Synthetic Data for any Differentiable Target
Pith reviewed 2026-05-10 18:03 UTC · model grok-4.3
The pith
A reinforcement learning method optimizes synthetic data generators so fine-tuning on their outputs steers language models toward any differentiable target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dataset Policy Gradient is a reinforcement learning primitive that optimizes a synthetic data generator by using higher-order gradients to compute exact data attributions and feeding those scores as policy rewards. The resulting dataset, when used for supervised fine-tuning, causes the target model to optimize any chosen differentiable metric. The authors prove the update closely approximates the ideal gradient for the generator and illustrate the approach by making the target model's language-modeling head embed a QR code, embed the pattern 67, reduce its L2 norm, rephrase inputs in a new language, and produce a chosen UUID.
What carries the argument
Dataset Policy Gradient (DPG), which scores each generated example by its higher-order-gradient contribution to the target metric and treats those scores as rewards in a policy-gradient update for the generator.
If this is right
- Target model weights can embed arbitrary patterns such as QR codes or the sequence 67 solely through supervised fine-tuning on the generated examples.
- The generator can learn to rephrase inputs in a language never mentioned in its prompts.
- Model components can be driven toward lower L2 norms or other weight-space properties via the generated data alone.
- Specific output strings such as chosen UUIDs can be produced consistently after fine-tuning, even without explicit conditioning in the generator.
- The same procedure applies to any differentiable metric, not just the five demonstrated cases.
Where Pith is reading between the lines
- The technique may let practitioners edit deployed models by generating fresh data rather than retraining from scratch or editing weights directly.
- If the approximation remains accurate at larger scales, DPG could become a general interface for specifying model goals through data rather than loss functions.
- Combining DPG with existing data-augmentation pipelines might reduce reliance on human-labeled examples for narrow behavioral targets.
- Computational cost of higher-order gradients will determine whether the method stays practical beyond small models or toy metrics.
Load-bearing premise
Higher-order gradients supply a stable, low-bias signal that can be turned into policy rewards without causing the generator to diverge or produce misleading attributions.
What would settle it
After running DPG, fine-tuning the target model on the generated data fails to improve the chosen metric beyond what random or unoptimized data achieves.
Figures





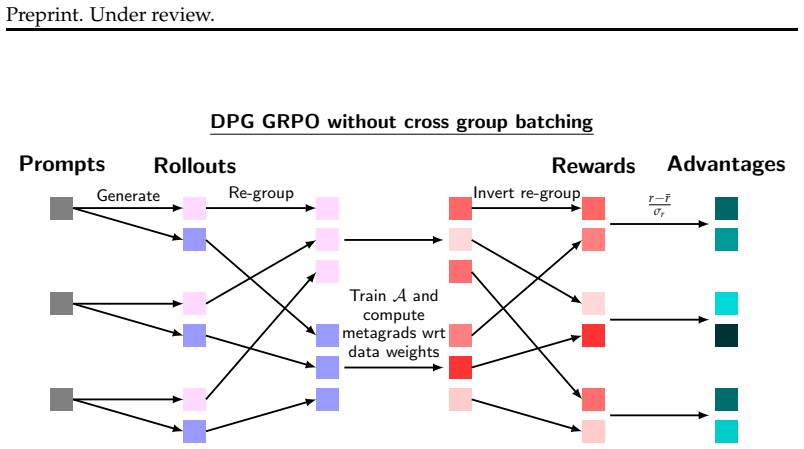

read the original abstract
What are the limits of controlling language models via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell^2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dataset Policy Gradient (DPG), an RL primitive for optimizing synthetic data generators. DPG uses exact data attribution scores derived from higher-order gradients of a differentiable target metric (computed after SFT on the generated data) as rewards in a policy gradient update for the generator. The authors prove that this yields a close approximation to the true (intractable) gradient of the post-SFT metric w.r.t. generator parameters. They demonstrate the approach on five tasks: causing a target LM's weights to embed a QR code, embed the pattern '67', or have reduced ℓ² norm; causing the generator to rephrase inputs in a new language; and causing it to output a specific UUID, all via SFT on the generated examples alone.
