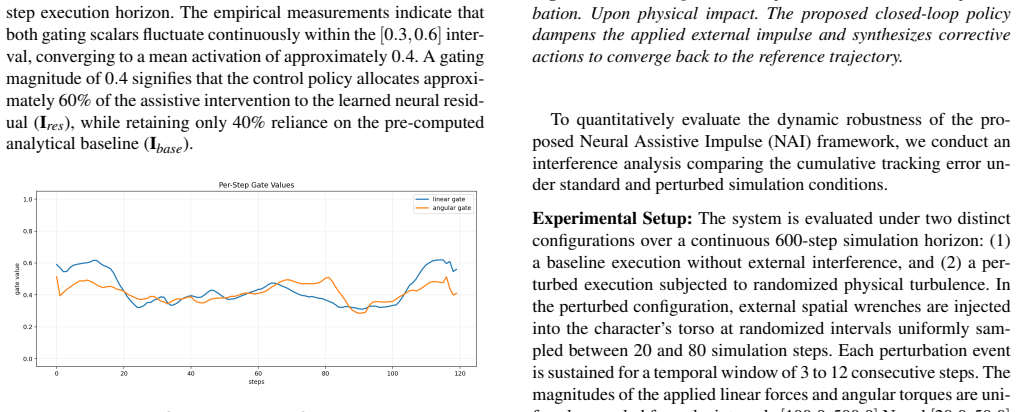
Recognition: no theorem link
Neural Assistive Impulses: Synthesizing Exaggerated Motions for Physics-based Characters
Pith reviewed 2026-05-10 19:20 UTC · model grok-4.3
The pith
Reformulating external assistance as impulses, split into an analytic high-frequency inverse-dynamics term and a learned low-frequency residual, lets physics-based characters stably track exaggerated motions that violate physical laws.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that reformulating external assistance in impulse space rather than force space, and decomposing it into an analytic high-frequency inverse-dynamics component together with a learned low-frequency residual correction under a hybrid neural policy, produces stable policy convergence and allows robust tracking of highly agile, dynamically infeasible maneuvers in physics-based character animation.
What carries the argument
Assistive Impulse Neural Control: the decomposition of assistance into an analytic high-frequency inverse-dynamics component plus a learned low-frequency residual governed by a hybrid neural policy.
Load-bearing premise
Reformulating assistance in impulse space and decomposing it into an analytic high-frequency inverse-dynamics component plus a learned low-frequency residual will produce stable policy convergence without introducing visible artifacts or reducing motion quality.
What would settle it
Running the hybrid policy on a test case of an instantaneous dash or mid-air trajectory change and checking whether velocity discontinuities still produce non-convergent high-magnitude impulses or visible artifacts in the resulting motion.
Figures











read the original abstract
Physics-based character animation has become a fundamental approach for synthesizing realistic, physically plausible motions. While current data-driven deep reinforcement learning (DRL) methods can synthesize complex skills, they struggle to reproduce exaggerated, stylized motions, such as instantaneous dashes or mid-air trajectory changes, which are required in animation but violate standard physical laws. The primary limitation stems from modeling the character as an underactuated floating-base system, in which internal joint torques and momentum conservation strictly govern motion. Direct attempts to enforce such motions via external wrenches often lead to training instability, as velocity discontinuities produce sparse, high-magnitude force spikes that prevent policy convergence. We propose Assistive Impulse Neural Control, a framework that reformulates external assistance in impulse space rather than force space to ensure numerical stability. We decompose the assistive signal into an analytic high-frequency component derived from Inverse Dynamics and a learned low-frequency residual correction, governed by a hybrid neural policy. We demonstrate that our method enables robust tracking of highly agile, dynamically infeasible maneuvers that were previously intractable for physics-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Assistive Impulse Neural Control for physics-based character animation. It reformulates external assistance in impulse space to ensure numerical stability and decomposes the assistive signal into an analytic high-frequency component derived from inverse dynamics plus a learned low-frequency residual correction governed by a hybrid neural policy. The central claim is that this enables robust tracking of highly agile, dynamically infeasible maneuvers (e.g., instantaneous dashes or mid-air trajectory changes) that were previously intractable for standard DRL methods due to training instability from sparse high-magnitude force spikes.
Significance. If the result holds, the work would represent a meaningful advance in physics-based character animation and DRL control. The impulse-space reformulation combined with the hybrid analytic-learned decomposition addresses a persistent instability issue when enforcing exaggerated motions that violate momentum conservation or underactuation constraints. This could enable more expressive animations while preserving simulator plausibility and may generalize to other hybrid control problems involving discontinuities.
major comments (2)
- [§3.2] §3.2 (hybrid decomposition): The central stability argument rests on the assumption that the analytic high-frequency inverse-dynamics term fully absorbs all velocity-discontinuity spikes, leaving only smooth low-frequency residuals for the learned policy. No derivation, frequency-domain bound, or verification under discretization/model mismatch is provided to confirm the split is exact; if imperfect, the residual can still receive destabilizing signals, recreating the original convergence problem. This is load-bearing for the robust-tracking claim.
