Recognition: unknown
TouchAnything: Diffusion-Guided 3D Reconstruction from Sparse Robot Touches
Pith reviewed 2026-05-10 17:03 UTC · model grok-4.3
The pith
Pretrained 2D vision diffusion models guide accurate 3D reconstruction from only a few robot touches
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the geometric knowledge already present in a pretrained large-scale 2D vision diffusion model can be transferred to the tactile domain, allowing an optimization procedure to recover accurate global 3D geometry from sparse contact points plus a coarse class label, even for object instances never encountered during training.
What carries the argument
An optimization loop that enforces agreement between the evolving 3D shape and the sparse tactile measurements while steering the shape toward the distribution of plausible objects encoded in the pretrained vision diffusion model.
If this is right
- Robots can obtain usable 3D models in occluded or dark settings where cameras provide no information.
- Reconstruction works on novel object instances without collecting category-specific training data.
- Sparse tactile sensing becomes sufficient for global shape recovery instead of requiring dense contact arrays.
- Pretrained vision models can be reused for tactile tasks without learning a separate diffusion model from scratch.
Where Pith is reading between the lines
- The same prior-transfer idea could be tested on other underconstrained sensing problems such as force or vibration data.
- Pairing the optimization with active touch selection might reduce the number of contacts still further.
- Larger or more recent vision diffusion models could be swapped in to handle finer surface details.
Load-bearing premise
The shape and semantic knowledge inside a 2D image diffusion model can be applied directly to 3D tactile data without retraining or category-specific adaptation.
What would settle it
Run the method on a new set of unseen objects using only the claimed number of touches, measure the surface error against ground-truth scans, and check whether the error stays comparable to or lower than baselines that do not use the diffusion prior.
Figures











read the original abstract
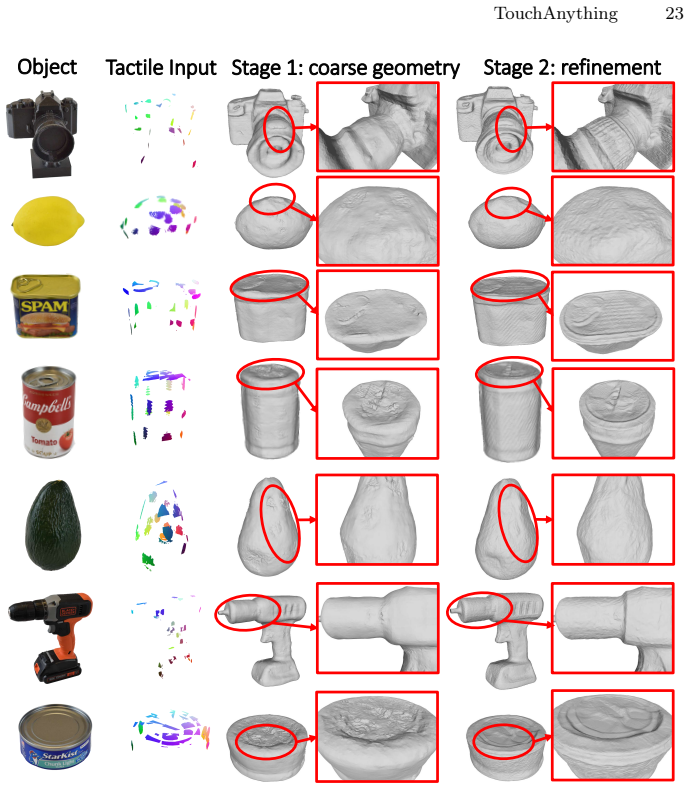
Accurate object geometry estimation is essential for many downstream tasks, including robotic manipulation and physical interaction. Although vision is the dominant modality for shape perception, it becomes unreliable under occlusions or challenging lighting conditions. In such scenarios, tactile sensing provides direct geometric information through physical contact. However, reconstructing global 3D geometry from sparse local touches alone is fundamentally underconstrained. We present TouchAnything, a framework that leverages a pretrained large-scale 2D vision diffusion model as a semantic and geometric prior for 3D reconstruction from sparse tactile measurements. Unlike prior work that trains category-specific reconstruction networks or learns diffusion models directly from tactile data, we transfer the geometric knowledge encoded in pretrained visual diffusion models to the tactile domain. Given sparse contact constraints and a coarse class-level description of the object, we formulate reconstruction as an optimization problem that enforces tactile consistency while guiding solutions toward shapes consistent with the diffusion prior. Our method reconstructs accurate geometries from only a few touches, outperforms existing baselines, and enables open-world 3D reconstruction of previously unseen object instances. Our project page is https://grange007.github.io/touchanything .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TouchAnything, a framework for reconstructing 3D object geometry from sparse tactile contacts. It formulates the task as an optimization problem that enforces consistency with the measured touches while using a pretrained 2D vision diffusion model (guided by a coarse class label) as a semantic and geometric prior. The central claims are that this yields accurate shapes from only a few touches, outperforms prior baselines, and enables open-world reconstruction of previously unseen object instances without category-specific training or learning a tactile diffusion model.
