Recognition: unknown
Blink: CPU-Free LLM Inference by Delegating the Serving Stack to GPU and SmartNIC
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
Blink removes the host CPU from the steady-state LLM inference path by redistributing tasks to a SmartNIC and persistent GPU kernel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper presents Blink as an end-to-end serving architecture that eliminates the host CPU from the steady-state inference path. Request handling moves to the SmartNIC for direct RDMA delivery into GPU memory, and the GPU runs a persistent kernel that executes batching, scheduling, and KV-cache management independently. When compared to TensorRT-LLM, vLLM, and SGLang, this yields up to 8.47 times lower pre-saturation P99 TTFT, 3.40 times lower P99 TPOT, 2.1 times higher decode throughput, and 48.6 percent lower energy per token, with no degradation under CPU interference that affects the other systems by up to two orders of magnitude.
What carries the argument
The persistent GPU kernel responsible for batching, scheduling, and KV-cache management, supported by SmartNIC RDMA for CPU-free input delivery.
Load-bearing premise
The load-bearing premise is that a persistent GPU kernel can handle all dynamic batching, scheduling, and memory management for LLM inference without CPU assistance, and that SmartNIC RDMA delivery functions reliably for every type of request without new delays.
What would settle it
A direct test would be to subject the server running Blink to heavy CPU interference from concurrent non-inference tasks and verify whether the P99 TTFT and TPOT stay close to the no-interference case, unlike the large degradations observed in CPU-dependent systems.
Figures
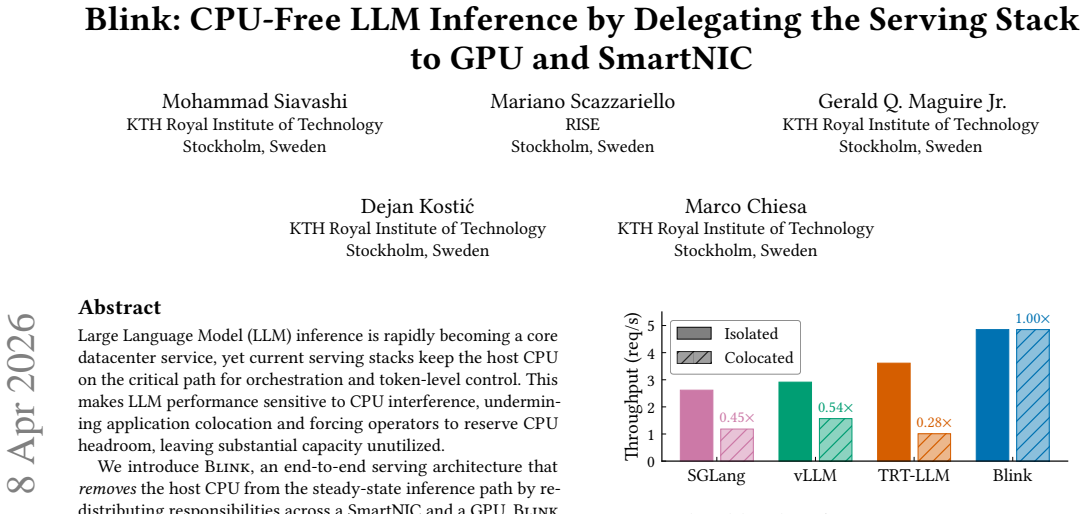






read the original abstract
Large Language Model (LLM) inference is rapidly becoming a core datacenter service, yet current serving stacks keep the host CPU on the critical path for orchestration and token-level control. This makes LLM performance sensitive to CPU interference, undermining application colocation and forcing operators to reserve CPU headroom, leaving substantial capacity unutilized. We introduce Blink, an end-to-end serving architecture that removes the host CPU from the steady-state inference path by redistributing responsibilities across a SmartNIC and a GPU. Blink offloads request handling to the SmartNIC, which delivers inputs directly into GPU memory via RDMA, and replaces host-driven scheduling with a persistent GPU kernel that performs batching, scheduling, and KV-cache management without CPU involvement. Evaluated against TensorRT-LLM, vLLM, and SGLang, Blink outperforms all baselines even in isolation, reducing pre-saturation P99 TTFT by up to 8.47$\times$ and P99 TPOT by up to 3.40$\times$, improving decode throughput by up to 2.1$\times$, and reducing energy per token by up to 48.6$\%$. Under CPU interference, Blink maintains stable performance, while existing systems degrade by up to two orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Blink, an end-to-end LLM serving architecture that removes the host CPU from the steady-state inference path by offloading request handling to a SmartNIC (via RDMA direct delivery into GPU memory) and replacing host-driven orchestration with a persistent GPU kernel that performs dynamic batching, scheduling, and KV-cache management. Evaluated against TensorRT-LLM, vLLM, and SGLang, the system claims up to 8.47× lower pre-saturation P99 TTFT, 3.40× lower P99 TPOT, 2.1× higher decode throughput, 48.6% lower energy per token, and stable performance under CPU interference where baselines degrade by up to two orders of magnitude.
