Recognition: 2 theorem links
· Lean TheoremYale-DM-Lab at ArchEHR-QA 2026: Deterministic Grounding and Multi-Pass Evidence Alignment for EHR Question Answering
Pith reviewed 2026-05-10 18:35 UTC · model grok-4.3
The pith
Ensemble voting across diverse models improves performance on EHR question answering subtasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The system achieves its reported development-set results by combining model diversity with ensemble voting strategies and by supplying the full clinician answer paragraph as additional context for evidence alignment, with the finding that alignment accuracy is primarily constrained by reasoning rather than other factors.
What carries the argument
Ensemble voting across diverse large language models with few-shot prompting and multi-pass evidence alignment using clinician answer context
Load-bearing premise
The performance gains and prompting strategies observed on the development set will generalize to unseen test data with varied patient questions and record formats.
What would settle it
A large drop in scores on the official hidden test set relative to the development set scores of 88.81 micro F1, 65.72 macro F1, 34.01, and 33.05 would show that the ensemble and context strategies fail to generalize.
Figures

read the original abstract
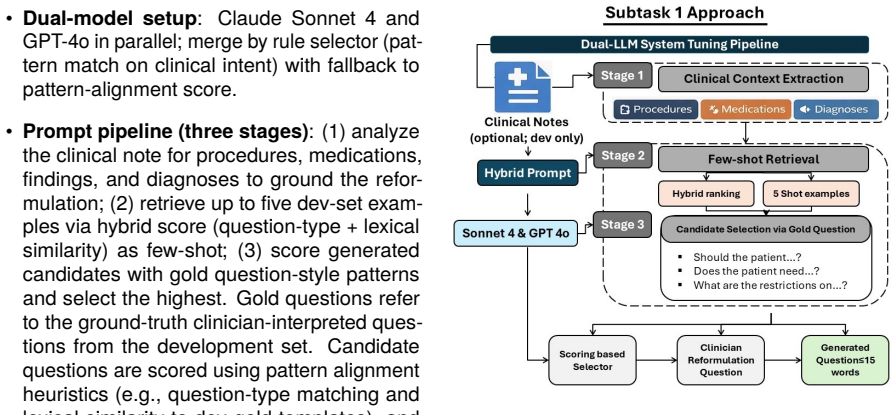
We describe the Yale-DM-Lab system for the ArchEHR-QA 2026 shared task. The task studies patient-authored questions about hospitalization records and contains four subtasks (ST): clinician-interpreted question reformulation, evidence sentence identification, answer generation, and evidence-answer alignment. ST1 uses a dual-model pipeline with Claude Sonnet 4 and GPT-4o to reformulate patient questions into clinician-interpreted questions. ST2-ST4 rely on Azure-hosted model ensembles (o3, GPT-5.2, GPT-5.1, and DeepSeek-R1) combined with few-shot prompting and voting strategies. Our experiments show three main findings. First, model diversity and ensemble voting consistently improve performance compared to single-model baselines. Second, the full clinician answer paragraph is provided as additional prompt context for evidence alignment. Third, results on the development set show that alignment accuracy is mainly limited by reasoning. The best scores on the development set reach 88.81 micro F1 on ST4, 65.72 macro F1 on ST2, 34.01 on ST3, and 33.05 on ST1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the Yale-DM-Lab system submitted to the ArchEHR-QA 2026 shared task on patient-authored questions about hospitalization records. It details a dual-model pipeline (Claude Sonnet 4 and GPT-4o) for subtask 1 (clinician-interpreted question reformulation) and Azure-hosted LLM ensembles (o3, GPT-5.2, GPT-5.1, DeepSeek-R1) with few-shot prompting and voting for subtasks 2–4 (evidence identification, answer generation, and evidence-answer alignment). The authors report three main findings from development-set experiments: consistent gains from model diversity and ensemble voting over single-model baselines, the utility of providing the full clinician answer paragraph as additional prompt context for alignment, and reasoning as the primary bottleneck for alignment accuracy. Best development-set scores are listed as 88.81 micro F1 (ST4), 65.72 macro F1 (ST2), 34.01 (ST3), and 33.05 (ST1).
