Recognition: no theorem link
LINE: LLM-based Iterative Neuron Explanations for Vision Models
Pith reviewed 2026-05-14 22:08 UTC · model grok-4.3
The pith
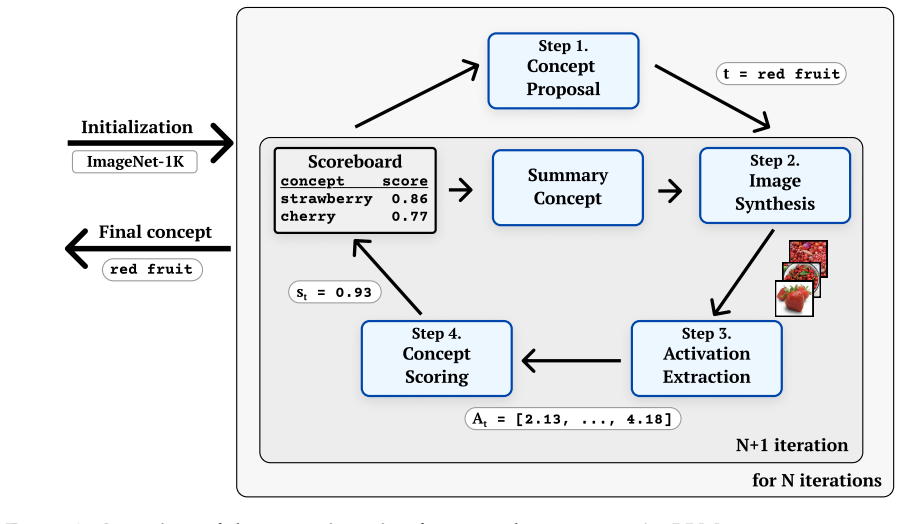
LINE uses an LLM and text-to-image generator in a closed loop to label neurons in vision models with open-vocabulary concepts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LINE is a novel iterative approach for open-vocabulary concept labeling in vision models that works in a strictly black-box setting by leveraging a large language model to propose and refine concepts and a text-to-image generator to create test images, guided by activation history, achieving state-of-the-art performance across model architectures with AUC improvements of up to 0.11 on ImageNet and 0.05 on Places365 while discovering on average 27% new concepts missed by predefined vocabularies.
What carries the argument
The closed-loop iterative refinement process in which the LLM proposes concepts, the text-to-image generator creates corresponding images, neuron activation is measured, and the history of activations guides the next proposal round.
If this is right
- The method supplies a complete generation history that supports evaluation of whether a neuron is polysemantic.
- It produces visual explanations that can be compared directly to those from gradient-dependent activation maximization techniques.
- It enables concept discovery outside any fixed vocabulary while remaining applicable to multiple vision model architectures.
- The black-box requirement means the same procedure can be applied without retraining or gradient access.
Where Pith is reading between the lines
- The generation history could be used to measure how narrowly or broadly a neuron responds across successive concept refinements.
- If the generated images reliably stand in for real data, the approach could be extended to audit neurons on datasets where human-labeled concepts are unavailable.
- The iterative loop might be adapted to other modalities such as audio or text models by swapping the image generator for an appropriate modality-specific generator.
Load-bearing premise
Images generated by the text-to-image model activate the target neuron in a manner representative of how the neuron would respond to real-world instances of the proposed concept.
What would settle it
Measure neuron activations on a large collection of real photographs that have been independently labeled with the exact concepts proposed by LINE and compare those activation values to the activations on the synthetic images produced for the same concepts.
Figures










read the original abstract
Interpreting individual neurons in deep neural networks is a crucial step towards understanding their complex decision-making processes and ensuring AI safety. Despite recent progress in neuron labeling, existing methods often limit the search space to predefined concept vocabularies or produce overly specific descriptions that fail to capture higher-order, global concepts. We introduce LINE, a novel, training-free iterative approach tailored for open-vocabulary concept labeling in vision models. Operating in a strictly black-box setting, LINE leverages a large language model and a text-to-image generator to iteratively propose and refine concepts in a closed loop, guided by activation history. LINE achieves state-of-the-art performance across multiple model architectures, yielding AUC improvements of up to 0.11 on ImageNet and 0.05 on Places365, while discovering, on average, 27% of new concepts missed by predefined vocabularies. Beyond identifying the top concept, LINE provides a complete generation history, enabling polysemanticity evaluation and producing visual explanations that rival gradient-dependent activation maximization methods. The source code will be made available soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LINE, a training-free black-box iterative algorithm that couples an LLM with a text-to-image generator to propose, refine, and select open-vocabulary concepts for individual neurons in vision models. Guided by activation history, the method claims state-of-the-art performance with AUC gains of up to 0.11 on ImageNet and 0.05 on Places365, plus discovery of 27% new concepts missed by fixed vocabularies; it also supplies a generation history for polysemanticity analysis and visual explanations.
Significance. If the reported gains are reproducible under standard real-image evaluation, LINE would meaningfully advance neuron-level interpretability by removing the closed vocabulary constraint and enabling post-hoc polysemanticity checks. The approach is conceptually simple and leverages existing foundation models, which could accelerate adoption in safety and debugging workflows.
major comments (2)
- [Abstract] Abstract: The central performance claims (AUC improvements of 0.11 on ImageNet and 0.05 on Places365, 27% new-concept discovery) are stated without any description of the evaluation protocol, baseline methods, number of neurons or models tested, AUC definition, or statistical tests. These omissions render the SOTA assertion unverifiable from the manuscript.
