Recognition: 2 theorem links
· Lean TheoremAn Actor-Critic Framework for Continuous-Time Jump-Diffusion Controls with Normalizing Flows
Pith reviewed 2026-05-10 19:40 UTC · model grok-4.3
The pith
Actor-critic method with time-inhomogeneous q-function and normalizing flows solves jump-diffusion controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the actor-critic framework built on a time-inhomogeneous little q-function and occupation measure yields a policy-gradient representation that accommodates time-dependent drift, volatility, and jump terms, while conditional normalizing flows parameterize the actor to enable expressive non-Gaussian policies with exact likelihood evaluation for entropy regularization and optimization.
What carries the argument
The time-inhomogeneous little q-function paired with conditional normalizing flows for policy parameterization in the actor-critic loop.
Load-bearing premise
The policy-gradient representation derived from the little q-function and occupation measure remains valid and numerically stable when explicit time dependence and jump discontinuities are present, and normalizing flows approximate the optimal policies with negligible error.
What would settle it
Numerical results on the Merton portfolio optimization problem showing large deviation from the known explicit optimal policy under jumps would falsify the accuracy claim.
Figures






read the original abstract
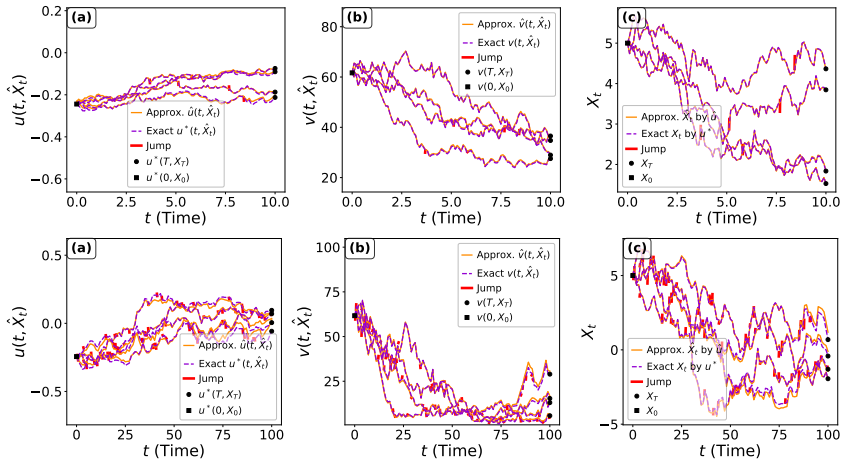
Continuous-time stochastic control with time-inhomogeneous jump-diffusion dynamics is central in finance and economics, but computing optimal policies is difficult under explicit time dependence, discontinuous shocks, and high dimensionality. We propose an actor-critic framework that serves as a mesh-free solver for entropy-regularized control problems and stochastic games with jumps. The approach is built on a time-inhomogeneous little q-function and an appropriate occupation measure, yielding a policy-gradient representation that accommodates time-dependent drift, volatility, and jump terms. To represent expressive stochastic policies in continuous-action spaces, we parameterize the actor using conditional normalizing flows, enabling flexible non-Gaussian policies while retaining exact likelihood evaluation for entropy regularization and policy optimization. We validate the method on time-inhomogeneous linear-quadratic control, Merton portfolio optimization, and a multi-agent portfolio game, using explicit solutions or high-accuracy benchmarks. Numerical results demonstrate stable learning under jump discontinuities, accurate approximation of optimal stochastic policies, and favorable scaling with respect to dimension and number of agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an actor-critic framework for entropy-regularized continuous-time stochastic control and games with time-inhomogeneous jump-diffusion dynamics. It derives a policy-gradient representation from a time-inhomogeneous little q-function and occupation measure, parameterizes stochastic policies via conditional normalizing flows for flexible non-Gaussian actions with exact likelihoods, and reports numerical validation on time-inhomogeneous linear-quadratic control, Merton portfolio optimization, and a multi-agent portfolio game against explicit solutions or benchmarks.
Significance. If the central derivation holds and the numerical claims are substantiated, the work would provide a practical mesh-free solver for high-dimensional jump-diffusion control problems common in finance, with the normalizing-flow actor enabling expressive policies and entropy regularization. The extension to multi-agent games is a positive feature. The approach builds on standard stochastic-control objects without obvious circularity, but its impact depends on rigorous confirmation that the gradient estimator remains unbiased under explicit time dependence and jumps.
major comments (2)
- [Policy-gradient derivation] The policy-gradient representation (derived from the little q-function and occupation measure) must be shown to remain valid under explicit time dependence in the drift, volatility, and jump intensity together with discontinuous jumps. The derivation needs to confirm that the time-inhomogeneous Dynkin formula is applied correctly to both diffusion and jump components of the generator, with no residual boundary or compensator terms in the occupation-measure integral; any tacit assumption of time-homogeneity or Lipschitz continuity violated by the jumps would bias the actor-critic updates.