Significance. If the transfer of 2D diffusion priors to sparse 3D tactile reconstruction holds with the reported accuracy, the work would be significant for robotic manipulation under occlusion or poor lighting. It demonstrates a practical way to leverage large-scale visual models for tactile perception without collecting large tactile datasets, potentially broadening open-world 3D sensing capabilities.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that the method 'enables open-world 3D reconstruction of previously unseen object instances' and 'outperforms existing baselines' from 'only a few touches' is stated without any quantitative support, ablation isolating the diffusion prior's contribution, or description of the evaluation protocol (number of touches, held-out instances, metrics). This leaves the transfer assumption unverified.
- [Method] Method section (optimization formulation): The approach relies on the 2D diffusion model supplying 3D-geometric information via guidance during optimization. However, without explicit details on how 3D shapes are rendered or scored against the 2D prior (e.g., via multi-view rendering or implicit surface queries), it is unclear whether solutions can satisfy the diffusion score while deviating from true geometry, especially for novel instances where distribution shift may occur.
minor comments (2)
- The manuscript should include a clear statement on code and data availability to support reproducibility claims.
- Figure captions and experimental tables would benefit from explicit mention of the number of touches used in each result to ground the 'few touches' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each major comment point-by-point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the method 'enables open-world 3D reconstruction of previously unseen object instances' and 'outperforms existing baselines' from 'only a few touches' is stated without any quantitative support, ablation isolating the diffusion prior's contribution, or description of the evaluation protocol (number of touches, held-out instances, metrics). This leaves the transfer assumption unverified.
Authors: The abstract is intended as a high-level summary, and the detailed quantitative results, including performance metrics on held-out instances, comparisons to baselines, ablations on the diffusion prior, and the evaluation protocol (specifying the number of touches and metrics like Chamfer distance) are presented in the Experiments section of the manuscript. To better support the claims in the abstract and address the referee's concern, we will revise the abstract to include a brief mention of key quantitative outcomes and the evaluation setup. This revision will be made in the next version of the manuscript. revision: yes
-
Referee: [Method] Method section (optimization formulation): The approach relies on the 2D diffusion model supplying 3D-geometric information via guidance during optimization. However, without explicit details on how 3D shapes are rendered or scored against the 2D prior (e.g., via multi-view rendering or implicit surface queries), it is unclear whether solutions can satisfy the diffusion score while deviating from true geometry, especially for novel instances where distribution shift may occur.
Authors: We appreciate this feedback on the clarity of the method description. The 3D reconstruction is represented using an implicit neural SDF, which is optimized by rendering it into multiple 2D views using a differentiable renderer. These rendered images are then evaluated against the diffusion prior by computing the diffusion score, with the class label providing conditioning for open-world generalization. Tactile touches are incorporated as direct constraints on the SDF values at contact locations. We agree that additional details would improve clarity, particularly regarding the multi-view rendering process and how the guidance prevents deviation from true geometry. We will expand the method section with more explicit explanations, including a figure illustrating the rendering and scoring pipeline, and pseudocode for the optimization loop. This will also discuss robustness to distribution shift for novel instances. revision: yes
Circularity Check
No significant circularity; method uses external pretrained 2D diffusion prior for optimization
full rationale
The paper's core derivation formulates reconstruction as an optimization enforcing tactile consistency plus guidance from a pretrained large-scale 2D vision diffusion model (e.g., via class-level description). This prior originates externally from 2D image training and is not fitted to the sparse tactile measurements or target instances within the paper. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or description; the approach explicitly contrasts with category-specific training or direct tactile diffusion learning. The claimed accuracy on unseen instances therefore rests on an independent transfer assumption rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ansel, J., Yang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., Chauhan, G., Chourdia, A., Constable, W., Des- maison, A., DeVito, Z., Ellison, E., Feng, W., Gong, J., Gschwind, M., Hirsh, B., Huang, S., Kalambarkar, K., Kirsch, L., Lazos, M., Lezcano, M., Liang, Y., Liang, J., Lu, Y., Luk, C., Maher, B...
