Recognition: no theorem link
The Cartesian Cut in Agentic AI
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
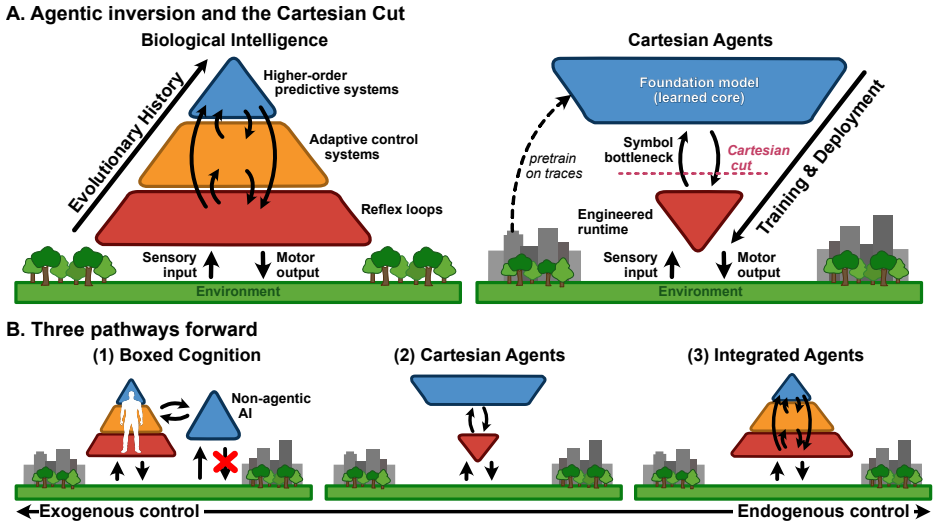
LLM agents implement Cartesian agency by coupling a learned predictive core to an external engineered runtime via a symbolic interface.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs gain competence by predicting words in human text, which often reflects how people perform tasks. Consequently, coupling an LLM to an engineered runtime turns prediction into control: outputs trigger interventions that enact goal-oriented behavior. Brains embed prediction within layered feedback controllers calibrated by the consequences of action. By contrast, LLM agents implement Cartesian agency: a learned core coupled to an engineered runtime via a symbolic interface that externalizes control state and policies. The split enables bootstrapping, modularity, and governance, but can induce sensitivity and bottlenecks.
What carries the argument
Cartesian agency, the mechanism in which a learned predictive core is coupled to an engineered runtime through a symbolic interface that externalizes control state and policies.
If this is right
- The symbolic interface allows competence from text prediction to be turned into goal-directed interventions without retraining the core model.
- Externalizing control state and policies supports modularity and easier oversight or governance of the agent's behavior.
- The separation can create bottlenecks at the interface and increase sensitivity to mismatches between the learned predictions and the runtime's needs.
- Bounded services limit the scope of autonomous action to improve robustness, while integrated agents reduce the split to increase autonomy at the cost of harder oversight.
Where Pith is reading between the lines
- Designers could test whether reducing the symbolic interface in favor of tighter prediction-control coupling improves performance on tasks with frequent environmental changes.
- The framework suggests hybrid architectures that keep some external governance while embedding more feedback calibration inside the learned component.
- Comparing failure modes across the three approaches on long-horizon tasks would clarify which trade-off dominates in practice.
Load-bearing premise
The location of control is the central design lever, and the described split between learned core and external runtime accurately captures the functional differences from biological feedback systems.
What would settle it
An experiment that measures robustness and autonomy metrics when the same task is solved by an LLM agent using the standard symbolic interface versus an otherwise identical system that integrates prediction directly into feedback control loops.