Significance. If the results hold, Blink could meaningfully improve datacenter utilization by enabling safe colocation of LLM inference with CPU-sensitive workloads, eliminating the need to reserve CPU headroom and thereby increasing overall capacity. The design of a fully GPU-resident serving stack with SmartNIC offload is a novel systems direction that, if validated, would influence future AI infrastructure research.
major comments (3)
- [§5] §5 Evaluation: The performance claims (e.g., 8.47× P99 TTFT reduction, stability under interference) are presented without any description of experimental setup, hardware specifications, baseline configurations and tuning, workload traces, number of runs, or statistical analysis such as error bars or confidence intervals. This absence is load-bearing because it prevents verification of whether the data actually support the central claims of outperformance and interference resistance.
- [§3.2] §3.2 (Persistent GPU Kernel): The description of how a single persistent GPU kernel implements all steady-state logic—including dynamic batching, request scheduling, KV-cache allocation/eviction, and token-level control—without CPU involvement or fallback paths lacks concrete details on control-flow restrictions, data-structure management, or synchronization within GPU programming constraints. This is central to both the CPU-free claim and the interference-resistance results; without such specifics, it is impossible to assess whether hidden host interactions undermine the reported gains.
- [§3.1] §3.1 (SmartNIC RDMA Path): The assertion that RDMA delivery from the SmartNIC works seamlessly for arbitrary request types, lengths, and patterns without introducing new latency or compatibility overheads is not supported by targeted microbenchmarks or failure-mode analysis. This assumption is load-bearing for the end-to-end latency and throughput numbers.
minor comments (2)
- The abstract and §1 would benefit from explicit definitions of TTFT and TPOT on first use, as well as clarification of the exact conditions under which the 'up to' speedups were measured.
- [§5] Evaluation figures lack sufficient detail in captions regarding axes, workload parameters, and the precise baseline versions/tunings used for each comparison.
Simulated Author's Rebuttal
Thank you for the detailed review and valuable feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our presentation of Blink. Below, we provide point-by-point responses to the major comments, and we commit to incorporating the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [§5] §5 Evaluation: The performance claims (e.g., 8.47× P99 TTFT reduction, stability under interference) are presented without any description of experimental setup, hardware specifications, baseline configurations and tuning, workload traces, number of runs, or statistical analysis such as error bars or confidence intervals. This absence is load-bearing because it prevents verification of whether the data actually support the central claims of outperformance and interference resistance.
Authors: We agree that the evaluation section would benefit from more comprehensive details on the experimental methodology. In the revised manuscript, we will expand §5 to include a full description of the hardware platform (including specific GPU, SmartNIC, and CPU models), baseline system configurations and any tuning applied, the workload traces and request patterns used, the number of experimental runs performed, and statistical measures such as standard deviations or confidence intervals for the reported metrics. This will enable independent verification of the performance claims. revision: yes
-
Referee: [§3.2] §3.2 (Persistent GPU Kernel): The description of how a single persistent GPU kernel implements all steady-state logic—including dynamic batching, request scheduling, KV-cache allocation/eviction, and token-level control—without CPU involvement or fallback paths lacks concrete details on control-flow restrictions, data-structure management, or synchronization within GPU programming constraints. This is central to both the CPU-free claim and the interference-resistance results; without such specifics, it is impossible to assess whether hidden host interactions undermine the reported gains.
