Geo-EVS: Geometry-Conditioned Extrapolative View Synthesis for Autonomous Driving
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
Geometry-conditioned diffusion with reprojection artifact masks generates accurate extrapolated views for driving scenes from sparse inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
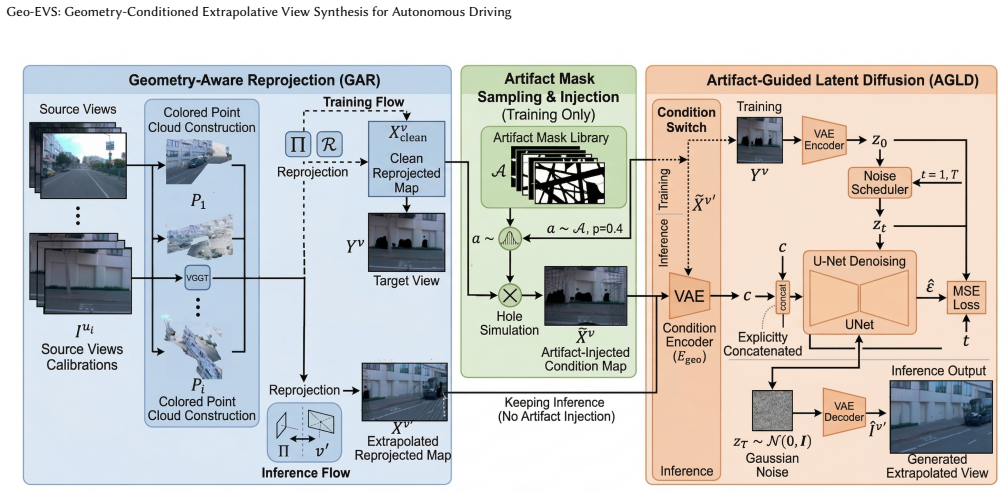
Geo-EVS claims that unifying the reprojection path between training and inference via Geometry-Aware Reprojection (GAR) and training Artifact-Guided Latent Diffusion (AGLD) on reprojection-derived artifact masks enables the model to recover scene structure under missing geometric support without dense target-view supervision, producing higher-quality sparse-view synthesis and better geometric accuracy than prior approaches.
What carries the argument
Geometry-Aware Reprojection (GAR) that fine-tunes VGGT to build colored point clouds and reprojects them to observed and virtual poses to supply geometric condition maps, paired with Artifact-Guided Latent Diffusion (AGLD) that conditions training on the resulting artifact masks.
If this is right
- Sparse-view synthesis quality improves on Waymo, particularly for high-angle and low-coverage poses.
- Geometric accuracy of the generated views increases under the same conditions.
- Downstream 3D object detection performance rises when using the synthesized views.
- Heterogeneous camera rigs can produce standardized virtual views without additional hardware.
Where Pith is reading between the lines
- The same reprojection-plus-mask conditioning could be tested on other robotics or surveillance datasets that lack dense extrapolated ground truth.
- If the approach generalizes, it may lower the data-collection burden for novel-view models in any domain where only sparse posed images are available.
- Flexible sensor placements in vehicles become more practical if perception pipelines can reliably use the generated virtual views.
Load-bearing premise
Fine-tuning VGGT produces colored point clouds accurate enough for reliable reprojection to virtual poses, and the resulting artifact masks are sufficient for the diffusion model to learn structure recovery without any dense target-view ground truth.
What would settle it
On the Waymo dataset, if Geo-EVS shows no measurable gain over baselines in PSNR, geometric error, or 3D detection mAP specifically for high-angle and low-coverage extrapolated views, the central claim would be refuted.