- [§4] §4 (experiments): The positive demonstration of tracking infeasible maneuvers is presented without quantitative metrics (e.g., tracking error, success rate, or convergence statistics), ablation studies on the frequency split or impulse reformulation, or comparisons to baselines such as direct force assistance. Without these, the claim that the method enables previously intractable motions cannot be verified.
minor comments (2)
- [Abstract] Abstract: The description of the hybrid neural policy could briefly note the network architecture or observation space to improve immediate clarity for readers.
- [Introduction] Notation: Impulse and wrench variables are introduced without an early equation defining their relationship to standard force/torque terms, which may slow readers unfamiliar with the reformulation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have prepared revisions to the manuscript that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (hybrid decomposition): The central stability argument rests on the assumption that the analytic high-frequency inverse-dynamics term fully absorbs all velocity-discontinuity spikes, leaving only smooth low-frequency residuals for the learned policy. No derivation, frequency-domain bound, or verification under discretization/model mismatch is provided to confirm the split is exact; if imperfect, the residual can still receive destabilizing signals, recreating the original convergence problem. This is load-bearing for the robust-tracking claim.
Authors: We agree that the manuscript would be strengthened by a more explicit justification of the frequency decomposition. In the revised version we will add a derivation in §3.2 that shows how the inverse-dynamics term analytically accounts for instantaneous velocity jumps (via the impulse-momentum relation), leaving a continuous residual. We will also include empirical verification consisting of power-spectrum plots of the assistive signals and additional simulation experiments that quantify residual high-frequency content under discretization and model mismatch. revision: yes
-
Referee: [§4] §4 (experiments): The positive demonstration of tracking infeasible maneuvers is presented without quantitative metrics (e.g., tracking error, success rate, or convergence statistics), ablation studies on the frequency split or impulse reformulation, or comparisons to baselines such as direct force assistance. Without these, the claim that the method enables previously intractable motions cannot be verified.
Authors: We concur that the experimental section requires additional quantitative support. The revised manuscript will report mean tracking error, success rates over multiple random seeds, and training convergence statistics. We will add ablation studies that isolate the impulse-space reformulation from direct force assistance and that vary the frequency split. Direct baseline comparisons against force-space assistance will also be included to demonstrate improved stability and tracking performance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new framework (Assistive Impulse Neural Control) that reformulates assistance in impulse space and introduces a hybrid decomposition into an analytic high-frequency inverse-dynamics term plus a learned low-frequency residual policy. The abstract and method sketch present this as an original contribution to stabilize tracking of dynamically infeasible motions. No load-bearing step reduces a claimed result or prediction to its own inputs by construction, self-definition, fitted-parameter renaming, or self-citation chains; the central claims rest on the introduced reformulation and decomposition rather than re-expressing prior fitted quantities or external theorems as internal outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION fin.entry.original add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 i...
-
[2]
Agarap A. F. : Deep learning using rectified linear units (relu), 2019. URL: https://arxiv.org/abs/1803.08375, http://arxiv.org/abs/1803.08375 arXiv:1803.08375
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Basset J., B\' e nard P., Barla P. : Smear: Stylized motion exaggeration with art-direction. In ACM SIGGRAPH 2024 Conference Papers (New York, NY, USA, 2024), SIGGRAPH '24, Association for Computing Machinery. URL: https://doi.org/10.1145/3641519.3657457, https://doi.org/10.1145/3641519.3657457 doi:10.1145/3641519.3657457
-
[4]
: Generalized biped walking control
