Recognition: 2 theorem links
· Lean TheoremLanG -- A Governance-Aware Agentic AI Platform for Unified Security Operations
Pith reviewed 2026-05-10 19:47 UTC · model grok-4.3
The pith
LanG combines multiple AI security components into one open-source platform that enforces governance policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
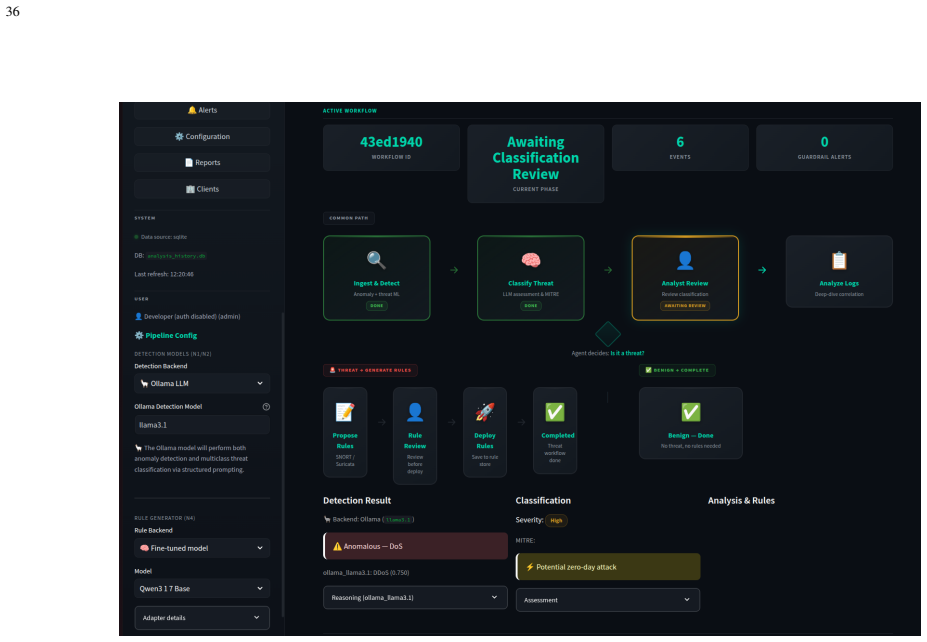
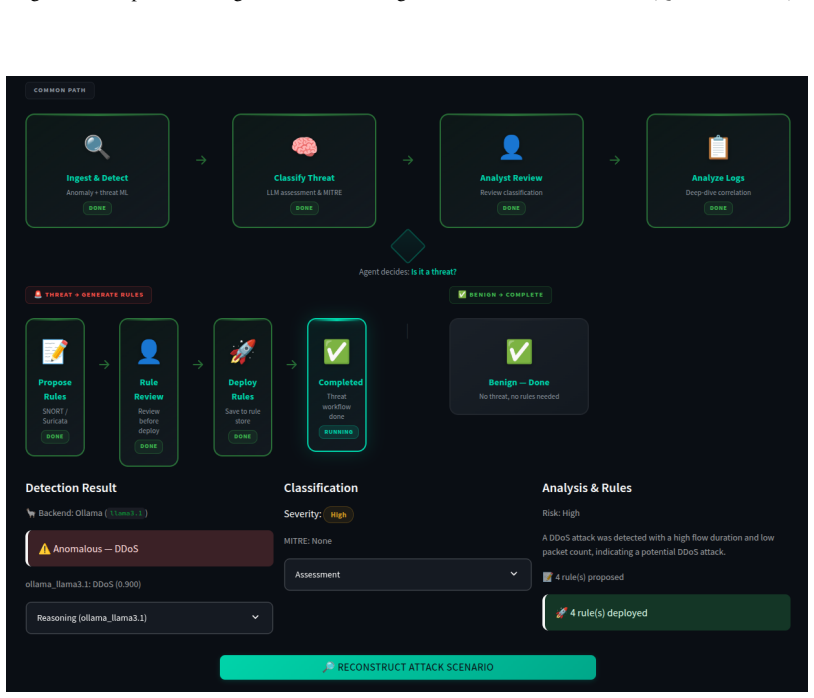
LanG is an open-source governance-aware agentic AI platform for unified security operations that delivers a Unified Incident Context Record with correlation engine, a LangGraph-based orchestrator with human-in-the-loop checkpoints, a fine-tuned LLM rule generator for Snort/Suricata/YARA rules, a three-phase attack reconstructor using Louvain detection and Bayesian scoring, and a layered architecture exposing tools via Model Context Protocol under an AI Governance Policy Engine with a two-layer guardrail pipeline, achieving the listed performance metrics and uniquely meeting multiple SOC requirements in one deployable system.
What carries the argument
The layered Governance-MCP-Agentic AI-Security architecture that governs all components through an AI Governance Policy Engine and a two-layer guardrail pipeline of regex plus semantic classifier.