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Azinović, D., Martin-Brualla, R., Goldman, D.B., Nießner, M., Thies, J.: Neural rgb-d surface reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6290–6301 (June 2022)
2022
-
[3]
Boerner, T.J., Deems, S., Furlani, T.R., Knuth, S.L., Towns, J.: ACCESS: Advanc- ingInnovation:NSF’sAdvancedCyberinfrastructureCoordinationEcosystem:Ser- vices & Support. In: Practice and Experience in Advanced Research Computing (PEARC ’23). p. 4. ACM, Portland, OR, USA (July 2023).https://doi.org/10. 1145/3569951.3597559,https://doi.org/10.1145/3569951.3597559
-
[4]
Calli, B., Singh, A., Bruce, J., Walsman, A., Konolige, K., Srinivasa, S., Abbeel, P., Dollar, A.M.: Yale-cmu-berkeley dataset for robotic manipulation research. The 16 L. Gu et al. International Journal of Robotics Research36(3), 261–268 (2017).https://doi. org/10.1177/0278364917700714,https://doi.org/10.1177/0278364917700714
-
[5]
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: ShapeNet: An Information-Rich 3D Model Repository. Tech. Rep. arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago (2015)
work page internal anchor Pith review arXiv 2015
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, R., Chen, Y., Jiao, N., Jia, K.: Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22246–22256 (2023)
2023
-
[7]
In: European Conference on Computer Vision
Chibane, J., Pons-Moll, G.: Implicit feature networks for texture completion from partial 3d data. In: European Conference on Computer Vision. pp. 717–725. Springer (2020)
2020
-
[8]
IEEE Robotics and Automation Letters9(6), 5719–5726 (2024)
Comi, M., Lin, Y., Church, A., Tonioni, A., Aitchison, L., Lepora, N.F.: Touchsdf: A deepsdf approach for 3d shape reconstruction using vision-based tactile sensing. IEEE Robotics and Automation Letters9(6), 5719–5726 (2024)
2024
-
[9]
In: 2025 International Conference on 3D Vision (3DV)
Comi, M., Tonioni, A., Tremblay, J., Yang, M., Blukis, V., Lin, Y., Lepora, N.F., Aitchison, L.: Snap-it, tap-it, splat-it: Tactile-informed 3d gaussian splatting for reconstructing challenging surfaces. In: 2025 International Conference on 3D Vision (3DV). pp. 1134–1143. IEEE (2025)
2025
-
[10]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Fang, I., Shi, K., He, X., Tan, S., Wang, Y., Zhao, H., Huang, H.J., Yuan, W., Feng, C., Zhang, J.: Fusionsense: Bridging common sense, vision, and touch for robust sparse-view reconstruction. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 15798–15805. IEEE (2025)
2025
-
[11]
Advances in Neural Information Processing Systems37, 29839–29863 (2024)
Gao, R., Deng, K., Yang, G., Yuan, W., Zhu, J.Y.: Tactile dreamfusion: Exploit- ing tactile sensing for 3d generation. Advances in Neural Information Processing Systems37, 29839–29863 (2024)
2024
-
[12]
IEEE Robotics and Automation Letters (2024)
Huang, H.J., Kaess, M., Yuan, W.: Normalflow: Fast, robust, and accurate contact- based object 6dof pose tracking with vision-based tactile sensors. IEEE Robotics and Automation Letters (2024)
2024
-
[13]
arXiv preprint arXiv:2508.15990 (2025)
Huang, H.J., Mirzaee, M.A., Kaess, M., Yuan, W.: Gelslam: A real-time, high- fidelity, and robust 3d tactile slam system. arXiv preprint arXiv:2508.15990 (2025)
-
[14]
Advances in Neural Information Processing Sys- tems36, 12171–12191 (2023)
Kasten, Y., Rahamim, O., Chechik, G.: Point cloud completion with pretrained text-to-image diffusion models. Advances in Neural Information Processing Sys- tems36, 12171–12191 (2023)
2023
-
[15]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[16]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision
Kung, P.C., Harisha, S., Vasudevan, R., Eid, A., Skinner, K.A.: Radarsplat: Radar gaussian splatting for high-fidelity data synthesis and 3d reconstruction of au- tonomous driving scenes. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision. pp. 27596–27606 (2025)
2025
-
[17]
ACM Transactions on Graphics 39(6) (2020)
Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primi- tives for high-performance differentiable rendering. ACM Transactions on Graphics 39(6) (2020)
2020
-
[18]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Li, Z., Müller, T., Evans, A., Taylor, R.H., Unberath, M., Liu, M.Y., Lin, C.H.: Neuralangelo: High-fidelity neural surface reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 300–309 (2023) TouchAnything 17
