Recognition: no theorem link
Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
Squeeze Evolve orchestrates multiple models by marginal utility to let verifier-free evolution match or exceed verifier-based performance at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
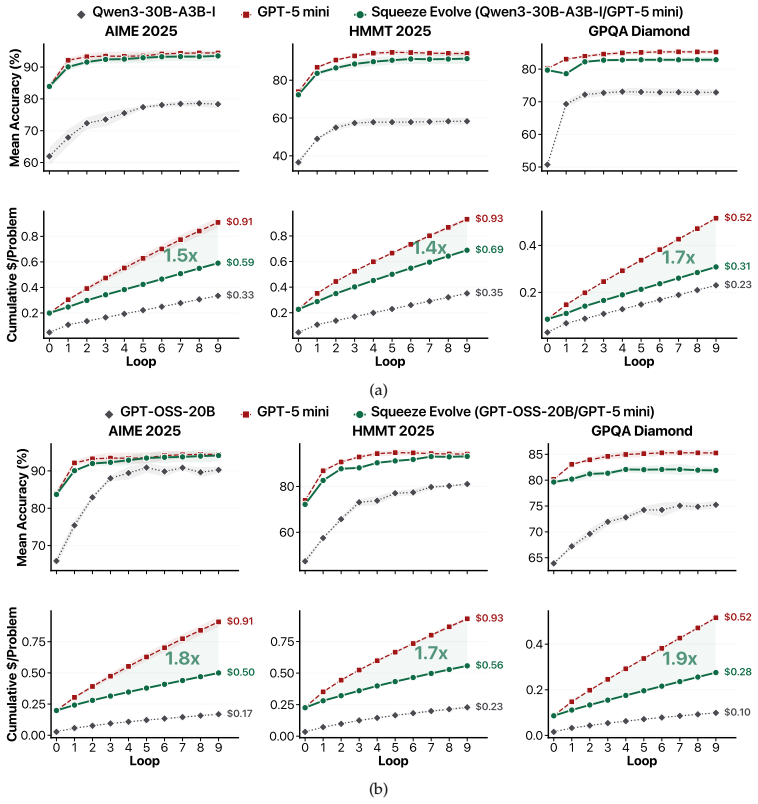
We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference. Guided by the principle of allocating model capability where it has the highest marginal utility, stronger models are reserved for high-impact stages while cheaper models handle the other stages at much lower costs. This principle addresses diversity collapse and cost-efficiency jointly while remaining lightweight. Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, MMMU-Pro, and BabyVision, Squeeze Evolve consistently improves the cost-capability frontier over single-model evolution, achieves new state-of-the-art results on several tasks, reduces API cost
What carries the argument
The marginal utility allocation principle that reserves stronger models for high-impact stages and cheaper models for the rest of the evolutionary process.
If this is right
- Consistent outperformance over single-model evolution on mathematical reasoning, coding, and multimodal tasks.
- New state-of-the-art results on several listed benchmarks without external verifiers.
- Up to 3 times lower API cost and up to 10 times higher fixed-budget throughput.
- Natural support for open-source, closed-source, and mixed-model deployments.
Where Pith is reading between the lines
- The same allocation logic could be tested in other multi-stage inference pipelines beyond evolution to reduce compute waste.
- Longer evolutionary runs might reveal whether the marginal utility rule continues to prevent mode collapse at larger scales.
- Practical deployments in settings with limited verifier access could become feasible if the cost and performance gains hold.
Load-bearing premise
Reserving stronger models for high-impact stages based on marginal utility jointly solves diversity collapse and cost issues without introducing new failure modes in the evolutionary process.
What would settle it
A head-to-head run on AIME 2025 or GPQA-Diamond where Squeeze Evolve fails to match verifier-based performance or shows no reduction in API cost under matched budgets.
