Recognition: unknown
SearchAD: Large-Scale Rare Image Retrieval Dataset for Autonomous Driving
Pith reviewed 2026-05-10 16:48 UTC · model grok-4.3
The pith
SearchAD supplies the first large-scale benchmark for retrieving rare safety-critical driving scenes from massive datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
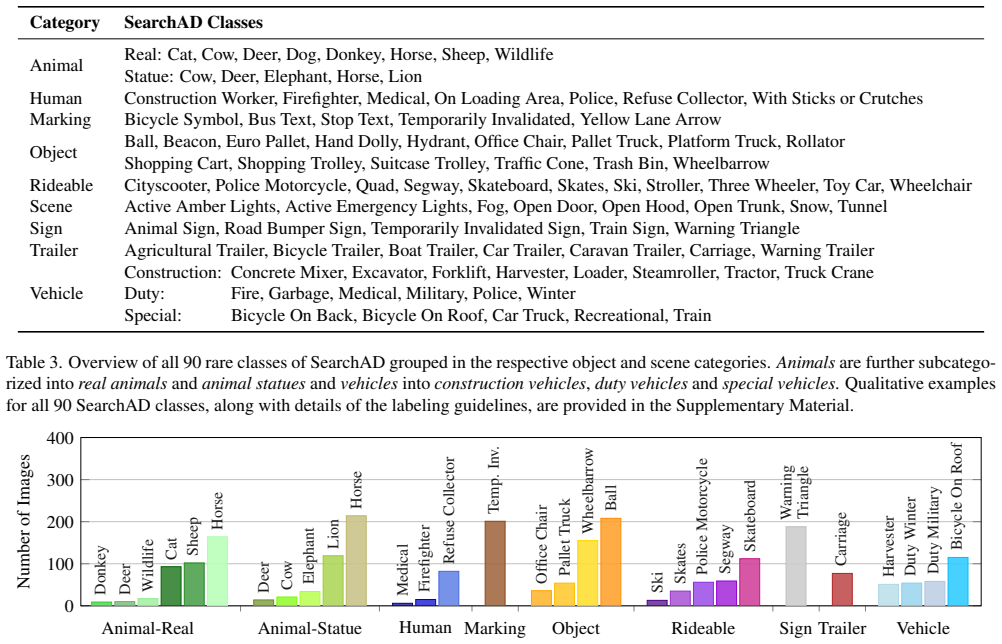
SearchAD aggregates frames from eleven existing sources into a single benchmark containing 423k images and high-quality manual annotations for 90 rare categories, complete with a held-out test set on a public server. The work shows that models aligning spatial visual features with language text produce the best zero-shot retrieval performance, that fine-tuning further raises accuracy, and that text-based methods consistently surpass image-based ones because of stronger semantic grounding, while absolute retrieval quality remains unsatisfactory for practical use.
What carries the argument
The SearchAD dataset itself, which aggregates frames from multiple sources and supplies bounding-box annotations for rare classes to support semantic retrieval tasks and data-curation experiments.
If this is right
- Text-to-image retrieval methods can be directly compared against image-only baselines on a standardized AD-specific test set.
- Fine-tuning on the provided training split produces measurable gains over zero-shot performance for rare-class retrieval.
- The dataset enables systematic study of how retrieval can improve data curation for long-tail perception tasks.
- Public benchmark server allows ongoing evaluation of new multi-modal models without access to the full training data.
Where Pith is reading between the lines
- Curating training sets with SearchAD-retrieved samples could reduce the total data volume required to achieve reliable detection of rare events.
- The observed advantage of language-aligned features may transfer to other domains where rare events must be located in large unlabeled collections.
- Repeated use of the benchmark could expose whether current multi-modal architectures fundamentally struggle with extreme class imbalance.
Load-bearing premise
The ninety chosen rare categories and their manual annotations accurately reflect real-world safety-critical driving situations without selection bias in category choice or frame sampling.
What would settle it
A new model that achieves near-perfect retrieval of all ninety categories on the held-out test set would indicate that the needle-in-a-haystack problem has been solved, contradicting the paper's finding of unsatisfactory performance.
