Exploring 6D Object Pose Estimation with Deformation
Pith reviewed 2026-05-12 03:00 UTC · model grok-4.3
The pith
Deformed objects sharply reduce 6D pose estimation performance according to the DeSOPE dataset
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The DeSOPE dataset features high-fidelity 3D scans of 26 object categories in one canonical state and three deformed configurations with accurate 3D registration, along with an RGB-D dataset of 133K frames and 665K pose annotations. Evaluation of object pose methods shows performance drops sharply with increasing deformation, underscoring the need for robust deformation handling in practical applications.
What carries the argument
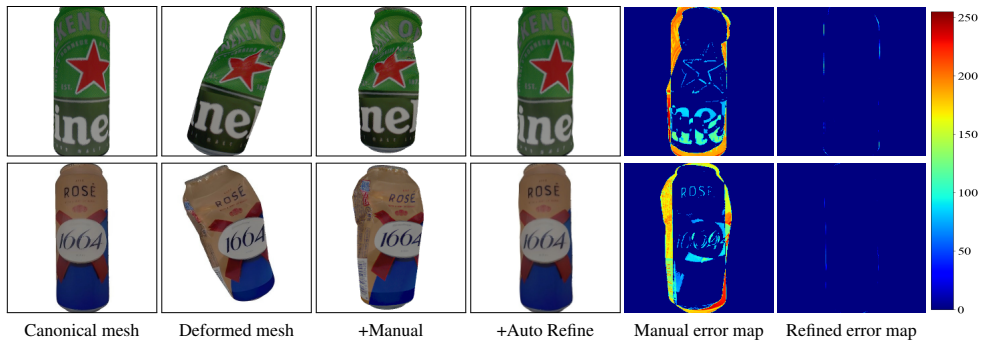
The semi-automatic annotation pipeline that starts with 2D masks, computes initial poses, refines via object-level SLAM, and ends with manual verification to create ground-truth for deformed objects.
If this is right
- Current methods assuming rigid or articulated objects will fail on deformed real-world items.
- Robust deformation handling is critical for applications like robotics and augmented reality.
- The dataset serves as a benchmark for developing new deformation-aware pose estimators.
Where Pith is reading between the lines
- Methods could be extended by incorporating shape deformation models learned from the dataset.
- This finding implies challenges for long-term tracking of objects that change shape over time.
- Future work might explore hybrid rigid-nonrigid pose estimation techniques tested on DeSOPE.
Load-bearing premise
The semi-automatic annotation pipeline produces sufficiently accurate ground-truth poses for the deformed configurations.
What would settle it
A re-annotation or independent measurement of the ground-truth poses on the most deformed objects that reveals significant inaccuracies would invalidate the performance drop observations.
Figures








read the original abstract
We present DeSOPE, a large-scale dataset for 6DoF deformed objects. Most 6D object pose methods assume rigid or articulated objects, an assumption that fails in practice as objects deviate from their canonical shapes due to wear, impact, or deformation. To model this, we introduce the DeSOPE dataset, which features high-fidelity 3D scans of 26 common object categories, each captured in one canonical state and three deformed configurations, with accurate 3D registration to the canonical mesh. Additionally, it features an RGB-D dataset with 133K frames across diverse scenarios and 665K pose annotations produced via a semi-automatic pipeline. We begin by annotating 2D masks for each instance, then compute initial poses using an object pose method, refine them through an object-level SLAM system, and finally perform manual verification to produce the final annotations. We evaluate several object pose methods and find that performance drops sharply with increasing deformation, suggesting that robust handling of such deformations is critical for practical applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the DeSOPE dataset for 6D object pose estimation of deformed objects, featuring high-fidelity 3D scans of 26 categories in one canonical and three deformed states with accurate registration, plus an RGB-D collection of 133K frames and 665K pose annotations. Annotations are produced via a semi-automatic pipeline (2D masks, initial pose from an object-pose estimator, object-level SLAM refinement, manual verification). Evaluation of several existing 6D pose methods shows sharp performance degradation with increasing deformation, leading to the claim that robust deformation handling is critical for practical applications.