Figures
read the original abstract
LLMs gain competence by predicting words in human text, which often reflects how people perform tasks. Consequently, coupling an LLM to an engineered runtime turns prediction into control: outputs trigger interventions that enact goal-oriented behavior. We argue that a central design lever is where control resides in these systems. Brains embed prediction within layered feedback controllers calibrated by the consequences of action. By contrast, LLM agents implement Cartesian agency: a learned core coupled to an engineered runtime via a symbolic interface that externalizes control state and policies. The split enables bootstrapping, modularity, and governance, but can induce sensitivity and bottlenecks. We outline bounded services, Cartesian agents, and integrated agents as contrasting approaches to control that trade off autonomy, robustness, and oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a central design lever in agentic AI systems is the location of control. Biological brains embed prediction within layered feedback controllers calibrated by the consequences of action, whereas LLM agents implement Cartesian agency: a learned predictive core coupled to an engineered runtime via a symbolic interface that externalizes control state and policies. This split enables bootstrapping, modularity, and governance but induces sensitivity and bottlenecks. The manuscript outlines three contrasting approaches—bounded services, Cartesian agents, and integrated agents—and analyzes their trade-offs in autonomy, robustness, and oversight.
Significance. If the framing holds, the paper supplies a coherent interpretive lens for analyzing architectural choices in agentic AI by centering control location and deriving logical consequences of the posited Cartesian split from current LLM usage patterns and biological descriptions. It earns credit for presenting the distinction clearly and mapping trade-offs directly to the three outlined approaches without hidden parameters or circular definitions.
major comments (1)
- Abstract: the central claim that the symbolic interface externalizes control state and policies is load-bearing for all subsequent trade-off analysis, yet the manuscript provides no explicit criteria or examples for identifying such an interface in deployed LLM agents (e.g., tool-calling loops or memory buffers), leaving the distinction at a level of generality that limits falsifiability and concrete application.
minor comments (2)
- The title invokes a 'Cartesian Cut' that is not formally defined or situated relative to prior uses of the term in philosophy or systems theory; a brief clarifying sentence would improve accessibility.
- The biological comparison would benefit from one or two additional citations to specific control-theoretic or neuroscientific models of layered feedback to strengthen the contrast without altering the conceptual nature of the argument.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript's framing and significance, as well as the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim that the symbolic interface externalizes control state and policies is load-bearing for all subsequent trade-off analysis, yet the manuscript provides no explicit criteria or examples for identifying such an interface in deployed LLM agents (e.g., tool-calling loops or memory buffers), leaving the distinction at a level of generality that limits falsifiability and concrete application.
Authors: We agree that greater concreteness in the abstract would strengthen the load-bearing claim and improve applicability. In the revised manuscript we will expand the abstract to include explicit examples and identification criteria, such as tool-calling loops (where LLM token predictions are parsed into structured external function calls that update runtime state and policies) and memory buffers (where control policies and state are maintained outside the predictive core). These additions will ground the Cartesian split in observable architectural patterns without changing the core arguments or trade-off analysis. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances a conceptual perspective framing control location as a design lever and contrasting embedded biological feedback with LLM Cartesian agency via symbolic interfaces. No equations, fitted parameters, quantitative predictions, or deductive derivations are present that could reduce to inputs by construction. The argument rests on observational descriptions of existing systems and logical consequences of the posited split, without self-definitional loops, self-citation load-bearing premises, or renamed empirical patterns. The core claims remain self-contained as an interpretive framework.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs gain competence by predicting words in human text, which often reflects how people perform tasks.
- domain assumption Brains embed prediction within layered feedback controllers calibrated by the consequences of action.
