Recognition: 2 theorem links
· Lean TheoremTraining-Free Object-Background Compositional T2I via Dynamic Spatial Guidance and Multi-Path Pruning
Pith reviewed 2026-05-10 17:53 UTC · model grok-4.3
The pith
A training-free framework restructures diffusion sampling with dynamic spatial guidance and multi-path pruning to improve foreground-background compositional alignment in text-to-image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing text-to-image diffusion models exhibit a persistent foreground bias that treats the background as a passive and under-optimized byproduct. This imbalance compromises global scene coherence and constrains compositional control. To address the limitation, we propose a training-free framework that restructures diffusion sampling to explicitly account for foreground-background interactions. Our approach consists of two key components: Dynamic Spatial Guidance introduces a soft, time step dependent gating mechanism that modulates foreground and background attention during the diffusion process, enabling spatially balanced generation. Second, Multi-Path Pruning performs multi-path latent
What carries the argument
Dynamic Spatial Guidance, a soft time step dependent gating mechanism that modulates foreground and background attention, combined with Multi-Path Pruning for multi-path latent exploration and filtering of trajectories using attention statistics and semantic alignment signals.
If this is right
- Improved global scene coherence in generated images
- Enhanced object-background compositional alignment
- Consistent performance gains across multiple diffusion model backbones
- Spatially balanced generation without model retraining or tuning
- A new benchmark for assessing object-background compositionality
Where Pith is reading between the lines
- The method may allow more precise control over scene elements in applications like design and advertising.
- It could be adapted to other generative tasks such as text-to-video for better background consistency.
- Reducing foreground bias might lead to more realistic AI-generated environments.
- This training-free approach suggests a general strategy for improving diffusion models' handling of complex prompts.
Load-bearing premise
The dynamic gating and pruning mechanisms can effectively modulate attention and select trajectories to achieve better object-background compositional alignment without compromising image quality or requiring model-specific tuning.
What would settle it
Generated images on the proposed benchmark showing no improvement or a decline in background coherence and object-background alignment metrics compared to standard diffusion sampling baselines.
Figures
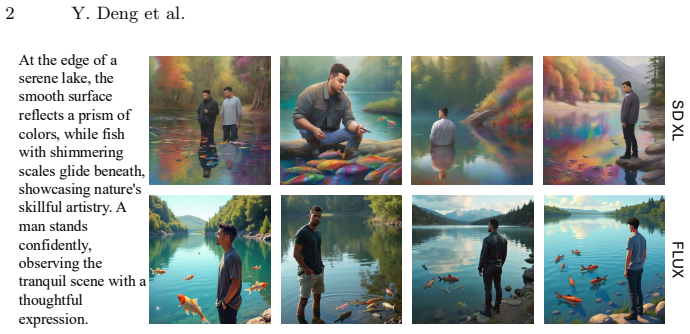






read the original abstract
Existing text-to-image diffusion models, while excelling at subject synthesis, exhibit a persistent foreground bias that treats the background as a passive and under-optimized byproduct. This imbalance compromises global scene coherence and constrains compositional control. To address the limitation, we propose a training-free framework that restructures diffusion sampling to explicitly account for foreground-background interactions. Our approach consists of two key components. First, Dynamic Spatial Guidance introduces a soft, time step dependent gating mechanism that modulates foreground and background attention during the diffusion process, enabling spatially balanced generation. Second, Multi-Path Pruning performs multi-path latent exploration and dynamically filters candidate trajectories using both internal attention statistics and external semantic alignment signals, retaining trajectories that better satisfy object-background constraints. We further develop a benchmark specifically designed to evaluate object-background compositionality. Extensive evaluations across multiple diffusion backbones demonstrate consistent improvements in background coherence and object-background compositional alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing text-to-image diffusion models suffer from foreground bias, and proposes a training-free framework to address it via two components: Dynamic Spatial Guidance, a soft time-step-dependent gating mechanism that modulates foreground and background attention during diffusion sampling, and Multi-Path Pruning, which explores multiple latent trajectories and filters them using internal attention statistics and external semantic alignment signals. The authors also introduce a dedicated benchmark for object-background compositionality and report consistent improvements in background coherence and compositional alignment across multiple diffusion backbones.
