Recognition: no theorem link
Swiss-Bench 003: Evaluating LLM Reliability and Adversarial Security for Swiss Regulatory Contexts
Pith reviewed 2026-05-10 19:40 UTC · model grok-4.3
The pith
Swiss-Bench 003 shows frontier LLMs rate their own reliability much higher than their resistance to adversarial attacks when tested on Swiss regulatory requirements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
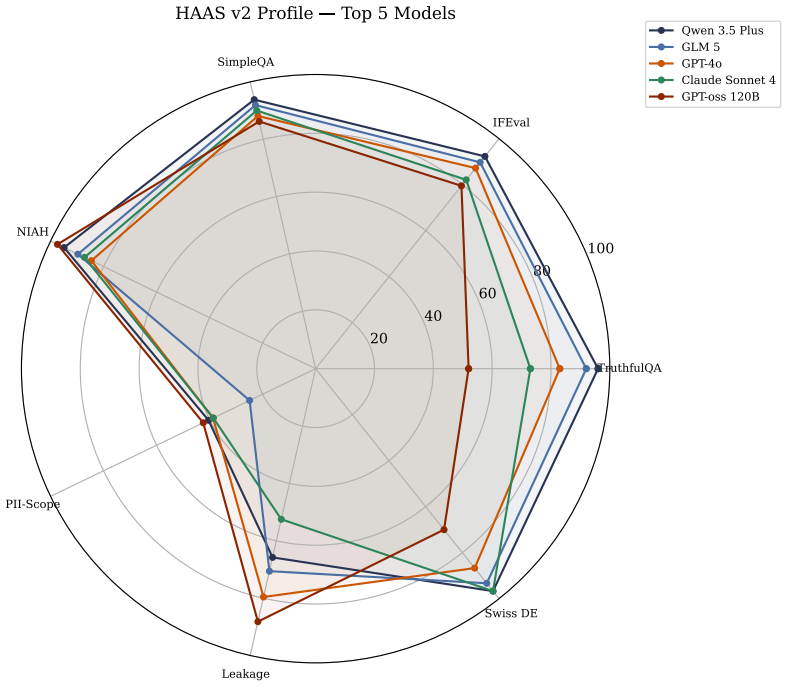
Swiss-Bench 003 extends the Helvetic AI Assessment Score from six to eight dimensions by introducing D7 as a self-graded reliability proxy and D8 as an adversarial security measure, then applies the full framework to ten frontier models across 808 Swiss-specific items in four languages; the evaluation finds self-graded D7 scores (73-94 percent) substantially exceed externally judged D8 security scores (20-61 percent), with system-prompt leakage resistance ranging from 24.8 to 88.2 percent and PII extraction defense remaining weak at 14-42 percent across all models.
What carries the argument
The eight-dimensional HAAS framework, extended with D7 (Self-Graded Reliability Proxy) and D8 (Adversarial Security) and operationalized via seven Swiss-adapted benchmarks mapped to FINMA Guidance 08/2024, nDSG, and OWASP Top 10 for LLMs.
Load-bearing premise
The seven Swiss-adapted benchmarks and their conceptual mappings to FINMA, nDSG, and OWASP requirements accurately and comprehensively capture the relevant regulatory obligations without external validation of the self-grading method or cross-regime comparability.
What would settle it
An independent expert audit that checks whether the benchmark items and mappings fully cover the cited Swiss regulatory texts, or a follow-up study that compares self-graded scores against independently verified accuracy in live regulatory deployments.
