Recognition: no theorem link
When to Call an Apple Red: Humans Follow Introspective Rules, VLMs Don't
Pith reviewed 2026-05-10 19:20 UTC · model grok-4.3
The pith
Vision-language models systematically violate the color-labeling rules they state for themselves, while humans follow their own rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
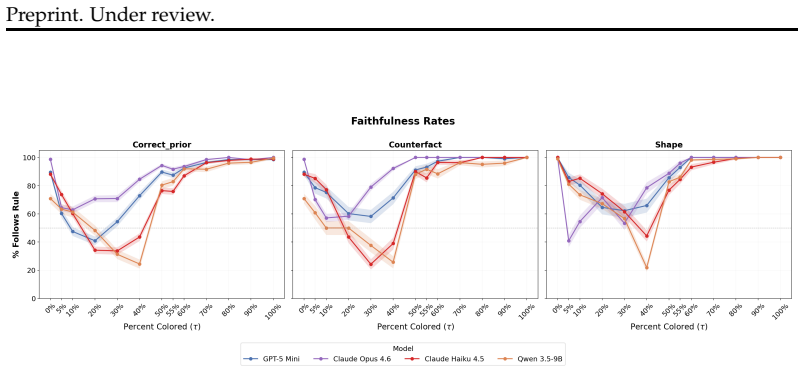
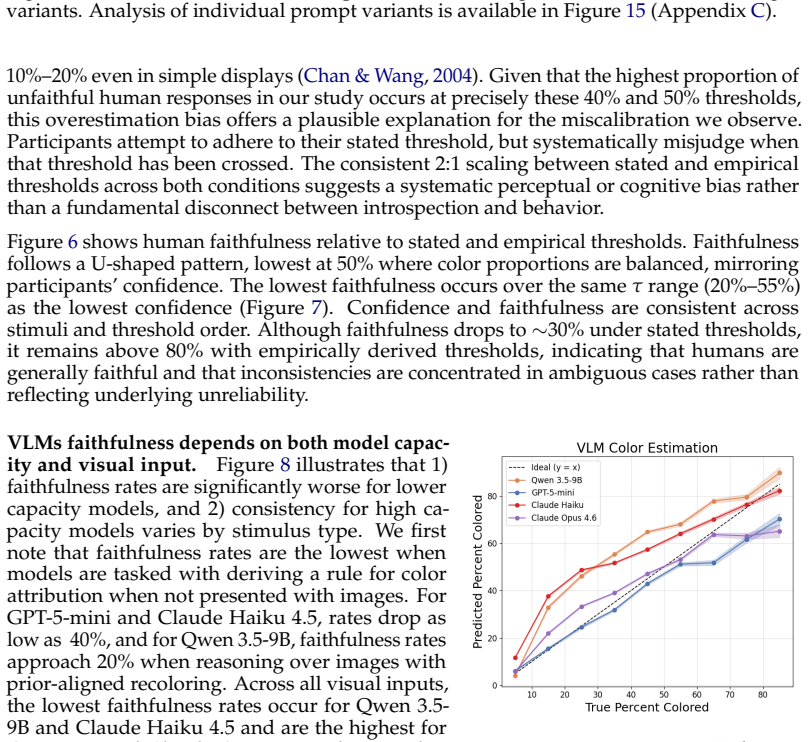
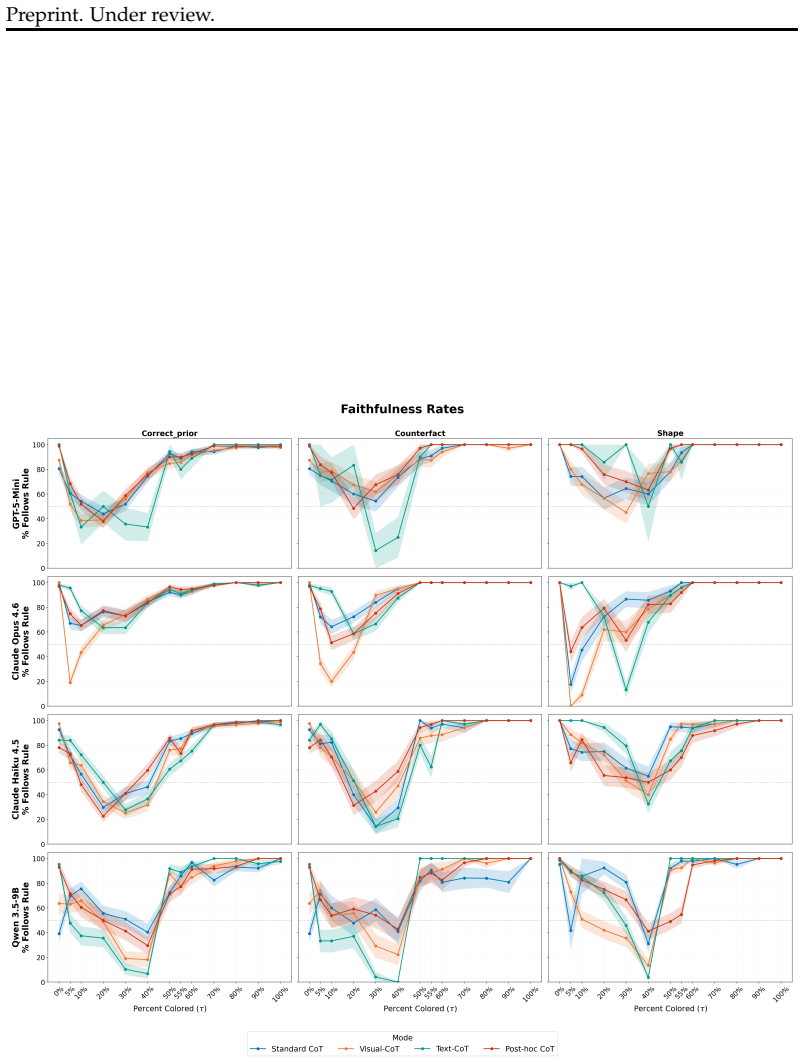
Using line drawings that vary color coverage across world-knowledge recolorings, counterfactual recolorings, and objects without color priors, the study elicits minimum pixel thresholds for color labels from both VLMs and humans, then measures adherence to those thresholds. VLMs violate their stated rules in nearly 60 percent of cases on objects with strong color priors, while humans remain faithful with deviations explained by overestimation of color coverage. VLMs estimate color coverage accurately yet contradict their own reasoning in final responses, and world-knowledge priors degrade faithfulness for models in ways that do not occur for humans.
What carries the argument
The Graded Color Attribution (GCA) dataset of line drawings that systematically vary pixel-level color coverage to elicit and test adherence to color-label thresholds across different prior conditions.
If this is right
- VLMs' introspective self-knowledge is miscalibrated.
- Reasoning failures in VLMs are not primarily difficulty-driven.
- World-knowledge priors degrade faithfulness in models differently than in humans.
- The mismatch carries direct implications for high-stakes deployment where models must predict or explain their own behavior.
Where Pith is reading between the lines
- Similar rule-elicitation tests could be applied to other domains such as causal or ethical judgments to check for parallel inconsistencies.
- Training or prompting techniques that enforce explicit consistency between stated rules and outputs might reduce the observed violations.
- Evaluation benchmarks for VLMs should include direct checks of rule adherence in addition to accuracy alone.
Load-bearing premise
That the rules participants state when prompted truly reflect the processes they use to make color judgments, rather than being shaped by how the questions are worded or how color is measured.
What would settle it
An experiment that forces models to output only decisions consistent with their previously stated thresholds and measures whether overall accuracy on the color task then falls below human levels or matches the rate of stated violations.