invented entities (1)
-
Cartesian agency
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Parallel organization of functionally segregated circuits linking basal ganglia and cortex
Garrett E. Alexander, Mahlon R. DeLong, and Peter L. Strick. “Parallel organization of functionally segregated circuits linking basal ganglia and cortex”. In:Annual Review of Neuroscience9.1 (1986), pp. 357–381.doi:10.1146/annurev.ne.09.030186.002041. url:https://doi.org/10.1146/annurev.ne.09.030186.002041
-
[2]
Concrete Problems in AI Safety
Dario Amodei et al. “Concrete Problems in AI Safety”. In:arXiv(2016).doi:10. 48550/arXiv.1606.06565. arXiv:1606.06565 [cs.AI].url:https://arxiv.org/ abs/1606.06565
work page internal anchor Pith review arXiv 2016
-
[3]
Thinking inside the box: controlling and using an Oracle AI
Stuart Armstrong, Anders Sandberg, and Nick Bostrom. “Thinking inside the box: controlling and using an Oracle AI”. In:Minds and Machines22.4 (2012), pp. 299– 324.doi:10.1007/s11023-012-9282-2.url:https://doi.org/10.1007/s11023- 012-9282-2
work page doi:10.1007/s11023-012-9282-2.url:https://doi.org/10.1007/s11023- 2012
-
[4]
Mahmoud Assran et al. “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture”. In:arXiv preprint arXiv:2301.08243(2023).doi:10.48550/ arXiv.2301.08243
-
[5]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran et al. “V-JEPA 2: Self-Supervised Video Models Enable Understand- ing, Prediction and Planning”. In:arXiv preprint arXiv:2506.09985(2025).doi:10. 48550/arXiv.2506.09985
work page internal anchor Pith review arXiv 2025
-
[6]
Gary Aston-Jones and Jonathan D. Cohen. “An integrative theory of locus coeruleus- norepinephrine function: adaptive gain and optimal performance”. In:Annual Review of Neuroscience28 (2005), pp. 403–450.doi:10.1146/annurev.neuro.28.061604. 135709.url:https://doi.org/10.1146/annurev.neuro.28.061604.135709
-
[7]
Working paper / preprint (under review, per publisher page at time of access)
Fazl Barez et al.Chain-of-Thought Is Not Explainability. Working paper / preprint (under review, per publisher page at time of access). 2025.url:https://www.aigi. ox.ac.uk/publications/chain-of-thought-is-not-explainability/(visited on 01/22/2026)
2025
-
[8]
Canonical microcircuits for predictive coding
Andre M. Bastos et al. “Canonical microcircuits for predictive coding”. In:Neuron 76.4 (2012), pp. 695–711.doi:10 . 1016 / j . neuron . 2012 . 10 . 038.url:https : //doi.org/10.1016/j.neuron.2012.10.038
-
[9]
Climbing towards NLU: On meaning, form, and understanding in the age of data
Emily M Bender and Alexander Koller. “Climbing towards NLU: On meaning, form, and understanding in the age of data”. In:Proceedings of the 58th annual meeting of the association for computational linguistics. 2020, pp. 5185–5198. 18
2020
-
[10]
arXiv preprint arXiv:2502.15657 , year=
Yoshua Bengio et al. “Superintelligent agents pose catastrophic risks: Can scientist AI offer a safer path?” In:arXiv(2025).doi:10.48550/arXiv.2502.15657. arXiv: 2502.15657 [cs.AI].url:https://arxiv.org/abs/2502.15657
-
[11]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani et al. “On the Opportunities and Risks of Foundation Models”. In: arXiv(2021).doi:10.48550/arXiv.2108.07258. arXiv:2108.07258 [cs.LG].url: https://arxiv.org/abs/2108.07258
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258 2021
-
[12]
Oxford University Press, 2014.isbn: 9780199678112.url:https://www.oxfordmartin.ox.ac.uk/publications/ superintelligence-paths-dangers-strategies/(visited on 01/22/2026)
Nick Bostrom.Superintelligence: Paths, Dangers, Strategies. Oxford University Press, 2014.isbn: 9780199678112.url:https://www.oxfordmartin.ox.ac.uk/publications/ superintelligence-paths-dangers-strategies/(visited on 01/22/2026)