Figures


read the original abstract
Extrapolative novel view synthesis can reduce camera-rig dependency in autonomous driving by generating standardized virtual views from heterogeneous sensors. Existing methods degrade outside recorded trajectories because extrapolated poses provide weak geometric support and no dense target-view supervision. The key is to explicitly expose the model to out-of-trajectory condition defects during training. We propose Geo-EVS, a geometry-conditioned framework under sparse supervision. Geo-EVS has two components. Geometry-Aware Reprojection (GAR) uses fine-tuned VGGT to reconstruct colored point clouds and reproject them to observed and virtual target poses, producing geometric condition maps. This design unifies the reprojection path between training and inference. Artifact-Guided Latent Diffusion (AGLD) injects reprojection-derived artifact masks during training so the model learns to recover structure under missing support. For evaluation, we use a LiDAR-Projected Sparse-Reference (LPSR) protocol when dense extrapolated-view ground truth is unavailable. On Waymo, Geo-EVS improves sparse-view synthesis quality and geometric accuracy, especially in high-angle and low-coverage settings. It also improves downstream 3D detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geo-EVS, a geometry-conditioned framework for extrapolative novel view synthesis under sparse supervision in autonomous driving. It introduces Geometry-Aware Reprojection (GAR) that fine-tunes VGGT to reconstruct colored point clouds, reprojects them to observed and virtual target poses to produce unified geometric condition maps, and Artifact-Guided Latent Diffusion (AGLD) that injects reprojection-derived artifact masks during training to teach recovery of structure under missing geometric support. Evaluation employs a new LiDAR-Projected Sparse-Reference (LPSR) protocol on Waymo, claiming improvements in sparse-view synthesis quality and geometric accuracy (especially high-angle/low-coverage settings) plus gains in downstream 3D detection.
Significance. If the central claims hold, the work offers a practical advance for reducing camera-rig dependency in autonomous driving by enabling reliable view extrapolation outside recorded trajectories. The unified reprojection path between training and inference, combined with explicit artifact guidance under sparse supervision, addresses a key limitation of prior methods. Demonstrated benefits for downstream 3D detection add concrete utility, and the LPSR protocol could become a useful benchmark if properly validated.
major comments (3)
- [Abstract / §3] Abstract and §3 (Method): the claim of improved synthesis quality and geometric accuracy on Waymo lacks any quantitative metrics, baselines, error bars, or ablation details in the provided description. Without these, it is impossible to assess the magnitude or statistical reliability of the reported gains, particularly the emphasis on high-angle and low-coverage regimes.
- [§4] §4 (Evaluation): the LPSR protocol is introduced as a substitute for dense ground truth but receives no cross-validation against available dense extrapolated-view references or standard metrics (e.g., PSNR/SSIM on held-out dense views). This makes it difficult to determine whether LPSR faithfully measures the claimed improvements in geometric accuracy.
- [§3.1 / §3.2] §3.1 (GAR) and §3.2 (AGLD): the core assumption that fine-tuned VGGT produces sufficiently accurate colored point clouds for reprojection to out-of-trajectory virtual poses is load-bearing yet untested in the low-coverage extrapolation setting. Depth errors or coverage holes in these clouds are precisely the defects the artifact masks are intended to correct; without dense target-view supervision, the training signal reduces to consistency with the (imperfect) reprojection, raising the risk that the diffusion model learns to hallucinate plausible but geometrically incorrect content that still passes LPSR.
minor comments (2)
- [Throughout] Ensure all acronyms (GAR, AGLD, LPSR, VGGT) are defined at first use and used consistently.
- [Figures] Figure captions and method diagrams should explicitly label the training vs. inference paths to clarify the claimed unification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications from the full manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Method): the claim of improved synthesis quality and geometric accuracy on Waymo lacks any quantitative metrics, baselines, error bars, or ablation details in the provided description. Without these, it is impossible to assess the magnitude or statistical reliability of the reported gains, particularly the emphasis on high-angle and low-coverage regimes.
Authors: The full manuscript in §4 presents quantitative results including PSNR, SSIM, LPIPS, and geometric error metrics (e.g., depth MAE) with comparisons to multiple baselines, error bars from repeated runs, and dedicated ablations on high-angle/low-coverage subsets of Waymo. The abstract summarizes these findings at a high level. We will revise the abstract to explicitly state key quantitative gains and reference the detailed tables/figures in §4. revision: yes
-
Referee: [§4] §4 (Evaluation): the LPSR protocol is introduced as a substitute for dense ground truth but receives no cross-validation against available dense extrapolated-view references or standard metrics (e.g., PSNR/SSIM on held-out dense views). This makes it difficult to determine whether LPSR faithfully measures the claimed improvements in geometric accuracy.