Figures












read the original abstract
Understanding when Vision-Language Models (VLMs) will behave unexpectedly, whether models can reliably predict their own behavior, and if models adhere to their introspective reasoning are central challenges for trustworthy deployment. To study this, we introduce the Graded Color Attribution (GCA) dataset, a controlled benchmark designed to elicit decision rules and evaluate participant faithfulness to these rules. GCA consists of line drawings that vary pixel-level color coverage across three conditions: world-knowledge recolorings, counterfactual recolorings, and shapes with no color priors. Using GCA, both VLMs and human participants establish a threshold: the minimum percentage of pixels of a given color an object must have to receive that color label. We then compare these rules with their subsequent color attribution decisions. Our findings reveal that models systematically violate their own introspective rules. For example, GPT-5-mini violates its stated introspection rules in nearly 60\% of cases on objects with strong color priors. Human participants remain faithful to their stated rules, with any apparent violations being explained by a well-documented tendency to overestimate color coverage. In contrast, we find that VLMs are excellent estimators of color coverage, yet blatantly contradict their own reasoning in their final responses. Across all models and strategies for eliciting introspective rules, world-knowledge priors systematically degrade faithfulness in ways that do not mirror human cognition. Our findings challenge the view that VLM reasoning failures are difficulty-driven and suggest that VLM introspective self-knowledge is miscalibrated, with direct implications for high-stakes deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Graded Color Attribution (GCA) dataset of line drawings varying in pixel-level color coverage across world-knowledge recolorings, counterfactual recolorings, and no-prior shapes. It elicits color-labeling thresholds (minimum pixel percentage required for a label) from VLMs and humans, then compares these to subsequent color-attribution decisions on the same images. The central claim is that VLMs systematically violate their own elicited thresholds (e.g., GPT-5-mini in ~60% of strong-prior cases), while humans remain largely faithful (with apparent violations attributable to overestimation of coverage); VLMs are accurate at pixel-coverage estimation yet still contradict their rules, with world-knowledge priors degrading faithfulness in a manner unlike human cognition. This is taken to indicate miscalibrated introspective self-knowledge in VLMs.
Significance. If the core comparison holds after addressing elicitation validity, the work supplies a controlled quantitative benchmark distinguishing rule-following from prior-driven behavior in VLMs versus humans, with direct relevance to trustworthy deployment and self-knowledge evaluation. The GCA dataset and the contrast between accurate coverage estimation and rule violation are concrete strengths that could support falsifiable follow-up tests.
major comments (3)
- [Methods (rule elicitation and decision phases); Results (violation rates)] The central claim that VLMs 'violate their own introspective rules' requires that the threshold elicited in the first phase is the operative decision criterion in the second phase. No ablation is described that forces the model to condition its color label on the previously stated threshold (e.g., by including the threshold in the decision prompt), nor is stability of thresholds across re-promptings of the same image set reported. Without these, the ~60% violation rate on strong-prior objects could be an artifact of separate prompting steps rather than evidence of miscalibrated self-knowledge.
- [§4 (GCA dataset construction and measurement); Results (coverage estimation vs. attribution)] The paper reports that VLMs remain accurate at pixel-coverage estimation yet contradict their thresholds. However, it is unclear how 'violation' is operationalized when the model's internal representation of coverage may differ from the GCA pixel measurement; if the model uses a different (unelicited) coverage estimate in its decision, the faithfulness metric does not isolate introspective failure from perceptual mismatch.
- [Results (human vs. VLM faithfulness; prior conditions)] The claim that 'world-knowledge priors systematically degrade faithfulness in ways that do not mirror human cognition' rests on the human-model comparison. The human explanation invokes a documented overestimation bias, but no parallel analysis checks whether model violations are similarly explained by systematic over- or under-estimation of coverage on the same images, or whether the prior effect is driven by the specific recoloring conditions in GCA.
minor comments (2)
- [Methods] Clarify the exact prompting templates used for threshold elicitation versus decision queries, including any differences in phrasing that might affect consistency.