2014
-
[13]
Language Models are Few-Shot Learners
Tom B. Brown et al. “Language Models are Few-Shot Learners”. In:Advances in Neural Information Processing Systems33 (2020), pp. 1877–1901.doi:10 . 48550 / arXiv.2005.14165. arXiv:2005.14165 [cs.CL].url:https://arxiv.org/abs/ 2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S´ ebastien Bubeck et al. “Sparks of artificial general intelligence: Early experiments with gpt-4”. In:arXiv preprint arXiv:2303.12712(2023)
work page internal anchor Pith review arXiv 2023
-
[15]
2022.url:https : / / github
Harrison Chase.LangChain. 2022.url:https : / / github . com / langchain - ai / langchain
2022
-
[16]
Does AI already have human-level intelligence? The evi- dence is clear
Eddy Keming Chen et al. “Does AI already have human-level intelligence? The evi- dence is clear”. In:Nature650 (2026), pp. 36–40.doi:10.1038/d41586-026-00285-6. url:https://www.nature.com/articles/d41586-026-00285-6
-
[17]
Wenhu Chen et al. “Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks”. In:arXiv(2022). Also published in TMLR (2023).doi:10.48550/arXiv.2211.12588. arXiv:2211.12588 [cs.CL].url: https://arxiv.org/abs/2211.12588
work page internal anchor Pith review doi:10.48550/arxiv.2211.12588 2022
-
[18]
Deep reinforcement learning from human preferences
Paul F Christiano et al. “Deep reinforcement learning from human preferences”. In: Advances in neural information processing systems30 (2017)
2017
-
[19]
Cortical mechanisms of action selection: the affordance competition hy- pothesis
Paul Cisek. “Cortical mechanisms of action selection: the affordance competition hy- pothesis”. In:Philosophical Transactions of the Royal Society B: Biological Sciences 362.1485 (2007), pp. 1585–1599.doi:10.1098/rstb.2007.2054.url:https://doi. org/10.1098/rstb.2007.2054
-
[20]
Evolution of behavioural control from chordates to primates
Paul Cisek. “Evolution of behavioural control from chordates to primates”. In:Philo- sophical Transactions of the Royal Society B: Biological Sciences377.1844 (2022), p. 20200522.doi:10.1098/rstb.2020.0522.url:https://doi.org/10.1098/ rstb.2020.0522. 19
work page doi:10.1098/rstb.2020.0522.url:https://doi.org/10.1098/ 2022
-
[21]
The extended mind
Andy Clark and David Chalmers. “The extended mind”. In:analysis58.1 (1998), pp. 7–19
1998
-
[22]
How Do You Feel? Interoception: the sense of the physiological condition of the body
A. D. (Bud) Craig. “How Do You Feel? Interoception: the sense of the physiological condition of the body”. In:Nature Reviews Neuroscience3.8 (2002), pp. 655–666.doi: 10.1038/nrn894.url:https://doi.org/10.1038/nrn894
work page doi:10.1038/nrn894.url:https://doi.org/10.1038/nrn894 2002
-
[23]
Eric Drexler.Reframing Superintelligence: Comprehensive AI Services as General Intelligence
K. Eric Drexler.Reframing Superintelligence: Comprehensive AI Services as General Intelligence. Tech. rep. Future of Humanity Institute, University of Oxford, 2019.url: https://www.fhi.ox.ac.uk/wp-content/uploads/Reframing_Superintelligence. pdf(visited on 01/22/2026)
2019
-
[24]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng et al. “ReTool: Reinforcement Learning for Strategic Tool Use in LLMs”. In:International Conference on Learning Representations (ICLR). Poster. 2026.url: https://openreview.net/forum?id=tRk1nofSmz
2026
-
[25]
Karl Friston. “A theory of cortical responses”. In:Philosophical Transactions of the Royal Society B: Biological Sciences360.1456 (2005), pp. 815–836.doi:10 . 1098 / rstb.2005.1622.url:https://doi.org/10.1098/rstb.2005.1622
-
[26]
PAL: Program-aided Language Models
Luyu Gao et al. “PAL: Program-aided Language Models”. In:arXiv(2022).doi:10. 48550/arXiv.2211.10435. arXiv:2211.10435 [cs.CL].url:https://arxiv.org/ abs/2211.10435