Figures
















read the original abstract
We show that verifier-free evolution is bottlenecked by both diversity and efficiency: without external correction, repeated evolution accelerates collapse toward narrow modes, while the uniform use of a high-cost model wastes compute and quickly becomes economically impractical. We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference. Our approach is guided by a simple principle: allocate model capability where it has the highest marginal utility. Stronger models are reserved for high-impact stages, while cheaper models handle the other stages at much lower costs. This principle addresses diversity and cost-efficiency jointly while remaining lightweight. Squeeze Evolve naturally supports open-source, closed-source, and mixed-model deployments. Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision, Squeeze Evolve consistently improves the cost-capability frontier over single-model evolution and achieves new state-of-the-art results on several tasks. Empirically, Squeeze Evolve reduces API cost by up to $\sim$3$\times$ and increases fixed-budget serving throughput by up to $\sim$10$\times$. Moreover, on discovery tasks, Squeeze Evolve is the first verifier-free evolutionary method to match, and in some cases exceed, the performance of verifier-based evolutionary methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that verifier-free evolutionary inference is limited by diversity collapse (narrow modes under repeated evolution without external correction) and inefficiency (uniform use of high-cost models). It introduces Squeeze Evolve, a lightweight multi-model orchestration framework that allocates stronger models exclusively to high-impact stages according to a marginal-utility principle while using cheaper models elsewhere. This is said to jointly mitigate diversity loss and cost, support mixed open/closed-source deployments, and yield up to 3× lower API cost and 10× higher throughput. On AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, MMMU-Pro and BabyVision, the method reportedly improves the cost-capability frontier and, on discovery tasks, is the first verifier-free evolutionary approach to match or exceed verifier-based baselines.
Significance. If the orchestration mechanism and empirical gains are rigorously validated, the work could meaningfully advance practical verifier-free evolution by lowering barriers to mixed-model use and addressing the two stated bottlenecks. The reported cost and throughput improvements would be practically relevant for scaling evolutionary methods. However, the significance is currently limited by the absence of any description of the stage-impact proxy, diversity metrics, or ablations, which prevents assessment of whether the central assumption holds.
major comments (4)
- [§3] §3 (Method): No algorithm, metric, or proxy is supplied for identifying 'high-impact stages' or computing marginal utility in a verifier-free setting. Without this, it is impossible to evaluate whether the allocation rule avoids the two failure modes raised in the skeptic note (biased trajectories or starvation of useful variation).
- [§4] §4 (Experiments): No diversity statistics (population variance, edit distance, semantic entropy, or mode-collapse measures) are reported for Squeeze Evolve versus single-model baselines, leaving the claim that the method 'addresses diversity collapse' unverified.
- [§4.3] §4.3 and Table 4: Ablation studies isolating the contribution of the marginal-utility allocation (versus uniform multi-model or random allocation) are absent; the performance gains cannot be attributed to the proposed principle.
- [§5] §5 (Discovery-task results): The claim that Squeeze Evolve is 'the first verifier-free method to match or exceed verifier-based evolutionary methods' requires a direct, controlled comparison table with prior verifier-based work (including identical budgets and seeds); the current presentation does not supply it.
minor comments (3)
- The title uses 'Squeeze Evolve' but the manuscript never defines what 'squeeze' refers to (model compression, stage compression, or something else).
- Figure captions and axis labels in the cost-throughput plots should explicitly state the exact model mix and budget used for each point.
- The abstract states 'naturally supports open-source, closed-source, and mixed-model deployments' but provides no implementation details or failure cases for API-rate or context-length mismatches.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will make the indicated revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method): No algorithm, metric, or proxy is supplied for identifying 'high-impact stages' or computing marginal utility in a verifier-free setting. Without this, it is impossible to evaluate whether the allocation rule avoids the two failure modes raised in the skeptic note (biased trajectories or starvation of useful variation).
Authors: We agree that the description of the stage-impact proxy requires expansion for full reproducibility. The proxy combines a lightweight performance-delta estimate (via a small pilot set) with a semantic-entropy diversity term to allocate stronger models only where marginal gains are highest. We will insert a formal algorithm box and pseudocode in §3 that explicitly defines the verifier-free computation, including safeguards against biased trajectories and variation starvation. revision: yes
-
Referee: [§4] §4 (Experiments): No diversity statistics (population variance, edit distance, semantic entropy, or mode-collapse measures) are reported for Squeeze Evolve versus single-model baselines, leaving the claim that the method 'addresses diversity collapse' unverified.