- [Numerical experiments and validation] The abstract reports validation against explicit solutions or high-accuracy benchmarks on three problems, yet no quantitative error tables, convergence rates, ablation studies, or stability metrics under jump discontinuities are referenced. This absence prevents assessment of whether the observed performance reflects correctness of the representation or implicit regularization effects.
minor comments (2)
- [Abstract] The abstract is information-dense; splitting the contribution list into bullet points would improve readability.
- [Preliminaries] Notation for the little q-function and occupation measure should be introduced with explicit definitions and contrasted with the standard Q-function to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions that will be incorporated to enhance the rigor and clarity of the work.
read point-by-point responses
-
Referee: [Policy-gradient derivation] The policy-gradient representation (derived from the little q-function and occupation measure) must be shown to remain valid under explicit time dependence in the drift, volatility, and jump intensity together with discontinuous jumps. The derivation needs to confirm that the time-inhomogeneous Dynkin formula is applied correctly to both diffusion and jump components of the generator, with no residual boundary or compensator terms in the occupation-measure integral; any tacit assumption of time-homogeneity or Lipschitz continuity violated by the jumps would bias the actor-critic updates.
Authors: We appreciate the referee's emphasis on rigorously establishing the validity of the policy-gradient representation under explicit time dependence and jumps. The derivation in Section 3 applies the time-inhomogeneous Dynkin formula to the little q-function, with the generator explicitly including both the diffusion terms (time-dependent drift and volatility) and the jump component via the compensator of the Poisson random measure. The occupation measure is defined such that boundary and residual compensator terms integrate to zero by construction. Nevertheless, to eliminate any ambiguity regarding regularity conditions or potential tacit assumptions, we will add a dedicated appendix that provides a complete, self-contained derivation. This appendix will step through the application of the Dynkin formula to both continuous and discontinuous parts, verify cancellation of all residual terms in the occupation-measure integral, and state the precise Lipschitz and integrability conditions under which the estimator remains unbiased. We believe this addition will fully address the concern. revision: yes
-
Referee: [Numerical experiments and validation] The abstract reports validation against explicit solutions or high-accuracy benchmarks on three problems, yet no quantitative error tables, convergence rates, ablation studies, or stability metrics under jump discontinuities are referenced. This absence prevents assessment of whether the observed performance reflects correctness of the representation or implicit regularization effects.
Authors: We agree that quantitative metrics are essential for a thorough assessment of the numerical results. While the manuscript presents figures illustrating performance on the time-inhomogeneous LQ control, Merton problem, and multi-agent game, we acknowledge that explicit error tables, convergence rates, ablation studies, and stability metrics under jumps are not included. In the revised manuscript we will add: (i) tables reporting L2 policy errors and value-function errors relative to the explicit solutions or high-accuracy benchmarks for each example; (ii) convergence plots showing the decay of the actor-critic loss and gradient variance; (iii) ablation studies isolating the effects of jump intensity and time-inhomogeneity; and (iv) stability metrics such as the variance of the policy-gradient estimator across runs with varying jump discontinuities. These additions will allow readers to evaluate the method's accuracy and robustness directly. revision: yes
Circularity Check
No circularity: policy-gradient derived from standard objects; normalizing flows are independent parameterization.