If this is right
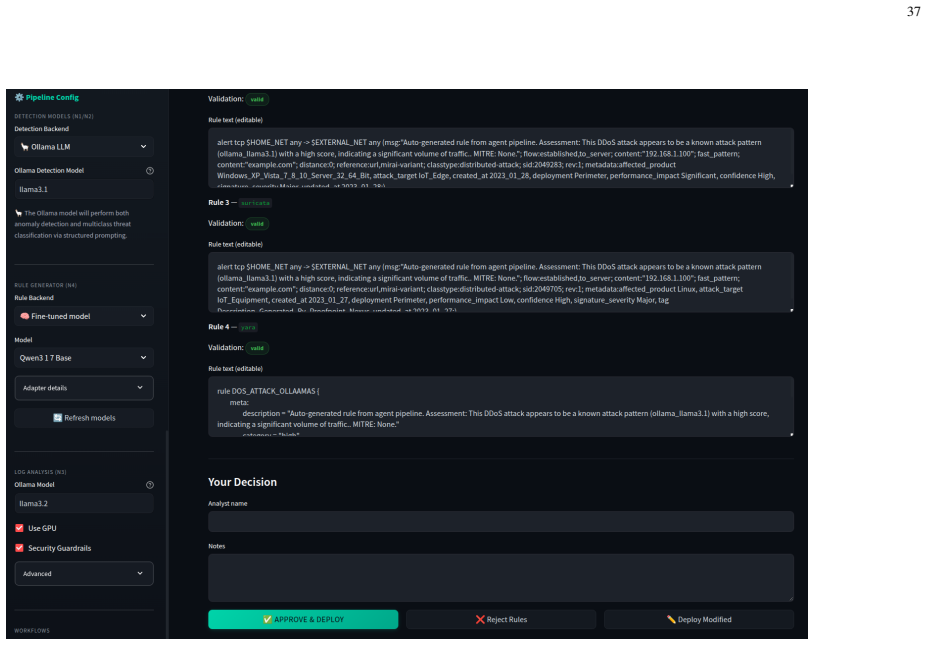
- Generates deployable security rules with 96.2% average acceptance rate across four base models.
- Correlates cross-source events into unified records at 87% F1 score.
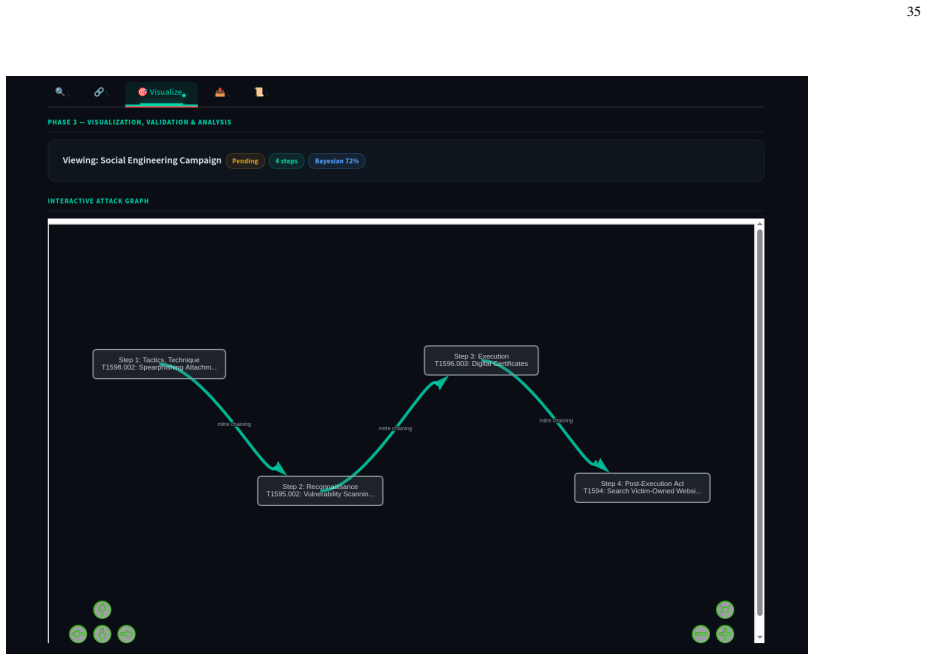
- Reconstructs attack kill-chains at 87.5% accuracy through community detection and Bayesian hypothesis scoring.
- Detects anomalies at 99% weighted F1 and threats at 91% weighted F1 with inference around 21 ms.
- Supports fully local, multi-tenant, role-based deployment for managed security service providers.
Where Pith is reading between the lines
- The human-in-the-loop design could lower barriers to regulated adoption by keeping oversight on AI actions.
- If the guardrails prove robust beyond the tested conditions, the platform could serve as a template for governed AI in other operational domains.
- Open-source availability might enable community testing on diverse network environments to strengthen generalization claims.
- Fast local inference times open the possibility of embedding the system directly on edge security devices.
Load-bearing premise
The reported accuracy, acceptance, and zero false-positive figures will continue to hold when the system encounters real-world adversarial inputs or previously unseen attack patterns.