Authors: The referee correctly notes the absence of explicit diversity metrics. While end-task gains on discovery benchmarks provide indirect support, we will add a dedicated subsection in §4 reporting population variance, edit distance, and semantic entropy for Squeeze Evolve against single-model baselines across all tasks. revision: yes
-
Referee: [§4.3] §4.3 and Table 4: Ablation studies isolating the contribution of the marginal-utility allocation (versus uniform multi-model or random allocation) are absent; the performance gains cannot be attributed to the proposed principle.
Authors: We acknowledge that targeted ablations isolating the marginal-utility rule are missing. We will add controlled ablation experiments in §4.3 (and update Table 4) comparing marginal-utility allocation against uniform multi-model and random allocation under identical budgets, thereby attributing gains specifically to the proposed principle. revision: yes
-
Referee: [§5] §5 (Discovery-task results): The claim that Squeeze Evolve is 'the first verifier-free method to match or exceed verifier-based evolutionary methods' requires a direct, controlled comparison table with prior verifier-based work (including identical budgets and seeds); the current presentation does not supply it.
Authors: We will revise §5 to include a direct comparison table against prior verifier-based methods, enforcing identical computational budgets and reporting results under matched random seeds to substantiate the claim with controlled evidence. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmarks, not self-referential derivations
full rationale
The paper describes Squeeze Evolve via a high-level principle of marginal-utility model allocation without any equations, fitted parameters, or derivations. Performance claims are supported solely by empirical results on external benchmarks (AIME, GPQA, ARC-AGI, etc.) rather than by predictions that reduce to the method's own inputs or self-citations. No self-definitional loops, fitted-input predictions, or load-bearing self-citation chains appear in the derivation chain.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
FrontierSmith automates synthesis of open-ended coding problems from closed-ended seeds and shows measurable gains on two open-ended LLM coding benchmarks.
Reference graph
Works this paper leans on
-
[1]
Arora, Yu Bai, Bowen Baker, and Haiming Bao et al
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, and Haiming Bao et al. gpt-oss-120b & gpt-oss-20b model card, 2025
2025
-
[2]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026
2026
-
[3]
Anthropic. Pricing. https://platform.claude.com/docs/en/about-claude/pricing, 2026. Claude API pricing page, accessed March 16, 2026
2026
-
[4]
Codeevolve: an open source evolutionary coding agent for algorithmic discovery and optimization, 2026
Henrique Assumpção, Diego Ferreira, Leandro Campos, and Fabricio Murai. Codeevolve: an open source evolutionary coding agent for algorithmic discovery and optimization, 2026
2026
-
[5]
Matharena: Evaluating llms on uncontaminated math competitions, 2026
Mislav Balunovi´ c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´ c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, 2026
2026
-
[6]
Tran, and Mehran Kazemi
Hritik Bansal, Arian Hosseini, Rishabh Agarwal, Vinh Q. Tran, and Mehran Kazemi. Smaller, weaker, yet better: Training llm reasoners via compute-optimal sampling, 2024
2024
-
[7]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024
2024
-
[8]
Adaevolve: Adaptive llm driven zeroth-order optimization, 2026
Mert Cemri, Shubham Agrawal, Akshat Gupta, Shu Liu, Audrey Cheng, Qiuyang Mang, Ashwin Naren, Lutfi Eren Erdogan, Koushik Sen, Matei Zaharia, Alex Dimakis, and Ion Stoica. Adaevolve: Adaptive llm driven zeroth-order optimization, 2026. 14
2026
-
[9]
Liang Chen, Weichu Xie, Yiyan Liang, Hongfeng He, Hans Zhao, Zhibo Yang, Zhiqi Huang, Haoning Wu, Haoyu Lu, Y. charles, Yiping Bao, Yuantao Fan, Guopeng Li, Haiyang Shen, Xuanzhong Chen, Wendong Xu, Shuzheng Si, Zefan Cai, Wenhao Chai, Ziqi Huang, Fangfu Liu, Tianyu Liu, Baobao Chang, Xiaobo Hu, Kaiyuan Chen, Yixin Ren, Yang Liu, Yuan Gong, and Kuan Li. B...