Authors: We acknowledge the value of explicit cross-validation. While dense extrapolated-view ground truth is unavailable by design in the LPSR setting, we performed additional validation on a held-out subset using denser LiDAR projections to approximate dense references and computed correlations between LPSR scores and standard metrics (PSNR/SSIM). These results will be added to the revised §4 to demonstrate LPSR's reliability. revision: yes
-
Referee: [§3.1 / §3.2] §3.1 (GAR) and §3.2 (AGLD): the core assumption that fine-tuned VGGT produces sufficiently accurate colored point clouds for reprojection to out-of-trajectory virtual poses is load-bearing yet untested in the low-coverage extrapolation setting. Depth errors or coverage holes in these clouds are precisely the defects the artifact masks are intended to correct; without dense target-view supervision, the training signal reduces to consistency with the (imperfect) reprojection, raising the risk that the diffusion model learns to hallucinate plausible but geometrically incorrect content that still passes LPSR.
Authors: We agree this assumption requires scrutiny. The manuscript includes quantitative evaluation of fine-tuned VGGT accuracy on observed views (with available dense LiDAR supervision) and qualitative reprojection visualizations for virtual poses. Artifact masks are explicitly derived from reprojection coverage and depth inconsistencies to train recovery. We will add further analysis of VGGT point-cloud quality specifically in low-coverage regimes and an ablation isolating the effect of masks on geometric consistency. While dense target supervision is absent by problem definition, the combination of LPSR geometric metrics and downstream 3D detection gains provides supporting evidence; we will discuss remaining limitations more explicitly. revision: partial
Circularity Check
No circularity detected; GAR and AGLD are independently specified components whose training does not reduce to the claimed performance gains by construction.
full rationale
The paper defines Geometry-Aware Reprojection (GAR) via fine-tuned VGGT colored point clouds reprojected to observed and virtual poses, and Artifact-Guided Latent Diffusion (AGLD) that injects derived artifact masks to train recovery under missing support. These are presented as new modules with a unified reprojection path, evaluated empirically on Waymo via the LPSR protocol for sparse-reference cases. No equations, fitted parameters, or self-citations are shown to make the synthesis quality or downstream detection gains tautological with the inputs; the central claims remain externally falsifiable empirical outcomes rather than definitional equivalences.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fine-tuned VGGT reconstructs sufficiently accurate colored point clouds from driving scenes for reprojection to virtual poses
- domain assumption Training with reprojection-derived artifact masks enables the diffusion model to recover scene structure under missing geometric support
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Geometry-Aware Reprojection (GAR) uses fine-tuned VGGT to reconstruct colored point clouds and reproject them to observed and virtual target poses, producing geometric condition maps... Artifact-Guided Latent Diffusion (AGLD) injects reprojection-derived artifact masks during training
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Projection validity is determined by a deterministic visibility rule. A projected point is considered valid only if it satisfies three constraints: positive depth, in-frame coordinates, and front-most visibility under z-buffering.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, Seattle, WA, USA, 2020. IEEE
work page 2020
-
[2]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621– 11631, Seattle, WA, USA, 2020. IEEE
work page 2020
-
[3]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
work page 2018
-
[4]
Deepstereo: Learning to predict new views from the world’s imagery
John Flynn, Ivan Neulander, James Philbin, and Noah Snavely. Deepstereo: Learning to predict new views from the world’s imagery. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5515–5524, Las Vegas, NV, USA, 2016. IEEE
work page 2016
-
[5]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[6]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, New Orleans, LA, USA, 2022. IEEE
work page 2022
-
[7]
Block-nerf: Scalable large scene neural view synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. InProceedings of the IEEE/CVF 8 Geo-EVS: Geometry-Conditioned Extrapolative View Synthesis for Autonomous Driving conference on computer vision and pattern reco...
