Alloc-MoE: Budget-Aware Expert Activation Allocation for Efficient Mixture-of-Experts Inference
Pith reviewed 2026-05-10 17:04 UTC · model grok-4.3
The pith
Alloc-MoE allocates a fixed budget of expert activations across layers and tokens in MoE models to reduce inference latency while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
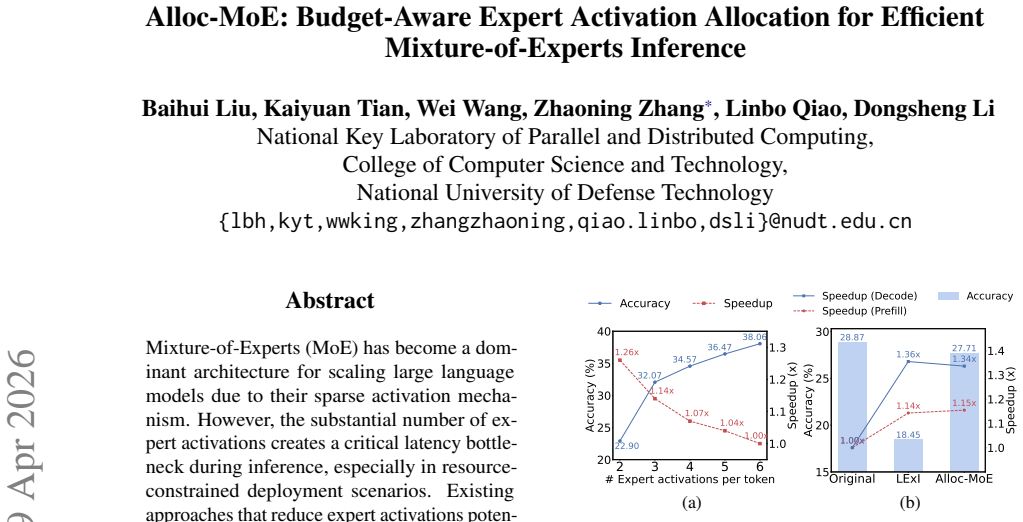
Alloc-MoE defines an activation budget as the total number of expert forward passes allowed and optimizes its distribution in two stages. Alloc-L uses layer sensitivity scores and dynamic programming to assign distinct activation counts to each layer. Alloc-T then reallocates the remaining budget at the token level according to routing scores, all without extra latency overhead. Experiments on several MoE models confirm that performance stays close to the full-budget baseline, with concrete gains of 1.15 times prefill throughput and 1.34 times decode throughput on DeepSeek-V2-Lite when the budget is cut to half.
What carries the argument
Activation budget allocation, performed first at the layer level by sensitivity profiling plus dynamic programming and then at the token level by routing-score redistribution.
If this is right
- Model quality remains close to the unconstrained case even when total expert activations are halved.
- Prefill and decode stages both accelerate, with reported factors of 1.15 times and 1.34 times on DeepSeek-V2-Lite.
- No retraining or architecture change is required for the speed-up.
- The same budget framework applies across multiple different MoE models.
Where Pith is reading between the lines
- The same sensitivity-plus-dynamic-programming step could be reused to optimize other sparse patterns such as attention head pruning.
- Token-level redistribution might interact usefully with KV-cache management in long-context serving.
- If sensitivity profiles transfer across similar model scales, profiling cost could be amortized over many deployment scenarios.
Load-bearing premise
Sensitivity scores computed once per layer accurately forecast how much final model quality will drop when expert counts are reduced, without needing full validation for every possible allocation.
What would settle it
Apply the computed layer and token allocations at half budget to DeepSeek-V2-Lite and measure perplexity or downstream accuracy; if the drop exceeds the full-budget baseline by more than the paper's reported margin, or if an exhaustive search finds a better allocation, the claim is refuted.
Figures










read the original abstract
Mixture-of-Experts (MoE) has become a dominant architecture for scaling large language models due to their sparse activation mechanism. However, the substantial number of expert activations creates a critical latency bottleneck during inference, especially in resource-constrained deployment scenarios. Existing approaches that reduce expert activations potentially lead to severe model performance degradation. In this work, we introduce the concept of \emph{activation budget} as a constraint on the number of expert activations and propose Alloc-MoE, a unified framework that optimizes budget allocation coordinately at both the layer and token levels to minimize performance degradation. At the layer level, we introduce Alloc-L, which leverages sensitivity profiling and dynamic programming to determine the optimal allocation of expert activations across layers. At the token level, we propose Alloc-T, which dynamically redistributes activations based on routing scores, optimizing budget allocation without increasing latency. Extensive experiments across multiple MoE models demonstrate that Alloc-MoE maintains model performance under a constrained activation budget. Especially, Alloc-MoE achieves $1.15\times$ prefill and $1.34\times$ decode speedups on DeepSeek-V2-Lite at half of the original budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Alloc-MoE, a unified framework for efficient MoE inference under an activation budget constraint. Alloc-L uses per-layer sensitivity profiling and dynamic programming to allocate expert activations across layers; Alloc-T dynamically redistributes activations at the token level based on routing scores. Experiments on multiple MoE models, including DeepSeek-V2-Lite, report that performance is maintained while achieving 1.15× prefill and 1.34× decode speedups at half the original budget.