Figures













read the original abstract
Retrieving rare and safety-critical driving scenarios from large-scale datasets is essential for building robust autonomous driving (AD) systems. As dataset sizes continue to grow, the key challenge shifts from collecting more data to efficiently identifying the most relevant samples. We introduce SearchAD, a large-scale rare image retrieval dataset for AD containing over 423k frames drawn from 11 established datasets. SearchAD provides high-quality manual annotations of more than 513k bounding boxes covering 90 rare categories. It specifically targets the needle-in-a-haystack problem of locating extremely rare classes, with some appearing fewer than 50 times across the entire dataset. Unlike existing benchmarks, which focused on instance-level retrieval, SearchAD emphasizes semantic image retrieval with a well-defined data split, enabling text-to-image and image-to-image retrieval, few-shot learning, and fine-tuning of multi-modal retrieval models. Comprehensive evaluations show that text-based methods outperform image-based ones due to stronger inherent semantic grounding. While models directly aligning spatial visual features with language achieve the best zero-shot results, and our fine-tuning baseline significantly improves performance, absolute retrieval capabilities remain unsatisfactory. With a held-out test set on a public benchmark server, SearchAD establishes the first large-scale dataset for retrieval-driven data curation and long-tail perception research in AD: https://iis-esslingen.github.io/searchad/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SearchAD, a large-scale rare image retrieval dataset for autonomous driving containing over 423k frames aggregated from 11 existing datasets. It provides manual annotations for more than 513k bounding boxes across 90 rare categories (some appearing fewer than 50 times), with defined splits supporting text-to-image, image-to-image retrieval, few-shot learning, and fine-tuning. Comprehensive evaluations indicate that text-based methods outperform image-based ones due to stronger semantic grounding, that models aligning spatial visual features with language perform best in zero-shot settings, and that a fine-tuning baseline improves results, though absolute retrieval performance remains unsatisfactory. The work releases the dataset and a public benchmark server with a held-out test set to support retrieval-driven data curation and long-tail perception research in AD.
Significance. If the annotations are reliable and representative, SearchAD could be a valuable contribution by establishing the first dedicated large-scale benchmark for the needle-in-a-haystack retrieval problem in safety-critical AD scenarios. The public server and emphasis on rare classes enable reproducible research on data curation for long-tail perception. The reported performance gap between text-based and image-based methods, if quantified rigorously, provides a concrete direction for multi-modal model development in this domain.
major comments (3)
- [Dataset Construction] Dataset Construction section: The manuscript repeatedly describes the annotations as 'high-quality manual annotations' for the 513k bounding boxes over 90 rare categories, yet provides no details on the annotation protocol, number of annotators, inter-annotator agreement, quality control procedures, or guidelines for handling ambiguous rare events. This directly undermines the central claim that SearchAD constitutes a reliable benchmark for long-tail perception and retrieval-driven curation, as the reported outperformance of text-based methods and the fine-tuning baseline rest entirely on these labels serving as trustworthy ground truth.
- [Evaluations] Evaluations section: The abstract and evaluation summary assert that 'text-based methods outperform image-based ones due to stronger inherent semantic grounding' and that 'our fine-tuning baseline significantly improves performance' while 'absolute retrieval capabilities remain unsatisfactory,' but no specific metrics (e.g., recall@K for K=1,5,10 or mAP), exact experimental setup, data split details, or comparison tables are referenced. Without these, the magnitude and statistical significance of the claimed gaps cannot be verified or reproduced.
- [Introduction and Dataset] Introduction and Dataset sections: The selection of the 90 rare categories and the frame sampling strategy from the 11 source datasets are not described with sufficient rigor to exclude post-hoc selection bias or non-representative sampling of safety-critical scenarios. It remains unclear whether category rarity was determined via pre-annotation frequency analysis across the full corpus or whether frames were chosen to ensure diversity in driving conditions, both of which are load-bearing for the 'needle-in-a-haystack' framing and the dataset's claimed utility.
minor comments (3)
- The project page URL in the abstract should be verified to confirm that all data splits, annotations, and the benchmark server are publicly accessible as stated.
- [Related Work] Related Work section: Additional citations to recent long-tail detection and rare-event retrieval papers in AD would better situate the contribution relative to existing benchmarks.
- [Figures] Figures showing example rare categories would benefit from higher-resolution insets or zoomed views to more clearly illustrate the visual challenges of the retrieval task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, and we will make revisions to improve the clarity and completeness of the paper.
read point-by-point responses
-
Referee: [Dataset Construction] The manuscript repeatedly describes the annotations as 'high-quality manual annotations' for the 513k bounding boxes over 90 rare categories, yet provides no details on the annotation protocol, number of annotators, inter-annotator agreement, quality control procedures, or guidelines for handling ambiguous rare events. This directly undermines the central claim that SearchAD constitutes a reliable benchmark for long-tail perception and retrieval-driven curation, as the reported outperformance of text-based methods and the fine-tuning baseline rest entirely on these labels serving as trustworthy ground truth.