Authors: The persistent GPU kernel in Blink is designed to handle all steady-state operations using CUDA primitives, with dynamic batching managed through atomic counters and a custom scheduler loop that runs continuously on the GPU. KV-cache management uses a GPU-resident data structure with eviction policies implemented via parallel scans. We will revise §3.2 to include detailed pseudocode, descriptions of synchronization mechanisms (such as __syncthreads and atomic operations), control flow restrictions imposed by the GPU execution model, and explicit statements confirming the absence of CPU fallback paths or host interactions during inference. This will provide the necessary concreteness to evaluate the design. revision: yes
-
Referee: [§3.1] §3.1 (SmartNIC RDMA Path): The assertion that RDMA delivery from the SmartNIC works seamlessly for arbitrary request types, lengths, and patterns without introducing new latency or compatibility overheads is not supported by targeted microbenchmarks or failure-mode analysis. This assumption is load-bearing for the end-to-end latency and throughput numbers.
Authors: We recognize that additional microbenchmarks would strengthen the support for the RDMA offload path. In the revision, we will add targeted experiments in §3.1 measuring RDMA transfer latencies and throughputs for varying request sizes, types, and arrival patterns. We will also include an analysis of potential failure modes, such as handling of network variability or buffer overflows, and how the SmartNIC and GPU kernel mitigate them. The end-to-end results demonstrate the overall effectiveness, but these additions will address the specific concerns raised. revision: yes
Circularity Check
Empirical systems paper with no derivations or self-referential claims
full rationale
The paper describes a systems architecture (SmartNIC + persistent GPU kernel) and reports benchmark results against TensorRT-LLM, vLLM, and SGLang. No equations, fitted parameters, uniqueness theorems, or derivation steps appear in the abstract or described content. Performance claims are empirical measurements, not predictions derived from the architecture itself. No self-citation load-bearing steps or ansatz smuggling are present. This matches the default case of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SmartNIC hardware can handle request intake and deliver inputs directly to GPU memory via RDMA without host CPU intervention
- domain assumption A persistent GPU kernel is feasible and can perform batching, scheduling, and KV-cache management without CPU involvement
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, et al . 2024. Phi-4 Technical Report. (2024). arXiv:2412.08905 [cs.CL]https://arxiv.org/abs/2412.08905
work page internal anchor Pith review arXiv 2024
-
[2]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Santa Clara, CA
2024
-
[3]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). Asso- ciation for Computational Linguistics, 4895–4901
2023
-
[4]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, et al. 2022. DeepSpeed-Inference: Enabling Efficient Inference of Trans- former Models at Unprecedented Scale. InProceedings of the International Con- ference for High Performance Computing, Networking, Storage and Analysis (SC)
2022
-
[5]
Arm. 2026. Arm AGI CPU.https://www.arm.com/products/cloud-datacenter/ arm-agi-cpu
2026
-
[6]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[7]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[8]
Ina Fried. 2024. OpenAI says ChatGPT usage has doubled in the last year.https: //www.axios.com/2024/08/29/openai-chatgpt-200-million-weekly-active-users
2024
-
[9]
Joshua Fried, Zhenyuan Ruan, Amy Ousterhout, and Adam Belay. 2020. Caladan: Mitigating Interference at Microsecond Timescales. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association
2020
-
[10]
Georgi Gerganov et al. 2023. llama.cpp: LLM Inference in C/C++.https://github. com/ggml-org/llama.cpp
2023
-
[11]
Jeff Gilchrist. 2004. Parallel Data Compression with bzip2. InProceedings of the 16th IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS). 559–564
2004
- [12]
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, et al . 2024. The Llama 3 Herd of Models. (2024). arXiv:2407.21783 [cs.AI]https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
Ranggi Hwang, Jianyu Wei, Shijie Cao, Changho Hwang, Xiaohu Tang, Ting Cao, and Mao Yang. 2024. Pre-Gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA ’24). IEEE Press, 1018–1031. doi:10.1109/ISCA59077.2024.00078
-
[16]
Intel. 2024. Intel Resource Director Technology (Intel RDT).https: //www.intel.com/content/www/us/en/architecture-and-technology/resource- director-technology.html
2024
-
[17]
Zhen Jin, Yiquan Chen, Mingxu Liang, Yijing Wang, Guoju Fang, Ao Zhou, Keyao Zhang, Jiexiong Xu, Wenhai Lin, Yiquan Lin, Shushu Zhao, Wenkai Shi, Zhenhua He, Shishun Cai, and Wenzhi Chen. 2025. OS2G: A High-Performance DPU Offloading Architecture for GPU-based Deep Learning with Object Storage. In Proceedings of the 30th ACM International Conference on Ar...