Significance. If the reported gains from ensembles and context injection hold under proper controls, the work offers practical, task-specific evidence on effective LLM usage for EHR question answering, particularly highlighting reasoning limitations and the value of clinician-provided context. The explicit numeric results and enumerated findings provide a clear empirical contribution to shared-task literature in clinical NLP.
major comments (2)
- Abstract: The first finding states that 'model diversity and ensemble voting consistently improve performance compared to single-model baselines,' yet no single-model baseline scores, ablation tables, or quantitative deltas are supplied anywhere in the manuscript, rendering the improvement claim unverifiable from the provided evidence.
- Abstract / reported results: All performance numbers and the three main findings are derived exclusively from the development set (e.g., 88.81 micro F1 on ST4) with no test-set results, cross-validation statistics, error bars, or significance tests reported, which directly undermines assessment of the claimed generalization of the prompting and voting strategies.
minor comments (2)
- The title highlights 'Deterministic Grounding and Multi-Pass Evidence Alignment,' but these specific techniques are not defined or isolated in the abstract or the listed findings, leaving their contribution unclear.
- No details are given on ensemble construction (e.g., how many models per subtask, exact voting procedure, or prompt templates), which affects reproducibility of the reported scores.
Simulated Author's Rebuttal
Thank you for the thorough review and valuable suggestions. We have carefully considered each major comment and provide point-by-point responses below, indicating the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: Abstract: The first finding states that 'model diversity and ensemble voting consistently improve performance compared to single-model baselines,' yet no single-model baseline scores, ablation tables, or quantitative deltas are supplied anywhere in the manuscript, rendering the improvement claim unverifiable from the provided evidence.
Authors: We agree that the current manuscript lacks explicit single-model baseline results and ablation studies to support the claim of consistent improvements from ensemble voting. The experiments section describes the ensemble setup but does not include comparative tables. We will add a new table in the experiments section presenting single-model performances for each subtask alongside the ensemble results, including the deltas in performance metrics. This will make the improvement claim verifiable. revision: yes
-
Referee: Abstract / reported results: All performance numbers and the three main findings are derived exclusively from the development set (e.g., 88.81 micro F1 on ST4) with no test-set results, cross-validation statistics, error bars, or significance tests reported, which directly undermines assessment of the claimed generalization of the prompting and voting strategies.
Authors: We acknowledge that the reported scores and findings are based solely on the development set. As this is a system description for a shared task, the test set annotations are not yet available for evaluation. We will revise the abstract and relevant sections to explicitly indicate that all quantitative results are from the development set and that test set performance will be reported once the official test results are released. Regarding cross-validation, error bars, and significance tests, these were not performed because our prompting and voting strategies are deterministic and we had limited computational resources for multiple runs. We can note this limitation in the paper. revision: partial
- No test-set results are available to report or analyze for generalization, as the shared task has not released test labels.
Circularity Check
No circularity: purely empirical system report
full rationale
The paper is a shared-task system description that reports direct experimental outcomes from model ensembles, few-shot prompting, and voting on the development set. No equations, derivations, fitted parameters, or predictions appear. Central claims (ensemble gains, context injection, reasoning bottleneck) are supported solely by the listed micro/macro F1 numbers obtained from running the described pipeline; they do not reduce to self-definitions, self-citations, or renamed inputs. This is the normal case of an empirical report whose results remain externally falsifiable on the shared-task test set.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our experiments show three main findings. First, model diversity and ensemble voting consistently improve performance... best scores on the development set reach 88.81 micro F1 on ST4...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ST4... ensemble aggregation with recall-oriented augmentation... full clinician answer paragraph as additional prompt context
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
They are difficult for patients to interpret without clinical training
Introduction Electronic health records (EHRs) contain dense clinical narratives. They are difficult for patients to interpret without clinical training. Prior work has studied information extraction from EHR text (Liu et al., 2013) and clinical question answering with large language models (LLMs) (Singhal et al., 2023; Nori et al., 2023). The ArchEHR-QA s...
2013
-
[2]
Related Work Information extraction from electronic health record (EHR) text has long been studied in clinical nat- ural language processing (NLP)Liu et al. (2025). Early work by Demner-Fushman et al. (2009) de- veloped clinical decision support methods based on structured information extracted from clinical narratives. More recent datasets extend this di...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shared Task and Dataset TheArchEHR-QA2026datasetcontains167cases derivedfromde-identifiedEHRnarratives(Soniand Demner-Fushman, 2026a). Each case includes a patientfree-textquestion,aclinicalnotesegmented into numbered sentences, a clinician-interpreted question, a clinician answer paragraph, and gold evidence alignments. The dataset is split into 20 devel...