Authors: We acknowledge that the current manuscript lacks sufficient detail on the annotation process. In the revised manuscript, we will add a subsection detailing the annotation protocol, including the use of multiple annotators, the guidelines for labeling rare categories, quality control steps such as cross-verification, and procedures for ambiguous cases. We will also include inter-annotator agreement metrics to validate the quality of the annotations. This will reinforce the trustworthiness of the ground truth for the benchmark tasks. revision: yes
-
Referee: [Evaluations] The abstract and evaluation summary assert that 'text-based methods outperform image-based ones due to stronger inherent semantic grounding' and that 'our fine-tuning baseline significantly improves performance' while 'absolute retrieval capabilities remain unsatisfactory,' but no specific metrics (e.g., recall@K for K=1,5,10 or mAP), exact experimental setup, data split details, or comparison tables are referenced. Without these, the magnitude and statistical significance of the claimed gaps cannot be verified or reproduced.
Authors: The Evaluations section of the manuscript contains the specific metrics, including recall@K values and mAP, along with descriptions of the experimental setups and data splits. However, we agree that the abstract and summary do not sufficiently reference these. We will revise the abstract and the Evaluations section introduction to explicitly cite the relevant tables and metrics, ensuring that the claims about outperformance and improvements are directly linked to the reported results for better verifiability and reproducibility. revision: yes
-
Referee: [Introduction and Dataset] The selection of the 90 rare categories and the frame sampling strategy from the 11 source datasets are not described with sufficient rigor to exclude post-hoc selection bias or non-representative sampling of safety-critical scenarios. It remains unclear whether category rarity was determined via pre-annotation frequency analysis across the full corpus or whether frames were chosen to ensure diversity in driving conditions, both of which are load-bearing for the 'needle-in-a-haystack' framing and the dataset's claimed utility.
Authors: We will enhance the Introduction and Dataset sections to provide a more rigorous description of the category selection and sampling strategy. This will include explaining that the 90 categories were selected based on frequency analysis of the aggregated data from the 11 source datasets to identify those with low occurrence rates (fewer than 50 instances for some). The frame sampling was designed to capture a diverse set of driving conditions while focusing on rare events. We will detail the process to demonstrate it was systematic and to address concerns about selection bias. revision: yes
Circularity Check
Empirical dataset paper with no circular derivation chain
full rationale
The paper introduces SearchAD as a new dataset with manual annotations and reports benchmark results from standard retrieval models (text-based vs image-based). No equations, fitted parameters, or derivations are present. Central claims rest on the released data and external model evaluations rather than reducing to self-defined quantities, self-citations, or ansatzes. This matches the default non-circular case for dataset/benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RayFronts: Open- set semantic ray frontiers for online scene understanding and exploration
Omar Alama, Avigyan Bhattacharya, Haoyang He, Se- ungchan Kim, Yuheng Qiu, Wenshan Wang, Cherie Ho, Nikhil Keetha, and Sebastian Scherer. RayFronts: Open- set semantic ray frontiers for online scene understanding and exploration. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5930–5937,
-
[2]
7, 8, 1, 2, 3, 4, 9, 10, 11
-
[3]
Neural codes for image retrieval
Artem Babenko, Anton Slesarev, Alexandr Chigorin, and Victor Lempitsky. Neural codes for image retrieval. InProc. of the European Conf. on Computer Vision (ECCV), pages 584–599, 2014. 7
2014
-
[4]
Content-based image re- trieval and the semantic gap in the deep learning era
Bj ¨orn Barz and Joachim Denzler. Content-based image re- trieval and the semantic gap in the deep learning era. InProc. of the International Conf. on Pattern Recognition (ICPR), pages 245–260, 2021. 3