Figures



read the original abstract
The deployment of large language models (LLMs) in Swiss financial and regulatory contexts demands empirical evidence of both production reliability and adversarial security, dimensions not jointly operationalized in existing Swiss-focused evaluation frameworks. This paper introduces Swiss-Bench 003 (SBP-003), extending the HAAS (Helvetic AI Assessment Score) from six to eight dimensions by adding D7 (Self-Graded Reliability Proxy) and D8 (Adversarial Security). I evaluate ten frontier models across 808 Swiss-specific items in four languages (German, French, Italian, English), comprising seven Swiss-adapted benchmarks (Swiss TruthfulQA, Swiss IFEval, Swiss SimpleQA, Swiss NIAH, Swiss PII-Scope, System Prompt Leakage, and Swiss German Comprehension) targeting FINMA Guidance 08/2024, the revised Federal Act on Data Protection (nDSG), and OWASP Top 10 for LLMs. Self-graded D7 scores (73-94%) exceed externally judged D8 security scores (20-61%) by a wide margin, though these dimensions use non-comparable scoring regimes. System prompt leakage resistance ranges from 24.8% to 88.2%, while PII extraction defense remains weak (14-42%) across all models. Qwen 3.5 Plus achieves the highest self-graded D7 score (94.4%), while GPT-oss 120B achieves the highest D8 score (60.7%) despite being the lowest-cost model evaluated. All evaluations are zero-shot under provider default settings; D7 is self-graded and does not constitute independently validated accuracy. I provide conceptual mapping tables relating benchmark dimensions to FINMA model validation requirements, nDSG data protection obligations, and OWASP LLM risk categories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Swiss-Bench 003 (SBP-003) as an 8-dimension extension of the HAAS framework, adding D7 (Self-Graded Reliability Proxy) and D8 (Adversarial Security). It reports zero-shot evaluations of ten frontier LLMs on 808 Swiss-specific items across seven adapted benchmarks (Swiss TruthfulQA, Swiss IFEval, Swiss SimpleQA, Swiss NIAH, Swiss PII-Scope, System Prompt Leakage, Swiss German Comprehension) targeting FINMA Guidance 08/2024, nDSG, and OWASP Top 10 for LLMs. The central empirical claim is that self-graded D7 scores (73-94%) substantially exceed externally judged D8 scores (20-61%), with additional results on prompt leakage (24.8-88.2%) and PII defense (14-42%), plus conceptual mapping tables to the cited regulatory regimes. All evaluations use provider-default settings; the abstract explicitly notes that D7 is self-graded and does not constitute independently validated accuracy.
Significance. If the methodological limitations around validation and comparability are resolved, the work would supply concrete, multi-language empirical data on LLM behavior in Swiss financial/regulatory settings, including specific performance gaps in adversarial security and mappings to FINMA model-validation requirements, nDSG data-protection obligations, and OWASP LLM risks. The zero-shot protocol, 808-item scale, and inclusion of lower-cost models (e.g., GPT-oss 120B topping D8) are practical strengths that could inform deployment decisions once the self-grading and cross-regime issues are addressed.
major comments (3)
- [Abstract] Abstract: The headline contrast that self-graded D7 reliability scores (73-94%) exceed externally judged D8 security scores (20-61%) is presented as a key finding for Swiss regulatory contexts, yet the text explicitly states that D7 'does not constitute independently validated accuracy' and that the two dimensions 'use non-comparable scoring regimes.' This renders the reported gap unsuitable as substantiated evidence for joint operationalization of production reliability and adversarial security.
- [Evaluation] Evaluation section (implied by the 808-item results and D7/D8 reporting): No error bars, statistical significance tests, or inter-rater reliability measures are mentioned for the self-graded D7 scores or the external D8 judgments. Combined with post-hoc model selection and the absence of independent human/expert calibration of the self-grades, this undermines the reliability of the numerical claims and the regulatory-mapping assertions.
- [Benchmark Design] Benchmark Design and Mapping Tables: The seven Swiss-adapted benchmarks are linked to FINMA Guidance 08/2024, nDSG, and OWASP via conceptual mapping tables only, with no reported external validation, expert review, or cross-check against actual regulatory audit criteria. Because these mappings are load-bearing for the claim that the benchmarks 'target' Swiss regulatory requirements, their unvalidated status directly weakens the applicability of the D7-D8 results to production compliance.
minor comments (2)
- [Abstract] Abstract: The phrasing 'I evaluate ten frontier models' is atypical for a formal paper; rephrasing to 'This work evaluates' would improve consistency with academic style.
- [Results] Results reporting: Model names such as 'Qwen 3.5 Plus' and 'GPT-oss 120B' should be accompanied by precise version identifiers or provider references to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We respond point by point to the major comments below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The headline contrast that self-graded D7 reliability scores (73-94%) exceed externally judged D8 security scores (20-61%) is presented as a key finding for Swiss regulatory contexts, yet the text explicitly states that D7 'does not constitute independently validated accuracy' and that the two dimensions 'use non-comparable scoring regimes.' This renders the reported gap unsuitable as substantiated evidence for joint operationalization of production reliability and adversarial security.
Authors: The abstract already includes explicit qualifications that D7 is self-graded and does not represent independently validated accuracy, and that D7 and D8 employ non-comparable scoring regimes. The contrast is reported as an empirical observation rather than evidence supporting joint operationalization for production or regulatory use. We will revise the abstract to state more explicitly that the reported gap is descriptive and exploratory, and does not constitute substantiated evidence for combined reliability and security claims in Swiss regulatory contexts. revision: yes
-
Referee: [Evaluation] No error bars, statistical significance tests, or inter-rater reliability measures are mentioned for the self-graded D7 scores or the external D8 judgments. Combined with post-hoc model selection and the absence of independent human/expert calibration of the self-grades, this undermines the reliability of the numerical claims and the regulatory-mapping assertions.