What would settle it
Deploy the guardrail pipeline and rule generator against a curated set of adversarial prompts or novel attack traces and measure whether false positives appear or rule acceptance falls substantially below 96%.
Figures











read the original abstract
Modern Security Operations Centers struggle with alert fatigue, fragmented tooling, and limited cross-source event correlation. Challenges that current Security Information Event Management and Extended Detection and Response systems only partially address through fragmented tools. This paper presents the LLM-assisted network Governance (LanG), an open-source, governance-aware agentic AI platform for unified security operations contributing: (i) a Unified Incident Context Record with a correlation engine (F1 = 87%), (ii) an Agentic AI Orchestrator on LangGraph with human-in-the-loop checkpoints, (iii) an LLM-based Rule Generator finetuned on four base models producing deployable Snort 2/3, Suricata, and YARA rules (average acceptance rate 96.2%), (iv) a Three-Phase Attack Reconstructor combining Louvain community detection, LLM-driven hypothesis generation, and Bayesian scoring (87.5% kill-chain accuracy), and (v) a layered Governance-MCP-Agentic AI-Security architecture where all tools are exposed via the Model Context Protocol, governed by an AI Governance Policy Engine with a two-layer guardrail pipeline (regex + Llama Prompt Guard 2 semantic classifier, achieving 98.1% F1 score with experimental zero false positives). Designed for Managed Security Service Providers, the platform supports multi-tenant isolation, role-based access, and fully local deployment. Finetuned anomaly and threat detectors achieve weighted F1 scores of 99.0% and 91.0%, respectively, in intrusion-detection benchmarks, running inferences in $\approx$21 ms with a machine-side mean time to detect of 1.58 s, and the rule generator exceeds 91% deployability on live IDS engines. A systematic comparison against eight SOC platforms confirms that LanG uniquely satisfies multiple industrial capabilities all in one open-source tool, while enforcing selected AI governance policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LanG, an open-source governance-aware agentic AI platform for unified security operations addressing SOC challenges like alert fatigue and fragmented tooling. It contributes (i) a Unified Incident Context Record with correlation engine (F1=87%), (ii) an Agentic AI Orchestrator on LangGraph with human-in-the-loop checkpoints, (iii) an LLM-based Rule Generator fine-tuned on four base models yielding 96.2% average acceptance rate for Snort/Suricata/YARA rules, (iv) a Three-Phase Attack Reconstructor using Louvain detection, LLM hypothesis generation, and Bayesian scoring (87.5% kill-chain accuracy), and (v) a layered Governance-MCP-Agentic AI-Security architecture with an AI Governance Policy Engine featuring a two-layer guardrail (regex + Llama Prompt Guard 2) achieving 98.1% F1 with experimental zero false positives. Additional elements include fine-tuned anomaly (99.0% F1) and threat (91.0% F1) detectors with ~21 ms inference and 1.58 s mean time to detect, plus a systematic comparison against eight SOC platforms asserting that LanG uniquely combines multiple industrial capabilities in one open-source tool while enforcing selected AI governance policies. The platform supports multi-tenant isolation, role-based access, and fully local deployment.
Significance. If the reported empirical results are validated with full experimental details, the work would offer a meaningful contribution as an integrated open-source platform that unifies correlation, orchestration, rule generation, attack reconstruction, and governance enforcement for SOC/MSSP use. The open-source availability, emphasis on local deployment, human-in-the-loop design, and explicit comparison to existing platforms are positive aspects that could aid adoption and reproducibility. The governance layer via the two-layer guardrail and Model Context Protocol exposure represents a timely focus on AI safety in security tooling. However, the significance depends heavily on whether the performance claims generalize beyond the (unspecified) test conditions.
major comments (3)
- Abstract: The manuscript reports multiple quantitative results (correlation F1=87%, rule acceptance 96.2%, attack reconstruction 87.5%, guardrail F1=98.1% with zero false positives, anomaly/threat detector F1 scores of 99.0%/91.0%) but supplies no information on datasets, baselines, evaluation protocols, statistical tests, or ablation studies. This omission is load-bearing for the central claims of effectiveness and uniqueness, as it is impossible to determine whether the numbers support the stated conclusions or generalize to real SOC conditions.
- Abstract (governance component): The two-layer guardrail (regex + Llama Prompt Guard 2) is presented as achieving 98.1% F1 'with experimental zero false positives' and is central to the claim that LanG 'uniquely' enforces AI governance policies relative to the eight compared platforms. No details are given on the test inputs (e.g., whether they include adversarial or novel prompts relevant to rule generation and agent actions), so the zero-FP result does not demonstrably transfer to the conditions that matter for the uniqueness assertion.
- Abstract (comparison): The assertion that 'a systematic comparison against eight SOC platforms confirms that LanG uniquely satisfies multiple industrial capabilities all in one open-source tool' is load-bearing for the paper's primary contribution claim, yet no information is provided on the identity of the eight platforms, the precise capabilities evaluated, or the evaluation methodology. Without this, the uniqueness conclusion cannot be assessed.
minor comments (2)
- Abstract: The phrase 'finetuned on four base models' is used without naming the models or describing the fine-tuning data, hyperparameters, or evaluation split, which reduces clarity even though it is not central to the main claims.