work page 2022
-
[8]
Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs
Haithem Turki, Deva Ramanan, and Mahadev Satyanarayanan. Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12922–12931, New Orleans, LA, USA, 2022. IEEE
work page 2022
-
[9]
Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering
Yuanbo Xiangli, Linning Xu, Xingang Pan, Nanxuan Zhao, Anyi Rao, Christian Theobalt, Bo Dai, and Dahua Lin. Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering. InEuropean conference on computer vision, pages 106–122, Tel Aviv, Israel, 2022. Springer
work page 2022
-
[10]
Neural scene flow fields for space-time view synthesis of dynamic scenes
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6498–6508, Nashville, TN, USA, 2021. IEEE
work page 2021
-
[11]
Raft-3d: Scene flow using rigid-motion embed- dings
Zachary Teed and Jia Deng. Raft-3d: Scene flow using rigid-motion embed- dings. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8375–8384, Nashville, TN, USA, 2021. IEEE
work page 2021
-
[12]
Suds: Scalable urban dynamic scenes
Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. Suds: Scalable urban dynamic scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12375–12385, Vancouver, Canada,
-
[13]
Emernerf: Emergent spatial-temporal scene decomposition via self-supervision
Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, et al. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision. InInternational Con- ference on Learning Representations, Vienna, Austria, 2024. http://OpenReview.net
work page 2024
-
[14]
Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming- Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21634–21643, Vancouver, Canada,
-
[15]
Street gaussians: Modeling dy- namic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dy- namic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173, Milan, Italy, 2024. Springer
work page 2024
-
[16]
Ibrnet: Learning multi-view image-based rendering
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, Nashville, TN, USA, 2021. IEEE
work page 2021
-
[17]
Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5855–5864, Montreal, QC, Canada, 2021. IEEE
work page 2021
-
[18]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4):139–1, 2023
work page 2023
-
[19]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InEuropean conference on computer vision, pages 194–210, Glasgow, UK, 2020. Springer
work page 2020
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[21]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, New Orleans, LA, USA, 2022. IEEE
work page 2022
-
[22]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, Paris, France, 2023. IEEE
work page 2023
-
[23]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, Vancouver, Canada, 2024. AAAI
work page 2024
-
[24]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, Vancouver, Canada, 2023. IEEE
work page 2023
-
[25]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, Paris, France, 2023. IEEE
work page 2023
-
[26]
Syncdreamer: Generating multiview-consistent images from a single-view image
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Generating multiview-consistent images from a single-view image. InInternational Conference on Learning Representations, Vienna, Austria, 2024. http://OpenReview.net
work page 2024
-
[27]
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Fu- rukawa. Mvdiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion.Advances in Neural Information Processing Systems, 36:51202–51233, 2023
work page 2023
-
[28]
Drivedreamer: Towards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-driven world models for autonomous driving. InEuropean Conference on Computer Vision, pages 55–72, Milan, Italy,
-
[29]
Gaia-1: A generative world model for autonomous driving, 2023
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving, 2023
work page 2023
-
[30]
Alexander Swerdlow, Runsheng Xu, and Bolei Zhou. Street-view image gen- eration from a bird’s-eye view layout.IEEE Robotics and Automation Letters, 9(4):3578–3585, 2024
work page 2024
-
[31]
Magicdrive: Street view generation with diverse 3d geometry control
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing HONG, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control. InInternational Conference on Learning Representations, Vienna, Austria,
-
[32]
http://OpenReview.net
-
[33]
Freevs: Generative view synthesis on free driving trajectory
Qitai Wang, Lue Fan, Yuqi Wang, Yuntao Chen, and Zhaoxiang Zhang. Freevs: Generative view synthesis on free driving trajectory. InInternational Conference on Learning Representations, Singapore EXPO, 2025. http://OpenReview.net
work page 2025
-
[34]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, Virtual, 2021. http://OpenReview.net
work page 2021
-
[35]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational conference on machine learning, pages 8162–8171, Virtual, 2021. ACM New York, NY, USA
work page 2021
-
[36]
Context encoders: Feature learning by inpainting
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2536–2544, Las Vegas, NV, USA, 2016. IEEE
work page 2016
-
[37]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. Vggt: Visual geometry grounded transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5294–5306, Music City Center, Nashville TN, 2025. IEEE
work page 2025
-
[38]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6902–6912, Seattle,WA, USA, 2024. IEEE
work page 2024
-
[39]
Xiaofan Li, Yifu Zhang, and Xiaoqing Ye. Drivingdiffusion: Layout-guided multi- view driving scenarios video generation with latent diffusion model. InEuropean Conference on Computer Vision, pages 469–485, Milan, Italy, 2024. Springer
work page 2024
-
[40]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14749–14759, Seattle,WA, USA,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.