2026
-
[10]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
François Chollet, Mike Knoop, Greg Kamradt, and Chris Landers. ARC-AGI-2: A new challenge for frontier AI reasoning systems.arXiv preprint arXiv:2505.11831, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[12]
State-of-the-art ARC-AGI-2 solver, 2026
Confluence Labs. State-of-the-art ARC-AGI-2 solver, 2026. GitHub repository, accessed March 2026
2026
-
[13]
Deep think with confidence, 2025
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence, 2025
2025
-
[14]
Gemini developer api pricing
Google. Gemini developer api pricing. https://ai.google.dev/gemini-api/docs/pricing, 2026. Google AI for Developers pricing page, accessed March 16, 2026
2026
-
[15]
Gemini 3 Flash model card
Google DeepMind. Gemini 3 Flash model card. Technical report, Google DeepMind, December 2025
2025
-
[16]
Gemini 3.1 Pro model card
Google DeepMind. Gemini 3.1 Pro model card. Technical report, Google DeepMind, February 2026
2026
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, and Xiao et al. Bi. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, September 2025
2025
-
[18]
N. T. Howard, C. Holland, A. E. White, M. Greenwald, and J. Candy. Multi-scale gyrokinetic simulation of tokamak plasmas: enhanced heat loss due to cross-scale coupling of plasma turbulence.Nuclear Fusion, 56, 2016
2016
-
[19]
Beating ARC-AGI-2 with code evolution, 2026
Imbue. Beating ARC-AGI-2 with code evolution, 2026. Blog post, accessed March 2026
2026
-
[20]
Openai o1 system card, 2024
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, and Alex Carney et al. Openai o1 system card, 2024
2024
-
[21]
Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
2024
-
[22]
Making, not taking, the best of n, 2025
Ammar Khairi, Daniel D’souza, Marzieh Fadaee, and Julia Kreutzer. Making, not taking, the best of n, 2025
2025
-
[23]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[24]
Shinkaevolve: Towards open-ended and sample-efficient program evolution, 2025
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution, 2025
2025
-
[25]
Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O. Stanley. Evolution through large models, 2022
2022
-
[26]
Llms can generate a better answer by aggregating their own responses, 2025
Zichong Li, Xinyu Feng, Yuheng Cai, Zixuan Zhang, Tianyi Liu, Chen Liang, Weizhu Chen, Haoyu Wang, and Tuo Zhao. Llms can generate a better answer by aggregating their own responses, 2025
2025
-
[27]
Let’s verify step by step, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023
2023
-
[28]
Pan, Alexander Du, Kurt Keutzer, Alvin Cheung, Alexandros G
Shu Liu, Shubham Agarwal, Monishwaran Maheswaran, Mert Cemri, Zhifei Li, Qiuyang Mang, Ashwin Naren, Ethan Boneh, Audrey Cheng, Melissa Z. Pan, Alexander Du, Kurt Keutzer, Alvin Cheung, Alexandros G. Dimakis, Koushik Sen, Matei Zaharia, and Ion Stoica. Evox: Meta-evolution for automated discovery, 2026
2026
-
[29]
When does verification pay off? a closer look at llms as solution verifiers, 2025
Jack Lu, Ryan Teehan, Jinran Jin, and Mengye Ren. When does verification pay off? a closer look at llms as solution verifiers, 2025
2025
-
[30]
Self-refine: Iterative refinement with self-feedback, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. 15
2023
-
[31]
Rethinking thinking tokens: Llms as improvement operators, 2025
Lovish Madaan, Aniket Didolkar, Suchin Gururangan, John Quan, Ruan Silva, Ruslan Salakhutdinov, Manzil Zaheer, Sanjeev Arora, and Anirudh Goyal. Rethinking thinking tokens: Llms as improvement operators, 2025
2025
-
[32]
Mahoney, Kurt Keutzer, and Amir Gholami
Monishwaran Maheswaran, Rishabh Tiwari, Yuezhou Hu, Kerem Dilmen, Coleman Hooper, Haocheng Xi, Nicholas Lee, Mehrdad Farajtabar, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. Arbitrage: Efficient reasoning via advantage-aware speculation, 2025
2025
-
[33]
s1: Simple test-time scaling, 2025
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025
2025
-
[34]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
2025
-
[35]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data, 2025
2025
-
[36]
GPT-5 system card
OpenAI. GPT-5 system card. Technical report, OpenAI, August 2025
2025
-
[37]
o4-mini model
OpenAI. o4-mini model. https://developers.openai.com/api/docs/models/o4-mini, 2026. OpenAI API model page, accessed March 16, 2026
2026
-
[38]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[39]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[40]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625(7995):468– 475, 2024