- Abstract: The inference time ('≈21 ms') and mean time to detect (1.58 s) are reported without specifying hardware, batch size, or test conditions, which is a minor presentation issue for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments correctly identify areas where the abstract could better support the quantitative claims and contribution statements. We have revised the manuscript to address these points by expanding the abstract and adding supporting details in the main text.
read point-by-point responses
-
Referee: Abstract: The manuscript reports multiple quantitative results (correlation F1=87%, rule acceptance 96.2%, attack reconstruction 87.5%, guardrail F1=98.1% with zero false positives, anomaly/threat detector F1 scores of 99.0%/91.0%) but supplies no information on datasets, baselines, evaluation protocols, statistical tests, or ablation studies. This omission is load-bearing for the central claims of effectiveness and uniqueness, as it is impossible to determine whether the numbers support the stated conclusions or generalize to real SOC conditions.
Authors: We agree that the abstract would be strengthened by including high-level experimental context. In the revised manuscript we have expanded the abstract to reference the primary datasets and benchmarks used for each component, the evaluation protocols (including hold-out testing and cross-validation), and the baselines. We have also added a concise summary of ablation studies and statistical significance testing in the experimental sections to better substantiate the reported metrics. revision: yes
-
Referee: Abstract (governance component): The two-layer guardrail (regex + Llama Prompt Guard 2) is presented as achieving 98.1% F1 'with experimental zero false positives' and is central to the claim that LanG 'uniquely' enforces AI governance policies relative to the eight compared platforms. No details are given on the test inputs (e.g., whether they include adversarial or novel prompts relevant to rule generation and agent actions), so the zero-FP result does not demonstrably transfer to the conditions that matter for the uniqueness assertion.
Authors: We accept that additional information on the guardrail test inputs is required to support the zero false-positive claim under relevant conditions. The revised abstract now notes that the evaluation included adversarial and domain-specific prompts. We have also added a paragraph in the governance section describing the test set composition, including the proportion of adversarial and novel prompts related to rule generation and agent actions, along with the exact evaluation protocol. revision: yes
-
Referee: Abstract (comparison): The assertion that 'a systematic comparison against eight SOC platforms confirms that LanG uniquely satisfies multiple industrial capabilities all in one open-source tool' is load-bearing for the paper's primary contribution claim, yet no information is provided on the identity of the eight platforms, the precise capabilities evaluated, or the evaluation methodology. Without this, the uniqueness conclusion cannot be assessed.
Authors: We acknowledge that the abstract's uniqueness claim would be clearer with a brief indication of the comparison scope. The detailed comparison, including platform identities, evaluated capabilities, and methodology, appears in Section 6. In the revision we have updated the abstract to name the platforms and summarize the capability categories and evaluation approach, while retaining the full analysis in the main text. revision: partial
Circularity Check
No circularity: all reported results are direct empirical measurements with no derivations or self-referential definitions.
full rationale
The paper presents an agentic AI platform and reports performance via benchmark F1 scores, acceptance rates, accuracy figures, and a platform comparison. These are framed as direct experimental outcomes from specific test conditions rather than quantities derived from other fitted parameters or prior self-citations. No equations, ansatzes, uniqueness theorems, or load-bearing self-citations appear in the provided text. The central claims rest on empirical validation and open-source implementation details, remaining independent of any circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-layer guardrail pipeline (regex + Llama Prompt Guard 2 semantic classifier, achieving 98.1% F1 score with experimental zero false positives)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Louvain community detection + Bayesian posterior scoring for attack scenarios
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Decision Evidence Maturity Model for Agentic AI: A Property-Level Method Specification
DEMM defines four executable evidence-sufficiency categories plus a conflicting category for agentic AI decisions and rolls per-property verdicts into a five-level maturity rubric.