Coros S., Beaudoin P., van de Panne M. : Generalized biped walking control. In ACM SIGGRAPH 2010 papers on - SIGGRAPH '10 (New York, New York, USA, 2010), ACM Press
2010
-
[5]
: C·ASE : Learning conditional adversarial skill embeddings for physics-based characters
Dou Z., Chen X., Fan Q., Komura T., Wang W. : C·ASE : Learning conditional adversarial skill embeddings for physics-based characters. In SIGA 2023 (2023)
2023
-
[6]
: Automated learning of muscle-actuated locomotion through control abstraction
Grzeszczuk R., Terzopoulos D. : Automated learning of muscle-actuated locomotion through control abstraction. In Proceedings of the 22nd annual conference on Computer graphics and interactive techniques - SIGGRAPH '95 (New York, New York, USA, 1995), ACM Press, pp. 63--70
1995
-
[7]
: NeuroAnimator : fast neural network emulation and control of physics-based models
Grzeszczuk R., Terzopoulos D., Hinton G. : NeuroAnimator : fast neural network emulation and control of physics-based models. In Proceedings of the 25th annual conference on Computer graphics and interactive techniques - SIGGRAPH '98 (New York, New York, USA, 1998), ACM Press
1998
-
[8]
: Learning agile and dynamic motor skills for legged robots
Hwangbo J., Lee J., Dosovitskiy A., Bellicoso D., Tsounis V., Koltun V., Hutter M. : Learning agile and dynamic motor skills for legged robots. Sci. Robot. 4, 26 (Jan. 2019), eaau5872
2019
-
[9]
Ju E., Won J., Lee J., Choi B., Noh J., Choi M. G. : Data-driven control of flapping flight. ACM Trans. Graph. 32, 5 (Sept. 2013), 1--12
2013
-
[10]
: ViSA : Physics-based virtual stunt actors for ballistic stunts
Kim M., Seo W., Lee S.-H., Won J. : ViSA : Physics-based virtual stunt actors for ballistic stunts. ACM Trans. Graph. 44, 4 (Aug. 2025), 1--15
2025
-
[11]
: Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning
Liu L., Hodgins J. : Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning. ACM Trans. Graph. 37, 4 (Aug. 2018), 1--14
2018
-
[12]
Luh J. Y. S., Walker M. W., Paul R. P. C. : On-line computational scheme for mechanical manipulators. Journal of Dynamic Systems, Measurement, and Control 102, 2 (1980), 69--76
1980
-
[13]
: Sampling-based contact-rich motion control
Liu L., Yin K., van de Panne M., Shao T., Xu W. : Sampling-based contact-rich motion control. ACM Trans. Graph. 29, 4 (July 2010), 1--10
2010
-
[14]
: Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
Makoviychuk V., Wawrzyniak L., Guo Y., Lu M., Storey K., Macklin M., Hoeller D., Rudin N., Allshire A., Handa A., State G. : Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
2021
-
[15]
B., Yang G., Paigwar K., Chen T., Agrawal P
Margolis G. B., Yang G., Paigwar K., Chen T., Agrawal P. : Rapid locomotion via reinforcement learning. arXiv [cs.RO] (May 2022)
2022
-
[16]
Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills
Peng X. B., Abbeel P., Levine S., van de Panne M. : Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph. 37, 4 (July 2018), 143:1--143:14. URL: http://doi.acm.org/10.1145/3197517.3201311, https://doi.org/10.1145/3197517.3201311 doi:10.1145/3197517.3201311
-
[17]
B., Berseth G., van de Panne M
Peng X. B., Berseth G., van de Panne M. : Dynamic terrain traversal skills using reinforcement learning. ACM Trans. Graph. 34, 4 (July 2015), 80:1--80:11. URL: http://doi.acm.org/10.1145/2766910, https://doi.org/10.1145/2766910 doi:10.1145/2766910
-
[18]
Graph.35, 4, Article 133 (July 2016), 11 pages
Peng X. B., Berseth G., van de Panne M. : Terrain-adaptive locomotion skills using deep reinforcement learning. ACM Trans. Graph. 35, 4 (July 2016), 81:1--81:12. URL: http://doi.acm.org/10.1145/2897824.2925881, https://doi.org/10.1145/2897824.2925881 doi:10.1145/2897824.2925881
-
[19]
B., Guo Y., Halper L., Levine S., Fidler S
Peng X. B., Guo Y., Halper L., Levine S., Fidler S. : Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters. ACM Trans. Graph. 41, 4 (July 2022)
2022
-
[20]
Peng X. B., Ma Z., Abbeel P., Levine S., Kanazawa A. : Amp: Adversarial motion priors for stylized physics-based character control. ACM Trans. Graph. 40, 4 (July 2021). URL: http://doi.acm.org/10.1145/3450626.3459670, https://doi.org/10.1145/3450626.3459670 doi:10.1145/3450626.3459670
-
[21]
: TokenHSI : Unified synthesis of physical human-scene interactions through task tokenization
Pan L., Yang Z., Dou Z., Wang W., Huang B., Dai B., Komura T., Wang J. : TokenHSI : Unified synthesis of physical human-scene interactions through task tokenization. arXiv [cs.CV] (Mar. 2025)
2025
-
[22]
On the Spectral Bias of Neural Networks
