Recognition: unknown
Kuramoto Oscillatory Phase Encoding: Neuro-inspired Synchronization for Improved Learning Efficiency
Pith reviewed 2026-05-10 16:51 UTC · model grok-4.3
The pith
Kuramoto oscillatory phase encoding adds a synchronized phase state to vision transformers to boost training, parameter, and data efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
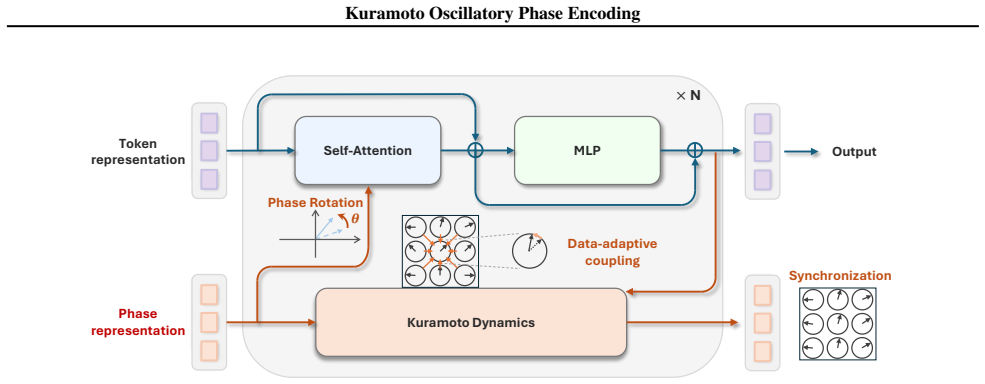
KoPE inserts an auxiliary phase variable governed by Kuramoto synchronization dynamics into each token of a Vision Transformer; the resulting phase alignment accelerates attention concentration, producing measurable improvements in training speed, parameter count, and data requirements while lifting accuracy on structured-understanding tasks such as semantic segmentation, panoptic segmentation, vision-language alignment, and few-shot abstract visual reasoning.
What carries the argument
Kuramoto oscillatory Phase Encoding (KoPE), an auxiliary phase state evolved by Kuramoto-model coupling that is added to the token representations of a Vision Transformer.
If this is right
- Vision models using KoPE require fewer training steps and fewer parameters to reach a given accuracy on image tasks.
- KoPE lifts performance on semantic and panoptic segmentation by strengthening feature binding through phase alignment.
- Representation alignment between vision and language encoders improves when both use synchronized phase states.
- Few-shot abstract visual reasoning accuracy rises because phase synchronization helps capture relational structure with limited examples.
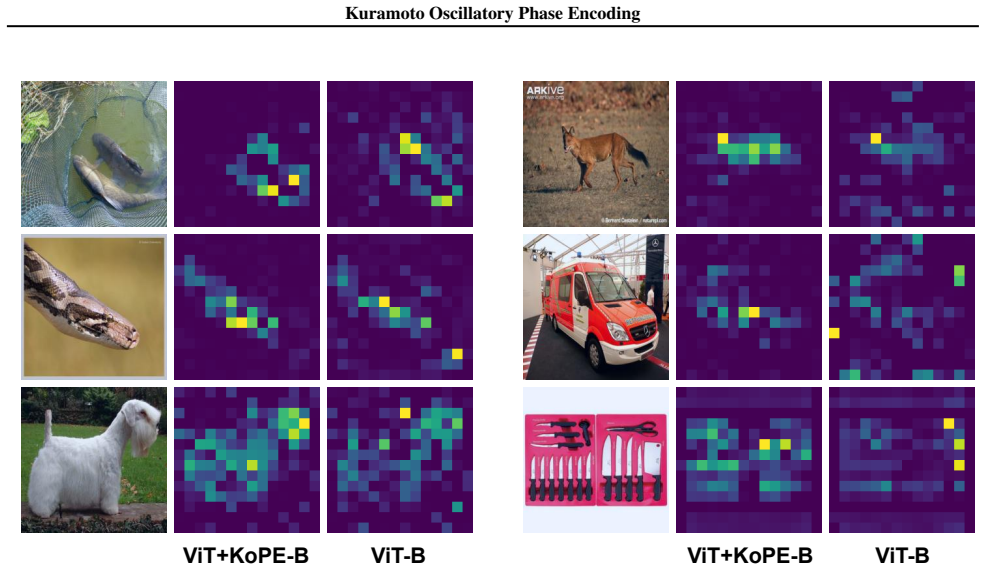
- Theoretical analysis indicates that the synchronization term shortens the number of attention iterations needed for tokens to focus on coherent regions.