Reference graph
Works this paper leans on
-
[1]
A survey on iot security: Application areas, security threats, and solution architectures,
V . Hassija, V . Chamola, V . Saxena, D. Jain, P. Goyal, and B. Sikdar, “A survey on iot security: Application areas, security threats, and solution architectures,”IEEE Access, vol. 7, pp. 82 721–82 743, 2019
2019
-
[2]
Demystifying iot security: An exhaustive survey on iot vulnerabilities and a first empirical look on internet-scale iot exploitations,
N. Neshenko, E. Bou-Harb, J. Crichigno, G. Kaddoum, and N. Ghani, “Demystifying iot security: An exhaustive survey on iot vulnerabilities and a first empirical look on internet-scale iot exploitations,”IEEE Communications Surveys & Tutorials, vol. 21, no. 3, pp. 2702–2733, 2019
2019
-
[3]
Security for 5g and beyond,
I. Ahmad, S. Shahabuddin, T. Kumar, J. Okwuibe, A. Gurtov, and M. Ylianttila, “Security for 5g and beyond,”IEEE Communications Surveys & Tutorials, vol. 21, no. 4, pp. 3682–3722, 2019
2019
-
[4]
Market guide for extended detection and response,
Gartner, “Market guide for extended detection and response,” Gartner Research Report, 2022, accessed: 2026-03-01
2022
-
[5]
A tale of three security operation centers,
S. C. Sundaramurthy, J. Case, T. Truong, L. Zomlot, and M. Hoffmann, “A tale of three security operation centers,” inProceedings of the 2014 ACM Workshop on Security Information Workers, ser. SIW ’14. New York, NY , USA: Association for Computing Machinery, 2014, p. 43–50. [Online]. Available: https://doi.org/10.1145/2663887.2663904
-
[6]
Security information and event management (siem): Analysis, trends, and usage in critical infrastructures,
G. González-Granadillo, S. González-Zarzosa, and R. Diaz, “Security information and event management (siem): Analysis, trends, and usage in critical infrastructures,”Sensors, vol. 21, no. 14, 2021. [Online]. Available: https://www.mdpi.com/1424-8220/21/14/4759
2021
-
[8]
The voice of the SOC ana- lyst report,
Trellix (formerly FireEye/Mandiant), “The voice of the SOC ana- lyst report,” https://www.trellix.com/about/newsroom/stories/research/ xdr-solving-the-soc-analyst-alert-fatigue-problem/, 2023, accessed: 2026-03-01
2023
-
[9]
Matched and mismatched SOCs: A qualitative study on security operations center issues,
F. B. Kokulu, A. Soneji, T. Bao, Y . Shoshitaishvili, Z. Zhao, A. Doupé, and G.-J. Ahn, “Matched and mismatched socs: A qualitative study on security operations center issues,” ser. CCS ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1955–1970. [Online]. Available: https://doi.org/10.1145/3319535.3354239
-
[10]
Security opera- tions center: A systematic study and open challenges,
M. Vielberth, F. Böhm, I. Fichtinger, and G. Pernul, “Security opera- tions center: A systematic study and open challenges,”IEEE Access, vol. 8, pp. 227 756–227 779, 2020
2020
-
[11]
Cost of a data breach report 2025,
Ponemon Institute, “Cost of a data breach report 2025,” https://www. ibm.com/reports/data-breach, 2025, accessed: 2026-02-01
2025
-
[12]
M-Trends 2025: Report,
Mandiant, “M-Trends 2025: Report,”Mandiant Technical Report, 2025, accessed: 2026-01-25. 30
2025
-
[13]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, W. X. Zhao, Z. Wei, and J.-R. Wen, “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[14]
The Rise and Potential of Large Language Model Based Agents: A Survey
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhouet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Y . Talebirad and A. Nadiri, “Multi-agent collaboration: Harnessing the power of intelligent LLM agents,”arXiv preprint arXiv:2306.03314, 2023
-
[16]
Agent ai: Surveying the horizons of multimodal interaction
Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Cho, Y . Nishi, N. Kanezaki, and J. Gao, “Agent AI: Surveying the horizons of multimodal interaction,”arXiv preprint arXiv:2401.03568, 2024
-
[17]
Log parsing with prompt-based few-shot learning,
V .-H. Le and H. Zhang, “Log parsing with prompt-based few-shot learning,” inProceedings of the 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 2438–2449
2023
-
[18]
LILAC: Log parsing using LLMs with adaptive parsing cache,
Z. Jiang, J. Liu, Z. Chen, Y . Li, J. Huang, Y . Huo, P. He, J. Gu, and M. R. Lyu, “LILAC: Log parsing using LLMs with adaptive parsing cache,”Proceedings of the ACM on Software Engineering (FSE), vol. 1, pp. 1–24, 2024
2024
-
[19]
arXiv preprint arXiv:2402.00891 (2024), https://arxiv.org/pdf/2402.00891
F. N. Motlagh, M. Hajizadeh, M. Majd, P. Najafi, F. Cheng, and C. Meinel, “Large language models in cybersecurity: State-of-the-art,” arXiv preprint arXiv:2402.00891, 2024
-
[20]
Li- nids: Llm-based intelligent nids rules generation for cybersecurity applications,