Rahaman N., Baratin A., Arpit D., Draxler F., Lin M., Hamprecht F. A., Bengio Y., Courville A. : On the spectral bias of neural networks, 2019. URL: https://arxiv.org/abs/1806.08734, http://arxiv.org/abs/1806.08734 arXiv:1806.08734
work page Pith review arXiv 2019
-
[23]
H., Hodgins J
Raibert M. H., Hodgins J. K. : Animation of dynamic legged locomotion. In Proceedings of the 18th annual conference on Computer graphics and interactive techniques (New York, NY, USA, July 1991), ACM
1991
- [24]
-
[25]
K., Pollard N
Safonova A., Hodgins J. K., Pollard N. S. : Synthesizing physically realistic human motion in low-dimensional, behavior-specific spaces. ACM Trans. Graph. 23, 3 (Aug. 2004), 514--521
2004
-
[26]
Silver D., Lever G., Heess N. M. O., Degris T., Wierstra D., Riedmiller M. A. : Deterministic policy gradient algorithms. In International Conference on Machine Learning (2014). URL: https://api.semanticscholar.org/CorpusID:13928442
2014
-
[27]
Trust Region Policy Optimization
Schulman J., Levine S., Moritz P., Jordan M. I., Abbeel P. : Trust region policy optimization, 2017. URL: https://arxiv.org/abs/1502.05477, http://arxiv.org/abs/1502.05477 arXiv:1502.05477
work page Pith review arXiv 2017
-
[28]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman J., Moritz P., Levine S., Jordan M., Abbeel P. : High-dimensional continuous control using generalized advantage estimation, 2018. URL: https://arxiv.org/abs/1506.02438, http://arxiv.org/abs/1506.02438 arXiv:1506.02438
work page internal anchor Pith review arXiv 2018
-
[29]
Proximal Policy Optimization Algorithms
Schulman J., Wolski F., Dhariwal P., Radford A., Klimov O. : Proximal policy optimization algorithms, 2017. URL: https://arxiv.org/abs/1707.06347, http://arxiv.org/abs/1707.06347 arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Tessler C., Kasten Y., Guo Y., Mannor S., Chechik G., Peng X. B. : Calm: Conditional adversarial latent models for directable virtual characters. In ACM SIGGRAPH 2023 Conference Proceedings (New York, NY, USA, 2023), SIGGRAPH '23, Association for Computing Machinery. URL: https://doi.org/10.1145/3588432.3591541, https://doi.org/10.1145/3588432.3591541 doi...
-
[31]
Deep Reinforcement Learning with Double Q-learning
van Hasselt H., Guez A., Silver D. : Deep reinforcement learning with double q-learning, 2015. URL: https://arxiv.org/abs/1509.06461, http://arxiv.org/abs/1509.06461 arXiv:1509.06461
work page Pith review arXiv 2015
-
[32]
Wang Z., Benes B., Qureshi A. H., Mousas C. : Evolution-based shape and behavior co-design of virtual agents. IEEE Transactions on Visualization and Computer Graphics 30, 12 (2024), 7579--7591. https://doi.org/10.1109/TVCG.2024.3355745 doi:10.1109/TVCG.2024.3355745
-
[33]
M., Agrawala M., Cohen M
Wang J., Drucker S. M., Agrawala M., Cohen M. F. : The cartoon animation filter. ACM Trans. Graph. 25, 3 (July 2006), 1169--1173
2006
-
[34]
: Learning body shape variation in physics-based characters
Won J., Lee J. : Learning body shape variation in physics-based characters. ACM Trans. Graph. 38, 6 (Dec. 2019), 1--12
2019
-
[35]
: Aerobatics control of flying creatures via self-regulated learning
Won J., Park J., Lee J. : Aerobatics control of flying creatures via self-regulated learning. In SIGGRAPH Asia 2018 Technical Papers on - SIGGRAPH Asia '18 (New York, New York, USA, 2018), ACM Press
2018
-
[36]
: Physanimator: Physics-guided generative cartoon animation, 2025
Xie T., Zhao Y., Jiang Y., Jiang C. : Physanimator: Physics-guided generative cartoon animation, 2025. URL: https://arxiv.org/abs/2501.16550, http://arxiv.org/abs/2501.16550 arXiv:2501.16550
-
[37]
: Residual force control for agile human behavior imitation and extended motion synthesis
Yuan Y., Kitani K. : Residual force control for agile human behavior imitation and extended motion synthesis. arXiv [cs.RO] (June 2020)
2020
-
[38]
Ye Y., Liu C. K. : Optimal feedback control for character animation using an abstract model. ACM Trans. Graph. 29, 4 (July 2010), 1--9
2010
-
[39]
Yu W., Turk G., Liu C. K. : Learning symmetric and low-energy locomotion. arXiv [cs.LG] (Jan. 2018)
2018
-
[40]
: Mink: Python inverse kinematics based on MuJoCo , Dec
Zakka K. : Mink: Python inverse kinematics based on MuJoCo , Dec. 2025. URL: https://github.com/kevinzakka/mink
2025
-
[41]
Zhang Z., Bashkirov S., Yang D., Shi Y., Taylor M., Peng X. B. : Physics-based motion imitation with adversarial differential discriminators. In SIGGRAPH Asia 2025 Conference Papers (SIGGRAPH Asia '25 Conference Papers) (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.