-
[4]
2","5"], while a BAD set may be [
Methodology 4.1. Prompting Setup We use task-specific prompt templates with fixed instruction blocks. We vary (i) few-shot example count, (ii) model ensemble composition, and (iii) vote threshold and post-processing settings. Few- shotexamplesareselectedinaleave-one-outman- ner from development cases and are excluded if they match the current case. Unless...
2024
-
[5]
We show development experiments and final test submissions
Results Table 1 reports performance across all four sub- tasks. We show development experiments and final test submissions. The experiments evaluate ensemble size, few-shot count, vote thresholds, and grounding strategies. Subtask 1: Question Reformulation.The best development configuration uses note grounding and pattern-based scoring. It achieves a scor...
-
[6]
Conclusion We presented the Yale-DM-Lab system for ArchEHR-QA 2026, a four-subtask pipeline for patient-facing EHR question answering. The system combines model-diverse LLM ensembles, self-consistency voting, and leave-one-out few- shot prompting. Our experiments present strong performance across subtasks, with evidence alignment (ST4) reaching 88.81 micr...
-
[7]
Larger clinical QA datasets would enable more reliable evaluation and tuning
Future Work Futureworkwillfocusonimprovingdatascale,mod- eling integration, and generation reliability. Larger clinical QA datasets would enable more reliable evaluation and tuning. Joint modeling across sub- tasks may reduce error propagation. Improving Subtask 3 is a priority, as answer generation re- mains the weakest component. The task requires produ...
-
[8]
First, the dataset is small
Limitations This work has several limitations. First, the dataset is small. The development set contains only 20 cases. This limit restricts reliable hyperparame- ter tuning. It also limits the diversity of few-shot examples. Second, the system relies heavily on prompt engineering. Model behavior depends on prompt wording and example selection. Small prom...
-
[9]
No identifiable patient informa- tion is used
Ethics Statement This work uses de-identified clinical data provided by the shared task. No identifiable patient informa- tion is used. The system is intended for research purposes only and not for clinical deployment
-
[10]
arXiv preprint arXiv:2603.00025 (2026)
Bibliographical References Tom B. Brown et al. 2020. Language models are few-shot learners.Advances in Neural Informa- tion Processing Systems, 33:1877–1901. Dina Demner-Fushman, Wendy W. Chapman, and Clement J. McDonald. 2009. What can natu- ral language processing do for clinical decision support?Journal of Biomedical Informatics, 42(5):760–772. Samah F...
-
[11]
Smith, Zachary Ziegler, Daniel Nadler, Peter Szolovits, Alistair Johnson, and Emily Alsentzer
Neural text summarization: A critical eval- uation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing, pages 540–551. Leonid Kuligin, Jan Lammert, Alexander Ostapenko, Kim Bressem, Martin Boeker, and Malte Tschochohei. 2025. Prompt design for medical question answering with large language models.Machine Learning wi...
-
[12]
InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics (ACL), pages 3214–3252
TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics (ACL), pages 3214–3252. As- sociation for Computational Linguistics. Adam Roberts, Colin Raffel, and Noam Shazeer
-
[13]
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
How much knowledge can you pack into the parameters of a language model?arXiv preprint arXiv:2002.08910. YashSaxena, ShubhamChopra, andA.M.Tripathi
work page internal anchor Pith review arXiv 2002
-
[14]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Evaluating consistency and reasoning ca- pabilities of large language models. InSecond International Conference on Data Science and Information System (ICDSIS), pages 1–5. IEEE. Karan Singhal et al. 2023. Large language models encode clinical knowledge.Nature, 620:172– 180. Sarvesh Soni and Dina Demner-Fushman. 2026a. A dataset for addressing patient’s in...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
1","3","7
Appendix This section presents the prompt templates used across all four subtasks as (Figure A1). Each tem- plate specifies the instruction structure, role config- uration, and output format used during inference. The templates correspond to the prompting strate- gies described in section 4 and illustrate the con- straints applied to each task. Subsection...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.