2021
-
[5]
Flohr, and Dariu M
Markus Braun, Sebastian Krebs, Fabian B. Flohr, and Dariu M. Gavrila. EuroCity Persons: A novel benchmark for person detection in traffic scenes.IEEE Trans. on Pat- tern Analysis and Machine Intelligence (PAMI), pages 1–1,
-
[6]
Smooth-AP: Smoothing the path towards large- scale image retrieval
Andrew Brown, Weidi Xie, Vicky Kalogeiton, and Andrew Zisserman. Smooth-AP: Smoothing the path towards large- scale image retrieval. InProc. of the European Conf. on Computer Vision (ECCV), pages 677–694, 2020. 3
2020
-
[7]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuScenes: A multi- modal dataset for autonomous driving. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020. 2, 3, 19
2020
-
[8]
SegmentMeIfYou- Can: A benchmark for anomaly segmentation
Robin Chan, Krzysztof Lis, Svenja Uhlemeyer, Hermann Blum, Sina Honari, Roland Siegwart, Pascal Fua, Math- ieu Salzmann, and Matthias Rottmann. SegmentMeIfYou- Can: A benchmark for anomaly segmentation. InProceed- ings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021. 2
2021
-
[9]
Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al. Meta CLIP 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
-
[10]
2, 6, 7, 8, 1, 9, 10, 11
-
[11]
The Cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016. 3, 19
2016
-
[12]
Simon Doll, Niklas Hanselmann, Lukas Schneider, Richard Schulz, Marius Cordts, Markus Enzweiler, and Hendrik P. A. Lensch. DualAD: Disentangling the dynamic and static world for end-to-end driving. InProc. IEEE Conf. on Com- puter Vision and Pattern Recognition (CVPR), pages 14728– 14737, 2024. 1
2024
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InProc. of the International Conf. on Learning Rep- resentations (ICLR...
2021
-
[14]
The FAISS li- brary.IEEE Transactions on Big Data, pages 1–17, 2025
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff John- son, Gergely Szilvasy, Pierre-Emmanuel Mazar ´e, Maria Lomeli, Lucas Hosseini, and Herv ´e J ´egou. The FAISS li- brary.IEEE Transactions on Big Data, pages 1–17, 2025. 6, 4, 5
2025
-
[15]
The Mapillary traffic sign dataset for detection and classification on a global scale
Christian Ertler, Jerneja Mislej, Tobias Ollmann, Lorenzo Porzi, Gerhard Neuhold, and Yubin Kuang. The Mapillary traffic sign dataset for detection and classification on a global scale. InProc. of the European Conf. on Computer Vision (ECCV), pages 68–84, 2020. 3, 8, 19
2020
-
[16]
ORION: A holistic end-to- end autonomous driving framework by vision-language in- structed action generation
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. ORION: A holistic end-to- end autonomous driving framework by vision-language in- structed action generation. InProc. of the IEEE International Conf. on Computer Vision (ICCV), 2025. 1
2025
-
[17]
Vision meets robotics: The KITTI dataset.Inter- national Journal of Robotics Research (IJRR), 32(11):1231– 1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The KITTI dataset.Inter- national Journal of Robotics Research (IJRR), 32(11):1231– 1237, 2013. 2, 3, 4, 19
2013
-
[18]
Dense open-set recognition with synthetic outliers generated by real NVP
Matej Grci ´c, Petra Bevandi ´c, and Sini ˇsa Segvi ´c. Dense open-set recognition with synthetic outliers generated by real NVP. InProc. of the Conf. on Computer Vision Theory and Applications (VISAPP), pages 133–143. INSTICC, 2021. 2
2021
-
[19]
Michael Green, Matan Levy, Issar Tzachor, Dvir Samuel, Nir Darshan, and Rami Ben-Ari. Find your needle: Small object image retrieval via multi-object attention optimization.arXiv preprint arXiv:2503.07038, 2025. 2, 5
-
[20]
LVIS: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A dataset for large vocabulary instance segmentation. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[21]
Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation
Sina Hajimiri, Ismail Ben Ayed, and Jose Dolz. Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation. InProc. of the IEEE Winter Conference on Applications of Computer Vision (WACV), pages 5061–5071,
-
[22]
6, 7, 8, 1, 2, 3, 4, 9, 10, 11
-
[23]
RADIOv2.5: Improved baselines for agglomerative vision foundation models