Significance. If the ground-truth poses prove reliable, the dataset supplies a much-needed benchmark that quantifies the failure modes of rigid and articulated pose estimators on real-world deformations, directly supporting the development of deformation-aware algorithms. The scale (26 categories, multiple deformation levels, large frame count) and the empirical demonstration of performance collapse constitute a concrete contribution to the field.
major comments (2)
- [Abstract / Dataset Construction] Abstract and Dataset Construction section: the semi-automatic annotation pipeline initializes poses with an off-the-shelf object-pose estimator (implicitly rigid) before SLAM and manual checks. Because the paper's own evaluation shows these estimators degrade sharply on deformed objects, the initial estimates for the deformed configurations are likely to contain systematic errors whose magnitude grows with deformation level. Without quantitative validation of final GT accuracy (reprojection error statistics, comparison against independent measurements, or controlled synthetic tests), the reported performance drops may be inflated by annotation bias rather than reflecting true algorithmic limitations.
- [Evaluation] Evaluation section: the performance curves versus deformation level are presented without error bars, confidence intervals, or statistical tests. In addition, the manuscript does not specify how the three deformation levels per category were quantitatively controlled or measured (e.g., via surface deviation metrics or physical parameters), which undermines the claim of a monotonic, interpretable degradation trend.
minor comments (2)
- [Abstract] The abstract states 'accurate 3D registration to the canonical mesh' but provides no registration algorithm, error metrics, or failure cases; this detail should be added for reproducibility.
- Clarify the exact set of object-pose methods used both for initial annotation and for the reported benchmark to prevent reader confusion between the two roles.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and Dataset Construction section: the semi-automatic annotation pipeline initializes poses with an off-the-shelf object-pose estimator (implicitly rigid) before SLAM and manual checks. Because the paper's own evaluation shows these estimators degrade sharply on deformed objects, the initial estimates for the deformed configurations are likely to contain systematic errors whose magnitude grows with deformation level. Without quantitative validation of final GT accuracy (reprojection error statistics, comparison against independent measurements, or controlled synthetic tests), the reported performance drops may be inflated by annotation bias rather than reflecting true algorithmic limitations.
Authors: We thank the referee for raising this valid concern about potential annotation bias. The pipeline does begin with a rigid estimator, but the poses are subsequently refined via object-level SLAM across multiple frames and undergo manual verification. The high-fidelity 3D scans with accurate registration further support GT reliability. Nevertheless, we agree that explicit quantitative validation is needed and will add reprojection error statistics and any available synthetic comparisons in the revised Dataset Construction section to demonstrate that final GT accuracy does not systematically degrade with deformation level. revision: yes
-
Referee: [Evaluation] Evaluation section: the performance curves versus deformation level are presented without error bars, confidence intervals, or statistical tests. In addition, the manuscript does not specify how the three deformation levels per category were quantitatively controlled or measured (e.g., via surface deviation metrics or physical parameters), which undermines the claim of a monotonic, interpretable degradation trend.