Significance. If the central claims hold, the work would be a meaningful contribution to the field by offering a practical, training-free intervention for a well-known limitation in diffusion-based T2I generation. The introduction of a specialized benchmark for object-background compositionality is a clear strength that could support future research, and the emphasis on model-agnostic applicability without retraining aligns with current needs for efficient inference-time improvements.
major comments (2)
- [Abstract and §3] Abstract and §3 (Dynamic Spatial Guidance): The claim that the soft, time-step-dependent gating mechanism can reliably modulate attention to achieve spatially balanced generation without model-specific tuning is load-bearing for the overall contribution. However, this hinges on the unstated assumption that foreground/background regions can be identified from internal attention statistics even at early timesteps (t > 0.6), where cross-attention is typically diffuse and non-localized; the manuscript provides no analysis or ablation of attention map quality across timesteps to support that the gating has a non-negligible effect rather than introducing artifacts.
- [§4 and evaluations] §4 (Multi-Path Pruning) and experimental results: The multi-path exploration and dynamic filtering strategy is presented as key to retaining trajectories that satisfy object-background constraints, yet the evaluations lack detailed ablations isolating the contribution of pruning versus the guidance component, or comparisons against simpler multi-path baselines. This makes it difficult to assess whether the reported consistent improvements are attributable to the proposed method or to other factors, weakening the central claim of reliable compositional gains.
minor comments (2)
- [Benchmark section] The description of the new object-background compositionality benchmark lacks specifics on dataset construction, evaluation metrics, and comparison to existing compositional benchmarks (e.g., those based on attribute binding or spatial relations); expanding this section would improve reproducibility.
- [Method sections] Notation for 'internal attention statistics' and 'external semantic alignment signals' is used without accompanying equations or precise definitions in the main text; adding formal notation would clarify the implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The concerns raised are substantive and we address each point below with clarifications and commitments to strengthen the manuscript through additional analysis and experiments.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dynamic Spatial Guidance): The claim that the soft, time-step-dependent gating mechanism can reliably modulate attention to achieve spatially balanced generation without model-specific tuning is load-bearing for the overall contribution. However, this hinges on the unstated assumption that foreground/background regions can be identified from internal attention statistics even at early timesteps (t > 0.6), where cross-attention is typically diffuse and non-localized; the manuscript provides no analysis or ablation of attention map quality across timesteps to support that the gating has a non-negligible effect rather than introducing artifacts.
Authors: We appreciate the referee's identification of this critical assumption. The Dynamic Spatial Guidance employs a deliberately soft, time-dependent schedule in which gating strength is minimal at early timesteps (t > 0.6) precisely to avoid over-reliance on diffuse attention maps; the modulation ramps up only as localization improves. This design ensures the early-stage effect is a gentle global bias rather than a hard spatial decision, reducing the risk of artifacts. While the original manuscript did not include explicit timestep-wise attention quality ablations, the consistent gains across multiple backbones without per-model tuning provide indirect support for robustness. To directly address the concern, we will add (i) visualizations and quantitative metrics of attention map localization across timesteps and (ii) an ablation varying the gating schedule in the revised version. revision: yes
-
Referee: [§4 and evaluations] §4 (Multi-Path Pruning) and experimental results: The multi-path exploration and dynamic filtering strategy is presented as key to retaining trajectories that satisfy object-background constraints, yet the evaluations lack detailed ablations isolating the contribution of pruning versus the guidance component, or comparisons against simpler multi-path baselines. This makes it difficult to assess whether the reported consistent improvements are attributable to the proposed method or to other factors, weakening the central claim of reliable compositional gains.
