Self-Discovered Intention-aware Transformer for Multi-modal Vehicle Trajectory Prediction
Pith reviewed 2026-05-10 18:12 UTC · model grok-4.3
The pith
A Transformer with separate tracks for intention and trajectory prediction improves multi-modal vehicle forecasts without graphs or labeled intentions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
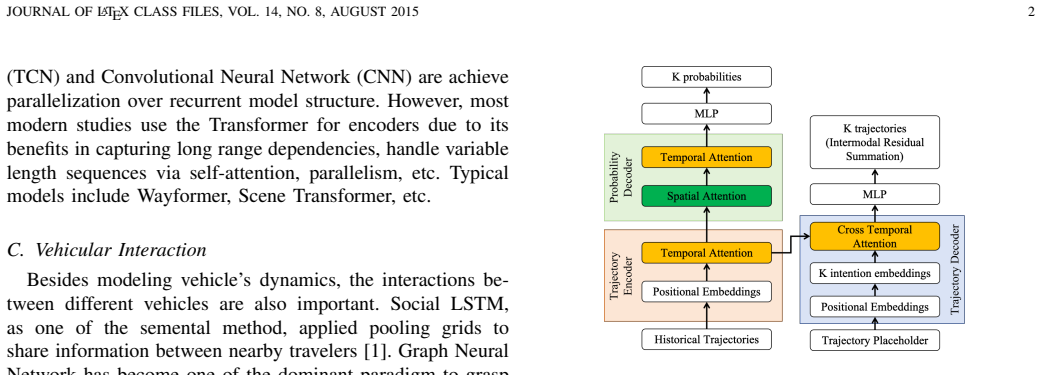
The model uses a Transformer backbone with two independent tracks. The intention track estimates the probability of each of K modes while accounting for surrounding vehicles. The trajectory track then produces the final paths by adding learned residual offsets to K base trajectories, allowing the network to output an ordered, non-redundant collection of future motions.
What carries the argument
Two-track Transformer architecture that isolates intention likelihood prediction from residual-offset trajectory generation.
Load-bearing premise
Separating the intention-prediction track from the trajectory-generation track will not lose critical joint information between spatial context and motion.
What would settle it
Running the two-track model and a single integrated Transformer on the same dataset and finding that the separated version produces lower accuracy or redundant trajectories would show the split discards useful joint information.
Figures

read the original abstract
Predicting vehicle trajectories plays an important role in autonomous driving and ITS applications. Although multiple deep learning algorithms are devised to predict vehicle trajectories, their reliant on specific graph structure (e.g., Graph Neural Network) or explicit intention labeling limit their flexibilities. In this study, we propose a pure Transformer-based network with multiple modals considering their neighboring vehicles. Two separate tracks are employed. One track focuses on predicting the trajectories while the other focuses on predicting the likelihood of each intention considering neighboring vehicles. Study finds that the two track design can increase the performance by separating spatial module from the trajectory generating module. Also, we find the the model can learn an ordered group of trajectories by predicting residual offsets among K trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a pure Transformer-based architecture for multi-modal vehicle trajectory prediction that incorporates information from neighboring vehicles. It employs two separate tracks—one dedicated to trajectory generation and the other to predicting intention likelihoods—and claims that this separation improves performance by isolating the spatial module from trajectory generation. The authors further state that the model learns an ordered group of K trajectories by predicting residual offsets among them.
Significance. If the empirical claims are substantiated, the two-track Transformer design could provide a flexible, graph-structure-free alternative to existing methods for multi-modal prediction in autonomous driving and ITS, while the residual-offset approach offers a potentially lightweight way to produce ordered, non-redundant trajectory modes without explicit intention labels.
major comments (3)
- [Abstract] Abstract: the central claims of performance gains from the two-track design and the ability to learn ordered trajectories via residual offsets rest on an unreported study; no quantitative results, baselines, ablation studies, or error metrics are supplied to support these statements, which are load-bearing for the contribution.
- [§3.2] §3.2: the separation of the intention-prediction track from the trajectory-generation track is presented as beneficial, yet no analysis or ablation demonstrates that critical joint dependencies between spatial context and trajectory modes are preserved after separation.
- [Eq. (4)] Eq. (4) (or equivalent residual computation): the mechanism for producing an ordered set of K trajectories via residual offsets contains no explicit diversity, ordering, or non-redundancy term; if the base trajectory is shared and offsets remain small, mode collapse is possible, and no ablation isolating residual offsets from direct multi-head output is described.
minor comments (2)
- [Abstract] Abstract contains repeated wording ('we find the the model') and a grammatical error ('their reliant on' should read 'their reliance on').