full rationale
The paper presents the time-inhomogeneous little q-function and occupation-measure policy gradient as obtained by applying the Dynkin formula to the entropy-regularized objective under jump-diffusion dynamics; this is an explicit derivation from classical stochastic-control identities rather than a re-statement of the target result. Conditional normalizing flows are introduced solely as a flexible, exact-likelihood policy class for continuous actions and entropy terms, with no claim that the optimal policy is defined in terms of the flow architecture. No load-bearing self-citation chain appears; the central representation is not obtained by fitting parameters to the numerical examples or by renaming a known empirical pattern. The validations against explicit LQ solutions and Merton benchmarks therefore constitute external checks rather than tautological confirmation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence and differentiability of a time-inhomogeneous little q-function for the entropy-regularized jump-diffusion control problem.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a continuous-time little q-function, define an appropriate time-dependent occupation measure, and establish its structural properties. This representation leads to a general policy gradient formula...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the β-discounted occupation measure of X_π is defined by μ_π,t,x(A) := E[∫_t^∞ e^{-β(s-t)} 1_{(s,X_π_s)∈A} ds]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Using large language models to automate and expedite reinforcement learning with reward machine
Shayan Meshkat Alsadat, Jean-Rapha ¨el Gaglione, Daniel Neider, Ufuk Topcu, and Zhe Xu. Using large language models to automate and expedite reinforcement learning with reward machine. In2025 American Control Conference (ACC), pages 206–211. IEEE, 2025
2025
-
[2]
Multi-agent reinforcement learning in non-cooperative stochastic games using large language models.IEEE Control Systems Letters, 8:2757–2762, 2024
Shayan Meshkat Alsadat and Zhe Xu. Multi-agent reinforcement learning in non-cooperative stochastic games using large language models.IEEE Control Systems Letters, 8:2757–2762, 2024
2024
-
[3]
Cambridge University Press, 2009
David Applebaum.L ´evy Processes and Stochastic Calculus. Cambridge University Press, 2009
2009
-
[4]
Optimal investment strategies under the relative performance in jump-diffusion markets.Decisions in Economics and Finance, 48(1):179–204, 2025
Burcu Aydo˘gan and Mogens Steffensen. Optimal investment strategies under the relative performance in jump-diffusion markets.Decisions in Economics and Finance, 48(1):179–204, 2025
2025
-
[5]
Neuronlike adaptive elements that can solve difficult learning control problems.IEEE Transactions on Systems, Man, and Cybernetics, (5):834–846, 2012
Andrew G Barto, Richard S Sutton, and Charles W Anderson. Neuronlike adaptive elements that can solve difficult learning control problems.IEEE Transactions on Systems, Man, and Cybernetics, (5):834–846, 2012
2012
-
[6]
Christian Bender and Nguyen Tran Thuan. Entropy-regularized mean-variance portfolio optimization with jumps.arXiv preprint arXiv:2312.13409, 2023
-
[7]
The periodic riccati equation
Sergio Bittanti, Patrizio Colaneri, and Giuseppe De Nicolao. The periodic riccati equation. InThe Riccati Equation, pages 127–162. Springer, 1991. 19
1991
-
[8]
Lijun Bo, Yijie Huang, Xiang Yu, and Tingting Zhang. Continuous-time q-learning for jump-diffusion models under tsallis entropy.arXiv preprint arXiv:2407.03888, 2024
-
[9]
Flowpg: action-constrained policy gradient with normalizing flows.Advances in Neural Information Processing Systems, 36:20118–20132, 2023
Janaka Brahmanage, Jiajing Ling, and Akshat Kumar. Flowpg: action-constrained policy gradient with normalizing flows.Advances in Neural Information Processing Systems, 36:20118–20132, 2023
2023
-
[10]
Wei Cai, Shuixin Fang, Wenzhong Zhang, and Tao Zhou. Martingale deep learning for very high dimensional quasi-linear partial differential equations and stochastic optimal controls.arXiv preprint arXiv:2408.14395, 2024
-
[11]
Deep learning for continuous-time stochastic control with jumps
Patrick Cheridito, Jean-Loup Dupret, and Donatien Hainaut. Deep learning for continuous-time stochastic control with jumps. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[12]
Learning equilibrium mean-variance strategy.Mathematical Finance, 33(4):1166–1212, 2023
Min Dai, Yuchao Dong, and Yanwei Jia. Learning equilibrium mean-variance strategy.Mathematical Finance, 33(4):1166–1212, 2023
2023
-
[13]
Control randomisation approach for policy gradient and application to reinforcement learning in optimal switching.Applied Mathematics & Optimization, 91(1):9, 2025
Robert Denkert, Huyˆen Pham, and Xavier Warin. Control randomisation approach for policy gradient and application to reinforcement learning in optimal switching.Applied Mathematics & Optimization, 91(1):9, 2025
2025
-
[14]
Reinforcement learning in continuous time and space.Neural Computation, 12(1):219–245, 2000
Kenji Doya. Reinforcement learning in continuous time and space.Neural Computation, 12(1):219–245, 2000
2000
-
[15]
Cambridge University Press, Cambridge, 2015
Jinqiao Duan.An Introduction to Stochastic Dynamics. Cambridge University Press, Cambridge, 2015
2015
-
[16]
Neural spline flows.Advances in Neural Information Processing Systems, 32, 2019
Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural spline flows.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[17]
Reinforcement learning for jump-diffusions, with financial applications.Mathematical Finance, 2026
Xuefeng Gao, Lingfei Li, and Xun Yu Zhou. Reinforcement learning for jump-diffusions, with financial applications.Mathematical Finance, 2026
2026
-
[18]
Reinforcement learning for linear-convex models with jumps via stability analysis of feedback controls.SIAM Journal on Control and Optimization, 61(2):755–787, 2023
Xin Guo, Anran Hu, and Yufei Zhang. Reinforcement learning for linear-convex models with jumps via stability analysis of feedback controls.SIAM Journal on Control and Optimization, 61(2):755–787, 2023
2023
-
[19]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[20]
Springer, 1993
Ernst Hairer, Gerhard Wanner, and Syvert P Nørsett.Solving ordinary differential equations I: Nonstiff problems. Springer, 1993
1993
-
[21]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[22]
Yanwei Jia, Du Ouyang, and Yufei Zhang. Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning.arXiv preprint arXiv:2503.09981, 2025
-
[23]
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.Journal of Machine Learning Research, 23(154):1–55, 2022
Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.Journal of Machine Learning Research, 23(154):1–55, 2022. 20
2022
-
[24]
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms.Journal of Machine Learning Research, 23(275):1–50, 2022
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms.Journal of Machine Learning Research, 23(275):1–50, 2022
2022
-
[25]
q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
Yanwei Jia and Xun Yu Zhou. q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
2023
-
[26]
q-learning in continuous time
Yanwei Jia and Xun Yu Zhou. Erratum to “q-learning in continuous time”.Journal of Machine Learning Research, 2025
2025
-
[27]
Chenyang Jiang, Donggyu Kim, Alejandra Quintos, and Yazhen Wang. Robust reinforcement learning under diffusion models for data with jumps.arXiv preprint arXiv:2411.11697, 2024
-
[28]
Multiagent relative investment games in a jump diffusion market with deep reinforcement learning algorithm.SIAM Journal on Financial Mathematics, 16(2):707–746, 2025
Liwei Lu, Ruimeng Hu, Xu Yang, and Yi Zhu. Multiagent relative investment games in a jump diffusion market with deep reinforcement learning algorithm.SIAM Journal on Financial Mathematics, 16(2):707–746, 2025
2025
-
[29]
Robert C. Merton. Optimum consumption and portfolio rules in a continuous-time model.Journal of Economic Theory, 3(4):373–413, 1971
1971
-
[30]
Learning optimal deterministic policies with stochastic policy gradients
Alessandro Montenegro, Marco Mussi, Alberto Maria Metelli, and Matteo Papini. Learning optimal deterministic policies with stochastic policy gradients. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, v...
2024
-
[31]
Springer, 2007
Bernt Øksendal and Agnes Sulem.Applied Stochastic Control of Jump Diffusions, volume 3. Springer, 2007
2007
-
[32]
Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshmi- narayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
2021
-
[33]
Springer Science & Business Media, 2009
Huyˆen Pham.Continuous-Time Stochastic Control and Optimization with Financial Applications, volume 61. Springer Science & Business Media, 2009
2009
-
[34]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[35]
Jordan, and Pieter Abbeel
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. InProceedings of the International Conference on Learning Representations (ICLR), 2016. Poster
2016
-
[36]
Policy gradient methods for reinforcement learning with function approximation.Advances in Neural Information Processing Systems, 12, 1999
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation.Advances in Neural Information Processing Systems, 12, 1999
1999
-
[37]
Making deep q-learning methods robust to time discretization
Corentin Tallec, L´eonard Blier, and Yann Ollivier. Making deep q-learning methods robust to time discretization. InInternational Conference on Machine Learning, pages 6096–6104. PMLR, 2019
2019
-
[38]
Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020. 21
2020
-
[39]
Continuous-time mean–variance portfolio selection: A reinforcement learning framework.Mathematical Finance, 30(4):1273–1308, 2020
Haoran Wang and Xun Yu Zhou. Continuous-time mean–variance portfolio selection: A reinforcement learning framework.Mathematical Finance, 30(4):1273–1308, 2020
2020
-
[40]
Continuous time q-learning for mean-field control problems.Applied Mathematics & Optimization, 91(1):10, 2025
Xiaoli Wei and Xiang Yu. Continuous time q-learning for mean-field control problems.Applied Mathematics & Optimization, 91(1):10, 2025
2025
-
[41]
Policy optimization for continuous reinforcement learning
Hanyang Zhao, Wenpin Tang, and David Yao. Policy optimization for continuous reinforcement learning. Advances in Neural Information Processing Systems, 36:13637–13663, 2023
2023
-
[42]
Mo Zhou, Jiequn Han, and Jianfeng Lu. Actor-critic method for high dimensional static hamilton– jacobi–bellman partial differential equations based on neural networks.SIAM Journal on Scientific Computing, 43(6):A4043–A4066, 2021. A More Numerical Details A.1 Neural Network (NN) Architectures and Experimental Details Critic network.We parameterize the crit...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.