Authors: We agree that isolating the incremental contributions is essential for validating the central claims. The current experiments report the combined effect of both components, which limits attribution. In the revision we will expand §4 and the experimental section with: (1) an ablation using Dynamic Spatial Guidance alone, (2) multi-path exploration without the pruning filter, and (3) a simpler baseline of random multi-path sampling (no attention or semantic filtering). These additions will quantify the specific benefit of the pruning step that uses internal attention statistics and external semantic alignment, allowing readers to assess whether the reported gains are attributable to the proposed mechanisms. revision: yes
Circularity Check
No significant circularity in heuristic training-free method
full rationale
The paper proposes a training-free heuristic framework with two components—Dynamic Spatial Guidance (soft timestep-dependent gating) and Multi-Path Pruning (multi-path exploration with attention and semantic filtering)—to address foreground bias in diffusion models. No equations, derivations, or first-principles results are present that reduce to inputs by construction. The approach is described purely as a restructuring of sampling with empirical validation across backbones and a new benchmark; there are no fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that justify uniqueness. The central claims rest on the described mechanisms and experimental outcomes rather than any closed-form reduction, making the work self-contained as a method contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Spatial Guidance introduces a soft, time step dependent gating mechanism that modulates foreground and background attention during the diffusion process... Multi-Path Pruning performs multi-path latent exploration and dynamically filters candidate trajectories using both internal attention statistics and external semantic alignment signals
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a training-free framework that restructures diffusion sampling to explicitly account for foreground-background interactions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2406.01970 (2024)
Ban, Y., Wang, R., Zhou, T., Gong, B., Hsieh, C.J., Cheng, M.: The Crystal Ball Hypothesis in diffusion models: Anticipating object positions from initial noise. arXiv preprint arXiv:2406.01970 (2024)
-
[3]
In: ACM SIGGRAPH 2024 Conference Papers
Bao, Z., Li, Y., Singh, K.K., Wang, Y.X., Hebert, M.: Separate-and-enhance: Com- positional finetuning for text-to-image diffusion models. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–10 (2024)
2024
-
[4]
Advances in Neural Information Processing Systems 32(2019)
Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., Tenenbaum, J., Katz, B.: Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Advances in Neural Information Processing Systems 32(2019)
2019
-
[5]
Journal of statistical mechanics: theory and experiment 2008(10), P10008 (2008)
Blondel, V.D., Guillaume, J.L., Lambiotte, R., Lefebvre, E.: Fast unfolding of com- munities in large networks. Journal of statistical mechanics: theory and experiment 2008(10), P10008 (2008)
2008
-
[6]
IEEE Transactions on Neural Networks and Learn- ing Systems27(6), 1214–1226 (2015)
Borji, A., Tanner, J.: Reconciling saliency and object center-bias hypotheses in ex- plaining free-viewing fixations. IEEE Transactions on Neural Networks and Learn- ing Systems27(6), 1214–1226 (2015)
2015
-
[7]
In: 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018)
Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A.: VGGFace2: A dataset for recognising faces across pose and age. In: 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). pp. 67–74. IEEE (2018)
2018
-
[8]
MaskAttn-SDXL: Controllable region-level text-to-image generation,
Chang, Y., Chen, J., Cheng, A., Bogdan, P.: Maskattn-sdxl: Controllable region- level text-to-image generation. arXiv preprint arXiv:2509.15357 (2025)
-
[9]
ACM Trans- actions on Graphics (TOG)42(4), 1–10 (2023)
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Trans- actions on Graphics (TOG)42(4), 1–10 (2023)
2023
-
[10]
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., Li, Z.: Pixart-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis (2023)
2023
-
[11]
arXiv preprint arXiv:2411.06558 (2024)
Chen, Z., Li, Y., Wang, H., Chen, Z., Jiang, Z., Li, J., Wang, Q., Yang, J., Tai, Y.: Region-aware text-to-image generation via hard binding and soft refinement. arXiv preprint arXiv:2411.06558 (2024)
-
[12]
In: Proceedings of the Spe- cial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Dahary, O., Cohen, Y., Patashnik, O., Aberman, K., Cohen-Or, D.: Be Decisive: Noise-Induced Layouts for Multi-Subject Generation. In: Proceedings of the Spe- cial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–12 (2025)
2025
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: ArcFace: Additive angular margin loss for deep face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4690–4699 (2019)
2019
-
[14]
Advances in Neural Information Processing Systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat GANs on image synthesis. Advances in Neural Information Processing Systems34, 8780–8794 (2021)
2021
-
[15]
Advances in Neural Information Processing Systems36, 18225–18250 (2023)