2023
-
[20]
In: 2025 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS)
Lin, T., Qadri, M., Zhang, K., Pediredla, A., Metzler, C.A., Kaess, M.: Acoustic neural 3d reconstruction under pose drift. In: 2025 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS). pp. 12704–12711. IEEE (2025)
2025
-
[21]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[22]
URL https://doi.org/10.1145/3528223
Müller,T.,Evans,A.,Schied,C.,Keller,A.:Instantneuralgraphicsprimitiveswith a multiresolution hash encoding. ACM Trans. Graph.41(4) (Jul 2022).https: //doi.org/10.1145/3528223.3530127,https://doi.org/10.1145/3528223. 3530127
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ni, J., Liu, Y., Lu, R., Zhou, Z., Zhu, S.C., Chen, Y., Huang, S.: Decompositional neural scene reconstruction with generative diffusion prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6022–6033 (June 2025)
2025
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse in- puts. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5480–5490 (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park,J.J.,Florence,P.,Straub,J.,Newcombe,R.,Lovegrove,S.:Deepsdf:Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 165– 174 (2019)
2019
-
[26]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review arXiv 2022
-
[27]
In: 2023 IEEE International Conference on Robotics and Automa- tion (ICRA)
Qadri, M., Kaess, M., Gkioulekas, I.: Neural implicit surface reconstruction using imaging sonar. In: 2023 IEEE International Conference on Robotics and Automa- tion (ICRA). pp. 1040–1047. IEEE (2023)
2023
-
[28]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Qadri,M.,Manchester,Z.,Kaess,M.:Learningcovariancesforestimationwithcon- strained bilevel optimization. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 15951–15957. IEEE (2024)
2024
-
[29]
In: 2022 IEEE/RSJ International Conferenceon IntelligentRobots andSystems(IROS).pp
Qadri, M., Sodhi, P., Mangelson, J.G., Dellaert, F., Kaess, M.: Incopt: Incremental constrained optimization using the bayes tree. In: 2022 IEEE/RSJ International Conferenceon IntelligentRobots andSystems(IROS).pp. 6381–6388. IEEE(2022)
2022
-
[30]
In: ACM SIG- GRAPH 2024 Conference Papers
Qadri,M.,Zhang,K.,Hinduja,A.,Kaess,M.,Pediredla,A.,Metzler,C.A.:Aoneus: A neural rendering framework for acoustic-optical sensor fusion. In: ACM SIG- GRAPH 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Qiu, L., Chen, G., Gu, X., Zuo, Q., Xu, M., Wu, Y., Yuan, W., Dong, Z., Bo, L., Han, X.: Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to-3d. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9914–9925 (2024)
2024
-
[32]
IEEE transactions on pattern analysis and machine intelligence47(9), 7255–7267 (2024)
Qu, Z., Vengurlekar, O., Qadri, M., Zhang, K., Kaess, M., Metzler, C., Jayasuriya, S., Pediredla, A.: Z-splat: Z-axis gaussian splatting for camera-sonar fusion. IEEE transactions on pattern analysis and machine intelligence47(9), 7255–7267 (2024)
2024
-
[33]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Rafidashti, M., Lan, J., Fatemi, M., Fu, J., Hammarstrand, L., Svensson, L.: Neu- radar: Neural radiance fields for automotive radar point clouds. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2488–2498 (2025)
2025
-
[34]
Accelerating 3D Deep Learning with PyTorch3D
Ravi,N.,Reizenstein,J.,Novotny,D.,Gordon,T.,Lo,W.Y.,Johnson,J.,Gkioxari, G.: Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501 (2020)
work page internal anchor Pith review arXiv 2007
-
[35]
In: Proceedings of the IEEE/CVF 18 L
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF 18 L. Gu et al. Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[36]
In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI
-
[37]
pp. 234–241. Springer International Publishing, Cham (2015)
2015
-
[38]
arXiv preprint arXiv:2403.12470 (2024)
Schaefer, S., Galvis, J.D., Zuo, X., Leutengger, S.: Sc-diff: 3d shape completion with latent diffusion models. arXiv preprint arXiv:2403.12470 (2024)
-
[39]
Advances in Neural Information Processing Systems34, 6087–6101 (2021)
Shen, T., Gao, J., Yin, K., Liu, M.Y., Fidler, S.: Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. Advances in Neural Information Processing Systems34, 6087–6101 (2021)
2021
-