Where Pith is reading between the lines
- The same phase-coupling mechanism could be tested on non-vision architectures such as language models or graph networks to check whether synchronization benefits generalize beyond images.
- If the efficiency gains persist at scale, KoPE might reduce the carbon cost of training large vision models by lowering required compute.
- The approach opens a route to more biologically plausible deep networks that maintain both rate and phase information, potentially aiding interpretability of internal dynamics.
- A natural next measurement is whether the learned phase patterns correlate with human visual binding phenomena on the same stimuli.
Load-bearing premise
That Kuramoto synchronization dynamics, once added as an auxiliary phase state, will consistently improve structure learning without destabilizing training or demanding extensive per-task retuning of coupling strength.
What would settle it
A controlled ablation in which the Kuramoto coupling term is replaced by a non-synchronizing phase update (for example random walks or zero coupling) and the efficiency and accuracy gains disappear or reverse.
Figures










read the original abstract
Spatiotemporal neural dynamics and oscillatory synchronization are widely implicated in biological information processing and have been hypothesized to support flexible coordination such as feature binding. By contrast, most deep learning architectures represent and propagate information through activation values, neglecting the joint dynamics of rate and phase. In this work, we introduce Kuramoto oscillatory Phase Encoding (KoPE) as an additional, evolving phase state to Vision Transformers, incorporating a neuro-inspired synchronization mechanism to advance learning efficiency. We show that KoPE can improve training, parameter, and data efficiency of vision models through synchronization-enhanced structure learning. Moreover, KoPE benefits tasks requiring structured understanding, including semantic and panoptic segmentation, representation alignment with language, and few-shot abstract visual reasoning (ARC-AGI). Theoretical analysis and empirical verification further suggest that KoPE can accelerate attention concentration for learning efficiency. These results indicate that synchronization can serve as a scalable, neuro-inspired mechanism for advancing state-of-the-art neural network models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kuramoto Oscillatory Phase Encoding (KoPE) as an auxiliary evolving phase state added to Vision Transformers. It incorporates a neuro-inspired synchronization mechanism based on the Kuramoto model to promote structure learning. The central claims are that KoPE yields measurable gains in training, parameter, and data efficiency for vision models and provides benefits on structured-understanding tasks including semantic and panoptic segmentation, vision-language representation alignment, and few-shot abstract visual reasoning on ARC-AGI. Theoretical analysis is presented suggesting that the phase dynamics accelerate attention concentration.
Significance. If the empirical gains and theoretical mechanism hold after addressing robustness concerns, the work would be moderately significant. It offers a concrete way to inject oscillatory synchronization into transformer architectures, potentially improving efficiency on tasks that benefit from structured representations. The combination of multi-task empirical results with an attention-concentration analysis provides a mechanistic hook that goes beyond pure performance tables. However, the absence of machine-checked proofs or fully parameter-free derivations limits the strength of the theoretical contribution.
major comments (2)
- [§3.2, Eq. (4)] §3.2 (Kuramoto Phase Dynamics) and Eq. (4): The coupling strength K is introduced as a tunable hyperparameter controlling synchronization. No sensitivity plots or fixed-K experiments across tasks are reported, leaving open the possibility that reported efficiency gains require task-specific retuning of K. This directly undermines the claim that KoPE provides reliable, plug-and-play improvements without destabilizing training.
- [§4.3, Table 3] §4.3 (Ablation Studies) and Table 3: Ablations isolate the phase state but do not control for the added computational cost of the auxiliary dynamics or compare against equivalent regularization or auxiliary-state baselines. Without these controls, it is unclear whether the reported training and data-efficiency gains are attributable to synchronization rather than increased model capacity or optimization effects.
minor comments (2)
- [§2] Notation for the phase state variable is introduced in §2 but reused inconsistently with the attention maps in §5; a single consistent symbol would improve readability.