Feng, W., Zhu, W., Fu, T.j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: Compositional visual planning and generation with large language models. Advances in Neural Information Processing Systems36, 18225–18250 (2023)
2023
-
[16]
In: Proceedings of the Object-Background Compositional T2I 17 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Feng, Y., Gong, B., Chen, D., Shen, Y., Liu, Y., Zhou, J.: Ranni: Taming text-to-image diffusion for accurate instruction following. In: Proceedings of the Object-Background Compositional T2I 17 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4744– 4753 (2024)
2024
-
[17]
arXiv preprint arXiv:2508.15260 , year=
Fu, Y., Wang, X., Tian, Y., Zhao, J.: Deep think with confidence. arXiv preprint arXiv:2508.15260 (2025)
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, X., Liu, J., Cui, M., Li, J., Yang, H., Huang, D.: InitNO: Boosting text- to-image diffusion models via initial noise optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9380– 9389 (2024)
2024
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Han, W., Lee, Y., Kim, C., Park, K., Hwang, S.J.: Spatial Transport Optimiza- tion by Repositioning Attention Map for Training-Free Text-to-Image Synthesis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18401–18410 (2025)
2025
-
[20]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review arXiv 2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hertz, A., Voynov, A., Fruchter, S., Cohen-Or, D.: Style aligned image generation via shared attention. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4775–4785 (2024)
2024
-
[22]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: ELLA: Equip diffusion mod- els with LLM for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024)
work page internal anchor Pith review arXiv 2024
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: TIFA: Accurate and interpretable text-to-image faithfulness evaluation with ques- tion answering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20406–20417 (2023)
2023
-
[24]
Advances in Neural Information Processing Systems36, 78723–78747 (2023)
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems36, 78723–78747 (2023)
2023
-
[25]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[26]
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi
Li, D., Kamko, A., Akhgari, E., Sabet, A., Xu, L., Doshi, S.: Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation. arXiv preprint arXiv:2402.17245 (2024)
-
[27]
In: International Con- ference on Machine Learning
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International Con- ference on Machine Learning. pp. 12888–12900. PMLR (2022)
2022
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, M., Hou, X., Liu, Z., Yang, D., Qian, Z., Chen, J., Wei, J., Jiang, Y., Xu, Q., Zhang, L.: MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13263–13272 (2025)
2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Li, Z., Min, M.R., Li, K., Xu, C.: StyleT2I: Toward compositional and high-fidelity text-to-image synthesis. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 18197–18207 (2022)
2022
-
[30]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liu, M., Ma, Y., Yang, Z., Dan, J., Yu, Y., Zhao, Z., Hu, Z., Liu, B., Fan, C.: LLM4GEN: Leveraging semantic representation of llms for text-to-image genera- tion. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 5523–5531 (2025)
2025
- [31]
-
[32]
In: Proceedings of the 18 Y
Meral, T.H.S., Simsar, E., Tombari, F., Yanardag, P.: CONFORM: Contrast is all you need for high-fidelity text-to-image diffusion models. In: Proceedings of the 18 Y. Deng et al. IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9005– 9014 (2024)
2024
-
[33]
In: European conference on computer vision
Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Doso- vitskiy, A., Mahendran, A., Arnab, A., Dehghani, M., Shen, Z., et al.: Simple open-vocabulary object detection. In: European conference on computer vision. pp. 728–755. Springer (2022)
2022
-
[34]
In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Misra, I., Lawrence Zitnick, C., Mitchell, M., Girshick, R.: Seeing through the human reporting bias: Visual classifiers from noisy human-centric labels. In: Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2930–2939 (2016)
2016
-
[35]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: GLIDE: Towards photorealistic image generation and edit- ing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021)
work page internal anchor Pith review arXiv 2021
-
[36]
Trends in cogni- tive sciences11(12), 520–527 (2007)
Oliva, A., Torralba, A.: The role of context in object recognition. Trends in cogni- tive sciences11(12), 520–527 (2007)
2007
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Patashnik, O., Garibi, D., Azuri, I., Averbuch-Elor, H., Cohen-Or, D.: Localizing object-level shape variations with text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23051–23061 (2023)
2023
-
[38]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M¨ uller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Courier Corporation (1976)
Poore, H.R.: Composition in art. Courier Corporation (1976)
1976
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qu, L., Li, H., Wang, W., Liu, X., Li, J., Nie, L., Chua, T.S.: SILMM: Self- improving large multimodal models for compositional text-to-image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18497–18508 (2025)
2025
-
[41]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763. PmLR (2021)