[40]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Shen, T., Gao, J., Yin, K., Liu, M.Y., Fidler, S.: Deep marching tetrahedra: a hy- brid representation for high-resolution 3d shape synthesis. In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[41]
IEEE Robotics and Automation Letters7(2), 2361–2368 (2022).https: //doi.org/10.1109/LRA.2022.3142412
Si, Z., Yuan, W.: Taxim: An example-based simulation model for gelsight tactile sensors. IEEE Robotics and Automation Letters7(2), 2361–2368 (2022).https: //doi.org/10.1109/LRA.2022.3142412
-
[42]
Science Robotics9(96), eadl0628 (2024)
Suresh, S., Qi, H., Wu, T., Fan, T., Pineda, L., Lambeta, M., Malik, J., Kalakrish- nan, M., Calandra, R., Kaess, M., et al.: Neuralfeels with neural fields: Visuotactile perception for in-hand manipulation. Science Robotics9(96), eadl0628 (2024)
2024
-
[43]
In: 2022 International Conference on Robotics and Automation (ICRA)
Suresh, S., Si, Z., Mangelson, J.G., Yuan, W., Kaess, M.: Shapemap 3-d: Efficient shape mapping through dense touch and vision. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 7073–7080. IEEE (2022)
2022
-
[44]
In: 2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS)
Swann,A.,Strong,M.,Do,W.K.,Camps,G.S.,Schwager,M.,Kennedy,M.:Touch- gs: Visual-tactile supervised 3d gaussian splatting. In: 2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). pp. 10511–10518. IEEE (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, G., Chen, Z., Loy, C.C., Liu, Z.: Sparsenerf: Distilling depth ranking for few-shot novel view synthesis. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9065–9076 (2023)
2023
-
[46]
Wang, S., She, Y., Romero, B., Adelson, E.: Gelsight wedge: Measuring high- resolution 3d contact geometry with a compact robot finger. In: 2021 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 6468–6475 (2021). https://doi.org/10.1109/ICRA48506.2021.9560783
-
[47]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Wang, Y., Zhang, Z., Qiu, J., Sun, D., Meng, Z., Wei, X., Yang, X.: Touch2shape: Touch-conditioned 3d diffusion for shape exploration and reconstruction. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 5656– 5665 (2025)
2025
-
[48]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, R., Mildenhall, B., Henzler, P., Park, K., Gao, R., Watson, D., Srinivasan, P.P., Verbin, D., Barron, J.T., Poole, B., et al.: Reconfusion: 3d reconstruction with diffusion priors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21551–21561 (2024)
2024
-
[50]
In: 2018 international conference on 3D vision (3DV)
Yuan, W., Khot, T., Held, D., Mertz, C., Hebert, M.: Pcn: Point completion net- work. In: 2018 international conference on 3D vision (3DV). pp. 728–737. IEEE (2018)
2018
-
[51]
Sensors17(12), 2762 (2017) TouchAnything 19
Yuan, W., Dong, S., Adelson, E.H.: Gelsight: High-resolution robot tactile sensors for estimating geometry and force. Sensors17(12), 2762 (2017) TouchAnything 19
2017
-
[52]
Yuksel, C.: Sample elimination for generating poisson disk sample sets. Comput. Graph. Forum34(2), 25–32 (May 2015).https://doi.org/10.1111/cgf.12538, https://doi.org/10.1111/cgf.12538
-
[53]
IEEE Robotics and Automation Letters11(2), 1434–1441 (2025)
Zhang, H., Zhang, X., Huang, J., Feng, Z., Xiao, X.: End-to-end diffusion-based 3d object reconstruction from robotic tactile sensing. IEEE Robotics and Automation Letters11(2), 1434–1441 (2025)
2025
-
[54]
In: European Conference on Computer Vision
Zhao, C., Sun, S., Wang, R., Guo, Y., Wan, J.J., Huang, Z., Huang, X., Chen, Y.V., Ren, L.: Tclc-gs: Tightly coupled lidar-camera gaussian splatting for autonomous driving: Supplementary materials. In: European Conference on Computer Vision. pp. 91–106. Springer (2024)
2024
-
[55]
Open3D: A Modern Library for 3D Data Processing
Zhou, Q.Y., Park, J., Koltun, V.: Open3D: A modern library for 3D data process- ing. arXiv:1801.09847 (2018)
work page internal anchor Pith review arXiv 2018
-
[56]
a camera
Zou, Z., Cheng, W., Cao, Y.P., Huang, S.S., Shan, Y., Zhang, S.H.: Sparse3d: Dis- tilling multiview-consistent diffusion for object reconstruction from sparse views. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 7900– 7908 (2024) 20 L. Gu et al. Supplementary Material In this supplementary material, we provide additional ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.