work page Pith review arXiv 2022
-
[27]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team. “Gemini Robotics: Bringing AI into the Physical World”. In: arXiv preprint arXiv:2503.20020(2025).doi:10.48550/arXiv.2503.20020
work page internal anchor Pith review doi:10.48550/arxiv.2503.20020 2025
-
[28]
Alignment faking in large language models
Ryan Greenblatt et al. “Alignment faking in large language models”. In:arXiv preprint arXiv:2412.14093(2024)
work page internal anchor Pith review arXiv 2024
-
[29]
Central Pattern Generators for Locomotion, with Spe- cial Reference to Vertebrates
Sten Grillner and Peter Wall´ en. “Central Pattern Generators for Locomotion, with Spe- cial Reference to Vertebrates”. In:Annual Review of Neuroscience8 (1985), pp. 233– 261.doi:10.1146/annurev.ne.08.030185.001313.url:https://doi.org/10. 1146/annurev.ne.08.030185.001313
work page doi:10.1146/annurev.ne.08.030185.001313.url:https://doi.org/10 1985
-
[30]
Mastering Atari with Discrete World Models
Danijar Hafner et al. “Mastering Atari with discrete world models”. In:arXiv(2020). doi:10 . 48550 / arXiv . 2010 . 02193. arXiv:2010 . 02193 [cs.LG].url:https : / / arxiv.org/abs/2010.02193
work page internal anchor Pith review arXiv 2020
-
[31]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, et al. “Language Models (Mostly) Know What They Know”. In:arXiv preprint arXiv:2207.05221(2022).doi:10.48550/ arXiv.2207.05221. 20
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Kandel et al.Principles of Neural Science
Eric R. Kandel et al.Principles of Neural Science. 6th ed. New York, NY: McGraw Hill, 2021.url:https : / / accessbiomedicalscience . mhmedical . com / content . aspx?aid=1180370208(visited on 01/22/2026)
2021
-
[33]
Scaling Laws for Neural Language Models
Jared Kaplan et al. “Scaling Laws for Neural Language Models”. In:arXiv(2020). doi:10 . 48550 / arXiv . 2001 . 08361. arXiv:2001 . 08361 [cs.LG].url:https : / / arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[34]
The ecological roles of bacterial chemotaxis
Johannes M Keegstra, Francesco Carrara, and Roman Stocker. “The ecological roles of bacterial chemotaxis”. In:Nature Reviews Microbiology20.8 (2022), pp. 491–504
2022
-
[35]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim et al. “OpenVLA: An Open-Source Vision-Language-Action Model”. In: arXiv preprint arXiv:2406.09246(2024).doi:10.48550/arXiv.2406.09246
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246 2024
-
[36]
Version 0.9.2 (2022- 06-27)
Yann LeCun.A Path Towards Autonomous Machine Intelligence. Version 0.9.2 (2022- 06-27). 2022.url:https : / / openreview . net / pdf ? id = BZ5a1r - kVsf(visited on 01/22/2026)
2022
-
[37]
Universal Intelligence: A Definition of Machine In- telligence
Shane Legg and Marcus Hutter. “Universal Intelligence: A Definition of Machine In- telligence”. In:Minds and Machines17.4 (2007), pp. 391–444.doi:10.1007/s11023- 007-9079-x.url:https://doi.org/10.1007/s11023-007-9079-x
-
[38]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine et al. “Offline Reinforcement Learning: Tutorial, Review, and Perspec- tives on Open Problems”. In:arXiv(2020).doi:10.48550/arXiv.2005.01643. arXiv: 2005.01643 [cs.LG].url:https://arxiv.org/abs/2005.01643
work page internal anchor Pith review doi:10.48550/arxiv.2005.01643 2020
-
[39]
Let’s verify step by step
Hunter Lightman et al. “Let’s verify step by step”. In:The Twelfth International Conference on Learning Representations. 2023
2023
-
[40]
Lost in the middle: How language models use long contexts
Nelson F Liu et al. “Lost in the middle: How language models use long contexts”. In: Transactions of the association for computational linguistics12 (2024), pp. 157–173