Authors: We agree that the evaluation presentation can be strengthened. In the revision we will add error bars (standard deviation across categories or runs), confidence intervals where appropriate, and statistical tests to confirm the significance of the degradation trend. We will also expand the Dataset Construction section to specify how the three deformation levels were controlled and quantified, reporting surface deviation metrics computed from the existing accurate 3D registrations between canonical and deformed scans. revision: yes
Circularity Check
No derivation chain present; empirical dataset paper
full rationale
The paper introduces the DeSOPE dataset via a semi-automatic annotation pipeline (2D masks, initial rigid pose estimation, object-level SLAM refinement, manual verification) and reports empirical performance of existing 6D pose estimators on deformed objects. No mathematical derivation, first-principles result, parameter fitting, or uniqueness theorem is claimed or present. The central finding—that performance drops with increasing deformation—is an observation from the collected data and evaluations, not a quantity that reduces to its own inputs by construction. The annotation process is a methodological description, not a self-referential loop that forces the reported degradation. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations
Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jian- ing Wei, and Matthias Grundmann. Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021. 2, 3
work page 2021
-
[2]
SpeedFolding: Learning Effi- cient Bimanual Folding of Garments
Yahav Avigal, Lars Berscheid, Tamim Asfour, Torsten Kr¨oger, and Ken Goldberg. SpeedFolding: Learning Effi- cient Bimanual Folding of Garments. In2022 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems,
-
[3]
HOT3D: Hand and Object Tracking in 3D From Egocentric Multi-View Videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, et al. HOT3D: Hand and Object Tracking in 3D From Egocentric Multi-View Videos. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2025. 2
work page 2025
-
[4]
Learning 6D Object Pose Estimation Using 3D Object Coordinates
Eric Brachmann, Alexander Krull, Frank Michel, Stefan Gumhold, Jamie Shotton, and Carsten Rother. Learning 6D Object Pose Estimation Using 3D Object Coordinates. In Proceedings of the European Conference on Computer Vi- sion, 2014. 2, 3
work page 2014
-
[5]
Multi-view Pose Fusion for Occlusion- Aware 3D Human Pose Estimation
Laura Bragagnolo, Matteo Terreran, Davide Allegro, and Stefano Ghidoni. Multi-view Pose Fusion for Occlusion- Aware 3D Human Pose Estimation. InProceedings of the European Conference on Computer Vision, 2024. 3
work page 2024
-
[6]
GS-Pose: Generalizable Segmentation-based 6D Object Pose Estima- tion With 3D Gaussian Splatting
Dingding Cai, Janne Heikkil ¨a, and Esa Rahtu. GS-Pose: Generalizable Segmentation-based 6D Object Pose Estima- tion With 3D Gaussian Splatting. In2025 International Con- ference on 3D Vision, 2025. 2
work page 2025
-
[7]
The YCB Object and Model Set: Towards Common Benchmarks for Manip- ulation Research
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srini- vasa, Pieter Abbeel, and Aaron M Dollar. The YCB Object and Model Set: Towards Common Benchmarks for Manip- ulation Research. In2015 International Conference on Ad- vanced Robotics, 2015. 2, 3
work page 2015
-
[8]
Cloth Fun- nels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation
Alper Canberk, Cheng Chi, Huy Ha, Benjamin Burchfiel, Eric Cousineau, Siyuan Feng, and Shuran Song. Cloth Fun- nels: Canonicalized-Alignment for Multi-Purpose Garment Manipulation. In2023 IEEE International Conference on Robotics and Automation, 2023. 3
work page 2023
-
[9]
ShapeNet: An Information-Rich 3D Model Repository.arXiv, 2015
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Mano- lis Savva, Shuran Song, Hao Su, et al. ShapeNet: An Information-Rich 3D Model Repository.arXiv, 2015. 6
