 5
2025
-
[60]
arXiv preprint arXiv:2501.15111 , year=
Jiaxing Zhao, Qize Yang, Yixing Peng, Detao Bai, Shimin Yao, Boyuan Sun, Xiang Chen, Shenghao Fu, Xihan Wei, Liefeng Bo, et al. Humanomni: A large vision-speech lan- guage model for human-centric video understanding.arXiv preprint arXiv:2501.15111, 2025. 2
-
[61]
Zhuo Zhi, Qiangqiang Wu, Minghe Shen, Wenbo Li, Yinchuan Li, Kun Shao, and Kaiwen Zhou. Videoa- gent2: Enhancing the llm-based agent system for long- form video understanding by uncertainty-aware cot.ArXiv, abs/2504.04471, 2025. 2
-
[62]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv preprint arXiv:2406.04264,
work page internal anchor Pith review arXiv
-
[63]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[64]
Videotree: Adaptive tree- based video representation for llm reasoning on long videos,
Wang Ziyang, Yu Shoubin, Stengel-Eskin Elias, Yoon Jae- hong, Cheng Feng, Bertasius Gedas, and Bansal Mohit. Videotree: Adaptive tree-based video representation for llm reasoning on long videos.arXiv preprint arXiv:2405.19209,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.