2024
-
[41]
Context-dependent computation by recurrent dynamics in pre- frontal cortex
Valerio Mante et al. “Context-dependent computation by recurrent dynamics in pre- frontal cortex”. In:Nature503 (2013), pp. 78–84.doi:10.1038/nature12742.url: https://doi.org/10.1038/nature12742
-
[42]
A hierarchy of intrinsic timescales across primate cortex
John D. Murray et al. “A hierarchy of intrinsic timescales across primate cortex”. In:Nature Neuroscience17.12 (2014), pp. 1661–1663.doi:10.1038/nn.3862.url: https://doi.org/10.1038/nn.3862
-
[43]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano et al. “WebGPT: Browser-assisted question-answering with human feedback”. In:arXiv(2021).doi:10.48550/arXiv.2112.09332. arXiv:2112.09332 [cs.CL].url:https://arxiv.org/abs/2112.09332. 21
work page internal anchor Pith review doi:10.48550/arxiv.2112.09332 2021
-
[44]
2024.url:https : / / www
Richard Ngo.The Agency Overhang. 2024.url:https : / / www . lesswrong . com / posts/tqs4eEJapFYSkLGfR/the-agency-overhang(visited on 03/27/2026)
2024
-
[45]
Training language models to follow instructions with human feedback
Long Ouyang et al. “Training language models to follow instructions with human feedback”. In:Advances in neural information processing systems35 (2022), pp. 27730– 27744
2022
-
[46]
Humans and automation: Use, misuse, disuse, abuse
Raja Parasuraman and Victor Riley. “Humans and automation: Use, misuse, disuse, abuse”. In:Human factors39.2 (1997), pp. 230–253
1997
-
[47]
Generating meaning: active inference and the scope and limits of passive AI
Giovanni Pezzulo et al. “Generating meaning: active inference and the scope and limits of passive AI”. In:Trends in Cognitive Sciences28.2 (2024), pp. 97–112.doi:10.1016/ j.tics.2023.10.002.url:https://doi.org/10.1016/j.tics.2023.10.002
-
[48]
Powers.Behavior: The Control of Perception
William T. Powers.Behavior: The Control of Perception. Chicago, IL: Aldine, 1973, pp. xi, 296.url:http://www.livingcontrolsystems.com/books/bcp/bcp.html (visited on 01/22/2026)
1973
-
[49]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian et al. “ToolRL: Reward is All Tool Learning Needs”. In:arXiv preprint arXiv:2504.13958(2025). arXiv:2504.13958 [cs.AI]
work page internal anchor Pith review arXiv 2025
-
[50]
OpenAI, 2019.url:https : / / cdn
Alec Radford et al.Language Models are Unsupervised Multitask Learners. OpenAI, 2019.url:https : / / cdn . openai . com / better - language - models / language _ models_are_unsupervised_multitask_learners.pdf(visited on 01/22/2026)
2019
-
[51]
Rajesh P. N. Rao and Dana H. Ballard. “Predictive coding in the visual cortex: a func- tional interpretation of some extra-classical receptive-field effects”. In:Nature Neuro- science2.1 (1999), pp. 79–87.doi:10.1038/4580.url:https://doi.org/10.1038/ 4580
work page doi:10.1038/4580.url:https://doi.org/10.1038/ 1999
-
[52]
The basal ganglia: a vertebrate solution to the selection problem?
Peter Redgrave, Tony J. Prescott, and Kevin Gurney. “The basal ganglia: a vertebrate solution to the selection problem?” In:Neuroscience89.4 (1999), pp. 1009–1023.doi: 10 . 1016 / S0306 - 4522(98 ) 00319 - 4.url:https : / / doi . org / 10 . 1016 / S0306 - 4522(98)00319-4
1999
-
[53]
Prototyping next-generation O-RAN research testbeds with SDRs,
Scott Reed et al. “A Generalist Agent”. In:arXiv(2022).doi:10.48550/arXiv.2205. 06175. arXiv:2205.06175 [cs.LG].url:https://arxiv.org/abs/2205.06175
-
[54]
St´ ephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning”. In:Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AIS- TATS). 2011, pp. 627–635.doi:10 . 48550 / arXiv . 1011 . 0686. arXiv:1011 . 0686 [cs.LG].url:https:...