2025
-
[18]
Elie Kfoury, Samia Choueiri, Ali Mazloum, Ali AlSabeh, Jose Gomez, and Jorge Crichigno. 2024. A Comprehensive Survey on SmartNICs: Architectures, Devel- opment Models, Applications, and Research Directions.IEEE Access12 (2024), 107297–107336. doi:10.1109/ACCESS.2024.3437203
-
[19]
Adithya Kumar, Anand Sivasubramaniam, and Timothy Zhu. 2023. SplitRPC: A Control + Data Path Splitting RPC Stack for ML Inference Serving.Proc. ACM Meas. Anal. Comput. Syst.7, 2, Article 30 (2023), 26 pages. doi:10.1145/3589974
-
[20]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
2023
-
[21]
Lamprakos, Lazaros Papadopoulos, Francky Catthoor, and Dimitrios Soudris
Christos P. Lamprakos, Lazaros Papadopoulos, Francky Catthoor, and Dimitrios Soudris. 2022. The Impact of Dynamic Storage Allocation on CPython Execu- tion Time, Memory Footprint and Energy Consumption: An Empirical Study. InEmbedded Computer Systems: Architectures, Modeling, and Simulation, Alex Orailoglu, Marc Reichenbach, and Matthias Jung (Eds.). Spri...
2022
- [22]
-
[23]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InProceedings of the 40th International Conference on Machine Learning (ICML)
2023
-
[24]
Evan Martin. 2012. Ninja: A Small Build System with a Focus on Speed.https: //ninja-build.org
2012
-
[25]
NVIDIA. 2019. NVIDIA TensorRT.https://github.com/NVIDIA/TensorRT
2019
-
[26]
NVIDIA. 2023. TensorRT-LLM.https://github.com/NVIDIA/TensorRT-LLM
2023
-
[27]
NVIDIA. 2024. CUDA Graphs.https://docs.nvidia.com/cuda/cuda-programming- guide/04-special-topics/cuda-graphs.html
2024
-
[28]
NVIDIA. 2024. CUDA Graphs — Device Graph Launch.https: //docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/cuda- graphs.html#device-graph-launch
2024
-
[29]
NVIDIA. 2024. CUDA Graphs — Fire and Forget Launch.https: //docs.nvidia.com/cuda/cuda-programming-guide/04-special-topics/cuda- graphs.html#fire-and-forget-launch
2024
-
[30]
NVIDIA. 2024. Enabling Dynamic Control Flow in CUDA Graphs with Device Graph Launch.https://developer.nvidia.com/blog/enabling-dynamic-control- flow-in-cuda-graphs-with-device-graph-launch/
2024
-
[31]
NVIDIA. 2024. NVIDIA-Certified Systems Configuration Guide. https://docs.nvidia.com/certification-programs/latest/nvidia-certified- configuration-guide.html
2024
-
[32]
NVIDIA. 2026. Nsight Systems.https://developer.nvidia.com/nsight-systems
2026
-
[33]
OpenChat Team. 2023. OpenChat ShareGPT v3 Dataset.https://huggingface.co/ datasets/openchat/openchat_sharegpt_v3
2023
-
[34]
Amy Ousterhout, Joshua Fried, Jonathan Behrens, Adam Belay, and Hari Balakr- ishnan. 2019. Shenango: Achieving High CPU Efficiency for Latency-sensitive Datacenter Workloads. InProceedings of the 16th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI)
2019
-
[35]
Seo Jin Park, Ramesh Govindan, Kai Shen, David Culler, Fatma Özcan, Geon- Woo Kim, and Hank Levy. 2025. Lovelock: Towards Smart NIC-Hosted Clusters. SIGENERGY Energy Inform. Rev.4, 5 (April 2025), 172–179. doi:10.1145/3727200. 3727226
-
[36]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Des- maison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, Hi...