- [§6.4] The ARC-AGI few-shot results in §6.4 would benefit from error bars over multiple random seeds and a clearer statement of the exact prompting and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating where revisions will be made to strengthen the presentation of results.
read point-by-point responses
-
Referee: [§3.2, Eq. (4)] §3.2 (Kuramoto Phase Dynamics) and Eq. (4): The coupling strength K is introduced as a tunable hyperparameter controlling synchronization. No sensitivity plots or fixed-K experiments across tasks are reported, leaving open the possibility that reported efficiency gains require task-specific retuning of K. This directly undermines the claim that KoPE provides reliable, plug-and-play improvements without destabilizing training.
Authors: We appreciate the referee highlighting the need for greater clarity on hyperparameter robustness. While K is a hyperparameter in the model formulation, all experiments in the manuscript were performed using a single consistent default value of K without per-task retuning. To directly address the concern, we will add sensitivity analysis plots varying K over a range of values and confirm performance with this fixed K across the reported tasks in the revised version. These additions will support the plug-and-play claim by demonstrating stability. revision: yes
-
Referee: [§4.3, Table 3] §4.3 (Ablation Studies) and Table 3: Ablations isolate the phase state but do not control for the added computational cost of the auxiliary dynamics or compare against equivalent regularization or auxiliary-state baselines. Without these controls, it is unclear whether the reported training and data-efficiency gains are attributable to synchronization rather than increased model capacity or optimization effects.
Authors: We agree that the current ablations would benefit from additional controls to isolate the synchronization mechanism. The phase dynamics incur only modest O(N) overhead per layer, but the manuscript does not explicitly quantify this or compare against non-synchronizing auxiliary states. In the revision, we will expand the ablation section and Table 3 to include (i) explicit FLOPs and runtime comparisons with and without KoPE, (ii) baselines using equivalent auxiliary phase states without Kuramoto coupling, and (iii) regularization-based controls. These will help attribute gains specifically to the synchronization dynamics. revision: yes
Circularity Check
No significant circularity; derivation relies on external neuro-inspired model and empirical results
full rationale
The paper introduces KoPE by augmenting Vision Transformers with an auxiliary phase state governed by the standard Kuramoto oscillator equations, then reports empirical gains in training/parameter/data efficiency plus benefits on segmentation, alignment, and ARC-AGI tasks. Theoretical analysis is invoked to link synchronization to accelerated attention concentration, but no equations or steps are shown that reduce the claimed improvements to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations whose content is itself unverified. The coupling strength K is a free parameter of the imported Kuramoto model rather than a quantity derived from the target efficiency metrics; its tuning is therefore an implementation choice, not a circular prediction. The central claims remain falsifiable against external benchmarks and do not collapse to tautology by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Kuramoto coupling strength
axioms (1)
- domain assumption Kuramoto model equations accurately capture useful neural synchronization when transplanted to artificial networks
invented entities (1)
-
KoPE phase state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
Bommasani, R. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
MONet: Unsupervised Scene Decomposition and Representation
Burgess, C. P., Matthey, L., Watters, N., Kabra, R., Higgins, I., Botvinick, M., and Lerchner, A. Monet: Unsupervised scene decomposition and representation.arXiv preprint arXiv:1901.11390,
work page Pith review arXiv 1901
-
[3]
On the Measure of Intelligence
Chollet, F. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
work page internal anchor Pith review arXiv 1911
-
[4]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Chollet, F., Knoop, M., Kamradt, G., Landers, B., and Pinkard, H. Arc-agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831,
work page internal anchor Pith review arXiv
-
[5]
On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208, 2020
Greff, K., Van Steenkiste, S., and Schmidhuber, J. On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208,
-
[6]
Hu, K., Cy, A., Qiu, L., Ding, X. D., Wang, R., Zhu, Y . E., Andreas, J., and He, K. Arc is a vision problem!arXiv preprint arXiv:2511.14761,
-
[7]
Less is More: Recursive Reasoning with Tiny Networks
Jolicoeur-Martineau, A. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871,
work page internal anchor Pith review arXiv
-
[8]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
Understanding and improving trans- former from a multi-particle dynamic system point of view
Lu, Y ., Li, Z., He, D., Sun, Z., Dong, B., Qin, T., Wang, L., and Liu, T.-y. Understanding and improving trans- former from a multi-particle dynamic system point of view. InICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations,
2020
- [10]
-
[11]
Sim´eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
11 Kuramoto Oscillatory Phase Encoding Wang, G., Li, J., Sun, Y ., Chen, X., Liu, C., Wu, Y ., Lu, M., Song, S., and Yadkori, Y . A. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734,
work page internal anchor Pith review arXiv
-
[13]
As Mask2Former requires pyramid inputs, we leverage a simple feature-to-pyramid module on the last layer of ViT or ViT+KoPE, similar to Li et al
with ViT or ViT+KoPE as backbones. As Mask2Former requires pyramid inputs, we leverage a simple feature-to-pyramid module on the last layer of ViT or ViT+KoPE, similar to Li et al. (2022). It builds feature maps with resolution scales 4, 2, 1, and 0.5 for the network output through transposed convolutions or max pooling, which is then processed by Mask2Fo...