work page 2015
-
[10]
Hansheng Chen, Pichao Wang, Fan Wang, Wei Tian, Lu Xiong, and Hao Li. EPro-PnP: Generalized End-to- End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2022. 2
work page 2022
-
[11]
Haonan Chen, Junxiao Li, Ruihai Wu, Yiwei Liu, Yiwen Hou, Zhixuan Xu, Jingxiang Guo, Chongkai Gao, Zhenyu Wei, Shensi Xu, et al. MetaFold: Language-Guided Multi- Category Garment Folding Framework via Trajectory Gen- eration and Foundation Model. In2025 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems, 2025. 3
work page 2025
-
[12]
Yongbo Chen, Yanhao Zhang, Shaifali Parashar, Liang Zhao, and Shoudong Huang. Non-Rigid Structure-from-Motion Via Differential Geometry With Recoverable Conformal Scale.IEEE Transactions on Robotics, 2025. 3
work page 2025
-
[13]
Zhangquan Chen, Puhua Jiang, and Ruqi Huang. DV- Matcher: Deformation-based Non-Rigid Point Cloud Match- ing Guided by Pre-trained Visual Features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 3
work page 2025
-
[14]
Go!SCAN SPARK 3D Scanner.https:// www.goengineer.com/3d-scanners/creaform/ goscan, 2026
Creaform. Go!SCAN SPARK 3D Scanner.https:// www.goengineer.com/3d-scanners/creaform/ goscan, 2026. 3
work page 2026
-
[15]
Objaverse: A Universe of Annotated 3D Objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsanit, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A Universe of Annotated 3D Objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023. 6
work page 2023
-
[16]
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kin- man, Ryan Hickman, Krista Reymann, Thomas B. McHugh, and Vincent Vanhoucke. Google Scanned Objects: A High- Quality Dataset of 3D Scanned Household Items. In2022 In- ternational Conference on Robotics and Automation, 2022. 6
work page 2022
-
[17]
Yang Fu and Xiaolong Wang. Category-Level 6D Object Pose Estimation in the Wild: A Semi-Supervised Learning Approach and A New Dataset.Advances in Neural Informa- tion Processing Systems, 2022. 2, 3
work page 2022
-
[18]
Human-Robot Alignment through Interactivity and Interpretability: Don’t Assume a” Spherical Human”
Matthew C Gombolay. Human-Robot Alignment through Interactivity and Interpretability: Don’t Assume a” Spherical Human”. InIJCAI, 2024. 3
work page 2024
-
[19]
Andrew Guo, Bowen Wen, Jianhe Yuan, Jonathan Trem- blay, Stephen Tyree, Jeffrey Smith, and Stan Birchfield. HANDAL: A dataset of real-world manipulable object cat- egories with pose annotations, affordances, and reconstruc- tions. In2023 IEEE/RSJ International Conference on Intel- ligent Robots and Systems, 2023. 2, 3
work page 2023
-
[20]
T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Ob- jects
Tom ´aˇs Hodan, Pavel Haluza, ˇStep´an Obdrˇz´alek, Jiri Matas, Manolis Lourakis, and Xenophon Zabulis. T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Ob- jects. In2017 IEEE Winter Conference on Applications of Computer Vision, 2017. 2
work page 2017
-
[21]
BOP: Benchmark for 6D Object Pose Estimation
Tomas Hodan, Frank Michel, Eric Brachmann, Wadim Kehl, Anders GlentBuch, Dirk Kraft, Bertram Drost, Joel Vidal, Stephan Ihrke, Xenophon Zabulis, et al. BOP: Benchmark for 6D Object Pose Estimation. InProceedings of the Euro- pean Conference on Computer Vision, 2018. 2, 7
work page 2018
-
[22]
Hand-held Object Reconstruction from RGB Video with Dynamic Interaction
Shijian Jiang, Qi Ye, Rengan Xie, Yuchi Huo, and Jiming Chen. Hand-held Object Reconstruction from RGB Video with Dynamic Interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[23]
HyunJun Jung, Shun-Cheng Wu, Patrick Ruhkamp, Guangyao Zhai, Hannah Schieber, Giulia Rizzoli, Pengyuan Wang, Hongcheng Zhao, Lorenzo Garattoni, Sven Meier, et al. Housecat6D: A Large-Scale Multi-Modal Category Level 6D Object Perception Dataset With Household Objects in Realistic Scenarios. InProceedings of the IEEE/CVF Con- ference on Computer Vision and...