- [Abstract] Title and abstract use both 'multi-modal' and 'multi modal'; standardize hyphenation throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of performance gains from the two-track design and the ability to learn ordered trajectories via residual offsets rest on an unreported study; no quantitative results, baselines, ablation studies, or error metrics are supplied to support these statements, which are load-bearing for the contribution.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. The manuscript reports experimental comparisons against baselines with standard error metrics in Section 4. We will revise the abstract to include key performance numbers demonstrating the gains from the two-track design and residual offsets. revision: yes
-
Referee: [§3.2] §3.2: the separation of the intention-prediction track from the trajectory-generation track is presented as beneficial, yet no analysis or ablation demonstrates that critical joint dependencies between spatial context and trajectory modes are preserved after separation.
Authors: We agree that an ablation study is needed to verify that the separation preserves necessary joint dependencies while isolating the spatial module. We will add this analysis to the revised manuscript. revision: yes
-
Referee: [Eq. (4)] Eq. (4) (or equivalent residual computation): the mechanism for producing an ordered set of K trajectories via residual offsets contains no explicit diversity, ordering, or non-redundancy term; if the base trajectory is shared and offsets remain small, mode collapse is possible, and no ablation isolating residual offsets from direct multi-head output is described.
Authors: We agree that the residual offset approach would benefit from an explicit ablation and discussion of diversity to address potential mode collapse. We will add an ablation comparing residual offsets to direct multi-head prediction, along with diversity metrics, in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical performance claims rest on experiments, not self-referential derivations
full rationale
The paper reports experimental findings on a Transformer architecture with a two-track design (intention likelihood vs. trajectory generation) and residual offsets for multi-modal outputs. These are presented as observed results from training and evaluation rather than mathematical derivations. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described structure. The central claims about performance gains and ordered trajectories are falsifiable empirical statements, not tautological reductions to inputs. The work is self-contained as an applied ML study without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Social LSTM: Human Trajectory Prediction in Crowded Spaces,
A. Alahi, K. Goel, V . Ramanathan, A. Robicquet, L. Fei-Fei, and S. Savarese, “Social LSTM: Human Trajectory Prediction in Crowded Spaces,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV , USA: IEEE, Jun. 2016, pp. 961–
work page 2016
-
[2]
Available: http://ieeexplore.ieee.org/document/7780479/
[Online]. Available: http://ieeexplore.ieee.org/document/7780479/
-
[3]
Grip: Graph-based interaction-aware trajectory prediction,
X. Li, X. Ying, and M. C. Chuah, “Grip: Graph-based interaction-aware trajectory prediction,” in2019 IEEE intelligent transportation systems conference (ITSC). IEEE, 2019, pp. 3960–3966
work page 2019
-
[4]
Vectornet: Encoding hd maps and agent dynamics from vectorized representation,
J. Gao, C. Sun, H. Zhao, Y . Shen, D. Anguelov, C. Li, and C. Schmid, “Vectornet: Encoding hd maps and agent dynamics from vectorized representation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 525–11 533
work page 2020
-
[5]
Social gan: Socially acceptable trajectories with generative adversarial networks,
A. Gupta, J. Johnson, L. Fei-Fei, S. Savarese, and A. Alahi, “Social gan: Socially acceptable trajectories with generative adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2255–2264
work page 2018
-
[6]
Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data,
T. Salzmann, B. Ivanovic, P. Chakravarty, and M. Pavone, “Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data,” in European conference on computer vision. Springer, 2020, pp. 683–700
work page 2020
-
[7]
Motiondiffuser: Controllable multi-agent motion prediction using diffu- sion,
C. Jiang, A. Cornman, C. Park, B. Sapp, Y . Zhou, D. Anguelovet al., “Motiondiffuser: Controllable multi-agent motion prediction using diffu- sion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9644–9653
work page 2023
-
[8]
Leapfrog diffusion model for stochastic trajectory prediction,
W. Mao, C. Xu, Q. Zhu, S. Chen, and Y . Wang, “Leapfrog diffusion model for stochastic trajectory prediction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5517– 5526
work page 2023
-
[9]
R. Feng, H. Zhu, N. Sze, S. Wang, and Z. Li, “Ubiquitous traffic eyes: trajectory dataset focus on multiple traffic states and state transition on urban expressways,”Transportation Letters, vol. 18, no. 2, pp. 446–462, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.