Greg Heinrich, Mike Ranzinger, Hongxu Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catanzaro, and Pavlo Molchanov. RADIOv2.5: Improved baselines for agglomerative vision foundation models. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 22487–22497, 2025. 2, 7, 8, 1, 9, 10, 11
2025
-
[24]
Scaling out-of-distribution detection for 9 real-world settings
Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joseph Kwon, Mohammadreza Mostajabi, Jacob Steinhardt, and Dawn Song. Scaling out-of-distribution detection for 9 real-world settings. InProc. of the International Conf. on Machine learning (ICML), pages 8759–8773, 2022. 2
2022
-
[25]
David Holtz, Niklas Hanselmann, Simon Doll, Marius Cordts, and Bernt Schiele. What matters for scalable and ro- bust learning in end-to-end driving planners?arXiv preprint arXiv:2603.15185, 2026. 1
-
[26]
Planning-oriented autonomous driv- ing
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driv- ing. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 17853–17862, 2023. 1
2023
-
[27]
OpenCLIP.Zenodo, 2021
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, et al. OpenCLIP.Zenodo, 2021. 2, 6, 7, 8, 1, 3, 9, 10, 11
2021
-
[28]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProc. of the International Conf. on Machine learning (ICML), pages 19730–19742, 2023. 2, 6, 7, 8, 1, 3, 4, 5, 9, 10, 11
2023
-
[29]
CODA: A real-world road corner case dataset for object detection in autonomous driving
Kaican Li, Kai Chen, Haoyu Wang, Lanqing Hong, Chao- qiang Ye, Jianhua Han, Yukuai Chen, Wei Zhang, Chunjing Xu, Dit-Yan Yeung, Xiaodan Liang, Zhenguo Li, and Hang Xu. CODA: A real-world road corner case dataset for object detection in autonomous driving. InProc. of the European Conf. on Computer Vision (ECCV), pages 406–423, 2022. 2, 4, 5
2022
-
[30]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProc. IEEE Conf. on Com- puter Vision and Pattern Recognition (CVPR), pages 10965– 10975, 2022. 6
2022
-
[31]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In Proc. of the European Conf. on Computer Vision (ECCV), pages 740–755, 2014. 2, 5
2014
-
[32]
Grounding DINO: Mar- rying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Mar- rying DINO with grounded pre-training for open-set object detection. InProc. of the European Conf. on Computer Vi- sion (ECCV), pages 38–55, 2025. 6, 7, 8, 1, 2, 3, 4, 5, 9, 10, 11
2025
-
[33]
Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X. Yu. Large-scale long-tailed recognition in an open world. InProc. IEEE Conf. on Com- puter Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[34]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proc. of the IEEE International Conf. on Computer Vision (ICCV), pages 10012–10022, 2021. 7
2021
-
[35]
Han Lu, Xiaosong Jia, Yichen Xie, Wenlong Liao, Xiaokang Yang, and Junchi Yan. ActiveAD: Planning-oriented active learning for end-to-end autonomous driving.arXiv preprint arXiv:2403.02877, 2024. 1
-
[36]
Two video data sets for tracking and retrieval of out of distribution objects
Kira Maag, Robin Chan, Svenja Uhlemeyer, Kamil Kowol, and Hanno Gottschalk. Two video data sets for tracking and retrieval of out of distribution objects. InProc. of the Asian Conf. on Computer Vision (ACCV), pages 3776–3794, 2022. 2
2022
-
[37]
Manning, Prabhakar Raghavan, and Hinrich Sch¨utze.Introduction to Information Retrieval
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Sch¨utze.Introduction to Information Retrieval. Cambridge University Press, 2008. 5, 6, 3
2008
-
[38]
One million scenes for autonomous driving: ONCE dataset
Jiageng Mao, Niu Minzhe, ChenHan Jiang, hanxue liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, Jie Yu, Chunjing XU, and Hang Xu. One million scenes for autonomous driving: ONCE dataset. InProceedings of the Neural Information Processing Sys- tems Track on Datasets and Benchmarks, 2021. 2
2021
-
[39]
The Mapillary Vistas dataset for seman- tic understanding of street scenes
Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The Mapillary Vistas dataset for seman- tic understanding of street scenes. InProc. of the IEEE In- ternational Conf. on Computer Vision (ICCV), 2017. 3, 19
2017
-
[40]