2021
-
[42]
arXiv preprint arXiv:2210.10606 (2022)
Rassin, R., Ravfogel, S., Goldberg, Y.: DALLE-2 is seeing double: Flaws in word-to- concept mapping in Text2Image models. arXiv preprint arXiv:2210.10606 (2022)
-
[43]
arXiv preprint arXiv:2502.14634 (2025)
Razghandi, A., Hosseini, S.M.H., Baghshah, M.S.: Cer: Confidence enhanced rea- soning in llms. arXiv preprint arXiv:2502.14634 (2025)
-
[44]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-BERT: Sentence embeddings using Siamese BERT-networks. arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition
Ren, M., Xiong, W., Yoon, J.S., Shu, Z., Zhang, J., Jung, H., Gerig, G., Zhang, H.: Relightful harmonization: Lighting-aware portrait background replacement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. pp. 6452–6462 (2024)
2024
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[47]
International Journal of Computer Vision53(2), 169–191 (2003)
Torralba, A.: Contextual priming for object detection. International Journal of Computer Vision53(2), 169–191 (2003)
2003
-
[48]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 1921–1930 (2023) Object-Background Compositional T2I 19
1921
-
[49]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, L., Li, S., Yang, F., Wang, J., Zhang, Z., Liu, Y., Wang, Y., Yang, J.: Not All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12880–12890 (2025)
2025
-
[50]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, R., Chen, Z., Chen, C., Ma, J., Lu, H., Lin, X.: Compositional text-to-image synthesis with attention map control of diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5544–5552 (2024)
2024
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Wang, S., Lin, W., Huang, H., Wang, H., Cai, S., Han, W., Jin, T., Chen, J., Sun, J., Zhu, J., et al.: Towards transformer-based aligned generation with self-coherence guidance. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 18455–18464 (2025)
2025
-
[52]
Authorea Preprints (2025)
Wang, T.: Energy-Based Learning and the Evolution of Hopfield Networks: From Boltzmann Machines to Transformer Attention Mechanisms. Authorea Preprints (2025)
2025
-
[53]
Advances in Neural Information Processing Systems 37, 128374–128395 (2024)
Wang, Z., Li, A., Li, Z., Liu, X.: GenArtist: Multimodal llm as an agent for unified image generation and editing. Advances in Neural Information Processing Systems 37, 128374–128395 (2024)
2024
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Z., Sha, Z., Ding, Z., Wang, Y., Tu, Z.: TokenCompose: Text-to-image dif- fusion with token-level supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8553–8564 (2024)
2024
-
[55]
arXiv preprint arXiv:2006.09994 , year=
Xiao, K., Engstrom, L., Ilyas, A., Madry, A.: Noise or signal: The role of image backgrounds in object recognition. arXiv preprint arXiv:2006.09994 (2020)
-
[56]
In: Forty- first International Conference on Machine Learning (2024)
Yang, L., Yu, Z., Meng, C., Xu, M., Ermon, S., Cui, B.: Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. In: Forty- first International Conference on Machine Learning (2024)
2024
-
[57]
Advances in Neural Information Processing Systems37, 96963–96992 (2024)
Zhang, X., Yang, L., Cai, Y., Yu, Z., Wang, K.N., Tian, Y., Xu, M., Tang, Y., Yang, Y., Cui, B., et al.: Realcompo: Balancing realism and compositionality im- proves text-to-image diffusion models. Advances in Neural Information Processing Systems37, 96963–96992 (2024)
2024
-
[58]
In: European Conference on Computer Vision
Zhang, Y., Yu, P., Wu, Y.N.: Object-conditioned energy-based attention map align- ment in text-to-image diffusion models. In: European Conference on Computer Vision. pp. 55–71. Springer (2024)
2024
-
[59]
arXiv preprint arXiv:2504.00010 (2025)
Zhang, Y., Li, J., Tai, Y.W.: LayerCraft: Enhancing text-to-image generation with cot reasoning and layered object integration. arXiv preprint arXiv:2504.00010 (2025)
-
[60]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, G., Zhou, X., Li, X., Qi, Z., Shan, Y., Li, X.: Layoutdiffusion: Controllable diffusion model for layout-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22490–22499 (2023)
2023
-
[61]
Zhou, Z., Yuhao, T., Li, Z., Yao, Y., Guo, L.Z., Ma, X., Li, Y.F.: Bridging inter- nal probability and self-consistency for effective and efficient llm reasoning. arXiv preprint arXiv:2502.00511 (2025) Object-Background Compositional T2I 1 Training-Free Object-Background Compo- sitional T2I via Dynamic Spatial Guidance and Multi-Path Pruning (Appendix) A ...
-
[62]
BACKGROUND SENTENCE: one simple sentence ONLY about background, environment, time, objects and atmosphere
-
[63]
OBJECT SENTENCE: one simple sentence ONLY about the main object and MUST include the target NAME exactly as given if present
-
[64]
OBJECT NOUNS: 5-10 nouns copied verbatim from the Composition refer- ring to the main object
-
[65]
Ken Davitian sits comfortably in an armchair, the flames from the nearby candles reflecting in his eyes as he smiles warmly
BACKGROUND NOUNS: 5-10 nouns copied verbatim from the Composition referring to locations/time/scenery/background objects/ambience. Constraints: use ONLY words present in the Composition for noun lists; lower- case; no verbs/adjectives; no words not present; no extra keys. Return a compact JSON object with keys: background sentence, object sentence, object...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.