2019
-
[37]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2025
-
[38]
Gon- zalez, Ion Stoica, and Harry Xu
Yifan Qiao, Shu Anzai, Shan Yu, Haoran Ma, Shuo Yang, Yang Wang, Miryung Kim, Yongji Wu, Yang Zhou, Jiarong Xing, Joseph E. Gonzalez, Ion Stoica, and Harry Xu. 2025. ConServe: Fine-Grained GPU Harvesting for LLM Online and Offline Co-Serving. arXiv:2410.01228 [cs.DC]https://arxiv.org/abs/2410.01228
-
[39]
SGLang Team. 2024. SGLang v0.4: Zero-Overhead Batch Scheduler, FP8 Cache, and More.https://www.lmsys.org/blog/2024-12-04-sglang-v0-4/
2024
-
[40]
Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need. (2019). arXiv:1911.02150 [cs.NE]https://arxiv.org/abs/1911.02150
work page internal anchor Pith review arXiv 2019
-
[41]
Ying Sheng et al. 2023. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. InProceedings of the 40th International Conference on Machine Learning (ICML)
2023
- [42]
-
[43]
Vikranth Srivatsa, Dongming Li, Yiying Zhang, and Reyna Abhyankar. 2024. Can Scheduling Overhead Dominate LLM Inference Performance? A Study of CPU Scheduling Overhead on Two Popular LLM Inference Systems.https: //mlsys.wuklab.io/posts/scheduling_overhead/
2024
-
[44]
Ting Sun, Penghan Wang, and Fan Lai. 2025. HyGen: Efficient LLM Serving via Elastic Online-Offline Request Co-location. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[45]
Maroun Tork, Lina Maudlej, and Mark Silberstein. 2020. Lynx: A SmartNIC- driven Accelerator-centric Architecture for Network Servers. InProceedings of the 25th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). ACM. doi:10.1145/3373376.3378528
-
[46]
Kamath, Ramya Prabhu, Jayashree Mohan, Simon Pe- ter, Ramachandran Ramjee, and Ashish Panwar
Abhishek Vijaya Kumar, Gianni Antichi, and Rachee Singh. 2025.Aqua: Network- Accelerated Memory Offloading for LLMs in Scale-Up GPU Domains. Association for Computing Machinery, New York, NY, USA, 48–62.https://doi.org/10.1145/ 3676641.3715983
-
[47]
2026.vLLM Documentation — Process Count Summary.https://docs.vllm
vLLM. 2026.vLLM Documentation — Process Count Summary.https://docs.vllm. ai/en/v0.16.0/design/arch_overview/#process-count-summary
2026
-
[48]
2026.vLLM Documentation — V1 Process Architecture.https://docs.vllm
vLLM. 2026.vLLM Documentation — V1 Process Architecture.https://docs.vllm. ai/en/v0.16.0/design/arch_overview/#v1-process-architecture
2026
-
[49]
vLLM Project. 2025. GuideLLM: Evaluate and Enhance Your LLM Deployments for Real-World Inference Needs.https://github.com/vllm-project/guidellm. 13
2025
-
[50]
vLLM Team. 2025. vLLM V1: A Major Upgrade to vLLM’s Core Architecture. https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
2025
-
[51]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2026. FastServe: Iteration-Level Preemptive Scheduling for Large Language Models. InProceedings of the 23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI)
2026
-
[52]
Yunming Xiao, Diman Zad Tootaghaj, Aditya Dhakal, Lianjie Cao, Puneet Sharma, and Aleksandar Kuzmanovic. 2024. Conspirator: SmartNIC-Aided Control Plane for Distributed ML Workloads. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Association, Santa Clara, CA, 767–784.https://www. usenix.org/conference/atc24/presentation/xiao
2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al . 2025. Qwen3 Technical Report. (2025). arXiv:2505.09388 [cs.CL]https://arxiv.org/abs/ 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung- Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 521–538. https://www.usenix.org/conference/osdi22/presentation/yu
2022
-
[55]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library.https://github.com/deepseek-ai/DeepEP
2025
-
[56]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[57]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Associ- ation, Santa Clara, CA, 193–210.https://www.usenix.org/con...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.