- [Results] The abstract states 'across all models and strategies,' but the main text should tabulate violation rates broken down by elicitation strategy and model to support that generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional controls and analyses can strengthen the evidence that VLMs exhibit miscalibrated introspective self-knowledge. We address each point below and outline planned revisions.
read point-by-point responses
-
Referee: The central claim that VLMs 'violate their own introspective rules' requires that the threshold elicited in the first phase is the operative decision criterion in the second phase. No ablation is described that forces the model to condition its color label on the previously stated threshold (e.g., by including the threshold in the decision prompt), nor is stability of thresholds across re-promptings of the same image set reported. Without these, the ~60% violation rate on strong-prior objects could be an artifact of separate prompting steps rather than evidence of miscalibrated self-knowledge.
Authors: We agree that an explicit conditioning ablation would provide stronger causal evidence. In the revision we will add a condition in which the decision prompt includes the model's own previously elicited threshold and report the resulting change in violation rates. We will also re-elicit thresholds on a held-out subset of images to quantify stability (e.g., via intra-class correlation or percentage agreement) and include these metrics. These additions directly test whether the observed violations persist when the rule is made salient in the same prompt context. revision: yes
-
Referee: The paper reports that VLMs remain accurate at pixel-coverage estimation yet contradict their thresholds. However, it is unclear how 'violation' is operationalized when the model's internal representation of coverage may differ from the GCA pixel measurement; if the model uses a different (unelicited) coverage estimate in its decision, the faithfulness metric does not isolate introspective failure from perceptual mismatch.
Authors: Violation is defined strictly as a mismatch between the final color label and the label that would be predicted by applying the elicited threshold to the ground-truth GCA pixel coverage. Because the paper already demonstrates that VLMs produce accurate coverage estimates when queried directly, perceptual mismatch is unlikely to explain the violations. In the revision we will add an explicit analysis that substitutes each model's own coverage estimate (obtained in a separate query) into the threshold rule and recomputes violation rates; this will isolate whether any residual violations remain after accounting for the model's internal coverage representation. revision: partial
-
Referee: The claim that 'world-knowledge priors systematically degrade faithfulness in ways that do not mirror human cognition' rests on the human-model comparison. The human explanation invokes a documented overestimation bias, but no parallel analysis checks whether model violations are similarly explained by systematic over- or under-estimation of coverage on the same images, or whether the prior effect is driven by the specific recoloring conditions in GCA.
Authors: The manuscript already reports that VLMs are highly accurate at coverage estimation, which rules out systematic estimation bias as the driver of their violations (in contrast to humans). To further isolate the role of world-knowledge priors, the revision will include (i) a breakdown of violation rates by the three GCA conditions and (ii) a correlation analysis between violation magnitude and the strength of the object's color prior. These analyses will demonstrate that the degradation is tied to prior interference rather than the particular recoloring manipulations. revision: yes
Circularity Check
Empirical benchmark study with self-contained derivation
full rationale
The paper introduces the GCA dataset and performs a direct empirical comparison: thresholds are elicited separately via prompting from VLMs and humans, then color attribution decisions are measured on the same images and checked for adherence. No parameters are fitted to the target violation rates, no thresholds are defined in terms of the decisions themselves, and no load-bearing premises rely on self-citations or imported uniqueness theorems. The central claim (models violate elicited rules while humans do not) is a measurement against external participant responses and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Controlled variations in pixel color coverage can isolate the effect of world-knowledge priors on decision rules.
invented entities (1)
-
Graded Color Attribution (GCA) dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
plausibility: On the (un) reliability of explanations from large language models , author=
Chirag Agarwal, Sree Harsha Tanneru, and Himabindu Lakkaraju. Faithfulness vs. plausi- bility: On the (un) reliability of explanations from large language models.arXiv preprint arXiv:2402.04614,
-
[2]
URL https:// arxiv.org/abs/2505.23945. Fazl Barez, Tung-Yu Wu, Iv´an Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, et al. Chain-of-thought is not explainability.Preprint, alphaXiv, pp. v1,
-
[3]
doi: 10.1016/j.jvcir.2003.09.001
ISSN 1047-3203. doi: 10.1016/j.jvcir.2003.09.001. Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, et al. Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410,
-
[4]
Sihao Ding, Santosh Vasa, and Aditi Ramadwar
URL https: //arxiv.org/abs/2309.04461. Sihao Ding, Santosh Vasa, and Aditi Ramadwar. Explanation-driven counterfactual testing for faithfulness in vision-language model explanations.arXiv preprint arXiv:2510.00047,
-
[5]
URLhttps://arxiv.org/abs/2505.17127. Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, David Duvenaud, Akbir Khan, Julian Michael, S¨oren Mindermann, Ethan Perez, Linda Petrini, Jonathan Uesato, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, and Evan Hubinger. Alignmen...