work page 2024
-
[24]
Any6D: Model-free 6D Pose Estimation of Novel Objects
Taeyeop Lee, Bowen Wen, Minjun Kang, Gyuree Kang, In So Kweon, and Kuk-Jin Yoon. Any6D: Model-free 6D Pose Estimation of Novel Objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 2
work page 2025
-
[25]
ViTa-Zero: Zero-shot Visuotactile Object 6D Pose Estimation
Hongyu Li, James Akl, Srinath Sridhar, Tye Brady, and Tas ¸kın Padır. ViTa-Zero: Zero-shot Visuotactile Object 6D Pose Estimation. In2025 IEEE International Conference on Robotics and Automation, 2025. 2
work page 2025
-
[26]
GCE- Pose: Global Context Enhancement for Category-Level Ob- ject Pose Estimation
Weihang Li, Hongli Xu, Junwen Huang, Hyunjun Jung, Pe- ter KT Yu, Nassir Navab, and Benjamin Busam. GCE- Pose: Global Context Enhancement for Category-Level Ob- ject Pose Estimation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2025. 2
work page 2025
-
[27]
DynamicPose: Real-Time and Robust 6D Object Pose Tracking for Fast-Moving Cameras and Objects
Tingbang Liang, Yixin Zeng, JiaTong Xie, and Boyu Zhou. DynamicPose: Real-Time and Robust 6D Object Pose Tracking for Fast-Moving Cameras and Objects. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2025. 2
work page 2025
-
[28]
Instance-Adaptive and Geometric-Aware Keypoint Learning for Category-Level 6D Object Pose Estimation
Xiao Lin, Wenfei Yang, Yuan Gao, and Tianzhu Zhang. Instance-Adaptive and Geometric-Aware Keypoint Learning for Category-Level 6D Object Pose Estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 2
work page 2024
-
[29]
Jian Liu, Wei Sun, Hui Yang, Pengchao Deng, Chongpei Liu, Nicu Sebe, Hossein Rahmani, and Ajmal Mian. Diff9D: Diffusion-based Domain-Generalized Category-Level 9-Dof Object Pose Estimation.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 2025. 2
work page 2025
-
[30]
Min Liu, Gang Yang, Siyuan Luo, and Lin Shao. Soft- MAC: Differentiable Soft Body Simulation with Forecast- based Contact Model and Two-way Coupling with Articu- lated Rigid Bodies and Clothes. In2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems, 2024. 3
work page 2024
-
[31]
Xiaofei Liu, Zhengkun Yi, Xinyu Wu, and Wanfeng Shang. Spatial-Temporal Transformer for Single RGB-D Camera Synchronous Tracking and Reconstruction of Non-Rigid Dy- namic Objects.International Journal of Computer Vision,
-
[32]
YOLO-6D-Pose: Enhancing Yolo for Single-Stage Monocular Multi-Object 6D Pose Estimation
Debapriya Maji, Soyeb Nagori, Manu Mathew, and Deepak Poddar. YOLO-6D-Pose: Enhancing Yolo for Single-Stage Monocular Multi-Object 6D Pose Estimation. In2024 Inter- national Conference on 3D Vision, 2024. 2
work page 2024
-
[33]
SplatPose: On-Device Outdoor AR Pose Estimation Using Gaussian Splatting
Weiwu Pang, Rajrup Ghosh, Jiawei Yang, Ziyu Wei, Bran- den Leong, Yue Wang, and Ramesh Govindan. SplatPose: On-Device Outdoor AR Pose Estimation Using Gaussian Splatting. InProceedings of the 33rd ACM International Conference on Multimedia, 2025. 2
work page 2025
-
[34]
Rahul Raguram, Ondrej Chum, Marc Pollefeys, Jiri Matas, and Jan-Michael Frahm. USAC: A Universal Framework for Random Sample Consensus.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012. 3
work page 2012
-
[35]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feicht- enhofer. SAM 2: Segment Anything in Images and Videos. InThe Thirteenth Inter...