Patil, Abhinav Benagi, Charith Rage, Dhany- atha Narayan, Susmitha A, and Pragya Paramita Sahu
Annapurna P. Patil, Abhinav Benagi, Charith Rage, Dhany- atha Narayan, Susmitha A, and Pragya Paramita Sahu. CLIP- based image retrieval: A comparative study using ceitm eval- uation. In2024 1st International Conference on Communi- cations and Computer Science (InCCCS), pages 1–7, 2024. 6
2024
-
[41]
Object retrieval with large vocabularies and fast spatial matching
James Philbin, Ondrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman. Object retrieval with large vocabularies and fast spatial matching. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 1–8, 2007. 3
2007
-
[42]
Lost in quantization: Improving par- ticular object retrieval in large scale image databases
James Philbin, Ondrej Chum, Michael Isard, Josef Sivic, and Andrew Zisserman. Lost in quantization: Improving par- ticular object retrieval in large scale image databases. In Proc. IEEE Conf. on Computer Vision and Pattern Recog- nition (CVPR), pages 1–8, 2008. 3
2008
-
[43]
Lost and found: detecting small road hazards for self-driving vehicles
Peter Pinggera, Sebastian Ramos, Stefan Gehrig, Uwe Franke, Carsten Rother, and Rudolf Mester. Lost and found: detecting small road hazards for self-driving vehicles. In Proc. IEEE International Conf. on Intelligent Robots and Systems (IROS), pages 1099–1106, 2016. 2, 3, 4, 16, 19
2016
-
[44]
Revisiting Oxford and Paris: Large-scale image retrieval benchmarking
Filip Radenovi ´c, Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ond ˇrej Chum. Revisiting Oxford and Paris: Large-scale image retrieval benchmarking. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR),
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProc. of the In- ternational Conf. on Machine learning (ICML), pages 8748– 8763, 2021. 2, 7
2021
-
[46]
AM-RADIO: Agglomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. AM-RADIO: Agglomerative vision foundation model reduce all domains into one. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 12490–12500, 2024. 7 10
2024
-
[47]
Faster R-CNN: Towards real-time object detection with re- gion proposal networks.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 39(6):1137–1149, 2017
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with re- gion proposal networks.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 39(6):1137–1149, 2017. 4
2017
-
[48]
SimLingo: Vision-only closed-loop autonomous driving with language-action alignment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. SimLingo: Vision-only closed-loop autonomous driving with language-action alignment. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 11993–12003, 2025. 1
2025
-
[49]
ACDC: The adverse conditions dataset with correspondences for se- mantic driving scene understanding
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. ACDC: The adverse conditions dataset with correspondences for se- mantic driving scene understanding. InProc. of the IEEE In- ternational Conf. on Computer Vision (ICCV), pages 10765– 10775, 2021. 3, 19
2021
-
[50]
Waslander, Yu Liu, and Hongsheng Li
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L. Waslander, Yu Liu, and Hongsheng Li. LMDrive: Closed-loop end-to-end driving with large language models. InProc. IEEE Conf. on Computer Vision and Pattern Recog- nition (CVPR), pages 15120–15130, 2024. 1
2024
-
[51]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
BEV-TSR: Text-scene retrieval in BEV space for autonomous driving.Proc
Tao Tang, Dafeng Wei, Zhengyu Jia, Tian Gao, Changwei Cai, Chengkai Hou, Peng Jia, Kun Zhan, Haiyang Sun, Fan JingChen, Yixing Zhao, Xiaodan Liang, Xianpeng Lang, and Yang Wang. BEV-TSR: Text-scene retrieval in BEV space for autonomous driving.Proc. of the Conf. on Artificial In- telligence (AAAI), 39(7):7275–7283, 2025. 5
2025
-
[53]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. SigLIP 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2, 6, 7, 8, 1, 9, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Girish Varma, Anbumani Subramanian, Anoop Namboodiri, Manmohan Chandraker, and C.V . Jawahar. IDD: A dataset for exploring problems of autonomous navigation in uncon- strained environments. InProc. of the IEEE Winter Con- ference on Applications of Computer Vision (WACV), pages 1743–1751, 2019. 3, 19