-
[6]
Alignment faking in large language models
URLhttps://arxiv.org/abs/2412.14093. Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness,
work page internal anchor Pith review arXiv
-
[7]
Counterfactual simulation training for chain-of-thought faithfulness
URLhttps://arxiv.org/abs/2602.20710. Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702,
-
[8]
Chengzhi Liu, Zhongxing Xu, Qingyue Wei, Juncheng Wu, James Zou, Xin Eric Wang, Yuyin Zhou, and Sheng Liu. More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models.arXiv preprint arXiv:2505.21523, 2025a. Fenglin Liu, Hongjian Zhou, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S. Chen, Yining Hua, Peilin Zho...
-
[9]
Andreas Madsen, Sarath Chandar, and Siva Reddy
URLhttps://arxiv.org/abs/2602.07833. Andreas Madsen, Sarath Chandar, and Siva Reddy. Are self-explanations from large language models faithful? InFindings of the Association for Computational Linguistics: ACL 2024, pp. 295–337,
-
[10]
arXiv preprint arXiv:2404.18624 , year=
URL https://arxiv.org/abs/ 2404.18624. Xu Shen, Song Wang, Zhen Tan, Laura Yao, Xinyu Zhao, Kaidi Xu, Xin Wang, and Tianlong Chen. Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning,
-
[11]
Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning
URLhttps://arxiv.org/abs/2510.04040. Nithin Sivakumaran, Shoubin Yu, Hyunji Lee, Yue Zhang, Ali Payani, Mohit Bansal, and Elias Stengel-Eskin. Balancing faithfulness and performance in reasoning via multi- listener soft execution,
-
[12]
Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald
URLhttps://arxiv.org/abs/2602.16154. Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald. Privileged self-access matters for introspection in ai,
-
[13]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman
URLhttps://arxiv.org/abs/2508.14802. Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36:74952–74965,
-
[14]
doi: 10.3758/s13414-025-03098-3
ISSN 1943-393X. doi: 10.3758/s13414-025-03098-3. URL https: //doi.org/10.3758/s13414-025-03098-3. Shengbin Yue, Ting Huang, Zheng Jia, Siyuan Wang, Shujun Liu, Yun Song, Xuanjing Huang, and Zhongyu Wei. Multi-agent simulator drives language models for legal intensive interaction,
-
[15]
URLhttps://arxiv.org/abs/2502.06882. Rosie Zhao, Anshul Shah, Xiaoyu Zhu, Xinke Deng, Zhongyu Jiang, Yang Yang, Joerg Liebelt, and Arnab Mondal. On robustness and chain-of-thought consistency of rl-finetuned vlms,
-
[16]
A Creating GCA The GCA dataset consists of two types of stimuli: object images and geometric shapes
URLhttps://arxiv.org/abs/2602.12506. A Creating GCA The GCA dataset consists of two types of stimuli: object images and geometric shapes. Object stimuli were derived from the Visual CounterFact (VCF) dataset Golovanevsky et al. (2025) and were used to create two color conditions: a a canonical color prior condition, where objects were colored with their t...
-
[17]
silver” to “grey
In this example, the enclosed white area inside the forklift outline is included in the foreground mask even though it does not belong to the object itself. Because these regions occupy only a small fraction of the total mask area, they were retained to preserve consistency across thresholds and simplify the masking procedure. Since coloring percentages w...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.