Significance. If the empirical results hold under rigorous validation, the work provides a practical, budget-aware method for reducing inference latency in large MoE models without retraining, which could aid deployment in resource-constrained settings. The concrete speedup figures and multi-model scope are strengths, but the moderate soundness noted in the absence of detailed ablations and statistical tests limits the assessed impact.
major comments (1)
- [Abstract (and §3.1 Alloc-L description)] The central claim that Alloc-MoE maintains performance at half budget (Abstract) rests on Alloc-L's sensitivity profiles and DP solution accurately predicting degradation for the chosen joint allocation. However, the approach assumes additive and independent layer impacts, which may not hold due to non-additive interactions from shared routing, residual connections, and token distributions; no cross-layer ablation or joint validation is indicated to confirm the proxy.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments across multiple MoE models' but provides no list of models, baseline methods, or statistical significance measures for the reported speedups.
- [§3] Notation for the activation budget and sensitivity metric should be defined more explicitly when first introduced to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the assumptions underlying Alloc-L. We address it directly below with clarifications drawn from the method and commit to a targeted revision.
read point-by-point responses
-
Referee: [Abstract (and §3.1 Alloc-L description)] The central claim that Alloc-MoE maintains performance at half budget (Abstract) rests on Alloc-L's sensitivity profiles and DP solution accurately predicting degradation for the chosen joint allocation. However, the approach assumes additive and independent layer impacts, which may not hold due to non-additive interactions from shared routing, residual connections, and token distributions; no cross-layer ablation or joint validation is indicated to confirm the proxy.
Authors: We agree that non-additive interactions exist through shared routing, residuals, and token distributions. Our sensitivity profiling, however, is not a purely theoretical decomposition: for each layer we measure actual end-to-end performance degradation while reducing that layer’s expert activations and keeping every other layer at its original (full) activation count. The resulting sensitivity values therefore already embed the interactions that occur during the forward pass. Dynamic programming then selects the integer allocation that minimizes the sum of these empirically observed sensitivities subject to the global budget. While we did not present a dedicated cross-layer ablation, the consistent preservation of accuracy across DeepSeek-V2-Lite, Mixtral, and other models at the chosen allocations provides practical validation of the proxy. We will add a concise discussion of the independence assumption, its empirical grounding, and its limitations to §3.1. revision: partial
Circularity Check
No circularity in derivation; framework is algorithmic and empirically validated
full rationale
The paper presents Alloc-MoE as a practical allocation method: Alloc-L uses per-layer sensitivity profiling followed by dynamic programming to meet a global activation budget, while Alloc-T performs token-level redistribution based on routing scores. These are described as optimization procedures whose outputs are then measured in experiments for speed and performance. No equations reduce the reported speedups (1.15× prefill, 1.34× decode) to quantities defined only by the allocation rules themselves, no fitted parameters are renamed as predictions, and no load-bearing claims rest on self-citations or imported uniqueness theorems. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lexi: Layer-adaptive active experts for efficient moe model inference,
AAAI Press. Krishna Teja Chitty-Venkata, Sandeep Madireddy, Mu- rali Emani, and Venkatram Vishwanath. 2025. Lexi: Layer-adaptive active experts for efficient moe model inference.Preprint, arXiv:2509.02753. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficul...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI. 2024a. Deepseek-v2: A strong, economi- cal, and efficient mixture-of-experts language model. Preprint, arXiv:2405.04434. DeepSeek-AI. 2024b. Deepseek-v3 technical report. Preprint, arXiv:2412.19437. William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transform...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 6159–6172, Bangkok, Thailand. Association for Computational Linguistics. Stephen Merity, Caiming Xiong, James Bradbury, and...
work page 2017
-
[4]
OLMoE: Open Mixture-of-Experts Language Models
A diverse corpus for evaluating and developing English math word problem solvers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984, Online. Association for Computational Linguistics. Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind...
work page internal anchor Pith review arXiv 2025
-
[5]
Seer-moe: Sparse expert efficiency through regularization for mixture-of-experts,
Seer-moe: Sparse expert efficiency through regularization for mixture-of-experts.CoRR, abs/2404.05089. Denis Paperno, Germán Kruszewski, Angeliki Lazari- dou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. 2016. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.