2019
-
[55]
V oorhees and Donna Harman
Ellen M. V oorhees and Donna Harman. Overview of the sixth text retrieval conference (trec-6).Information Process- ing & Management, 36(1):3–35, 2000. 5, 6
2000
-
[56]
Distribution-balanced loss for multi-label classification in long-tailed datasets
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, and Dahua Lin. Distribution-balanced loss for multi-label classification in long-tailed datasets. InProc. of the European Conf. on Computer Vision (ECCV), pages 162–178, 2020. 2
2020
-
[57]
CORA: Adapting CLIP for open-vocabulary detection with region prompting and anchor pre-matching
Xiaoshi Wu, Feng Zhu, Rui Zhao, and Hongsheng Li. CORA: Adapting CLIP for open-vocabulary detection with region prompting and anchor pre-matching. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 7031–7040, 2023. 6
2023
-
[58]
Zhongyu Xia, Jishuo Li, Zhiwei Lin, Xinhao Wang, Yongtao Wang, and Ming-Hsuan Yang. OpenAD: Open-world au- tonomous driving benchmark for 3D object detection.arXiv preprint arXiv:2411.17761, 2024. 2, 4
-
[59]
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yu- liang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, et al. WOD-E2E: Waymo open dataset for end-to-end driving in challenging long-tail sce- narios.arXiv preprint arXiv:2510.26125, 2025. 2
-
[60]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hocken- maier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descrip- tions.Transactions of the Association for Computational Linguistics, 2:67–78, 2014. 2, 5
2014
-
[61]
BDD100K: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Dar- rell. BDD100K: A diverse driving dataset for heterogeneous multitask learning. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020. 3, 4, 5, 19
2020
-
[62]
Unifying panoptic segmentation for autonomous driving
Oliver Zendel, Matthias Sch ¨orghuber, Bernhard Rainer, Markus Murschitz, and Csaba Beleznai. Unifying panoptic segmentation for autonomous driving. InProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 21351–21360, 2022. 3, 19
2022
-
[63]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProc. of the IEEE International Conf. on Computer Vision (ICCV), pages 11975–11986, 2023. 2, 7
2023
-
[64]
Evaluation of similarity measurement for image retrieval
Dengsheng Zhang and Guojun Lu. Evaluation of similarity measurement for image retrieval. InInternational Confer- ence on Neural Networks and Signal Processing, pages 928– 931 V ol.2, 2003. 6 11 SearchAD: Large-Scale Rare Image Retrieval Dataset for Autonomous Driving Supplementary Material A. SearchAD Dataset In this section, we provide more details on th...
2003
-
[65]
[24] [50] [25] [8] [20] [19] [1, 19] Animal-Real-Cat 0.11 0.18 0.09 0.03 0.03 0.07 0.110.14 Animal-Real-Cow 16.86 7.97 16.55 9.22 14.21 13.40 27.9628.25 Animal-Real-Deer48.046.67 6.69 39.40 33.53 38.49 10.43 40.90 Animal-Real-Dog29.748.95 13.71 12.78 16.06 10.67 20.39 28.23 Animal-Real-Donkey 0.00 0.01 0.07 0.02 0.03 0.150.220.10 Animal-Real-Horse14.921.3...
-
[66]
[24] [50] [25] [8] [20] [19] [1, 19] Scene-Fog 0.87 86.36 71.1987.3368.92 61.45 86.86 1.58 Scene-Open-Door 1.71 2.26 3.22 2.47 2.70 2.62 3.007.58 Scene-Open-Hood 0.07 0.096.863.00 0.59 0.35 0.06 0.25 Scene-Open-Trunk 1.85 2.93 4.29 3.20 3.57 3.30 2.707.58 Scene-Snow 6.63 60.34 54.60 66.47 56.87 70.1774.7961.49 Scene-Tunnel 2.74 33.25 24.11 32.46 20.13 38....
-
[67]
[20] [8] [50] [19] [29] [25] [1, 19] Animal-Real-Cat 0.02 0.02 0.01 0.02 0.030.070.06 0.02 Animal-Real-Cow 0.39 0.19 2.19 0.2517.6310.51 13.06 0.26 Animal-Real-Deer 33.39 33.48 33.62 33.3469.7021.11 33.57 33.35 Animal-Real-Dog 5.02 1.47 2.11 4.70 18.8520.739.16 6.91 Animal-Real-Donkey 0.01 0.03 0.02 0.01 0.010.050.00 0.01 Animal-Real-Horse 0.03 0.03 0.02 ...
-
[68]
[20] [8] [50] [19] [29] [25] [1, 19] Scene-Fog 71.57 23.94 46.04 53.21 2.7977.0770.22 58.32 Scene-Open-Door 2.50 2.04 2.12 2.73 1.832.962.47 2.53 Scene-Open-Hood 0.15 0.12 0.080.200.08 0.08 0.11 0.10 Scene-Open-Trunk 2.98 2.15 2.52 2.81 2.50 3.163.202.20 Scene-Snow 10.58 34.12 7.32 9.98 7.43 9.9541.9911.07 Scene-Tunnel 13.18 20.07 19.02 15.69 4.32 4.5526....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.