Significance. If the gradient approximation holds with bounded error across finite SFT trajectories and the method proves stable, DPG would offer a general mechanism for steering LM properties and behaviors using only synthetic data for arbitrary differentiable objectives. The demonstrations suggest potential for non-prompt-based control (e.g., weight-level pattern embedding or output constraints), which could complement existing fine-tuning and editing techniques. Credit is due for the explicit proof attempt and the concrete, falsifiable examples; however, significance is tempered by the need for rigorous validation of the approximation under realistic multi-step optimization.
major comments (2)
- [Proof of gradient approximation (Section 3 or equivalent)] The proof that DPG 'closely approximates the true, intractable gradient' (abstract) relies on higher-order gradients providing reliable data attribution. Standard derivations of such attributions (influence functions or Hessian-vector products) are first-order linearizations around the initial parameters. The demonstrations involve multiple SFT steps with non-negligible learning rates, during which parameters move and the attribution becomes path-dependent; the manuscript must supply either an explicit error bound on the linearization or empirical measurements of approximation quality (e.g., correlation between DPG rewards and true finite-difference gradients) along the actual optimization trajectory.
- [Experimental results (Section 4)] Table or figure reporting the five demonstrations: success is claimed for ambitious targets (QR-code embedding in LM head, exact UUID production). The manuscript should report quantitative success metrics, variance across runs, and controls (e.g., SFT on random or non-DPG-generated data) to show that the observed effects are attributable to the DPG-optimized dataset rather than incidental properties of the generator or base model.
minor comments (2)
- [Method description] Clarify the precise definition and computational implementation of the 'higher-order gradients' used for attribution (e.g., which Hessian terms are retained, how they are estimated without full materialization).
- [Introduction or Related Work] Add discussion of related work on influence functions, data attribution, and synthetic-data-based model editing to better position the contribution relative to prior approximations.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We have carefully considered the major comments and will make revisions to address them as detailed below.
read point-by-point responses
-
Referee: [Proof of gradient approximation (Section 3 or equivalent)] The proof that DPG 'closely approximates the true, intractable gradient' (abstract) relies on higher-order gradients providing reliable data attribution. Standard derivations of such attributions (influence functions or Hessian-vector products) are first-order linearizations around the initial parameters. The demonstrations involve multiple SFT steps with non-negligible learning rates, during which parameters move and the attribution becomes path-dependent; the manuscript must supply either an explicit error bound on the linearization or empirical measurements of approximation quality (e.g., correlation between DPG rewards and true finite-difference gradients) along the actual optimization trajectory.
Authors: We thank the referee for this insightful observation. While our proof establishes that DPG approximates the gradient using higher-order terms for data attribution, we recognize that the multi-step nature of SFT introduces path-dependence not fully bounded in the current analysis. In the revision, we will include empirical evaluations measuring the correlation between the DPG-computed rewards and finite-difference approximations of the true gradient at various points along the training trajectory. This will quantify the approximation error in practice. revision: yes
-
Referee: [Experimental results (Section 4)] Table or figure reporting the five demonstrations: success is claimed for ambitious targets (QR-code embedding in LM head, exact UUID production). The manuscript should report quantitative success metrics, variance across runs, and controls (e.g., SFT on random or non-DPG-generated data) to show that the observed effects are attributable to the DPG-optimized dataset rather than incidental properties of the generator or base model.