2024
-
[41]
Scaling test-time compute without verification or rl is suboptimal, 2025
Amrith Setlur, Nived Rajaraman, Sergey Levine, and Aviral Kumar. Scaling test-time compute without verification or rl is suboptimal, 2025
2025
-
[42]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025
2025
-
[43]
Harman Singh, Xiuyu Li, Kusha Sareen, Monishwaran Maheswaran, Sijun Tan, Xiaoxia Wu, Junxiong Wang, Alpay Ariyak, Qingyang Wu, Samir Khaki, Rishabh Tiwari, Long Lian, Yucheng Lu, Boyi Li, Alane Suhr, Ben Athiwaratkun, and Kurt Keutzer.v 1: Unifying generation and self-verification for parallel reasoners, 2026
2026
-
[44]
Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024
2024
-
[45]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y. Charles, H. S. Che, Cheng Chen, Guanduo Chen, and Huarong Chen et al. Kimi k2.5: Visual agentic intelligence, 2026
2026
-
[46]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[47]
gpt-oss-120b api
Together AI. gpt-oss-120b api. https://www.together.ai/models/gpt-oss-120b, 2026. Together AI model page, accessed March 16, 2026
2026
-
[48]
Qwen3 235b a22b instruct 2507 fp8 api
Together AI. Qwen3 235b a22b instruct 2507 fp8 api. https://www.together.ai/models/ qwen3-235b-a22b-instruct-2507-fp8, 2026. Together AI model page, accessed March 16, 2026
2026
-
[49]
C3po: Optimized large language model cascades with probabilistic cost constraints for reasoning, 2025
Antonios Valkanas, Soumyasundar Pal, Pavel Rumiantsev, Yingxue Zhang, and Mark Coates. C3po: Optimized large language model cascades with probabilistic cost constraints for reasoning, 2025
2025
-
[50]
Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, Nikolay Malkin, and Moksh Jain
Siddarth Venkatraman, Vineet Jain, Sarthak Mittal, Vedant Shah, Johan Obando-Ceron, Yoshua Bengio, Brian R. Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, Nikolay Malkin, and Moksh Jain. Recursive self-aggregation unlocks deep thinking in large language models, 2026
2026
-
[51]
Mixture-of-agents enhances large language model capabilities, 2024
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities, 2024. 16
2024
-
[52]
Self-consistency improves chain of thought reasoning in language models, 2023
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023
2023
-
[53]
Large language models are better reasoners with self-verification, 2023
Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification, 2023
2023
-
[54]
Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models, 2025
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models, 2025
2025
-
[55]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023
2023
-
[56]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark, 2025
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark, 2025
2025
-
[57]
Learning to discover at test time, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time, 2026
2026
-
[58]
Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, 2024
Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, 2024
2024
-
[59]
Generative verifiers: Reward modeling as next-token prediction, 2025
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction, 2025
2025
-
[60]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs, 2024
2024
-
[61]
x y r " ( nine decimal digits each ) 17to stdout . 18
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models, 2024. 17 Appendix A Related Work Test-time scaling.Test-time scaling invests additional inference compute to improve output quality [44, 54], through parallel sampling [52, 7], sequential refi...
2024
-
[62]
ndarray , np
->tuple[ np . ndarray , np . ndarray ,float]: 146best_c = start . copy () 147best_r , best_sum = _lp_optimal ( best_c ) 148 149temperature = 0.02 150foritin range( iterations ) : 151cand_c = best_c . copy () 152k = rng . integers (1 , 4) 153sel = rng . choice (N , size =k , replace = False ) 154max_step = 0.09 * (1.0 - it / iterations ) + 0.005 155cand_c ...
-
[63]
{:.9 f } {:.9 f } {:.9 f }\ n
->tuple[ np . ndarray , np . ndarray ,float]: 174if not_SCIPY : 175returncentres , radii_start , radii_start .sum() 176 177n = N 178x0 = np . empty (3 * n ) 179x0 [: n ] = centres [: , 0] 180x0 [ n :2 * n ] = centres [: , 1] 181x0 [2 * n :] = radii_start 182 183bounds = ([(0.0 , 1.0) ] * n 184+ [(0.0 , 1.0) ] * n 185+ [(0.0 , None ) ] * n ) 186 187defcons...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.