A. Abdennebi, K. Nadjia, L. Lahlou, and H. Ould-Slimane, “Li- nids: Llm-based intelligent nids rules generation for cybersecurity applications,” in2025 16th International Conference on Network of the Future (NoF), 2025, pp. 55–63
2025
-
[21]
SecureBERT: A domain-specific language model for cybersecurity,
E. Aghaei, X. Niu, W. Shadid, and E. Al-Shaer, “SecureBERT: A domain-specific language model for cybersecurity,”Journal of Cyber- security and Privacy, vol. 3, no. 3, pp. 391–414, 2023
2023
-
[22]
CyBERT: Contextualized embeddings for the cybersecurity domain,
P. Ranade, A. Piplai, S. Mittal, A. Joshi, and T. Finin, “CyBERT: Contextualized embeddings for the cybersecurity domain,” in2021 IEEE International Conference on Big Data (Big Data). IEEE, 2021, pp. 3334–3342
2021
-
[23]
SecureFalcon: The next cyber reasoning system for cyber security,
M. A. Ferrag, N. Ndhlovu, N. Tihanyi, L. C. Cordeiro, M. Debbah, and T. Lestable, “SecureFalcon: The next cyber reasoning system for cyber security,”arXiv preprint arXiv:2307.06616, 2023
-
[24]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Code Llama: Open Foundation Models for Code
B. Rozière, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan et al., “Code Llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,” ser. AISec ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 79–90. [Online]. Available: https://doi.org/10.1145/3605764.3623985
-
[27]
Prompt injection attack against LLM-integrated applications,
Y . Liu, G. Deng, Z. Xu, Y . Li, Y . Zheng, Y . Zhang, L. Zhao, T. Zhang, K. Wang, and Y . Liu, “Prompt injection attack against LLM-integrated applications,” inProceedings of the 2024 USENIX Security Symposium, 2024, pp. 1–18
2024
-
[28]
Ignore this title and HackAPrompt: Exposing systemic weaknesses of LLMs through a global scale prompt hacking competition,
S. Schulhoff, J. Pinto, A. Khan, L.-F. Bouchard, C. Si, S. Anati, V . Tagliabue, A. Kost, C. Carnahan, and J. Boyd-Graber, “Ignore this title and HackAPrompt: Exposing systemic weaknesses of LLMs through a global scale prompt hacking competition,” 2023. [Online]. Available: https://aclanthology.org/2023.emnlp-main.302/
2023
-
[29]
Beyond the safeguards: Exploring the security risks of ChatGPT,
E. Derner and K. Batisti ˇc, “Beyond the safeguards: Exploring the security risks of ChatGPT,”arXiv preprint arXiv:2305.08005, 2023
-
[30]
Owasp top 10 for llm apps & gen ai agentic security initiative,
S. John, R. R. F. Del, K. Evgeniy, O. Helen, H. Idan, U. Kayla, H. Ken, S. Peter, A. Rakshith, B. Ronet al., “Owasp top 10 for llm apps & gen ai agentic security initiative,” Ph.D. dissertation, OW ASP, 2025
2025
-
[31]
LLM agents can autonomously hack websites, 2024
R. Fang, R. Bindu, A. Gupta, Q. Zhan, and D. Kang, “LLM agents can autonomously hack websites,” inarXiv preprint arXiv:2402.06664, 2024
-
[32]
J. Xu, J. Nong, E. Vidal, A. Mukherjee, and X. Luo, “AutoAttacker: A large language model guided system to implement automatic cyber- attacks,”arXiv preprint arXiv:2403.01038, 2024
-
[33]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Trans. Inf. Syst., vol. 43, no. 2, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3703155
-
[34]
Regulation 2024/1689 of the eur. parl. council of june 13, 2024 (eu artificial intelligence act),
N. A. Smuha, “Regulation 2024/1689 of the eur. parl. council of june 13, 2024 (eu artificial intelligence act),”International Legal Materials, vol. 64, no. 5, p. 1234–1381, 2025
2024
-
[35]
Artifi- cial intelligence risk management framework (AI RMF 1.0),
National Institute of Standards and Technology, “Artifi- cial intelligence risk management framework (AI RMF 1.0),” https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1. pdf?isid=enterprisehub_us&ikw=enterprisehub_us_lead% 2Fhow-to-responsibly-use-ai-powered-hr-tools_textlink_https%3A% 2F%2Fnvlpubs.nist.gov%2Fnistpubs%2Fai%2FNIST.AI.100-1.pdf, 2023, nIST AI 100-1
2023
-
[36]
The operational role of security information and event management systems,
S. Bhatt, P. K. Manadhata, and L. Zomlot, “The operational role of security information and event management systems,”IEEE Security & Privacy, vol. 12, no. 5, pp. 35–41, 2014
2014
-
[37]
LangGraph: Building stateful multi-agent appli- cations,
LangChain, Inc., “LangGraph: Building stateful multi-agent appli- cations,” https://github.com/langchain-ai/langgraph, 2024, accessed: 2025-10-15
2024
-
[38]
Computer security incident handling guide (SP 800-61 rev. 3),
National Institute of Standards and Technology, “Computer security incident handling guide (SP 800-61 rev. 3),” https://csrc.nist.gov/pubs/ sp/800/61/r3/final, 2024, accessed: 2026-03-01
2024
-
[39]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach et al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review arXiv 2024
-
[40]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 10 088–10 115. [Online]. Available: https://proceedings.neurips.cc/paper_files...