Authors: We agree that additional quantitative details would strengthen the experimental section. The demonstrations in the manuscript are primarily qualitative to illustrate the novel capabilities, but we will add a table in the revised version reporting success metrics (such as embedding accuracy or output match rates), standard deviations from multiple independent runs, and control experiments using randomly generated data or data from non-optimized generators. These additions will confirm the attribution of the observed effects to the DPG method. revision: yes
Circularity Check
No circularity in the core derivation chain
full rationale
The paper defines DPG as using exact higher-order gradient data attribution scores directly as policy rewards for optimizing a synthetic data generator, then claims a proof that this approximates the intractable true gradient of the post-SFT metric. No equations or steps in the abstract reduce the claimed approximation to a fitted parameter, self-definition, or self-citation chain by construction. The targets (QR-code embedding, UUID production) are presented as empirical illustrations rather than inputs to the derivation. The method is grounded in external gradient computations from the target model, satisfying the criteria for an independent, non-circular derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The target metric is differentiable with respect to model parameters
- domain assumption Higher-order gradients can be obtained exactly for data attribution
invented entities (1)
-
Dataset Policy Gradient (DPG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://zenodo.org/ records/12608602. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie 11 Preprint. Under review. Sravankumar, Artem Korenev, Arthur Hinsvar...
-
[2]
Thus, the two functions are smooth with parameterL :=max(G 3,Φ max(G2 1 +G 2)). A.3 Lemma 2 Let learning algorithm A be SGD operating on x∼π θ, performing gradient descent on ℓ(ϕ,x)to minimizeE x∼π θ [ℓ(ϕ,x)]. We show that the SGD iterates defined by ϕk :=ϕ k−1 −η∇ℓ(ϕ k−1,x k−1) with xk ∼π θ converges to its SDE equivalent in the small-step-size limit, wi...
work page 2021
-
[3]
Now, we bound the ℓ2 distance of the two processes, which is the ℓ2 norm of ∆t
Now define the difference sequence ∆t :=Z t −Z ′ t with the associated SDE d∆t :=−(∇f(Z t)− ∇f(Z ′ t))dt+ √η(Σ(Z t)−Σ ′(Z′ t))dWt. Now, we bound the ℓ2 distance of the two processes, which is the ℓ2 norm of ∆t. By Ito’s formula (Itˆo, 1951), d||∆ t||2 =2∆ td∆t +Tr(η(Σ(Z t)−Σ ′(Z′ t))(Σ(Z t)−Σ ′(Z′ t))⊤)dt =2∆ t(−∇f(Z t) +∇f(Z ′ t))dt+2 √η∆t(Σ(Zt)−Σ ′(Z′ t...
work page 1951
-
[4]
Timo Gottschalk: A Renowned German Rally Co-driver
of CPT’d models on our test split of the multilingual LAMBADA tasks. Rows designate the source of the CPT data. All CPT experiments are run with 10M tokens, which is far more than the single step case where our generators were optimized. Our DPG RL procedure with Adam in A is able to generate synthetic data that generalizes to this longer training regime,...
work page 2024
-
[5]
Prior to being elected to this position, he was the ambassador of the National Assembly of Armenia. He attended Yerevan State University, finishing his degree in the same institution.\n\nI will likely rewrite this in a more readable and fluid version. \n\n' 29 'The Independent (Armenian): An Interview with Vardan Bostanjyan. \n\nWe couldn’t fall apart. At...
work page 1949
-
[6]
29 Preprint. Under review. 67, DPG GRPO Hyperparameters Parameter V alue Generator Learning rate 5e−6 Max Prompt Length 1024 Max Response Length 128 Groups,G4 Rollout Batch Size /G256 (1), 2048 (8), 24576 (96) KL Coefficient 0 Train Temperature 1.0 Val Temperature 1.0 GRPO Optimization Steps,M3840 (1), 480 (8), 40 (96) GRPO Train Epochs 40 Modelmeta-llama...
work page 2048
-
[7]
Hyperparameters for SFT on LAMBADA Parameter V alue Learning rate 1e−6, 1e−5 Weight Decay 0 Epochs 1, 5, 10 Context Length 2048 Batch Size 64 Modelmeta-llama/Llama-3.2-1B-Instruct,meta-llama/Llama-3.2-1B Infra Hugging Face Table 12: Hypermarameters for the SFT experiments shown in Table
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.