2022
-
[14]
to train ViT and ViT+KoPE under CLIP-style learning. We utilize the unfiltered medium-scale data from DataComp (Gadre et al., 2023), which originally contains 128M data (around 4.5 TB) while we only successfully downloaded 70% of the data from the Internet (around 3.2 TB). We use the same data and training settings for both models, and we consider ViT-B-1...
2023
-
[15]
During training, we evaluate the zero-shot classification performance on ImageNet validation set and ImageNet V2 following the OpenCLIP realization
while we double the training samples seen (from 128M to 256M). During training, we evaluate the zero-shot classification performance on ImageNet validation set and ImageNet V2 following the OpenCLIP realization. After training, we also systematically evaluate the zero-shot performance on 40 datasets following CLIP benchmark (Cherti & Beaumont, 2022). The ...
2022
-
[16]
that views it a vision problem, and leverage the same procedure to patchify images and perform data augmentation. We follow the training pipeline to first pretrain the model on training tasks from ARC-AGI-1 and re-arc for 100 epochs, and then perform test-time training separately for each task in the validation set of ARC-1/ARC-2. Test-time training is pe...
2025
-
[17]
Analysis Experiments For analysis of attention concentration, we calculate the average Gini metric over all tokens for all heads of the attention of CLS token in the last layer
B.6. Analysis Experiments For analysis of attention concentration, we calculate the average Gini metric over all tokens for all heads of the attention of CLS token in the last layer. The Gini metric is computed by: Gini(ˆa0) = PN i=1(2i−N−1)ˆa 0,i PN i=1 ˆa0,i , 14 Kuramoto Oscillatory Phase Encoding where ˆa0 ∈R N is the sorted attention score (ˆa0,1 ≤ˆa...
2023
-
[18]
A is fixed during training
and every entry of A is sampled from n + 1√m ,− 1√m o . A is fixed during training. We slightly modify the model to append a CLS token in the sequence (index 0), while the model output is still defined as the average of all tokens, so the analysis in Li et al. (2023) can be adapted. We mainly focus on the attention from this token. For KoPE, we consider e...
2023
-
[19]
(63)) and the proxy bound ϕn(T)(|S n| − |S 1 n|)≤η C (Eq
establishes that WQ, WK amplify discriminative query/key features and induce attention sparsification (Claim 2); (ii) this yields attention concentration (Proposition 2), together with the growth ∥q1(T)∥ 2 = Θ(logT) (Eq. (63)) and the proxy bound ϕn(T)(|S n| − |S 1 n|)≤η C (Eq. (65)); (iii) these concentration/proxy controls enter the margin lower bound (...
2023
-
[20]
w/o Kuramoto
74.0M 17.8G 47.38 63.26 72.85 80.73 82.70 non-relevant exponential mass entering the proxy bound is reduced at the same stage of training. This suggests a smaller effective constant in the slack term c′(1−ζ) , and therefore potentially smaller sufficient requirements on iterations and samples, consistent with the observed training/data efficiency. D. More...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.