2023
-
[42]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations (ICLR), 2022
2022
-
[43]
Emerging threats open ruleset,
Proofpoint, “Emerging threats open ruleset,” https://rules. emergingthreats.net/, 2024
2024
-
[44]
Fast unfolding of communities in large networks,
V . D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,”Journal of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, p. P10008, 2008
2008
-
[45]
Intelligence- driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains,
E. M. Hutchins, M. J. Cloppert, and R. M. Amin, “Intelligence- driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains,”Leading Issues in Information Warfare & Security Research, vol. 1, no. 1, pp. 80–106, 2011
2011
-
[46]
Constructing attack scenarios through correlation of intrusion alerts,
P. Ning, Y . Cui, and D. S. Reeves, “Constructing attack scenarios through correlation of intrusion alerts,” inProceedings of the 9th ACM Conference on Computer and Communications Security, 2002, pp. 245–254
2002
-
[47]
A systematic survey on multi- step attack detection,
J. Navarro, A. Deruyver, and P. Parrend, “A systematic survey on multi- step attack detection,”Computers & Security, vol. 76, pp. 214–249, 2018
2018
-
[48]
Model context protocol specification,
Anthropic, “Model context protocol specification,” https: //modelcontextprotocol.io/, 2025, accessed: 2025-11-01
2025
-
[49]
Ollama – get up and running with large language models locally,
Ollama, “Ollama – get up and running with large language models locally,” https://ollama.com/, 2024
2024
-
[50]
Streamlit — the fastest way to build and share data apps,
Snowflake Inc., “Streamlit — the fastest way to build and share data apps,” https://streamlit.io/, 2024
2024
-
[51]
A multi-vocal review of security orchestration,
C. Islam, M. A. Babar, and S. Nepal, “A multi-vocal review of security orchestration,”ACM Computing Surveys, vol. 52, no. 2, pp. 1–45, 2019
2019
-
[52]
Could SOAR save the SOC?
R. Brewer, “Could SOAR save the SOC?”Computer Fraud & Security, vol. 2019, no. 9, pp. 8–11, 2019
2019
-
[53]
Splunk SOAR documentation,
Splunk (Cisco), “Splunk SOAR documentation,” https://docs.splunk. com/Documentation/SOAR/current/, 2024, accessed: 2026-03-01
2024
-
[54]
Cortex XSOAR: Security orchestration, au- tomation and response,
Palo Alto Networks, “Cortex XSOAR: Security orchestration, au- tomation and response,” https://docs-cortex.paloaltonetworks.com/r/ Cortex-XSOAR, 2024, accessed: 2026-03-01
2024
-
[55]
Shuffle: Open source SOAR platform,
Shuffle, “Shuffle: Open source SOAR platform,” https://shuffler.io/docs, 2024, accessed: 2026-03-01
2024
-
[56]
CrowdStrike Falcon platform: Endpoint security and XDR,
CrowdStrike, “CrowdStrike Falcon platform: Endpoint security and XDR,” https://www.crowdstrike.com/platform/, 2024, accessed: 2026- 03-01
2024
-
[57]
Microsoft Sentinel: Cloud-native SIEM and SOAR,
Microsoft, “Microsoft Sentinel: Cloud-native SIEM and SOAR,” https: //learn.microsoft.com/en-us/azure/sentinel/overview, 2024, accessed: 2026-03-01
2024
-
[58]
Cortex XSIAM: AI-driven security operations platform,
Palo Alto Networks, “Cortex XSIAM: AI-driven security operations platform,” https://www.paloaltonetworks.com/cortex/cortex-xsiam, 2024, accessed: 2026-03-01. 31
2024
-
[59]
H. Xu, Y . Shi, Z. Zhao, Y . Wang, C. Xiao, B. Xu, J. Cheng, J. Gao, Q. Lin, F. Yang, Y . Qiao, and D. Lu, “Large language models for cyber security: A systematic literature review,”arXiv preprint arXiv:2405.04760, 2024
-
[60]
Revolutionizing cyber threat detection with large language models: A privacy-preserving BERT-based lightweight model for IoT/IIoT devices,
M. A. Ferrag, O. Friha, D. Hamouda, L. Maglaras, and H. Janicke, “Revolutionizing cyber threat detection with large language models: A privacy-preserving BERT-based lightweight model for IoT/IIoT devices,”IEEE Access, vol. 12, pp. 23 733–23 750, 2024
2024
-
[61]
Getting PWNed by AI: Penetration testing with large language models,
A. Happe and J. Cito, “Getting PWNed by AI: Penetration testing with large language models,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 2023, pp. 2082–2086
2023
-
[62]
CyberMetric: A benchmark dataset for evaluating large language models knowledge in cybersecurity,
N. Tihanyi, M. A. Ferrag, R. Jain, T. Bisztray, and M. Debbah, “CyberMetric: A benchmark dataset for evaluating large language models knowledge in cybersecurity,”arXiv preprint arXiv:2402.07688, 2024
-
[63]
Sec-Llama: A com- pact fine-tuned LLM for network intrusion detection in Kubernetes clusters,
A. Abdennebi, N. Kara, and H. Ould-Slimane, “Sec-Llama: A com- pact fine-tuned LLM for network intrusion detection in Kubernetes clusters,” in2025 IEEE International Mediterranean Conference on Communications and Networking (MeditCom). IEEE, 2025, pp. 1–6