- [Method] Method section (iterative loop): Neuron activations used to score and refine concepts are measured exclusively on images synthesized by the text-to-image model. No experiment validates that these synthetic activations correlate with activations on real-world images of the same concept; systematic distribution shift would invalidate the closed-loop optimization and the reported AUC numbers.
minor comments (1)
- [Abstract] Abstract: The statement that source code 'will be made available soon' should include a concrete timeline or repository link to allow reviewers to inspect the implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help improve the clarity and rigor of the manuscript. We address each major point below and will make the necessary revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (AUC improvements of 0.11 on ImageNet and 0.05 on Places365, 27% new-concept discovery) are stated without any description of the evaluation protocol, baseline methods, number of neurons or models tested, AUC definition, or statistical tests. These omissions render the SOTA assertion unverifiable from the manuscript.
Authors: We agree that the abstract would benefit from additional context to make the claims verifiable at a glance. In the revised version we will expand the abstract to briefly note the evaluation protocol (real-image AUC on ImageNet and Places365 using ROC curves for activation prediction), the baselines (fixed-vocabulary methods), the scope (multiple architectures and hundreds of neurons), and that gains are reported as averages with standard deviation across runs. Full experimental details remain in Sections 4 and 5. revision: yes
-
Referee: [Method] Method section (iterative loop): Neuron activations used to score and refine concepts are measured exclusively on images synthesized by the text-to-image model. No experiment validates that these synthetic activations correlate with activations on real-world images of the same concept; systematic distribution shift would invalidate the closed-loop optimization and the reported AUC numbers.
Authors: We acknowledge the concern about possible distribution shift. The final reported AUC numbers are computed exclusively on real images from ImageNet and Places365, providing an end-to-end validation of the discovered concepts. However, we did not include an explicit correlation study between synthetic and real activations during the iterative loop. We will add a new subsection with a quantitative analysis (e.g., activation correlation coefficients on matched concept pairs) to confirm that the closed-loop optimization remains reliable. revision: yes
Circularity Check
No significant circularity detected
full rationale
LINE is a procedural black-box algorithm that iteratively calls external LLM and text-to-image models to propose concepts, then measures neuron activations on the generated images to refine them. No equations, fitted parameters, or self-referential definitions appear in the method; the reported AUC gains and new-concept discovery rates are computed directly from those external activation measurements rather than being forced by any internal construction. No load-bearing self-citations or uniqueness theorems imported from prior author work are invoked to justify the core loop. The approach therefore remains self-contained against external benchmarks and does not reduce any claimed result to its own inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neuron activations measured on text-to-image generated pictures correspond to the neuron's response to the underlying concept in natural images.
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread. Kirill Bykov, Laura Kopf, Shinichi Nakajima, Marius Kloft, and Marina Höhne. Labeling neural representations with inverse recognition.Advances in Neural Information Processing Systems, 36, 2024. Josep Lopez Camuñas, Christy Li, Tamar Rott Shaham, Antonio Torralba, and Agata Lapedriza. OpenMAIA: a multimodal automated interpret...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.23915/distill.00007 2024
-
[2]
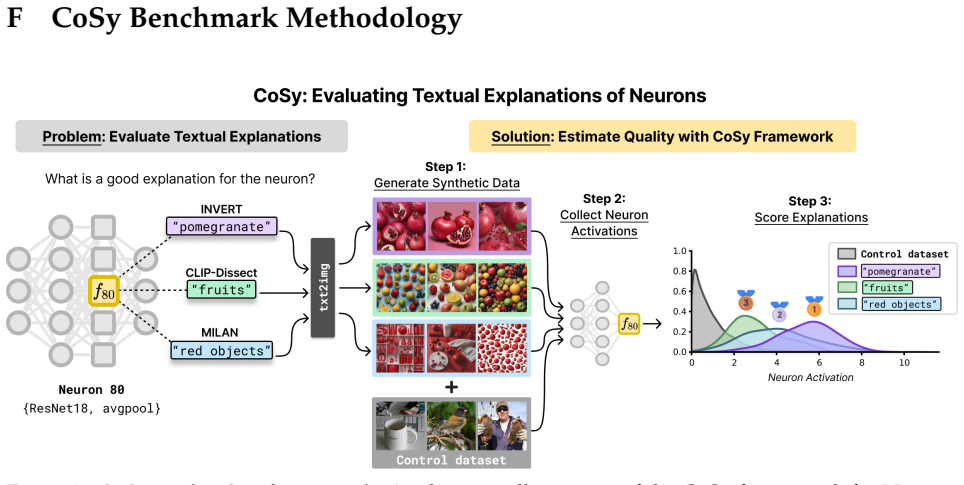
Generate Synthetic Data.Given a proposed concept label t (e.g.,polka dots), a generative T2I model is used to synthesize a collection of images, denoted as in our workP
-
[3]
This yields two sets of scalar activations: •A t: Activations from the synthetic concept images inP
Collect Neuron Activations.Both the synthetic images P and a control dataset of natural images Xcontrol ⊂ X are passed through the target vision network f and the activations are extracted from the specific neuronn. This yields two sets of scalar activations: •A t: Activations from the synthetic concept images inP. •A control: Activations from the natural...
-
[4]
A higher score indicates that the concept t is a better match for the neuronn
Score Explanations.A scoring function ψ(Acontrol, At) is used to quantify the difference between the two activation distributions. A higher score indicates that the concept t is a better match for the neuronn. The benchmark evaluates these explanations using two complementary scoring functions that capture different aspects of neuron behavior: Area Under ...
-
[5]
core” (for the core classes) or “spurious
and extending the results from Figure 4, we selected 3 classes containing heavily spurious features and 3 classes relaying mainly on core features from Salient ImageNet (Singla and Feizi, 2022). For each evaluated class, we provided visual explanations of the top-5 features, categorized as either “core” (for the core classes) or “spurious” (for the spurio...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.