-
[55]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick et al. “Toolformer: Language Models Can Teach Themselves to Use Tools”. In:arXiv(2023).doi:10 . 48550 / arXiv . 2302 . 04761. arXiv:2302 . 04761 [cs.CL].url:https://arxiv.org/abs/2302.04761
work page internal anchor Pith review arXiv 2023
-
[56]
doi:10.1038/s41586-020- 3001-6
Julian Schrittwieser et al. “Mastering Atari, Go, Chess and Shogi by planning with a learned model”. In:Nature588.7839 (2020), pp. 604–609.doi:10.1038/s41586-020- 03051-4.url:https://doi.org/10.1038/s41586-020-03051-4
-
[57]
Science376(6594), 5197 (2022) https://doi.org/10.1126/science
Wolfram Schultz, Peter Dayan, and P. Read Montague. “A neural substrate of predic- tion and reward”. In:Science275.5306 (1997), pp. 1593–1599.doi:10.1126/science. 275.5306.1593.url:https://doi.org/10.1126/science.275.5306.1593
-
[58]
Melanie Sclar et al. “Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting”. In: International Conference on Learning Representations (ICLR). 2024.doi:10.48550/ arXiv.2310.11324. arXiv:2310.11324 [cs.CL].url:https://arxiv.org/abs/ 2310.11324
-
[59]
Defining and Characterizing Reward Gaming
Joar Skalse et al. “Defining and Characterizing Reward Gaming”. In:Advances in Neural Information Processing Systems. 2022.url:https://arxiv.org/abs/2209. 13085
2022
-
[60]
Sutton.The Bitter Lesson
Richard S. Sutton.The Bitter Lesson. 2019.url:http://www.incompleteideas. net/IncIdeas/BitterLesson.html(visited on 01/22/2026)
2019
-
[61]
Optimal feedback control as a theory of motor coordination,
Emanuel Todorov and Michael I. Jordan. “Optimal feedback control as a theory of motor coordination”. In:Nature Neuroscience5.11 (2002), pp. 1226–1235.doi:10. 1038/nn963.url:https://doi.org/10.1038/nn963
-
[62]
How to make artificial agents more like natural agents
Michael Tomasello. “How to make artificial agents more like natural agents”. In:Trends in Cognitive Sciences29.9 (2025), pp. 783–786.doi:10.1016/j.tics.2025.07.004. url:https://doi.org/10.1016/j.tics.2025.07.004
-
[63]
Write a recipe for chocolate cake
Miles Turpin et al. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting”. In:arXiv(2023). NeurIPS 2023.doi: 10.48550/arXiv.2305.04388. arXiv:2305.04388 [cs.CL].url:https://arxiv. org/abs/2305.04388
-
[64]
Emergent Abilities of Large Language Models
Jason Wei et al. “Emergent abilities of large language models”. In:arXiv preprint arXiv:2206.07682(2022)
work page internal anchor Pith review arXiv 2022
-
[65]
Internal models in the cerebel- lum
Daniel M. Wolpert, R. Chris Miall, and Mitsuo Kawato. “Internal models in the cerebel- lum”. In:Trends in Cognitive Sciences2.9 (1998), pp. 338–347.doi:10.1016/S1364- 6613(98)01221-2.url:https://doi.org/10.1016/S1364-6613(98)01221-2. 23
-
[66]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao et al. “ReAct: Synergizing Reasoning and Acting in Language Models”. In: International Conference on Learning Representations (ICLR). 2023.doi:10.48550/ arXiv.2210.03629. arXiv:2210.03629 [cs.CL].url:https://arxiv.org/abs/ 2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Uncertainty, neuromodulation, and attention
Angela J. Yu and Peter Dayan. “Uncertainty, neuromodulation, and attention”. In: Neuron46.4 (2005), pp. 681–692.doi:10 . 1016 / j . neuron . 2005 . 04 . 026.url: https://doi.org/10.1016/j.neuron.2005.04.026
-
[68]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brianna Zitkovich et al. “RT-2: Vision-Language-Action Models Transfer Web Knowl- edge to Robotic Control”. In:Conference on Robot Learning. PMLR. 2023, pp. 2165– 2183.doi:10.48550/arXiv.2307.15818. arXiv:2307.15818 [cs.RO].url:https: //arxiv.org/abs/2307.15818. 24
work page internal anchor Pith review doi:10.48550/arxiv.2307.15818 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.