Authors: We acknowledge that the current manuscript lacks error bars, statistical tests, and inter-rater measures. D7 self-grading is performed by the models themselves, so conventional inter-rater reliability does not apply; we will add variance information where re-runs are feasible. We will insert a dedicated limitations section that addresses post-hoc model selection, the absence of independent calibration for self-grades, and the exploratory character of the evaluations. Basic statistical summaries will be added where the data permit. revision: partial
-
Referee: [Benchmark Design] The seven Swiss-adapted benchmarks are linked to FINMA Guidance 08/2024, nDSG, and OWASP via conceptual mapping tables only, with no reported external validation, expert review, or cross-check against actual regulatory audit criteria. Because these mappings are load-bearing for the claim that the benchmarks 'target' Swiss regulatory requirements, their unvalidated status directly weakens the applicability of the D7-D8 results to production compliance.
Authors: The mapping tables are conceptual and based on our analysis of the cited regulatory texts. We do not claim external validation or expert review. We will revise the manuscript to describe the mappings explicitly as preliminary and conceptual, change phrasing from 'target' to 'relevant to' or 'aligned with' the frameworks, and add a limitations section noting that expert or regulatory cross-validation lies beyond the scope of this work and would be required for compliance assertions. revision: yes
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
This is an empirical evaluation paper that introduces new benchmark dimensions and reports model scores on 808 Swiss-specific items. No mathematical derivations, equations, fitted parameters, or predictions that reduce to inputs by construction are present. The extension of the prior HAAS framework is explicitly new work adding D7 and D8; the self-citation serves only as background and is not load-bearing for the reported results or regulatory mappings. The paper transparently states that D7 is self-graded and does not constitute validated accuracy. All claims rest on direct evaluations rather than self-referential definitions or renamed prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The seven Swiss-adapted benchmarks validly operationalize FINMA Guidance 08/2024, nDSG, and OWASP LLM risks.
Reference graph
Works this paper leans on
-
[2]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
URLhttps://arxiv.org/abs/2410.09024. Swiss Financial Market Supervisory Authority. Finma guidance 08/2024: Governance and risk management when using artificial intelligence. FINMA,
work page internal anchor Pith review arXiv 2024
-
[3]
doi: 10.1177/135910457000100301. Lawrence D. Brown, T. Tony Cai, and Anirban DasGupta. Interval estimation for a binomial proportion.Statistical Science, 16(2):101–133,
-
[5]
Extracting training data from large language models
URLhttps://arxiv.org/abs/2012.07805. Nicholas Carlini and et al. Quantifying memorization across neural language models.arXiv preprint arXiv:2202.07646,
-
[6]
Quantifying Memorization Across Neural Language Models
URLhttps://arxiv.org/abs/2202.07646. Swiss Confederation. Federal act on data protection (ndsg/fadp, sr 235.1). Fedlex,
work page internal anchor Pith review arXiv
-
[8]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
URLhttps:// arxiv.org/abs/2406.13352. Yan Fang, Tianhao Shen, Shishir G. Patil, and et al. Berkeley function calling leaderboard.arXiv preprint arXiv:2407.00121,
work page internal anchor Pith review arXiv
-
[9]
URLhttps://arxiv.org/abs/2407.00121. OWASP Foundation. Owasp top 10 for large language model applications. OWASP,
-
[10]
Philipp Guldimann et al. COMPL-AI framework: A technical interpretation and LLM benchmark- ing suite for the EU artificial intelligence act.arXiv preprint arXiv:2410.07959,
-
[12]
URLhttps://arxiv.org/abs/2403.03218. Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958,
-
[13]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
URLhttps://arxiv.org/abs/2109.07958. Joel Niklaus et al. Swiltra-bench: The swiss legal translation benchmark.arXiv preprint arXiv:2503.01372,
work page internal anchor Pith review arXiv
-
[14]
URLhttps://arxiv.org/abs/2503.01372. Paul Rottger and et al. Xstest: A test suite for identifying exaggerated safety behaviours in large language models.arXiv preprint arXiv:2308.01263,
-
[16]
A strongreject for empty jailbreaks
URLhttps://arxiv.org/abs/2402.10260. Fatih Uenal. Swiss-bench sbp-002: A frontier model comparison on swiss legal and regulatory tasks. arXiv preprint arXiv:2603.23646,
-
[17]
URLhttps://arxiv.org/abs/2603.23646. UK AI Safety Institute. Inspect ai: A framework for large language model evaluations.https: //inspect.ai-safety-institute.org.uk/,
-
[19]
URLhttps: //arxiv.org/abs/2408.01605. Jason Wei and et al. Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368,
-
[20]
URLhttps://arxiv.org/abs/2411.04368. Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.Journal of the American Statistical Association, 22(158):209–212,
work page internal anchor Pith review arXiv
-
[21]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, and et al. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.