work page 2025
-
[36]
Com- mon Objects in 3D: Large-Scale Learning and Evaluation of Real-Life 3D Category Reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon Objects in 3D: Large-Scale Learning and Evaluation of Real-Life 3D Category Reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, 2021. 2, 3
work page 2021
-
[37]
Rethinking correspondence-based category-level object pose estimation
Ren, Huan and Yang, Wenfei and Zhang, Shifeng and Zhang, Tianzhu. Rethinking correspondence-based category-level object pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[38]
Soft Robot Shape Estimation: A Load-Agnostic Geometric Method
Christian Sorensen and Marc D Killpack. Soft Robot Shape Estimation: A Load-Agnostic Geometric Method. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023. 3
work page 2023
-
[39]
Stephen Tyree, Jonathan Tremblay, Thang To, Jia Cheng, Terry Mosier, Jeffrey Smith, and Stan Birchfield. 6-DoF Pose Estimation of Household Objects For Robotic Manipulation: An Accessible Dataset and Benchmark. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems,
-
[40]
Shinji Umeyama. Least-Squares Estimation of Transforma- tion Parameters Between Two Point Patterns.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2002. 3
work page 2002
-
[41]
Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2019. 2, 3
work page 2019
-
[42]
Co- SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time Slam
Hengyi Wang, Jingwen Wang, and Lourdes Agapito. Co- SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time Slam. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[43]
Hua Wang, Hong Liu, Jiale Ren, Mingxin Tan, and Zhongzien Jiang. CLIP-6D: Empowering CLIP as a Zero- Shot 6D Pose Estimator Through Generalizable Object- Specific Representations. InProceedings of the 33rd ACM International Conference on Multimedia, 2025. 2
work page 2025
-
[44]
Pengyuan Wang, HyunJun Jung, Yitong Li, Siyuan Shen, Rahul Parthasarathy Srikanth, Lorenzo Garattoni, Sven Meier, Nassir Navab, and Benjamin Busam. PhoCal: A Multi-Modal Dataset for Category-Level Object Pose Esti- mation With Photometrically Challenging Objects. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. 3
work page 2022
-
[45]
SCFlow2: Plug-and-Play Object Pose Refiner With Shape-Constraint Scene Flow
Qingyuan Wang, Rui Song, Jiaojiao Li, Kerui Cheng, David Ferstl, and Yinlin Hu. SCFlow2: Plug-and-Play Object Pose Refiner With Shape-Constraint Scene Flow. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2025. 2, 3, 4, 6, 7
work page 2025
-
[46]
FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024. 2, 4, 7
work page 2024
-
[47]
SurgPose: A Dataset for Articulated Robotic Surgical Tool Pose Estimation and Tracking
Zijian Wu, Adam Schmidt, Randy Moore, Haoying Zhou, Alexandre Banks, Peter Kazanzides, and Septimiu E Salcud- ean. SurgPose: A Dataset for Articulated Robotic Surgical Tool Pose Estimation and Tracking. In2025 IEEE Interna- tional Conference on Robotics and Automation, 2025. 2
work page 2025
-
[48]
6D-Diff: A Keypoint Diffusion Framework for 6D Object Pose Estima- tion
Li Xu, Haoxuan Qu, Yujun Cai, and Jun Liu. 6D-Diff: A Keypoint Diffusion Framework for 6D Object Pose Estima- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024. 2
work page 2024
-
[49]
DPhu- man: Generalizable Neural Human Rendering Via Point Registration-Based Human Deformation
Yongang Yu, Zhigang Chen, and Tangquan Qi. DPhu- man: Generalizable Neural Human Rendering Via Point Registration-Based Human Deformation. InNational Con- ference of Theoretical Computer Science, 2025. 3
work page 2025
-
[50]
Hui Zhang, Jianzhi Lyu, Chuangchuang Zhou, Hongzhuo Liang, Yuyang Tu, Fuchun Sun, and Jianwei Zhang. ADG- Net: A Sim2Real Multimodal Learning Framework for Adaptive Dexterous Grasping.IEEE Transactions on Cy- bernetics, 2025. 2
work page 2025
-
[51]
GenPose: Gen- erative Category-level Object Pose Estimation via Diffusion Models
Jiyao Zhang, Mingdong Wu, and Hao Dong. GenPose: Gen- erative Category-level Object Pose Estimation via Diffusion Models. InProceedings of the 37th International Conference on Neural Information Processing Systems, 2023. 7
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.