2025
-
[64]
Machine learning and large language models-based techniques for cyber threat detection: A comparative study,
——, “Machine learning and large language models-based techniques for cyber threat detection: A comparative study,” in2025 IEEE Inter- national Conference on Cyber Security and Resilience (CSR). IEEE, 2025, pp. 1–8
2025
-
[65]
Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study,
M. A. Ferrag, L. Maglaras, S. Moschoyiannis, and H. Janicke, “Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study,”Journal of Information Security and Applica- tions, vol. 50, p. 102419, 2020
2020
-
[66]
Network intrusion detection system: A systematic study of machine learning and deep learning approaches,
Z. Ahmad, A. Shahid Khan, C. Wai Shiang, J. Abdullah, and F. Ahmad, “Network intrusion detection system: A systematic study of machine learning and deep learning approaches,”Transactions on Emerging Telecommunications Technologies, vol. 32, no. 1, p. e4150, 2021
2021
-
[67]
Kitsune: An ensemble of autoencoders for online network intrusion detection,
Y . Mirsky, T. Doitshman, Y . Elovici, and A. Shabtai, “Kitsune: An ensemble of autoencoders for online network intrusion detection,” arXiv preprint arXiv:1802.09089, 2018
-
[68]
Machine learning and deep learning methods for intrusion detection systems: A survey,
H. Liu and B. Lang, “Machine learning and deep learning methods for intrusion detection systems: A survey,”Applied Sciences, vol. 9, no. 20, p. 4396, 2019
2019
-
[69]
A hybrid intrusion detection system based on sparse autoencoder and deep neural network,
K. Narayana Rao, K. Venkata Rao, and P. R. P.V .G.D., “A hybrid intrusion detection system based on sparse autoencoder and deep neural network,”Computer Communications, vol. 180, pp. 77– 88, 2021. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S0140366421003285
2021
-
[70]
UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set),
N. Moustafa and J. Slay, “UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set),” in2015 Military Communications and Information Systems Conference (MilCIS). IEEE, 2015, pp. 1–6
2015
-
[71]
Toward generating a new intrusion detection dataset and intrusion traffic characterization,
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” Proceedings of the 4th International Conference on Information Sys- tems Security and Privacy (ICISSP), pp. 108–116, 2018
2018
-
[72]
Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy,
I. Sharafaldin, A. Habibi Lashkari, S. Hakak, and A. A. Ghorbani, “Developing realistic distributed denial of service (DDoS) attack dataset and taxonomy,” in2019 International Carnahan Conference on Security Technology (ICCST). IEEE, 2019, pp. 1–8
2019
-
[73]
Generative deep learning to detect cyberattacks for the IoT-23 dataset,
N. Abdalgawad, A. Sajun, Y . Kaddoura, I. A. Zualkernan, and F. Aloul, “Generative deep learning to detect cyberattacks for the IoT-23 dataset,”IEEE Access, vol. 10, pp. 6430–6441, 2022
2022
-
[74]
Event log correlation for multi-step attack detection,
S. U. Shaukat, S. Khan, and S. Parkinson, “Event log correlation for multi-step attack detection,”SECURITY AND PRIVACY, vol. 9, no. 1, p. e70151, 2026. [Online]. Available: https://onlinelibrary.wiley.com/ doi/abs/10.1002/spy2.70151
-
[75]
Snort – network intrusion detection and prevention system,
Cisco Talos, “Snort – network intrusion detection and prevention system,” https://www.snort.org/, 2024
2024
-
[76]
Suricata – open source IDS/IPS/NSM engine,
Open Information Security Foundation (OISF), “Suricata – open source IDS/IPS/NSM engine,” https://suricata.io/, 2024
2024
-
[77]
Y ARA: The pattern matching swiss knife,
V . Alvarez, “Y ARA: The pattern matching swiss knife,” https:// virustotal.github.io/yara/, 2024
2024
-
[78]
Sigma: Generic signature format for SIEM systems,
SigmaHQ, “Sigma: Generic signature format for SIEM systems,” https: //github.com/SigmaHQ/sigma, 2024, accessed: 2026-03-01
2024
-
[79]
Event log correlation for multi-step attack detection,
S. U. Shaukat, S. Khan, and S. Parkinson, “Event log correlation for multi-step attack detection,”Security and Privacy, vol. 9, no. 1, p. e70151, 2026
2026
-
[80]
HOLMES: Real-time APT detection through correlation of suspicious information flows,
S. M. Milajerdi, R. Gjomemo, B. Eshete, R. Sekar, and V . N. Venkatakr- ishnan, “HOLMES: Real-time APT detection through correlation of suspicious information flows,” in2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1137–1152
2019
-
[81]
MITRE ATT&CK: Design and philosophy,
B. E. Strom, A. Applebaum, D. P. Miller, K. C. Nickels, A. G. Pennington, and C. B. Thomas, “MITRE ATT&CK: Design and philosophy,”MITRE Technical Report, pp. 1–30, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.